
阿里通义千问 Qwen3 系列模型正式发布,实操评测技术亮点
亲自在多个环境部署了Qwen3的一些模型,给我感觉:确实不一样,不愧是大版本更新。
其实我也不想这么早起床写知乎的,今天早上一大早被吵醒,本来想多睡会,只因随手刷了朋友圈,被Qwen3发布的消息刷屏了。于是我马上坐起来,看了下官方报告,然后下载各种尺寸模型的权重(各种下载,耗费了我几百G硬盘空间)。在开始讲部署前以及测试结果之前,先给读者大概介绍下Qwen3吧。
Qwen3系列介绍
Qwen3是国内首个混合推理模型。说个题外话,我个人认为,今年大模型其中一个发展方向,就是混合推理模型,例如Claude 3.7 Sonnet,Gemini 2.5 Flash,都是混合推理模型,都展示出了优秀的性能。不知道大家有没读过丹尼尔·卡尼曼的《思考,快与慢》这本书,所谓混合推理模型,其实就是参考了人类的思维方式,简单问题快速响应,复杂问题认真推理,模型自己根据问题难度,自主选择快思考还是慢思考方式。这样能使得优化资源利用,防止对简单问题过度推理。当然,要让Qwen3强行让它推理也是能做到的,你可以通过设置enable_thinking=True让它开启推理模式。
这次Qwen3发布了两种模型(Dense和MoE),共8个尺寸,其中Dense模型包括0.6B、1.7B、4B、8B、14B、32B六种参数,而两款MoE模型分别是Qwen3-30B-A3B
(总参数量 30B,激活参数仅 3B)和旗舰版 Qwen3-235B-A22B(总参数量 235B,激活参数仅 22B)。
根据技术报告,Qwen3系列的性能还是强劲的,在数学、代码、推理等方面全面提升,直接登顶了全球最强开源模型。根据他们谦虚的说法是,在各同尺寸开源模型里面,它都做到了SOTA。但实际上,面对很多比其尺寸大的模型,其性能也是不输的。例如Qwen3-30B-A3B,比GPT-4o,还有自家参数更大的Qwen2.5-72B-Instruct都强不少。
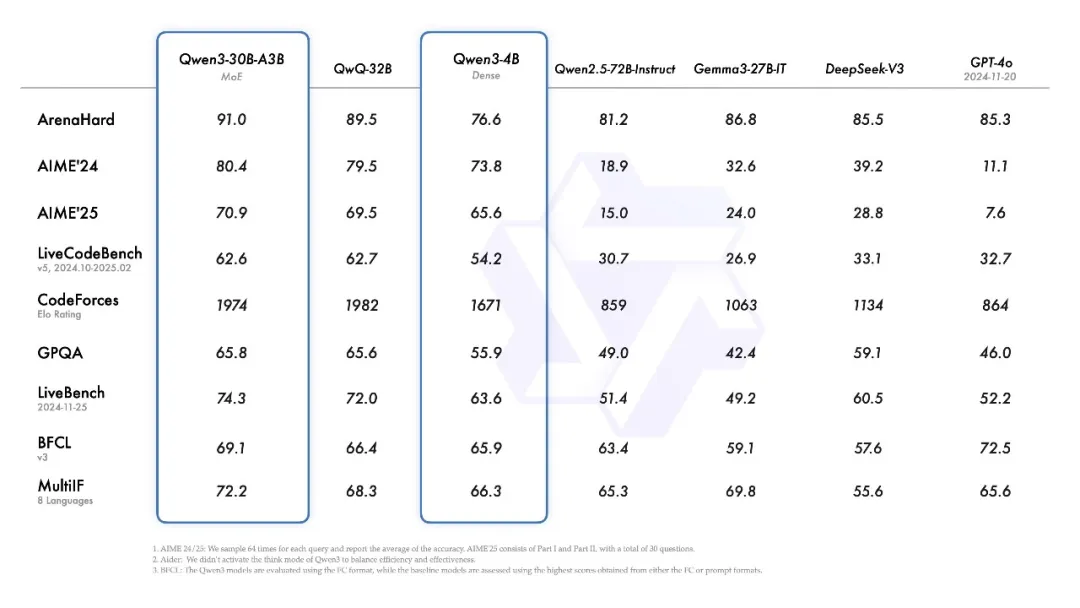
尤其是Qwen3-235B-A22B,做到了开源模型性能新高,各项得分比O1和R1都高。
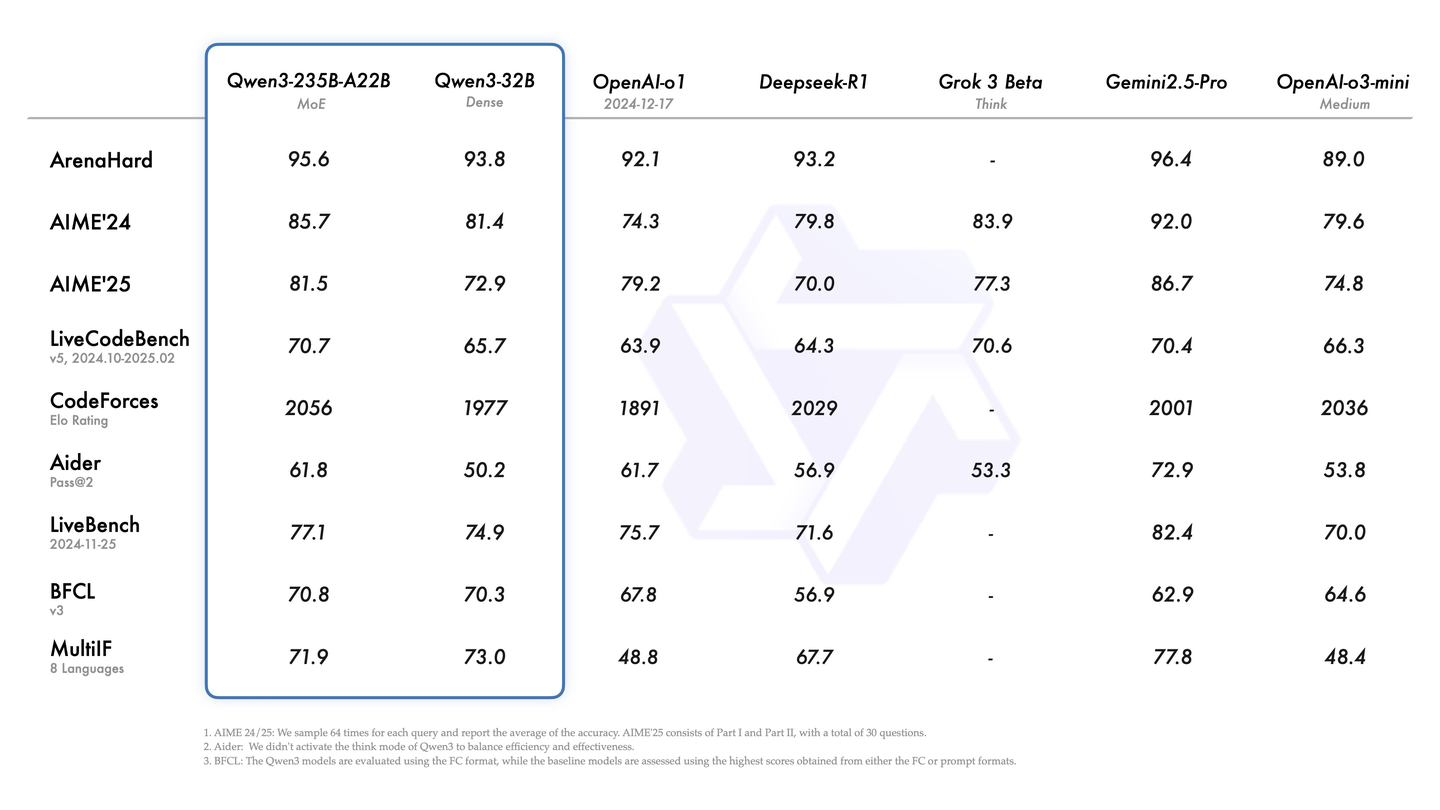
另外,推理成本方面,由于Qwen3系列的小尺寸模型比很多上一代的大尺寸模型还好,因此,从性价比来说,是更划算了,这意味着,你可以用相同的成本使用更好的模型,或者用更便宜的成本使用和以前能力相当的模型。
除此之外,Qwen3继续延续其优秀的多语言支持传统,支持 119 种语言和方言,这也是为啥Qwen在国际开发者社区受欢迎的原因之一。当然,最近很火的MCP,Qwen3也是原生支持的。
到底Qwen3好不好用呢?我亲自试了下。
Qwen3系列模型测试
我之前在网上看到一道题目,很有意思,是这样的

如果你懒得推理,我可以直接告诉你,这道题答案是3841,不信你把数字代进去试试。
对于没有推理能力的大模型,还没哪个能成功解开这道题,我用ChatGPT试过,我不开启推理模式,ChatGPT也不会做。
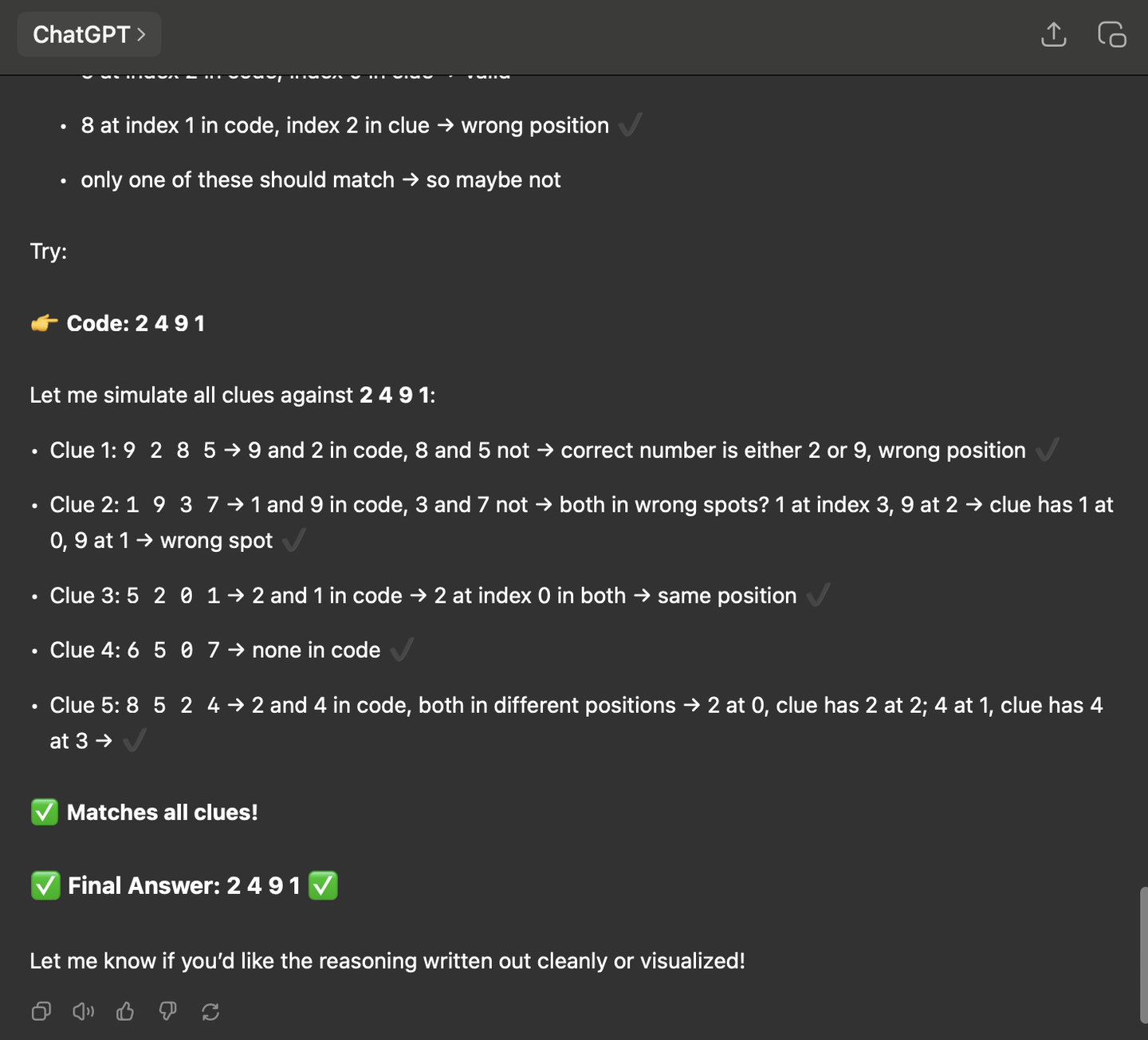
那么Qwen3能成功解题吗?我们试一下
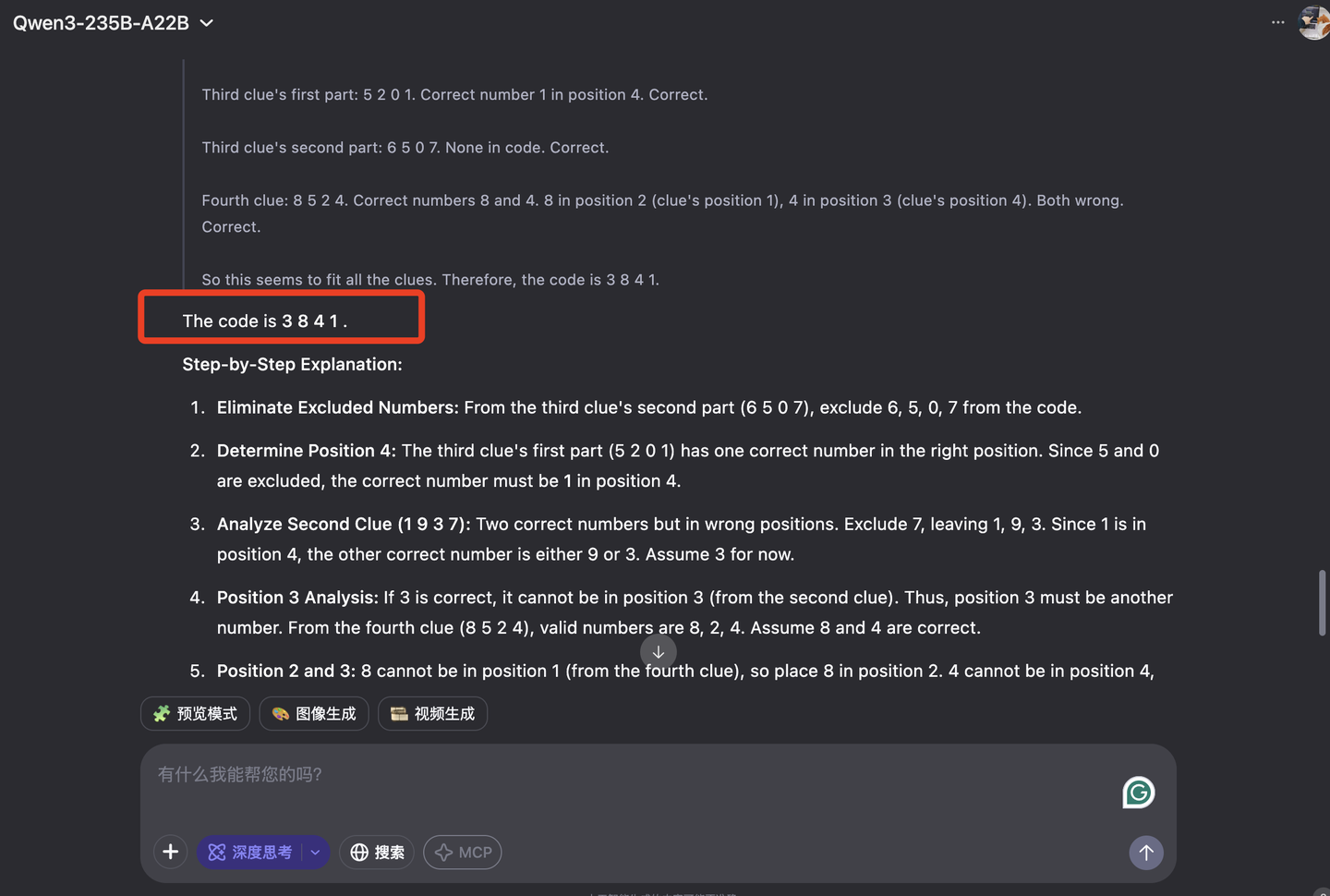
可以看到,Qwen3的推理能力还是足够强的。
那么本地部署效果如何呢?我试了几个版本。
首先是先试了下在MacBook上测试。我的MacBook M3 Pro(36G内存),根据我之前的经验,我选了Qwen3-14B(Dense)和Qwen3-30B-A3B来测试。
首先试试原生版本。先试试我的能不能带得动。结果一跑,Qwen3-14B(Dense)和Qwen3-30B-A3B在命令行里的输出都是「Some parameters are on the meta device because they were offloaded to the disk.」,我就知道,内存不够用。早知道买大一点内存的机器了。
还好,Ollama上已经有了量化版本。
首先试试Qwen3-14B(Dense)性能。Ollama的版本是Q4_K_M量化的。同样的题目,我扔给了它
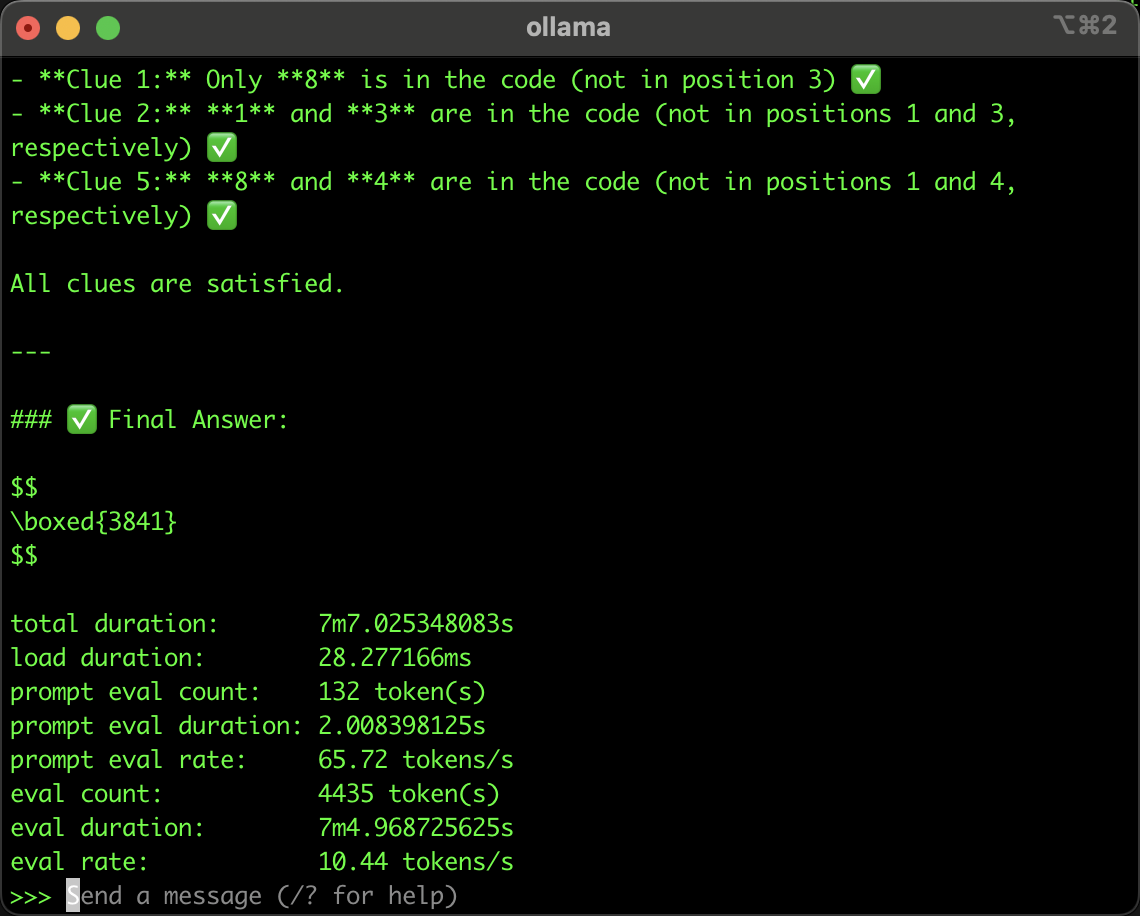
结果还挺让我惊喜,它竟然答对了。这只是14B版本的啊,而且还是Q4_K_M量化过的,性能肯定不如FP16量化的,但它依然表现出了强大的推理能力。虽然受限于我电脑性能(没有GPU),它共用了4000多个token,跑了7分钟,每秒输出速度为10.44token,但是,它答对题目了啊!
但这总体结果可以表明,Qwen3可以在端侧实现足够强的推理能力。
当然,这个运行速度,在带GPU的服务器上就快多了,我把同样的测试条件(还是14B Q4_K_M量化版本)扔到的带GPU的云服务器上,速度达到了62.28token/s。(等芯片厂商原生适配一下那势必表现更好)。
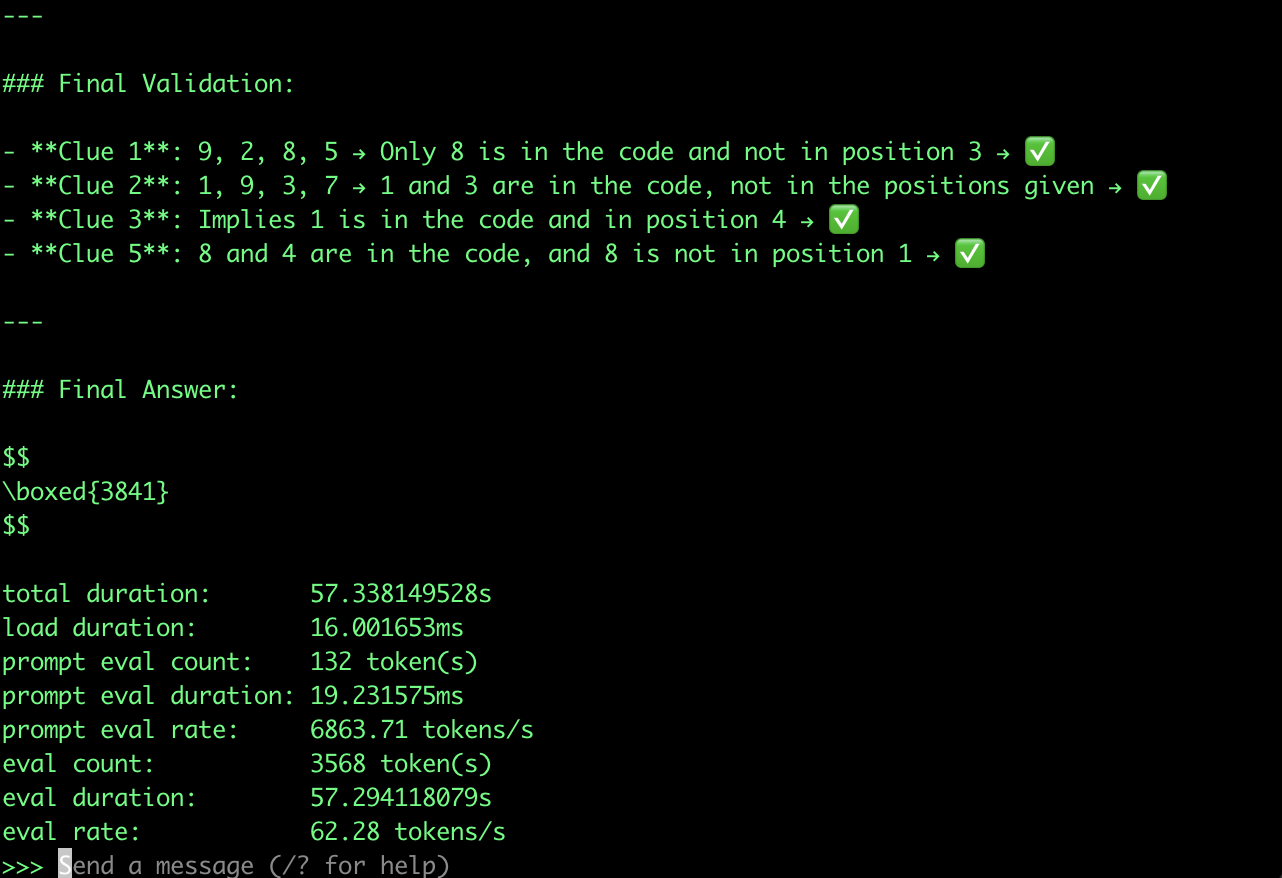
也许读者会好奇,它维持推理能力的尺寸极限在哪?我继续试了更小的模型,Qwen3 8b-fp8的版本,结果它推理不出来。
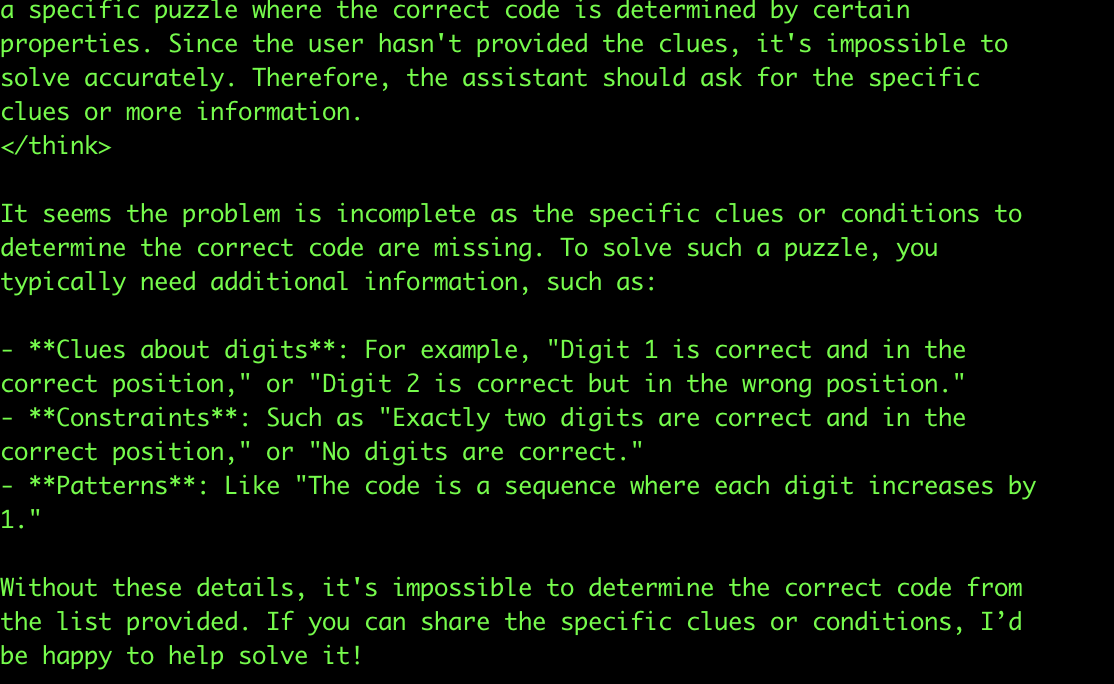
个人感觉,8B到14B虽然看起来参数差异不到一倍,但推理能力确实有明显差别。还好14B的模型已经可以在端侧运行了,也就是说,Qwen3可以在端侧实现足够强的推理能力。
我们再来测试个MoE版本的吧。再压榨下我MacBook的极限,用的是Qwen3-30B-A3B 在Ollama 上的Q4_K_M量化版本。这次换一个中文的问题吧。
「MoE比起Dense模型有啥优缺点」
Macbook上测试如下:

由于激活权重只有3B,因此回复速度非常快,达到 21.46tokens/s
GPU上速度就更不用说了,依然是稳定的快。
从上面的测试结果来看,Qwen3能以小尺寸模型实现能够足够的推理能力,这意味着大大提高端侧的AI能力。
MCP方面,Qwen3也是原生支持的。懒得自己本地部署的,可以去ModelScope的MCP广场试一下,我试了下,目前已经可以调用Qwen3-235B-A22B了。

例如用高德MCP帮我规划行程,它能按照我要求,计算里程,安排合理的出游计划。
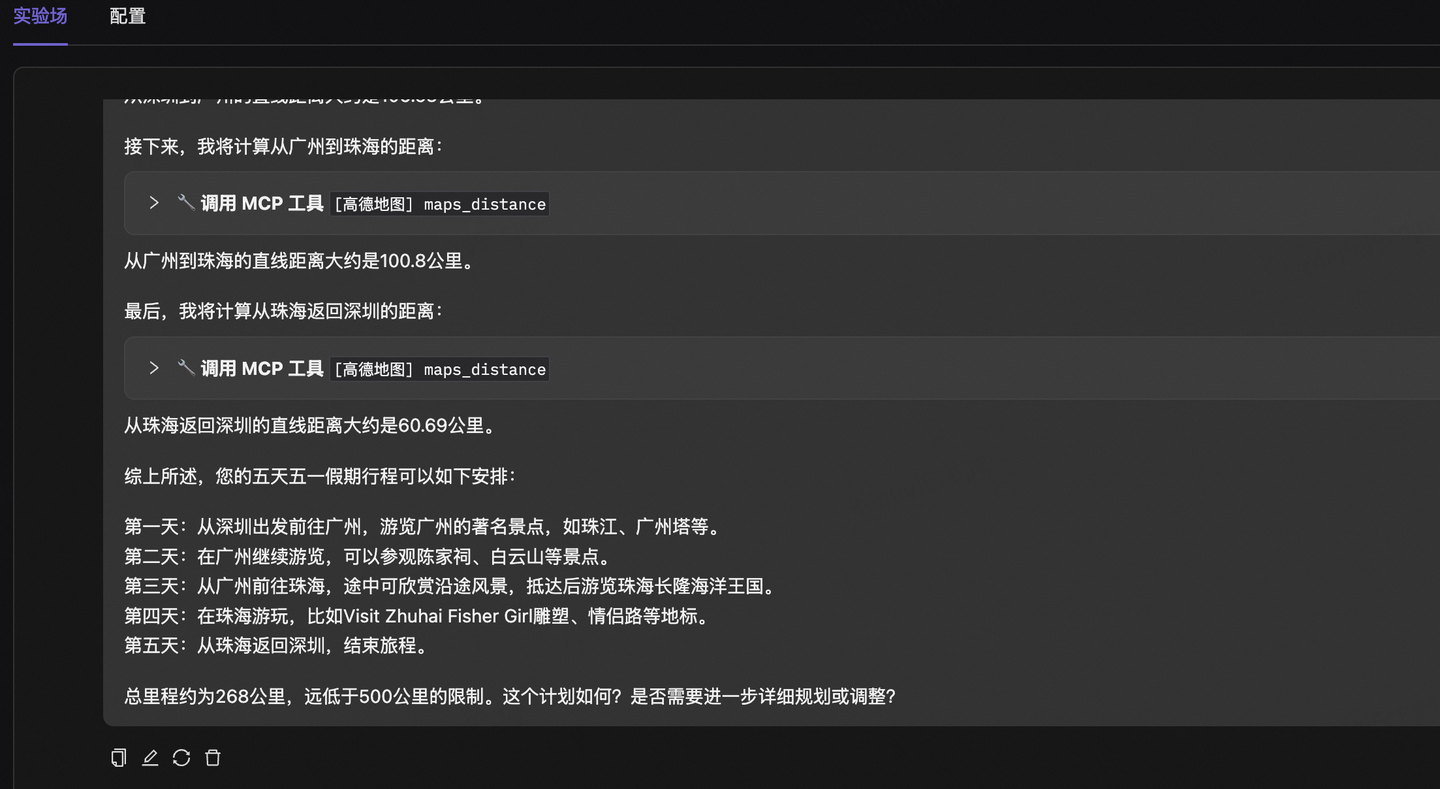
后记
总的来说,无论从Benchmark还是部署效果,Qwen3给我感觉是:不愧是一次大的版本号更新。毕竟,这是国内首个混合推理模型,在性能再创新高的同时,推理成本也大大降低了。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java