
小米开源首个推理大模型Xiaomi MiMo,数学和代码方面超越了OpenAI o1-mini和阿里Qwen
4月30日上午消息,小米开源首个为推理(Reasoning)而生的大模型‘Xiaomi MiMo’,联动预训练到后训练,全面提升推理能力。

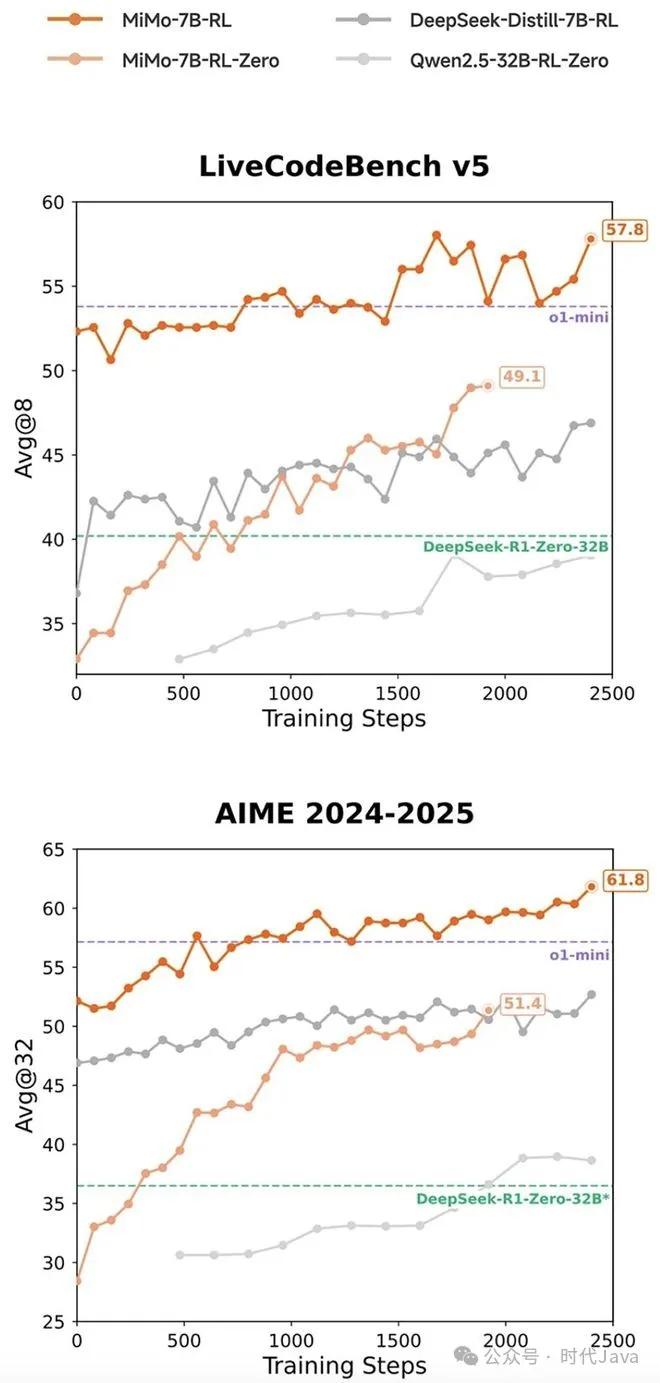
据介绍,在数学推理(AIME 24-25)和 代码竞赛(LiveCodeBench v5)公开测评集上,MiMo 仅用 7B 的参数规模,超越了 OpenAI 的闭源推理模型 o1-mini 和阿里Qwen 更大规模的开源推理模型 QwQ-32B-Preview。
随着DeepSeek-R1引发业界强化学习(RL)共创潮,DeepSeek-R1-Distill-7B和Qwen2.5-32B已成为广泛使用的强化学习起步模型。在相同RL训练数据情况下,MiMo-7B 的数学&代码领域的强化学习潜力显著领先。
值得注意的是,MiMo-7B全系列模型均已开源。据了解,MiMo 来自小米全新成立不久的“小米大模型Core团队”的初步尝试。
在相同强化学习训练数据情况下,MiMo-7B-RL在数学和代码推理任务上均表现出色,分数超过DeepSeek-R1-Distill-7B和Qwen2.5-32B。
MiMo是新成立不久的小米大模型Core团队的初步尝试,4款MiMo-7B模型(基础模型、SFT模型、基于基础模型训练的强化学习模型、基于SFT模型训练的强化学习模型)均开源至Hugging Face。代码库采用Apache2.0许可证授权。
开源地址:https://huggingface.co/XiaomiMiMo
小米大模型Core团队已公开MiMo的26页技术报告。

技术报告地址:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
从技术的角度,小米走的路径是“小参数,高性能,推理优先”的路线:
仅7B,但性能超越 OpenAI o1-mini 和阿里 Qwen-32B-Preview,有没有一个很熟悉的味道——从DS过来的罗福利负责Ai基座大模型,很多事情连贯了起来
推理能力是核心优化方向,不是通用闲聊模型
专注方向:数学+代码推理能力,在 AIME 24-25、LiveCodeBench v5 等测评集中表现领先,这个背后的逻辑就是,小米的Ai绝对不会仅仅停留在小爱上面,那个太狭隘了,而是为Agent,系统任务执行,自动驾驶逻辑引擎等高级用途准备底座模型。
问了一下业内的朋友,反馈它在推理性能和参数规模效率比是非常优异的。
小米的公司真正的想象力是在Ai,这也是我早期为什么有选择他的原因。
这算是小米在 Ai的一个开始纪念碑(不是里程碑),Mimo是小米Ai战略升级的一个信号弹。终究,小米Ai会让小爱同学从助手走向Agent,也让小米在人车家生态中拥有真正的“智能中枢引擎”。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java