CACHE FUSION 原理
前面已经介绍了 RAC 的后台进程,为了更深入的了解这些后台进程的工作原理,先了解一下 RAC 中多节点对共享数据文件访问的管理是如何进行的。要了解 RAC 工作原理的中心,需要知道 Cache Fusion 这个重要的概念,要发挥 Cache Fusion 的作用,要有一个前提条件,那就是互联网络的速度要比访问磁盘的速度要快。否则,没有引入 CACHE FUSION 的意义。而事实上,现在 100MB 的互联网都很常见。
什么是 CACHE FUSION?
Cache Fusion 就是通过互联网络(高速的 Private interconnect)在集群内各节点的 SGA 之间进行块传递,这是RAC最核心的工作机制,他把所有实例的SGA虚拟成一个大的SGA区,每当不同的实例请求相同的数据块时,这个数据块就通过 Private interconnect 在实例间进行传递。以避免首先将块推送到磁盘,然后再重新读入其他实例的缓存中这样一种低效的实现方式(OPS 的实现)。当一个块被读入 RAC 环境中某个实例的缓存时,该块会被赋予一个锁资源(与行级锁不同),以确保其他实例知道该块正在被使用。之后,如果另一个实例请求该块的一个副本,而该块已经处于前一个实例的缓存内,那么该块会通过互联网络直接被传递到另一个实例的 SGA。如果内存中的块已经被改变,但改变尚未提交,那么将会传递一个 CR 副本。这就意味着只要可能,数据块无需写回磁盘即可在各实例的缓存之间移动,从而避免了同步多实例的缓存所花费的额外 I/O。很明显,不同的实例缓存的数据可以是不同的,也就是在一个实例要访问特定块之前,而它又从未访问过这个块,那么它要么从其他实例 cache fusion 过来,或者从磁盘中读入。GCS(Global Cache Service,全局内存服务)和 GES(Global EnquenceService,全局队列服务)进程管理使用集群节点之间的数据块同步互联。
这里还是有一些问题需要思考的:
- 在所有实例都未读取该块,而第一个实例读取时,是怎么加的锁,加的什么锁?如果此时有另一个实例也要读这个块,几乎是同时的,那么 Oracle 如何来仲裁,如何让其中一个读取,而另一个再从前者的缓存中通过 cache 来得到?
- 如果一个块已经被其他实例读入,那么本实例如何判断它的存在?
- 如果某个实例改变了这个数据块,是否会将改变传递到其他实例,或者说其他实例是否会知道并重新更新状态?
- 如果一个实例要 swap out 某个块,而同时其他实例也有这个块的缓存,修改过的和未修改过的,本实例修改的和其他实例修改的,如何操作? truncate 一张表,drop 一张表... 和单实例有何不同?
- 应该如何设计应用,以使 RAC 真正发挥作用,而不是引入竞争,导致系统被削弱?
- RAC 下锁的实现。
锁是在各实例的 SGA 中保留的资源,通常被用于控制对数据库块的访问。每个实例通常会保留或控制一定数量与块范围相关的锁。当一个实例请求一个块时,该块必须获得一个锁,并且锁必须来自当前控制这些锁的实例。也就是锁被分布在不同的实例上。而要获得特定的锁要从不同的实例上去获得。但是从这个过程来看这些锁不是固定在某个实例上的,而是根据锁的请求频率会被调整到使用最频繁的实例上,从而提高效率。要实现这些资源的分配和重分配、控制,这是很耗用资源的。这也决定了 RAC 的应用设计要求比较高。假设某个实例崩溃或者某个实例加入,那么这里要有一个比较长的再分配资源和处理过程。在都正常运行的情况下会重新分配,以更加有效的使用资源;在实例推出或加入时也会重新分配。在 alert 文件中可以看到这些信息。而 Cache Fusion 及其他资源的分配控制,要求有一个快速的互联网络,所以要关注与互联网络上消息相关的度量,以测试互联网络的通信量和相应时间。对于前面的一些问题,可以结合另外的概念来学习,它们是全局缓存服务和全局队列服务。
全局缓存服务(GCS):要和 Cache Fusion 结合在一起来理解。全局缓存要涉及到数据块。全局缓存服务负责维护该全局缓冲存储区内的缓存一致性,确保一个实例在任何时刻想修改一个数据块时,都可获得一个全局锁资源,从而避免另一个实例同时修改该块的可能性。进行修改的实例将拥有块的当前版本(包括已提交的和未提交的事物)以及块的前象(post image)。如果另一个实例也请求该块,那么全局缓存服务要负责跟踪拥有该块的实例、拥有块的版本是什么,以及块处于何种模式。LMS 进程是全局缓存服务的关键组成部分。
猜想:Oracle 目前的 cache fusion 是在其他实例访问时会将块传输过去再构建一个块在那个实例的 SGA 中,这个主要的原因可能是 interconnect 之间的访问还是从本地内存中访问更快,从而让 Oracle 再次访问时可以从本地内存快速获取。但是这也有麻烦的地方,因为在多个节点中会有数据块的多个 copy,这样在管理上的消耗是很可观的,Oracle 是否会有更好的解决方案出现在后续版本中?如果 interconnect 速度允许的话...)
全局队列服务(GES):主要负责维护字典缓存和库缓存内的一致性。字典缓存是实例的 SGA 内所存储的对数据字典信息的缓存,用于高速访问。由于该字典信息存储在内存中,因而在某个节点上对字典进行的修改(如DDL)必须立即被传播至所有节点上的字典缓存。GES 负责处理上述情况,并消除实例间出现的差异。处于同样的原因,为了分析影响这些对象的 SQL 语句,数据库内对象上的库缓存锁会被去掉。这些锁必须在实例间进行维护,而全局队列服务必须确保请求访问相同对象的多个实例间不会出现死锁。LMON、LCK 和 LMD 进程联合工作来实现全局队列服务的功能。GES 是除了数据块本身的维护和管理(由 GCS 完成)之外,在 RAC 环境中调节节点间其他资源的重要服务。
SQL> select * from gv$sysstat where name like 'gcs %'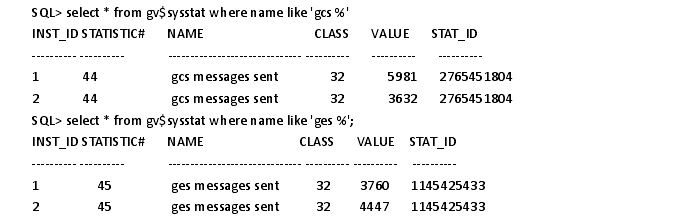
这里可以看到 gcs 和 ges 消息的发送个数。(如果没有使用 DBCA 来创建数据库,那么要 SYSDBA 权限来运行CATCLUST.SQL 脚本来创建 RAC 相关的视图和表)
什么是高可用
Oracle failsafe、Data Guard 和 RAC 均为 ORACLE 公司提供的高可靠性(HA)解决方案。然而之三者之间却存在着很大区别。
HA 是 High Availability 的首字母组合,翻译过来,可以叫做高可用,或高可用性,高可用(环境)。我觉得应该说 HA 是一个观念而不是一项或一系列具体技术,就象网格一样。作过系统方案就知道了,评价系统的性能当中就有一项高可用。也就是 OS 一级的双机热备。RAC 是 real application cluster 的简称,它是在多个主机上运行一个数据库的技术,即是一个 db 多个 instance。它的好处是 可以由多个性能较差的机器构建出一个整体性能很好的集群,并且实现了负载均衡,那么当一个节点出现故障时,其上的服务会自动转到另外的节点去执行,用户甚 至感觉不到什么。
FAILSAFE 和 RAC 的区别
操作系统
failsafe 系统局限于 WINDOWS 平台,必须配合 MSCS(microsoft cluster server),而 RAC 最早是在 UNIX 平台推出的,目前已扩展至 LINUX 和 WINDOWS 平台,通过 OSD(operating system dependent)与系统交互。对于高端的 RAC 应用,UNIX 依然是首选的平台。
系统结构
FAILSAFE 采用的是 SHARE NOTHING 结构,即采用若干台服务器组成集群,共同连接到一个共享磁盘系统,在同一时刻,只有一台服务器能够访问共享磁盘,能够对外提供服务。只要当此服务器失效时,才有另一台接管共享磁盘。RAC 则是采用 SHARE EVERYTHING,组成集群的每一台服务器都可以访问共享磁盘,都能对外提供服务。也就是说 FAILSAFE 只能利用一台服务器资源,RAC 可以并行利用多台服务器资源。
运行机理
组成 FAILSAFE 集群的每台 SERVER 有独立的 IP,整个集群又有一个 IP,另外还为 FAILSAFE GROUP 分配一个单独的 IP(后两个 IP 为虚拟 IP,对于客户来说,只需知道集群 IP,就可以透明访问数据库)。工作期间,只有一台服务器(preferred or owner or manager)对外提供服务,其余服务器(operator)成待命状,当前者失效时,另一服务器就会接管前者,包括FAILSAFE GROUP IP与CLUSTER IP,同时FAILSAFE会启动上面的DATABASE SERVICE,LISTENER 和其他服务。客户只要重新连接即可,不需要做任何改动。对于 RAC 组成的集群,每台服务器都分别有自已的 IP,INSTANCE 等,可以单独对外提供服务,只不过它们都是操作位于共享磁盘上的同一个数据库。当某台服务器失效后,用户只要修改网络配置,如(TNSNAMES。ORA),即可重新连接到仍在正常运行的服务器上。但和 TAF 结合使用时,甚至网络也可配置成透明的。
集群容量
前者通常为两台,后者在一些平台上能扩展至 8 台。
分区
FAILSAFE 数据库所在的磁盘必须是 NTFS 格式的,RAC 则相对灵活,通常要求是 RAW,然而若干 OS 已操作出了 CLUSTER 文件系统可以供 RAC 直接使用。
综上所述,FAILSAFE 比较适合一个可靠性要求很高,应用相对较小,对高性能要求相对不高的系统,而 RAC则更适合可靠性、扩展性、性能要求都相对较高的较大型的应用。
RAC 和 OPS 区别
RAC 是 OPS 的后继版本,继承了 OPS 的概念,但是 RAC 是全新的,CACHE 机制和 OPS 完全不同。RAC 解决了 OPS 中 2 个节点同时写同一个 BLOCK 引起的冲突问题。 从产品上来说 RAC 和 OPS 是完全不同的产品,但是我们可以认为是相同产品的不同版本
双机热备、RAC 和 DATA GUARD 的区别
Data Guard 是 Oracle 的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,这是两套硬件配置可以不同的系统,但是这两套系统的软件结构保持一致,包括软件的版本,目录存储结构,以及数据的同步(其实也不是实时同步的),这两套系统之间只要网络是通的就可以了,是一种异地容灾的解决方案。而对于 RAC,则是本地的高可用集群,每个节点用来分担不用或相同的应用,以解决运算效率低下,单节点故障这样的问题,它是几台硬件相同或不相同的服务器,加一个 SAN(共享的存储区域)来构成的。
Oracle 高可用性产品比较见下表:

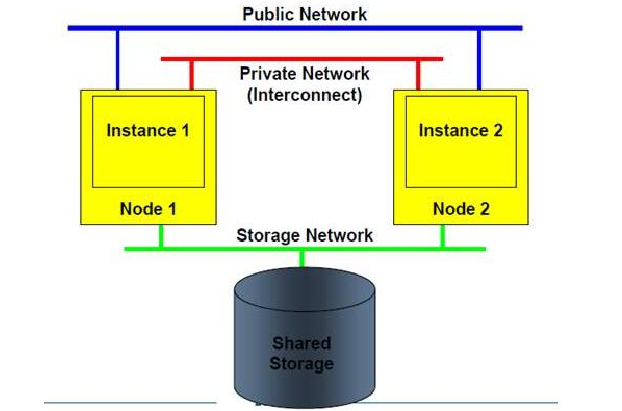
节点间的通信(INTERCONNECT)
通常在 RAC 环境下,在公用网络的基础上,需要配置两条专用的网络用于节点间的互联,在 HACMP/ES 资源的定义中,这两条专用的网络应该被定义为"private" 。在实例启动的过程中,RAC 会自动识别和使用这两条专用的网络,并且如果存在公用"public" 的网络,RAC 会再识别一条公用网络。当 RAC 识别到多条网络时,RAC 会使用 TNFF (Transparent Network Failvoer Failback) 功能,在 TNFF 下所有的节点间通信都通过第一条专用的网络进行,第二条( 或第三条等) 作为在第一条专用的网络失效后的备份。RAC 节点间通信如下图所示。