
本教程源代码目录在book/machine_translation, 初次使用请参考PaddlePaddle安装教程。
背景介绍
机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
早期机器翻译系统多为基于规则的翻译系统,需要由语言学家编写两种语言之间的转换规则,再将这些规则录入计算机。该方法对语言学家的要求非常高,而且我们几乎无法总结一门语言会用到的所有规则,更何况两种甚至更多的语言。因此,传统机器翻译方法面临的主要挑战是无法得到一个完备的规则集合[1]。
为解决以上问题,统计机器翻译(Statistical Machine Translation, SMT)技术应运而生。在统计机器翻译技术中,转化规则是由机器自动从大规模的语料中学习得到的,而非我们人主动提供规则。因此,它克服了基于规则的翻译系统所面临的知识获取瓶颈的问题,但仍然存在许多挑战:
1)人为设计许多特征(feature),但永远无法覆盖所有的语言现象;
2)难以利用全局的特征;
3)依赖于许多预处理环节,如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,而每个环节的错误会逐步累积,对翻译的影响也越来越大。
近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:
1)仍以统计机器翻译系统为框架,只是利用神经网络来改进其中的关键模块,如语言模型、调序模型等(见图1的左半部分);
2)不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端的神经网络机器翻译(End-to-End Neural Machine Translation, End-to-End NMT)(见图1的右半部分),简称为NMT模型。
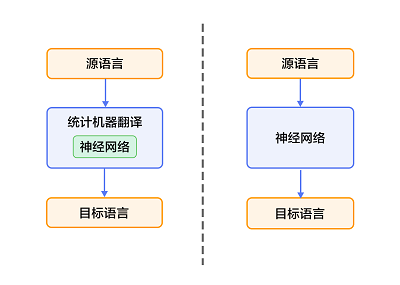
图1. 基于神经网络的机器翻译系统
本教程主要介绍NMT模型,以及如何用PaddlePaddle来训练一个NMT模型。
效果展示
以中英翻译(中文翻译到英文)的模型为例,当模型训练完毕时,如果输入如下已分词的中文句子:
这些 是 希望 的 曙光 和 解脱 的 迹象 .如果设定显示翻译结果的条数(即柱搜索算法的宽度)为3,生成的英语句子如下:
0 -5.36816 These are signs of hope and relief . <e>
1 -6.23177 These are the light of hope and relief . <e>
2 -7.7914 These are the light of hope and the relief of hope . <e> 左起第一列是生成句子的序号;左起第二列是该条句子的得分(从大到小),分值越高越好;左起第三列是生成的英语句子。
另外有两个特殊标志:<e>表示句子的结尾,<unk>表示未登录词(unknown word),即未在训练字典中出现的词。
模型概览
本节依次介绍GRU(Gated Recurrent Unit,门控循环单元),双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架和注意力(Attention)机制,以及柱搜索(beam search)算法。
GRU
我们已经在情感分析一章中介绍了循环神经网络(RNN)及长短时间记忆网络(LSTM)。相比于简单的RNN,LSTM增加了记忆单元(memory cell)、输入门(input gate)、遗忘门(forget gate)及输出门(output gate),这些门及记忆单元组合起来大大提升了RNN处理远距离依赖问题的能力。
GRU[2]是Cho等人在LSTM上提出的简化版本,也是RNN的一种扩展,如下图所示。GRU单元只有两个门:
重置门(reset gate):如果重置门关闭,会忽略掉历史信息,即历史不相干的信息不会影响未来的输出。
更新门(update gate):将LSTM的输入门和遗忘门合并,用于控制历史信息对当前时刻隐层输出的影响。如果更新门接近1,会把历史信息传递下去。
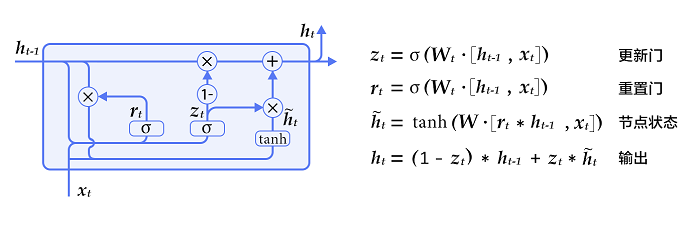
图2. GRU(门控循环单元)
一般来说,具有短距离依赖属性的序列,其重置门比较活跃;相反,具有长距离依赖属性的序列,其更新门比较活跃。另外,Chung等人[3]通过多组实验表明,GRU虽然参数更少,但是在多个任务上都和LSTM有相近的表现。
双向循环神经网络
我们已经在语义角色标注一章中介绍了一种双向循环神经网络,这里介绍Bengio团队在论文[2,4]中提出的另一种结构。该结构的目的是输入一个序列,得到其在每个时刻的特征表示,即输出的每个时刻都用定长向量表示到该时刻的上下文语义信息。
具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵($W_1, W_3$),隐层到隐层自己的权重矩阵($W_2,W_5$),前向隐层和后向隐层到输出层的权重矩阵($W_4, W_6$)。注意,该网络的前向隐层和后向隐层之间没有连接。
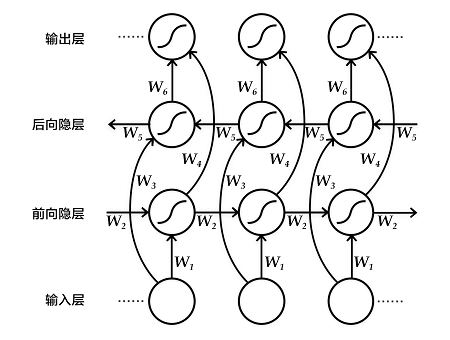
图3. 按时间步展开的双向循环神经网络
编码器-解码器框架
编码器-解码器(Encoder-Decoder)[2]框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
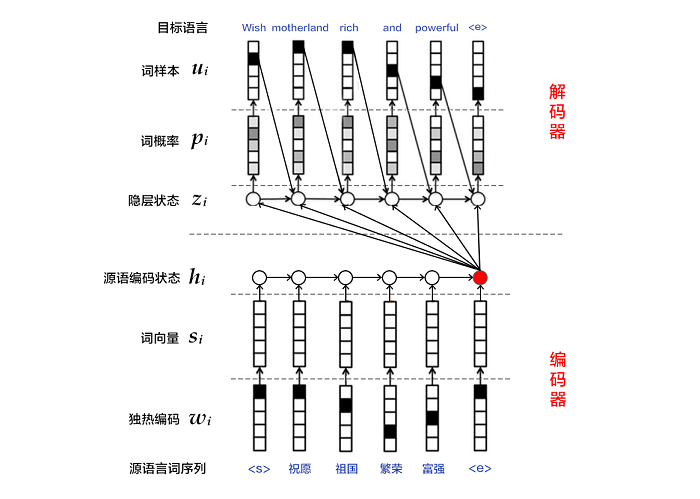
图4. 编码器-解码器框架
编码器
编码阶段分为三步:
1.one-hot vector表示:将源语言句子$x=\left { x_1,x_2,...,x_T \right }$的每个词$x_i$表示成一个列向量$w_i\epsilon \left { 0,1 \right }^{\left | V \right |},i=1,2,...,T$。这个向量$w_i$的维度与词汇表大小$\left | V \right |$ 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
2.映射到低维语义空间的词向量:one-hot vector表示存在两个问题:
1)生成的向量维度往往很大,容易造成维数灾难;
2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。
因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为$C\epsilon R^{K\times \left | V \right |}$,用$s_i=Cw_i$表示第$i$个词的词向量,$K$为向量维度。
3.用RNN编码源语言词序列:这一过程的计算公式为$h_i=\varnothing _\theta \left ( h_{i-1}, s_i \right )$,其中$h_0$是一个全零的向量,$\varnothing _\theta$是一个非线性激活函数,最后得到的$\mathbf{h}=\left { h_1,..., h_T \right }$就是RNN依次读入源语言$T$个词的状态编码序列。整句话的向量表示可以采用$\mathbf{h}$在最后一个时间步$T$的状态编码,或使用时间维上的池化(pooling)结果。
第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列$(x_1,x_2,...,x_T)$的顺序依次编码源语言端词,并得到一系列隐层状态$(\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_T})$。类似的,后向GRU按照$(x_T,x_{T-1},...,x_1)$的顺序依次编码源语言端词,得到$(\overleftarrow{h_1},\overleftarrow{h_2},...,\overleftarrow{h_T})$。最后对于词$x_i$,通过拼接两个GRU的结果得到它的隐层状态,即$h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T}$。
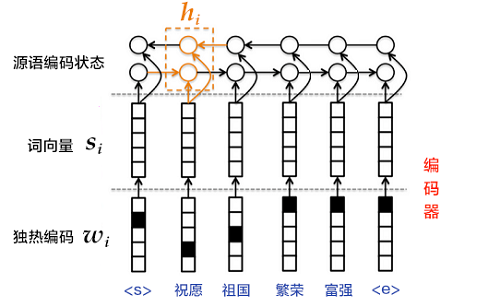
图5. 使用双向GRU的编码器
解码器
机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)$c$、真实目标语言序列的第$i$个词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。计算公式如下:
$$z_{i+1}=\phi _{\theta '}\left ( c,u_i,z_i \right )$$
其中$\phi _{\theta '}$是一个非线性激活函数;$c=q\mathbf{h}$是源语言句子的上下文向量,在不使用注意力机制时,如果编码器的输出是源语言句子编码后的最后一个元素,则可以定义$c=h_T$;$u_i$是目标语言序列的第$i$个单词,$u_0$是目标语言序列的开始标记<s>,表示解码开始;$z_i$是$i$时刻解码RNN的隐层状态,$z_0$是一个全零的向量。
将$z_{i+1}$通过softmax归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
其中$W_sz_{i+1}+b_z$是对每个可能的输出单词进行打分,再用softmax归一化就可以得到第$i+1$个词的概率$p_{i+1}$。
根据$p_{i+1}$和$u_{i+1}$计算代价。
重复步骤1~3,直到目标语言序列中的所有词处理完毕。
机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见柱搜索算法。
注意力机制
如果编码阶段的输出是一个固定维度的向量,会带来以下两个问题:1)不论源语言序列的长度是5个词还是50个词,如果都用固定维度的向量去编码其中的语义和句法结构信息,对模型来说是一个非常高的要求,特别是对长句子序列而言;2)直觉上,当人类翻译一句话时,会对与当前译文更相关的源语言片段上给予更多关注,且关注点会随着翻译的进行而改变。而固定维度的向量则相当于,任何时刻都对源语言所有信息给予了同等程度的关注,这是不合理的。因此,Bahdanau等人[4]引入注意力(attention)机制,可以对编码后的上下文片段进行解码,以此来解决长句子的特征学习问题。下面介绍在注意力机制下的解码器结构。
与简单的解码器不同,这里$z_i$的计算公式为:
$$z_{i+1}=\phi _{\theta '}\left ( c_i,u_i,z_i \right )$$
可见,源语言句子的编码向量表示为第$i$个词的上下文片段$c_i$,即针对每一个目标语言中的词$u_i$,都有一个特定的$c_i$与之对应。$c_i$的计算公式如下:
$$c_i=\sum _{j=1}^{T}a_{ij}h_j, a_i=\left[ a_{i1},a_{i2},...,a_{iT}\right ]$$
从公式中可以看出,注意力机制是通过对编码器中各时刻的RNN状态$h_j$进行加权平均实现的。权重$a_{ij}$表示目标语言中第$i$个词对源语言中第$j$个词的注意力大小,$a_{ij}$的计算公式如下:
\begin{align} a_{ij}&=\frac{exp(e_{ij})}{\sum_{k=1}^{T}exp(e_{ik})}\\ e_{ij}&=align(z_i,h_j)\\ \end{align}
其中,$align$可以看作是一个对齐模型,用来衡量目标语言中第$i$个词和源语言中第$j$个词的匹配程度。具体而言,这个程度是通过解码RNN的第$i$个隐层状态$z_i$和源语言句子的第$j$个上下文片段$h_j$计算得到的。传统的对齐模型中,目标语言的每个词明确对应源语言的一个或多个词(hard alignment);而在注意力模型中采用的是soft alignment,即任何两个目标语言和源语言词间均存在一定的关联,且这个关联强度是由模型计算得到的实数,因此可以融入整个NMT框架,并通过反向传播算法进行训练。
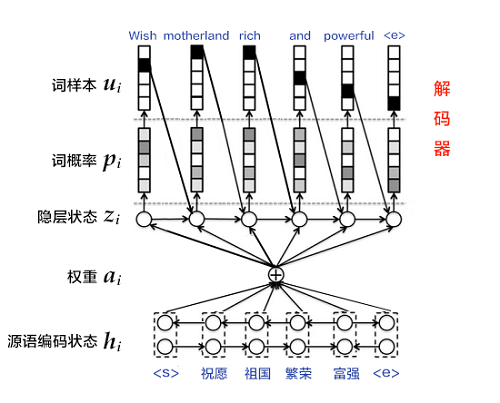
图6. 基于注意力机制的解码器
柱搜索算法
柱搜索(beam search)是一种启发式图搜索算法,用于在图或树中搜索有限集合中的最优扩展节点,通常用在解空间非常大的系统(如机器翻译、语音识别)中,原因是内存无法装下图或树中所有展开的解。如在机器翻译任务中希望翻译“<s>你好<e>”,就算目标语言字典中只有3个词(<s>, <e>, hello),也可能生成无限句话(hello循环出现的次数不定),为了找到其中较好的翻译结果,我们可采用柱搜索算法。
柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
1.每一个时刻,根据源语言句子的编码信息$c$、生成的第$i$个目标语言序列单词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。
2.将$z_{i+1}$通过softmax归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。
3.根据$p_{i+1}$采样出单词$u_{i+1}$。
4.重复步骤1~3,直到获得句子结束标记<e>或超过句子的最大生成长度为止。
注意:$z_{i+1}$和$p_{i+1}$的计算公式同解码器中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
数据介绍
本教程使用WMT-14数据集中的bitexts(after selection)作为训练集,dev+test data作为测试集和生成集。
数据预处理
我们的预处理流程包括两步:
将每个源语言到目标语言的平行语料库文件合并为一个文件:
合并每个XXX.src和XXX.trg文件为XXX。
XXX中的第$i$行内容为XXX.src中的第$i$行和XXX.trg中的第$i$行连接,用'\t'分隔。
创建训练数据的“源字典”和“目标字典”。每个字典都有DICTSIZE个单词,包括:语料中词频最高的(DICTSIZE - 3)个单词,和3个特殊符号<s>(序列的开始)、<e>(序列的结束)和<unk>(未登录词)。
示例数据
因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的较小规模的数据集。
该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
流程说明
paddle初始化
# 加载 paddle的python包
import sys
import paddle.v2 as paddle
# 配置只使用cpu,并且使用一个cpu进行训练
paddle.init(use_gpu=False, trainer_count=1)
# 训练模式False,生成模式True
is_generating = False模型结构
首先,定义了一些全局变量。
dict_size = 30000 # 字典维度
source_dict_dim = dict_size # 源语言字典维度
target_dict_dim = dict_size # 目标语言字典维度
word_vector_dim = 512 # 词向量维度
encoder_size = 512 # 编码器中的GRU隐层大小
decoder_size = 512 # 解码器中的GRU隐层大小
beam_size = 3 # 柱宽度
max_length = 250 # 生成句子的最大长度其次,实现编码器框架。分为三步:
输入是一个文字序列,被表示成整型的序列。序列中每个元素是文字在字典中的索引。所以,我们定义数据层的数据类型为integer_value_sequence(整型序列),序列中每个元素的范围是[0, source_dict_dim)。
src_word_id = paddle.layer.data(
name='source_language_word',
type=paddle.data_type.integer_value_sequence(source_dict_dim))将上述编码映射到低维语言空间的词向量$\mathbf{s}$。
src_embedding = paddle.layer.embedding(
input=src_word_id,
size=word_vector_dim,
param_attr=paddle.attr.ParamAttr(name='_source_language_embedding'))用双向GRU编码源语言序列,拼接两个GRU的编码结果得到$\mathbf{h}$。
src_forward = paddle.networks.simple_gru(
input=src_embedding, size=encoder_size)
src_backward = paddle.networks.simple_gru(
input=src_embedding, size=encoder_size, reverse=True)
encoded_vector = paddle.layer.concat(input=[src_forward, src_backward])接着,定义基于注意力机制的解码器框架。分为三步:
对源语言序列编码后的结果(见2的最后一步),过一个前馈神经网络(Feed Forward Neural Network),得到其映射。
with paddle.layer.mixed(size=decoder_size) as encoded_proj:
encoded_proj += paddle.layer.full_matrix_projection(
input=encoded_vector)构造解码器RNN的初始状态。由于解码器需要预测时序目标序列,但在0时刻并没有初始值,所以我们希望对其进行初始化。这里采用的是将源语言序列逆序编码后的最后一个状态进行非线性映射,作为该初始值,即$c_0=h_T$。
backward_first = paddle.layer.first_seq(input=src_backward)
with paddle.layer.mixed(
size=decoder_size, act=paddle.activation.Tanh()) as decoder_boot:
decoder_boot += paddle.layer.full_matrix_projection(
input=backward_first) 定义解码阶段每一个时间步的RNN行为,即根据当前时刻的源语言上下文向量$c_i$、解码器隐层状态$z_i$和目标语言中第$i$个词$u_i$,来预测第$i+1$个词的概率$p_{i+1}$。
decoder_mem记录了前一个时间步的隐层状态$z_i$,其初始状态是decoder_boot。
context通过调用simple_attention函数,实现公式$c_i=\sum {j=1}^{T}a_{ij}h_j$。其中,enc_vec是$h_j$,enc_proj是$h_j$的映射(见3.1),权重$a_{ij}$的计算已经封装在simple_attention函数中。
decoder_inputs融合了$c_i$和当前目标词current_word(即$u_i$)的表示。
gru_step通过调用gru_step_layer函数,在decoder_inputs和decoder_mem上做了激活操作,即实现公式$z_{i+1}=\phi _{\theta '}\left ( c_i,u_i,z_i \right )$。
最后,使用softmax归一化计算单词的概率,将out结果返回,即实现公式$p\left ( u_i|u_{<i},\mathbf{x} \right )=softmax(W_sz_i+b_z)$。
def gru_decoder_with_attention(enc_vec, enc_proj, current_word):
decoder_mem = paddle.layer.memory(
name='gru_decoder', size=decoder_size, boot_layer=decoder_boot)
context = paddle.networks.simple_attention(
encoded_sequence=enc_vec,
encoded_proj=enc_proj,
decoder_state=decoder_mem)
with paddle.layer.mixed(size=decoder_size * 3) as decoder_inputs:
decoder_inputs += paddle.layer.full_matrix_projection(input=context)
decoder_inputs += paddle.layer.full_matrix_projection(
input=current_word)
gru_step = paddle.layer.gru_step(
name='gru_decoder',
input=decoder_inputs,
output_mem=decoder_mem,
size=decoder_size)
with paddle.layer.mixed(
size=target_dict_dim,
bias_attr=True,
act=paddle.activation.Softmax()) as out:
out += paddle.layer.full_matrix_projection(input=gru_step)
return out 定义解码器框架名字,和gru_decoder_with_attention函数的前两个输入。注意:这两个输入使用StaticInput,具体说明可见StaticInput文档。
```python
decoder_group_name = "decoder_group"
group_input1 = paddle.layer.StaticInputV2(input=encoded_vector, is_seq=True)
group_input2 = paddle.layer.StaticInputV2(input=encoded_proj, is_seq=True)
group_inputs = [group_input1, group_input2]
```训练模式下的解码器调用:
首先,将目标语言序列的词向量trg_embedding,直接作为训练模式下的current_word传给gru_decoder_with_attention函数。
其次,使用recurrent_group函数循环调用gru_decoder_with_attention函数。
接着,使用目标语言的下一个词序列作为标签层lbl,即预测目标词。
最后,用多类交叉熵损失函数classification_cost来计算损失值。
if not is_generating:
trg_embedding = paddle.layer.embedding(
input=paddle.layer.data(
name='target_language_word',
type=paddle.data_type.integer_value_sequence(target_dict_dim)),
size=word_vector_dim,
param_attr=paddle.attr.ParamAttr(name='_target_language_embedding'))
group_inputs.append(trg_embedding)
# For decoder equipped with attention mechanism, in training,
# target embeding (the groudtruth) is the data input,
# while encoded source sequence is accessed to as an unbounded memory.
# Here, the StaticInput defines a read-only memory
# for the recurrent_group.
decoder = paddle.layer.recurrent_group(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs)
lbl = paddle.layer.data(
name='target_language_next_word',
type=paddle.data_type.integer_value_sequence(target_dict_dim))
cost = paddle.layer.classification_cost(input=decoder, label=lbl)生成模式下的解码器调用:
首先,在序列生成任务中,由于解码阶段的RNN总是引用上一时刻生成出的词的词向量,作为当前时刻的输入,因此,使用GeneratedInput来自动完成这一过程。具体说明可见GeneratedInput文档。
其次,使用beam_search函数循环调用gru_decoder_with_attention函数,生成出序列id。
if is_generating:
# In generation, the decoder predicts a next target word based on
# the encoded source sequence and the last generated target word.
# The encoded source sequence (encoder's output) must be specified by
# StaticInput, which is a read-only memory.
# Embedding of the last generated word is automatically gotten by
# GeneratedInputs, which is initialized by a start mark, such as <s>,
# and must be included in generation.
trg_embedding = paddle.layer.GeneratedInputV2(
size=target_dict_dim,
embedding_name='_target_language_embedding',
embedding_size=word_vector_dim)
group_inputs.append(trg_embedding)
beam_gen = paddle.layer.beam_search(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs,
bos_id=0,
eos_id=1,
beam_size=beam_size,
max_length=max_length)注意:我们提供的配置在Bahdanau的论文[4]上做了一些简化,可参考issue #1133。
训练模型
参数定义
依据模型配置的`cost`定义模型参数。可以打印参数名字,如果在网络配置中没有指定名字,则默认生成。
```python
if not is_generating:
parameters = paddle.parameters.create(cost)
for param in parameters.keys():
print param
```数据定义
获取wmt14的dataset reader。
```python
if not is_generating:
wmt14_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.wmt14.train(dict_size=dict_size), buf_size=8192),
batch_size=5)
```构造trainer
根据优化目标cost,网络拓扑结构和模型参数来构造出trainer用来训练,在构造时还需指定优化方法,这里使用最基本的SGD方法。
```python
if not is_generating:
optimizer = paddle.optimizer.Adam(
learning_rate=5e-5,
regularization=paddle.optimizer.L2Regularization(rate=8e-4))
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=optimizer)
```构造event_handler
可以通过自定义回调函数来评估训练过程中的各种状态,比如错误率等。下面的代码通过event.batch_id % 2 == 0 指定每2个batch打印一次日志,包含cost等信息。
```python
if not is_generating:
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 2 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
```启动训练
```python
if not is_generating:
trainer.train(
reader=wmt14_reader, event_handler=event_handler, num_passes=2)
```训练开始后,可以观察到event_handler输出的日志如下:
Pass 0, Batch 0, Cost 148.444983, {'classification_error_evaluator': 1.0}
.........
Pass 0, Batch 10, Cost 335.896802, {'classification_error_evaluator': 0.9325153231620789}
.........生成模型
加载预训练的模型
由于NMT模型的训练非常耗时,我们在50个物理节点(每节点含有2颗6核CPU)的集群中,花了5天时间训练了一个模型供大家直接下载使用。该模型大小为205MB,[BLEU评估](#BLEU评估)值为26.92。
```python
if is_generating:
parameters = paddle.dataset.wmt14.model()
```数据定义