
Apache Spark 3.0.0发布及新特性解析
2020年6月18日,开发了近两年(自2018年10月份至今)的Apache Spark 3.0.0 正式发布!
Apache Spark 3.0.0版本包含3400多个补丁,是开源社区做出巨大贡献的结晶,在Python和SQL功能方面带来了重大进展并且将重点聚焦在了开发和生产的易用性上。同时,今年也是Spark开源10周年,这些举措反映了Spark自开源以来,是如何不断的满足更广泛的受众需求以及更多的应用场景。
首先来看一下Apache Spark 3.0.0主要的新特性:
- 在TPC-DS基准测试中,通过启用自适应查询执行、动态分区裁剪等其他优化措施,相比于Spark 2.4,性能提升了2倍
- 兼容ANSI SQL
- 对pandas API的重大改进,包括python类型hints及其他的pandas UDFs
- 简化了Pyspark异常,更好的处理Python error
- structured streaming的新UI
- 在调用R语言的UDF方面,速度提升了40倍
- 超过3400个Jira问题被解决,这些问题在Spark各个核心组件中分布情况如下图:

此外,采用Spark3.0版本,主要代码并没有发生改变。
改进的Spark SQL引擎
Spark SQL是支持大多数Spark应用的引擎。例如,在Databricks,超过 90%的Spark API调用使用了DataFrame、Dataset和SQL API及通过SQL优化器优化的其他lib包。这意味着即使是Python和Scala开发人员也通过Spark SQL引擎处理他们的大部分工作。
如下图所示,Spark3.0在整个runtime,性能表现大概是Spark2.4的2倍:
接下来,我们将介绍Spark SQL引擎的新特性。
即使由于缺乏或者不准确的数据统计信息和对成本的错误估算导致生成的初始计划不理想,但是自适应查询执行(Adaptive Query Execution)通过在运行时对查询执行计划进行优化,允许Spark Planner在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化,从而提升性能。
由于Spark数据存储和计算是分离的,因此无法预测数据的到达。基于这些原因,对于Spark来说,在运行时自适应显得尤为重要。AQE目前提供了三个主要的自适应优化:
- 动态合并shuffle partitions
可以简化甚至避免调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。
- 动态调整join策略
在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行次优计划的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能
- 动态优化倾斜的join(skew joins)
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
基于3TB的TPC-DS基准测试中,与不使用AQE相比,使用AQE的Spark将两个查询的性能提升了1.5倍以上,对于另外37个查询的性能提升超过了1.1倍。

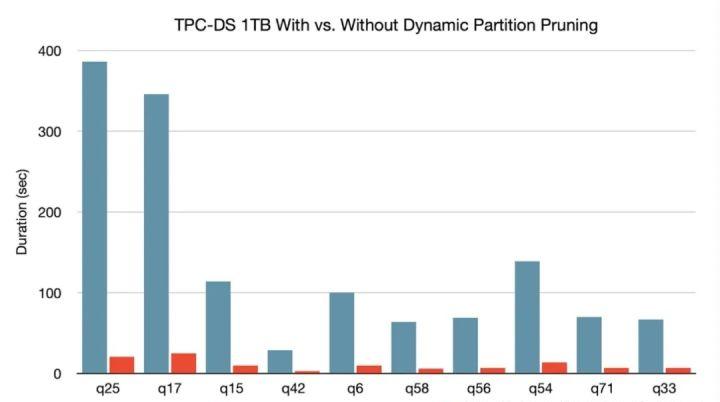
动态分区裁剪
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。在一个TPC-DS基准测试中,102个查询中有60个查询获得2到18倍的速度提升。
更多动态分区裁剪介绍可参考:https://databricks.com/session_eu19/dynamic-partition-pruning-in-apache-spark#:~:text=Dynamic%20partition%20pruning%20occurs%20when,any%20number%20of%20dimension%20tables
ANSI SQL兼容性
对于将工作负载从其他SQL引擎迁移到Spark SQL来说至关重要。为了提升兼容性,该版本采用Proleptic Gregorian日历,用户可以禁止使用ANSI SQL的保留关键字作为标识符。此外,在数字类型的操作中,引入运行时溢出检查,并在将数据插入具有预定义schema的表时引入了编译时类型强制检查,这些新的校验机制提高了数据的质量。更多ASNI兼容性介绍,可参考:https://spark.apache.org/docs/3.0.0/sql-ref-ansi-compliance.html
Join hints
尽管社区一直在改进编译器,但仍然不能保证编译器可以在任何场景下做出最优决策——join算法的选择是基于统计和启发式算法。当编译器无法做出最佳选择时,用户可以使用join hints来影响优化器以便让它选择更好的计划。
Apache Spark 3.0对已存在的join hints进行扩展,主要是通过添加新的hints方式来进行的,包括:
SHUFFLE_MERGE、SHUFFLE_HASH和SHUFFLE_REPLICATE_NL。
增强的Python API:PySpark和Koalas
Python现在是Spark中使用较为广泛的编程语言,因此也是Spark 3.0的重点关注领域。Databricks有68%的notebook命令是用Python写的。PySpark在 Python Package Index上的月下载量超过 500 万。

很多Python开发人员在数据结构和数据分析方面使用pandas API,但仅限于单节点处理。Databricks会持续开发Koalas——基于Apache Spark的pandas API实现,让数据科学家能够在分布式环境中更高效地处理大数据。
通过使用Koalas,在PySpark中,数据科学家们就不需要构建很多函数(例如,绘图支持),从而在整个集群中获得更高性能。
经过一年多的开发,Koalas实现对pandas API将近80%的覆盖率。Koalas每月PyPI下载量已迅速增长到85万,并以每两周一次的发布节奏快速演进。虽然Koalas可能是从单节点pandas代码迁移的最简单方法,但很多人仍在使用PySpark API,也意味着PySpark API也越来越受欢迎。
Spark 3.0为PySpark API做了多个增强功能:
- 带有类型提示的新pandas API
pandas UDF最初是在Spark 2.3中引入的,用于扩展PySpark中的用户定义函数,并将pandas API集成到PySpark应用中。但是,随着UDF类型的增多,现有接口就变得难以理解。该版本引入了一个新的pandas UDF接口,利用Python的类型提示来解决pandas UDF类型激增的问题。新接口变得更具Python风格化和自我描述性。 - 新的pandas UDF类型和pandas函数API
该版本增加了两种新的pandas UDF类型,即系列迭代器到系列迭代器和多个系列迭代器到系列迭代器。这对于数据预取和昂贵的初始化操作来说非常有用。此外,该版本还添加了两个新的pandas函数API,map和co-grouped map。更多详细信息请参考:https://databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html。 - 更好的错误处理
对于Python用户来说,PySpark的错误处理并不友好。该版本简化了PySpark异常,隐藏了不必要的JVM堆栈跟踪信息,并更具Python风格化。
改进Spark中的Python支持和可用性仍然是我们最优先考虑的问题之一。
Hydrogen、流和可扩展性
Spark 3.0完成了Hydrogen项目的关键组件,并引入了新功能来改善流和可扩展性。
- 加速器感知调度
Hydrogen项目旨在更好地统一基于Spark的深度学习和数据处理。GPU和其他加速器已经被广泛用于加速深度学习工作负载。为了使Spark能够利用目标平台上的硬件加速器,该版本增强了已有的调度程序,使集群管理器可以感知到加速器。用户可以通过配置来指定加速器(详细配置介绍可参考:https://spark.apache.org/docs/3.0.0/configuration.html#custom-resource-scheduling-and-configuration-overview)。然后,用户可以调用新的RDD API来利用这些加速器。
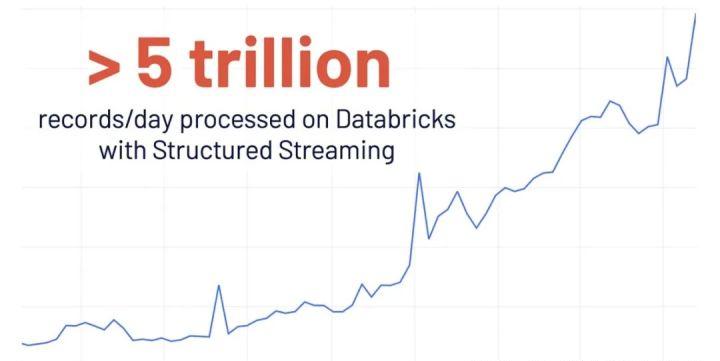
- 结构化流的新UI
结构化流最初是在Spark 2.0中引入的。在Databricks,使用量同比增长4倍后,每天使用结构化流处理的记录超过了5万亿条。
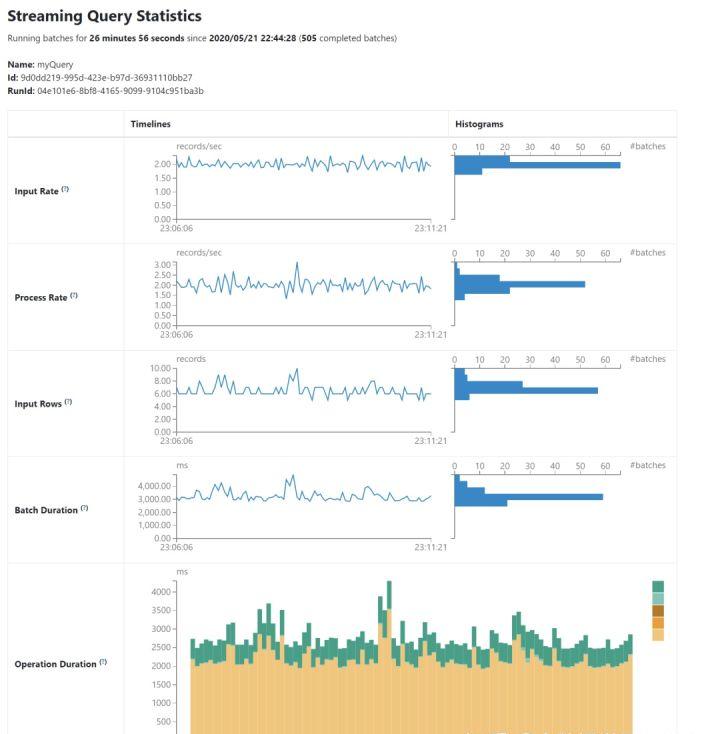
Apache Spark添加了一个专门的新Spark UI用于查看流jobs。新UI提供了两组统计信息:
- 流查询作业已完成的聚合信息
- 流查询的详细统计信息,包括Input Rate, Process Rate, Input Rows, Batch Duration, Operation Duration等
- 可观察的指标
持续监控数据质量变化是管理数据管道的一种重要功能。Spark
3.0引入了对批处理和流应用程序的功能监控。可观察的指标是可以在查询上定义的聚合函数(DataFrame)。一旦DataFrame执行达到一个完成点(如,完成批查询)后会发出一个事件,该事件包含了自上一个完成点以来处理的数据的指标信息。
- 新的目录插件API
现有的数据源API缺乏访问和操作外部数据源元数据的能力。新版本增强了数据源V2 API,并引入了新的目录插件API。对于同时实现了目录插件API和数据源V2 API的外部数据源,用户可以通过标识符直接操作外部表的数据和元数据(在相应的外部目录注册了之后)。
Spark 3.0的其他更新
Spark 3.0是社区的一个重要版本,解决了超过3400个Jira问题,这是440多个contributors共同努力的结果,这些contributors包括个人以及来自Databricks、谷歌、微软、英特尔、IBM、阿里巴巴、Facebook、英伟达、Netflix、Adobe等公司的员工。
在这篇博文中,我们重点介绍了Spark在SQL、Python和流技术方面的关键改进。
除此之外,作为里程碑的Spark 3.0版本还有很多其他改进功能在这里没有介绍。发行文档中提供了更多详尽的本次版本的改进信息,包括数据源、生态系统、监控等。

最后,热烈祝贺Spark开源发展10周年!
Spark诞生于UC
Berkeley’s
AMPlab,该实验室致力于数据密集型计算的研究。AMPLab研究人员与大型互联网公司合作,致力于解决数据和AI问题。但是他们发现,对于那些那些拥有海量数据并且数据不断增长的公司同样面临类似的问题需要解决。于是,该团队研发了一个新引擎来处理这些新兴的工作负载,同时使处理数据的APIs,对于开发人员更方便使用。
社区很快将Spark扩展到不同领域,在流、Python和SQL方面提供了新功能,并且这些模式现在已经构成了Spark的一些主要用例。作为数据处理、数据科学、机器学习和数据分析工作负载事实上的引擎,持续不断的投入成就了Spark的今天。Apache Spark 3.0通过对SQL和Python(如今使用Spark的两种最广泛的语言)支持的显著改进,以及对性能、可操作性等方面的优化,延续了这种趋势。
附英文说明:
Spark Release 3.0.0
Apache Spark 3.0.0 is the first release of the 3.x line. The vote
passed on the 10th of June, 2020. This release is based on git tag v3.0.0
which includes all commits up to June 10. Apache Spark 3.0 builds on
many of the innovations from Spark 2.x, bringing new ideas as well as
continuing long-term projects that have been in development. With the
help of tremendous contributions from the open-source community, this
release resolved more than 3400 tickets as the result of contributions
from over 440 contributors.
This year is Spark’s 10-year anniversary as an open source project. Since its initial release in 2010, Spark has grown to be one of the most active open source projects. Nowadays, Spark is the de facto unified engine for big data processing, data science, machine learning and data analytics workloads.
Spark SQL is the top active component in this release. 46% of the resolved tickets are for Spark SQL. These enhancements benefit all the higher-level libraries, including structured streaming and MLlib, and higher level APIs, including SQL and DataFrames. Various related optimizations are added in this release. In TPC-DS 30TB benchmark, Spark 3.0 is roughly two times faster than Spark 2.4.
Python is now the most widely used language on Spark. PySpark has more than 5 million monthly downloads on PyPI, the Python Package Index. This release improves its functionalities and usability, including the pandas UDF API redesign with Python type hints, new pandas UDF types, and more Pythonic error handling.
Here are the feature highlights in Spark 3.0: adaptive query execution; dynamic partition pruning; ANSI SQL compliance; significant improvements in pandas APIs; new UI for structured streaming; up to 40x speedups for calling R user-defined functions; accelerator-aware scheduler; and SQL reference documentation.
To download Apache Spark 3.0.0, visit the downloads page. You can consult JIRA for the detailed changes. We have curated a list of high level changes here, grouped by major modules.
- Core, Spark SQL, Structured Streaming
- MLlib
- SparkR
- GraphX
- Deprecations
- Known Issues
- Credits
Core, Spark SQL, Structured Streaming
Highlight
- [Project Hydrogen] Accelerator-aware Scheduler (SPARK-24615)
- Adaptive Query Execution (SPARK-31412)
- Dynamic Partition Pruning (SPARK-11150)
- Redesigned pandas UDF API with type hints (SPARK-28264)
- Structured Streaming UI (SPARK-29543)
- Catalog plugin API (SPARK-31121)
- Java 11 support (SPARK-24417)
- Hadoop 3 support (SPARK-23534)
- Better ANSI SQL compatibility
Performance Enhancements
- Adaptive Query Execution (SPARK-31412)
- Basic framework (SPARK-23128)
- Post shuffle partition number adjustment (SPARK-28177)
- Dynamic subquery reuse (SPARK-28753)
- Local shuffle reader (SPARK-28560)
- Skew join optimization (SPARK-29544)
- Optimize reading contiguous shuffle blocks (SPARK-9853)
- Dynamic Partition Pruning (SPARK-11150)
- Other optimizer rules
- Rule TransposeWindow (SPARK-20636)
- Rule ReuseSubquery (SPARK-27279)
- Rule PushDownLeftSemiAntiJoin (SPARK-19712)
- Rule PushLeftSemiLeftAntiThroughJoin (SPARK-19712)
- Rule ReplaceNullWithFalse (SPARK-25860)
- Rule Eliminate sorts without limit in the subquery of Join/Aggregation (SPARK-29343)
- Rule PruneHiveTablePartitions (SPARK-15616)
- Pruning unnecessary nested fields from Generate (SPARK-27707)
- Rule RewriteNonCorrelatedExists (SPARK-29800)
- Minimize table cache synchronization costs (SPARK-26917, SPARK-26617, SPARK-26548)
- Split aggregation code into small functions (SPARK-21870)
- Add batching in INSERT and ALTER TABLE ADD PARTITION command (SPARK-29938)
- Allows Aggregator to be registered as a UDAF (SPARK-27296)
SQL Compatibility Enhancements
- Switch to Proleptic Gregorian calendar (SPARK-26651)
- Build Spark’s own datetime pattern definition (SPARK-31408)
- Introduce ANSI store assignment policy for table insertion (SPARK-28495)
- Follow ANSI store assignment rule in table insertion by default (SPARK-28885)
- Add a SQLConf
spark.sql.ansi.enabled(SPARK-28989) - Support ANSI SQL filter clause for aggregate expression (SPARK-27986)
- Support ANSI SQL OVERLAY function (SPARK-28077)
- Support ANSI nested bracketed comments (SPARK-28880)
- Throw exception on overflow for integers (SPARK-26218)
- Overflow check for interval arithmetic operations (SPARK-30341)
- Throw Exception when invalid string is cast to numeric type (SPARK-30292)
- Make interval multiply and divide’s overflow behavior consistent with other operations (SPARK-30919)
- Add ANSI type aliases for char and decimal (SPARK-29941)
- SQL Parser defines ANSI compliant reserved keywords (SPARK-26215)
- Forbid reserved keywords as identifiers when ANSI mode is on (SPARK-26976)
- Support ANSI SQL: LIKE … ESCAPE syntax (SPARK-28083)
- Support ANSI SQL Boolean-Predicate syntax (SPARK-27924)
- Better support for correlated subquery processing (SPARK-18455)
PySpark Enhancements
- Redesigned pandas UDFs with type hints (SPARK-28264)
- Allow Pandas UDF to take an iterator of pd.DataFrames (SPARK-26412)
- Support StructType as arguments and return types for Scalar Pandas UDF (SPARK-27240 )
- Support Dataframe Cogroup via Pandas UDFs (SPARK-27463)
- Add mapInPandas to allow an iterator of DataFrames (SPARK-28198)
- Certain SQL functions should take column names as well (SPARK-26979)
- Make PySpark SQL exceptions more Pythonic (SPARK-31849)
Extensibility Enhancements
- Catalog plugin API (SPARK-31121)
- Data source V2 API refactoring (SPARK-25390)
- Hive 3.0 and 3.1 metastore support (SPARK-27970, SPARK-24360)
- Extend Spark plugin interface to driver (SPARK-29396)
- Extend Spark metrics system with user-defined metrics using executor plugins (SPARK-28091)
- Developer APIs for extended Columnar Processing Support (SPARK-27396)
- Built-in source migration using DSV2: parquet, ORC, CSV, JSON, Kafka, Text, Avro (SPARK-27589)
- Allow FunctionInjection in SparkExtensions (SPARK-25560)
Connector Enhancements
- Support High Performance S3A committers (SPARK-23977)
- Column pruning through nondeterministic expressions (SPARK-29768)
- Support
spark.sql.statistics.fallBackToHdfsin data source tables (SPARK-25474) - Allow partition pruning with subquery filters on file source (SPARK-26893)
- Avoid pushdown of subqueries in data source filters (SPARK-25482)
- Recursive data loading from file sources (SPARK-27990)
- Parquet/ORC
- Support merge schema for ORC (SPARK-11412)
- Nested schema pruning for ORC (SPARK-27034)
- Predicate conversion complexity reduction for ORC (SPARK-27105, SPARK-28108)
- Upgrade Apache ORC to 1.5.9 (SPARK-30695)
- Parquet predicate pushdown for nested fields (SPARK-17636)
- Pushdown of disjunctive predicates (SPARK-27699)
- Generalize Nested Column Pruning (SPARK-25603) and turned on by default (SPARK-29805)
- Parquet Only
- ORC Only
- CSV
- Support filters pushdown in CSV datasource (SPARK-30323)
- Hive Serde
- No schema inference when reading Hive serde table with native data source (SPARK-27119)
- Hive CTAS commands should use data source if it is convertible (SPARK-25271)
- Use native data source to optimize inserting partitioned Hive table (SPARK-28573)
- Kafka
- Add support for Kafka headers (SPARK-23539)
- Add Kafka delegation token support (SPARK-25501)
- Introduce new option to Kafka source: offset by timestamp (starting/ending) (SPARK-26848)
- Support the “minPartitions” option in Kafka batch source and streaming source v1 (SPARK-30656)
- Upgrade Kafka to 2.4.1 (SPARK-31126)
- New built-in data sources
- New build-in binary file data sources (SPARK-25348)
- New no-op batch data sources (SPARK-26550) and no-op streaming sink (SPARK-26649)
Feature Enhancements
- [Hydrogen] Accelerator-aware Scheduler (SPARK-24615)
- Introduce a complete set of Join Hints (SPARK-27225)
- Add PARTITION BY hint for SQL queries (SPARK-28746)
- Metadata Handling in Thrift Server (SPARK-28426)
- Add higher order functions to scala API (SPARK-27297)
- Support simple all gather in barrier task context (SPARK-30667)
- Hive UDFs supports the UDT type (SPARK-28158)
- Support DELETE/UPDATE/MERGE Operators in Catalyst (SPARK-28351, SPARK-28892, SPARK-28893)
- Implement DataFrame.tail (SPARK-30185)
- New built-in functions
- sinh, cosh, tanh, asinh, acosh, atanh (SPARK-28133)
- any, every, some (SPARK-19851)
- bit_and, bit_or (SPARK-27879)
- bit_count (SPARK-29491)
- bit_xor (SPARK-29545)
- bool_and, bool_or (SPARK-30184)
- count_if (SPARK-27425)
- date_part (SPARK-28690)
- extract (SPARK-23903)
- forall (SPARK-27905)
- from_csv (SPARK-25393)
- make_date (SPARK-28432)
- make_interval (SPARK-29393)
- make_timestamp (SPARK-28459)
- map_entries (SPARK-23935)
- map_filter (SPARK-23937)
- map_zip_with (SPARK-23938)
- max_by, min_by (SPARK-27653)
- schema_of_csv (SPARK-25672)
- to_csv (SPARK-25638)
- transform_keys (SPARK-23939)
- transform_values (SPARK-23940)
- typeof (SPARK-29961)
- version (SPARK-29554)
- xxhash64 (SPARK-27099)
- Improvements on the existing built-in functions
- built-in date-time functions/operations improvement (SPARK-31415)
- Support FAILFAST mode for from_json (SPARK-25243)
- array_sort adds a new comparator parameter (SPARK-29020)
- filter can now take the index as input as well as the element (SPARK-28962)
Monitoring and Debuggability Enhancements
- New Structured Streaming UI (SPARK-29543)
- SHS: Allow event logs for running streaming apps to be rolled over (SPARK-28594)
- JDBC tab in SHS (SPARK-29724, SPARK-29726)
- Add an API that allows a user to define and observe arbitrary metrics on batch and streaming queries (SPARK-29345)
- Instrumentation for tracking per-query planning time (SPARK-26129)
- Put the basic shuffle metrics in the SQL exchange operator (SPARK-26139)
- SQL statement is shown in SQL Tab instead of callsite (SPARK-27045)
- Add tooltip to SparkUI (SPARK-29449)
- Improve the concurrent performance of History Server (SPARK-29043)
- EXPLAIN FORMATTED command (SPARK-27395)
- Support Dumping truncated plans and generated code to a file (SPARK-26023)
- Enhance describe framework to describe the output of a query (SPARK-26982)
- Add SHOW VIEWS command (SPARK-31113)
- Improve the error messages of SQL parser (SPARK-27901)
- Support Prometheus monitoring natively (SPARK-29429)
- Add executor memory metrics to heartbeat and expose in executors REST API (SPARK-23429)
- Add Executor metrics and memory usage instrumentation to the metrics system (SPARK-27189)
Documentation and Test Coverage Enhancements
- Build a SQL Reference (SPARK-28588)
- Build a user guide for WebUI (SPARK-28372)
- Build a page for SQL configuration documentation (SPARK-30510)
- Add version information for Spark configuration (SPARK-30839)
- Port regression tests from PostgreSQL (SPARK-27763)
- Thrift-server test coverage (SPARK-28608)
- Test coverage of UDFs (python UDF, pandas UDF, scala UDF) (SPARK-27921)
Native Spark App in Kubernetes
- Support user-specified driver and executor pod templates (SPARK-24434)
- Allow dynamic allocation without an external shuffle service (SPARK-27963)
- More responsive dynamic allocation with K8S (SPARK-28487)
- Kerberos Support for Spark on K8S (SPARK-23257)
- Kerberos Support in Kubernetes resource manager (Client Mode) (SPARK-25815)
- Support client dependencies with a Hadoop Compatible File System (SPARK-23153)
- Add configurable auth secret source in k8s backend (SPARK-26239)
- Support subpath mounting with Kubernetes (SPARK-25960)
- Make Python 3 the default in PySpark Bindings for K8S (SPARK-24516)
Other Notable Changes
- Java 11 support (SPARK-24417)
- Hadoop 3 support (SPARK-23534)
- Built-in Hive execution upgrade from 1.2.1 to 2.3.7 (SPARK-23710, SPARK-28723, SPARK-31381)
- Use Apache Hive 2.3 dependency by default (SPARK-30034)
- GA Scala 2.12 and remove 2.11 (SPARK-26132)
- Improve logic for timing out executors in dynamic allocation (SPARK-20286)
- Disk-persisted RDD blocks served by shuffle service, and ignored for Dynamic Allocation (SPARK-27677)
- Acquire new executors to avoid hang because of blacklisting (SPARK-22148)
- Allow sharing Netty’s memory pool allocators (SPARK-24920)
- Fix deadlock between TaskMemoryManager and UnsafeExternalSorter$SpillableIterator (SPARK-27338)
- Introduce AdmissionControl APIs for StructuredStreaming (SPARK-30669)
- Spark History Main page performance improvement (SPARK-25973)
- Speed up and slim down metric aggregation in SQL listener (SPARK-29562)
- Avoid the network when shuffle blocks are fetched from the same host (SPARK-27651)
- Improve file listing for DistributedFileSystem (SPARK-27801)
- Remove Support for hadoop 2.6 (SPARK-25016)
Changes of behavior
Please read the migration guides for each component: Spark Core, Spark SQL, Structured Streaming and PySpark.
A few other behavior changes that are missed in the migration guide:
- In Spark 3.0, the deprecated class
org.apache.spark.sql.streaming.ProcessingTimehas been removed. Useorg.apache.spark.sql.streaming.Trigger.ProcessingTimeinstead. Likewise,org.apache.spark.sql.execution.streaming.continuous.ContinuousTriggerhas been removed in favor ofTrigger.Continuous, andorg.apache.spark.sql.execution.streaming.OneTimeTriggerhas been hidden in favor ofTrigger.Once. (SPARK-28199) - Due to the upgrade of Scala 2.12,
DataStreamWriter.foreachBatchis not source compatible for Scala program. You need to update your Scala source code to disambiguate between Scala function and Java lambda. (SPARK-26132)
Programming guides: Spark RDD Programming Guide and Spark SQL, DataFrames and Datasets Guide and Structured Streaming Programming Guide.
MLlib
Highlight
- Multiple columns support was added to Binarizer (SPARK-23578), StringIndexer (SPARK-11215), StopWordsRemover (SPARK-29808) and PySpark QuantileDiscretizer (SPARK-22796)
- Support Tree-Based Feature Transformation(SPARK-13677)
- Two new evaluators MultilabelClassificationEvaluator (SPARK-16692) and RankingEvaluator (SPARK-28045) were added
- Sample weights support was added in DecisionTreeClassifier/Regressor (SPARK-19591), RandomForestClassifier/Regressor (SPARK-9478), GBTClassifier/Regressor (SPARK-9612), RegressionEvaluator (SPARK-24102), BinaryClassificationEvaluator (SPARK-24103), BisectingKMeans (SPARK-30351), KMeans (SPARK-29967) and GaussianMixture (SPARK-30102)
- R API for PowerIterationClustering was added (SPARK-19827)
- Added Spark ML listener for tracking ML pipeline status (SPARK-23674)
- Fit with validation set was added to Gradient Boosted Trees in Python (SPARK-24333)
- RobustScaler transformer was added (SPARK-28399)
- Factorization Machines classifier and regressor were added (SPARK-29224)
- Gaussian Naive Bayes (SPARK-16872) and Complement Naive Bayes (SPARK-29942) were added
- ML function parity between Scala and Python (SPARK-28958)
- predictRaw is made public in all the Classification models. predictProbability is made public in all the Classification models except LinearSVCModel (SPARK-30358)
Changes of behavior
Please read the migration guide for details.
A few other behavior changes that are missed in the migration guide:
- In Spark 3.0, a multiclass logistic regression in Pyspark will now (correctly) return LogisticRegressionSummary, not the subclass BinaryLogisticRegressionSummary. The additional methods exposed by BinaryLogisticRegressionSummary would not work in this case anyway. (SPARK-31681)
- In Spark 3.0, pyspark.ml.param.shared.Has* mixins do not provide any set(self, value) setter methods anymore, use the respective self.set(self., value) instead. See SPARK-29093 for details. (SPARK-29093)
Programming guide: Machine Learning Library (MLlib) Guide.
SparkR
- Arrow optimization in SparkR’s interoperability (SPARK-26759)
- Performance enhancement via vectorized R gapply(), dapply(), createDataFrame, collect()
- “eager execution” for R shell, IDE (SPARK-24572)
- R API for Power Iteration Clustering (SPARK-19827)
Changes of behavior
Please read the migration guide for details.
Programming guide: SparkR (R on Spark).
GraphX
Programming guide: GraphX Programming Guide.
Deprecations
- Deprecate Python 2 support (SPARK-27884)
- Deprecate R < 3.4 support (SPARK-26014)
- Deprecate UserDefinedAggregateFunction (Spark-30423)
Known Issues
- Streaming queries with
dropDuplicatesoperator may not be able to restart with the checkpoint written by Spark 2.x. This will be fixed in Spark 3.0.1. (SPARK-31990) - In Web UI, the job list page may hang for more than 40 seconds. This will be fixed in Spark 3.0.1. (SPARK-31967)
- Set
io.netty.tryReflectionSetAccessiblefor Arrow on JDK9+ (SPARK-29923) - With AWS SDK upgrade to 1.11.655, we strongly encourage the users
that use S3N file system (open-source NativeS3FileSystem that is based
on jets3t library) on Hadoop 2.7.3 to upgrade to use AWS Signature V4
and set the bucket endpoint or migrate to S3A (“s3a://” prefix) - jets3t
library uses AWS v2 by default and s3.amazonaws.com as an endpoint.
Otherwise, the 403 Forbidden error may be thrown in the following cases:
Note that if you use S3AFileSystem, e.g. (“s3a://bucket/path”) to access S3 in S3Select or SQS connectors, then everything will work as expected. (SPARK-30968)
- If a user accesses an S3 path that contains “+” characters and uses the legacy S3N file system, e.g. s3n://bucket/path/+file.
- If a user has configured AWS V2 signature to sign requests to S3 with S3N file system.
- Parsing day of year using pattern letter ‘D’ returns the wrong
result if the year field is missing. This can happen in SQL functions
like
to_timestampwhich parses datetime string to datetime values using a pattern string. This will be fixed in Spark 3.0.1. (SPARK-31939) - Join/Window/Aggregate inside subqueries may lead to wrong results if the keys have values -0.0 and 0.0. This will be fixed in Spark 3.0.1. (SPARK-31958)
- A window query may fail with ambiguous self-join error unexpectedly. This will be fixed in Spark 3.0.1. (SPARK-31956)
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java