
Dify结合MCP查询数据库
今天介绍的demo就如题目所说,是一个查询数据库的MCP服务,其实之前我们也有一篇讲text2sql的案例《DeepSeek+Dify查询数据库》,但是因为我们表结构作为知识库,需要我们把这个表结构做的很丰富,确保能够更精准的生成相应的SQL语句,今天介绍的MCP查询数据库会更灵活一些。
一、MCP服务
https://mcp.so/zh/server/dbhub/bytebase?tab=content

当然数据库的MCP还是有很多的,我只是当时选择了这个MCP服务,所以用这个做举例,有兴趣的可以自行去查看选择,部分数据库相关的MCP服务如下:
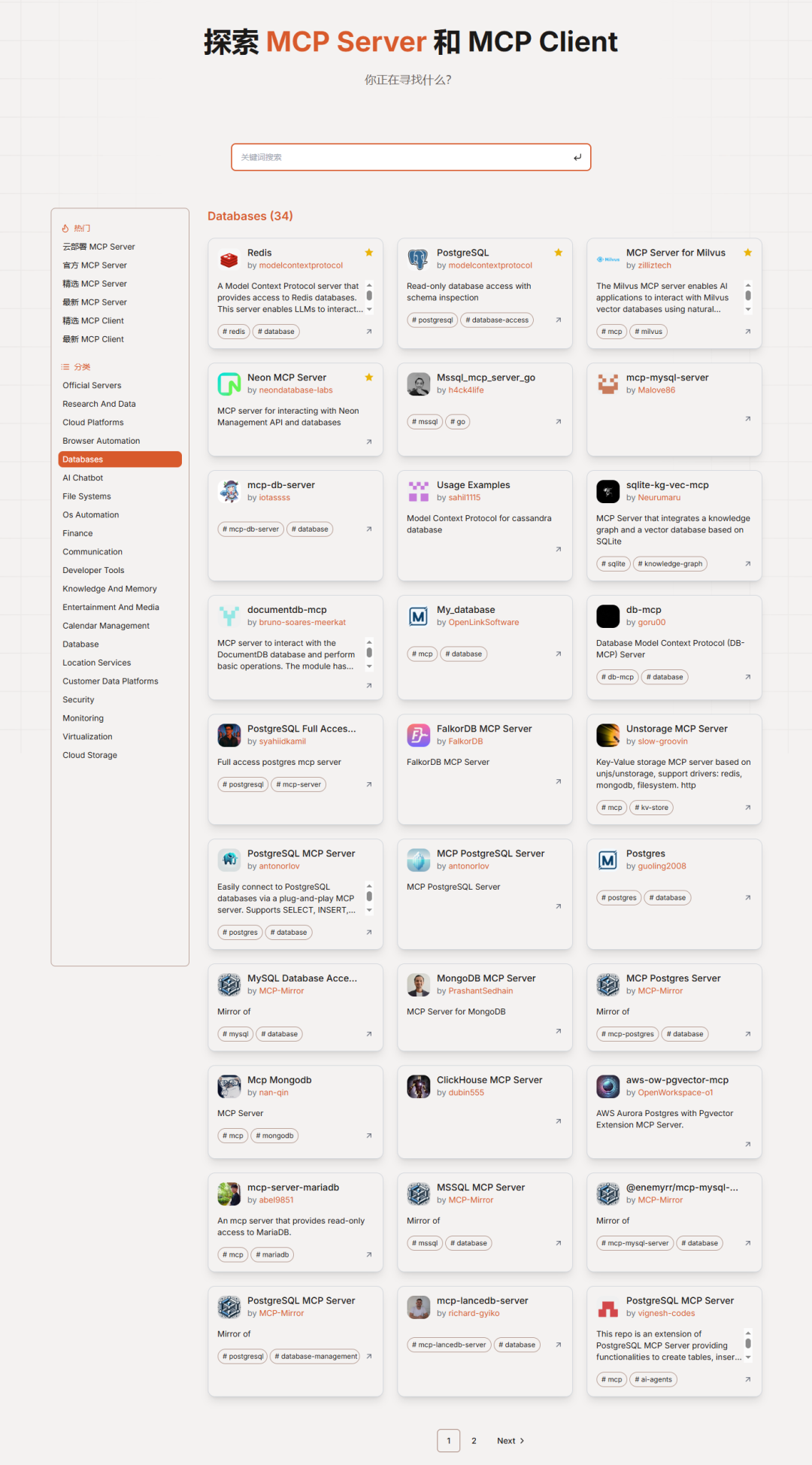
DbHub的Github仓库如下:
https://github.com/bytebase/dbhub
因为没有线上的服务,只能我们自己去部署启动一个DbHub的MCP服务供我们使用,下面先讲下如何部署DbHub。
安装部署DbHub服务有四种方案,可以用Docker,NPM,Claude Desktop,Cursor这四种方式,我对Docker比较熟悉一些,也有相关环境,就用Docker部署启动的,其余方式没有试过,有兴趣的可以试试。
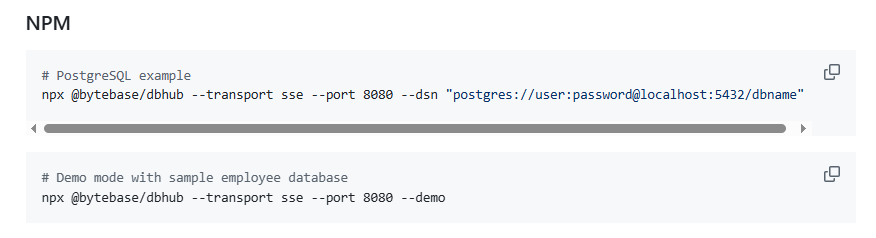
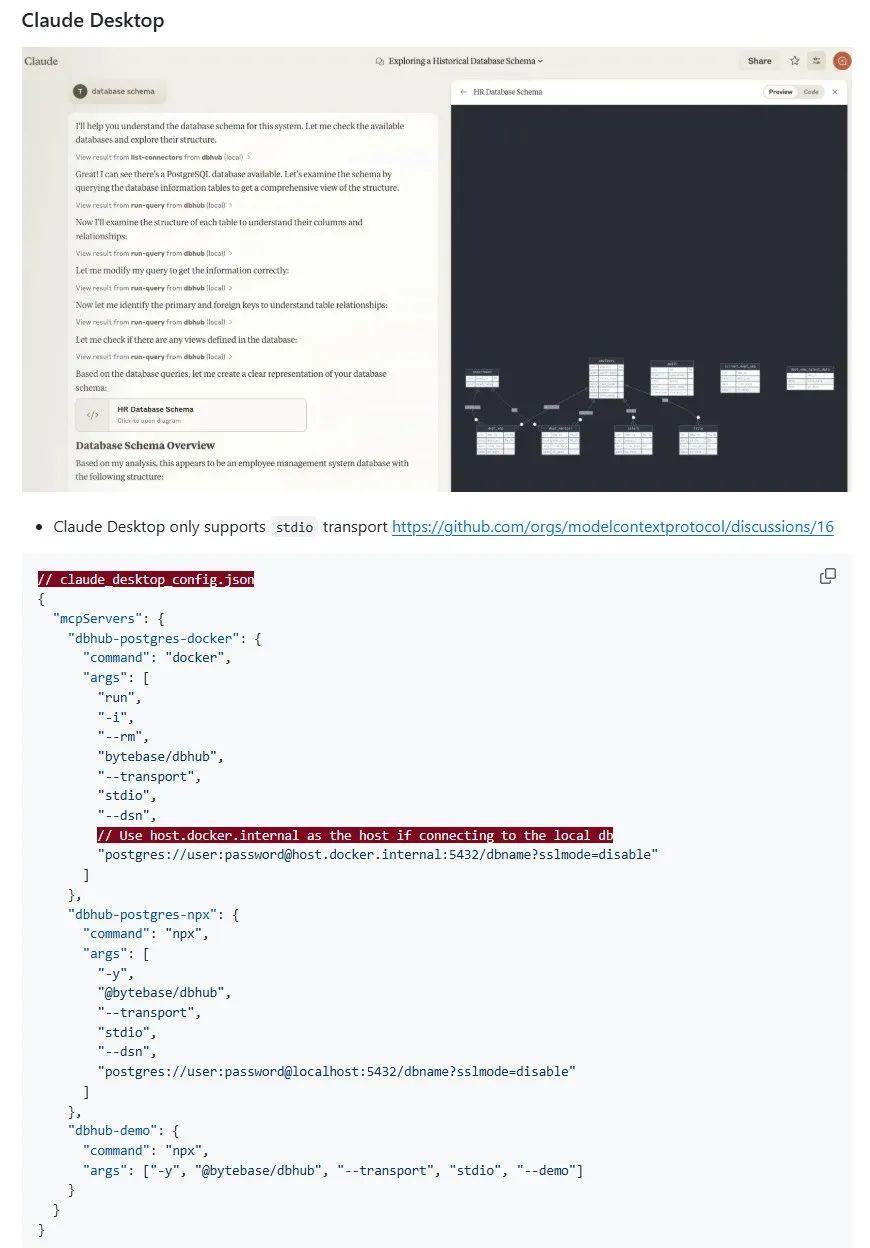
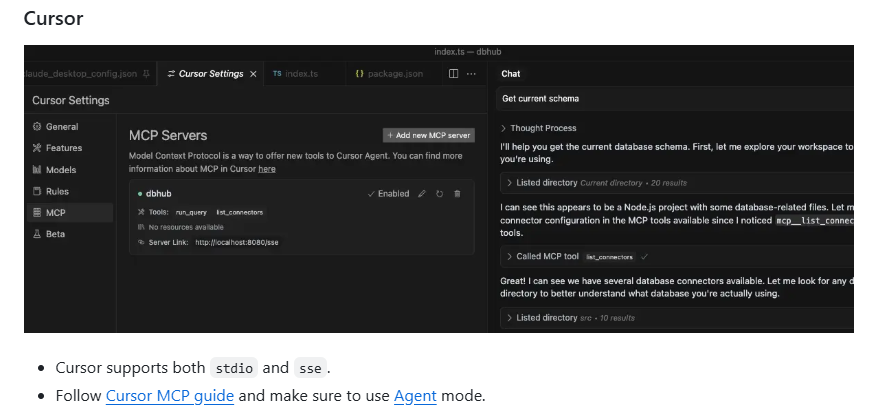
上面就是其他三种方式,下面我们按照Docker的方式去执行,命令如下:
dockerrun
--init --name dbhub --publish8080:8080bytebase/dbhub --transport sse
--port8080--dsn"mysql://<用户名>:<密码>@127.0.0.1:3306/<数据库名称>?sslmode=disable"
上面命令需要替换一下用户名,密码和数据库名,不需要带<>,按照你们实际的一个参数去填写。
我是windows,所以在docker desktop中可以看到container

启动后我们可以看到相关的日志:

到这儿我们算启动了MCP服务,下面我们就要去Dify中去使用。
二、Dify内使用MCP服务
之前一篇文章《Dify插件本地无法安装解决方案》其实需要安装的插件就是我们这里需要用到的:MCP_SSE插件
下面先看看这次Demo的整体界面,其实很简单,就是一个开始一个结束再加上一个知识库和一个Agent节点,
开始节点没有做任何设置,都是默认,不再做过多讲解:
知识检索节点

我的数据库脚本如下:
学生表:
教师表:
班级表:
CREATETABLE`classes`
( `class_id`intNOTNULLAUTO_INCREMENT COMMENT'班级唯一标识',
`class_name`varchar(50)COLLATEutf8mb4_binNOTNULLCOMMENT'班级名称(例:2023级1班)',
`head_teacher_id`intNOTNULLCOMMENT'班主任ID',
`create_year`yearNOTNULLCOMMENT'创建年份',PRIMARYKEY (`class_id`), KEY
`fk_head_teacher`
(`head_teacher_id`),CONSTRAINT`fk_head_teacher`FOREIGNKEY
(`head_teacher_id`)REFERENCES`teachers` (`teacher_id`)) ENGINE=InnoDB
AUTO_INCREMENT=104DEFAULTCHARSET=utf8mb4COLLATE=utf8mb4_bin
COMMENT='班级信息表';
课程信息表:
CREATETABLE`courses`
( `course_id`intNOTNULLAUTO_INCREMENT COMMENT'课程唯一标识',
`course_code`varchar(20)COLLATEutf8mb4_binNOTNULLCOMMENT'课程代码(例:MATH101)',
`course_name`varchar(100)COLLATEutf8mb4_binNOTNULLCOMMENT'课程名称',
`credit`decimal(3,1)NOTNULLCOMMENT'学分',
`teacher_id`intNOTNULLCOMMENT'负责教师ID',
`course_hours`smallintDEFAULTNULLCOMMENT'课时数',PRIMARYKEY
(`course_id`),UNIQUEKEY `course_code` (`course_code`), KEY
`fk_course_teacher`
(`teacher_id`),CONSTRAINT`fk_course_teacher`FOREIGNKEY
(`teacher_id`)REFERENCES`teachers` (`teacher_id`)) ENGINE=InnoDB
AUTO_INCREMENT=5DEFAULTCHARSET=utf8mb4COLLATE=utf8mb4_bin
COMMENT='课程信息表';
学生考试成绩表:
CREATE
TABLE`exam_results`(`result_id`intNOT NULL AUTO_INCREMENT
COMMENT'成绩记录唯一标识',`student_id`intNOT NULL
COMMENT'学生ID',`course_id`intNOT NULL COMMENT'课程ID',`exam_date`date NOT
NULL COMMENT'考试日期',`score`decimal(5,2) DEFAULT NULL
COMMENT'考试成绩',`exam_type`enum('期中','期末','补考','测验') COLLATE utf8mb4_bin
NOT NULL COMMENT'考试类型',`recorder_id`intNOT NULL
COMMENT'录入教师ID',`record_time`datetime DEFAULT CURRENT_TIMESTAMP
COMMENT'录入时间', PRIMARY KEY (`result_id`), UNIQUE
KEY`unique_exam_record`(`student_id`,`course_id`,`exam_date`,`exam_type`),
KEY`fk_result_course`(`course_id`),
KEY`fk_result_recorder`(`recorder_id`),
CONSTRAINT`fk_result_course`FOREIGN KEY (`course_id`)
REFERENCES`courses`(`course_id`), CONSTRAINT`fk_result_recorder`FOREIGN
KEY (`recorder_id`) REFERENCES`teachers`(`teacher_id`),
CONSTRAINT`fk_result_student`FOREIGN KEY (`student_id`)
REFERENCES`students`(`student_id`), CONSTRAINT`exam_results_chk_1`CHECK
((`score`between0and100))) ENGINE=InnoDB AUTO_INCREMENT=9DEFAULT
CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='学生考试成绩表';
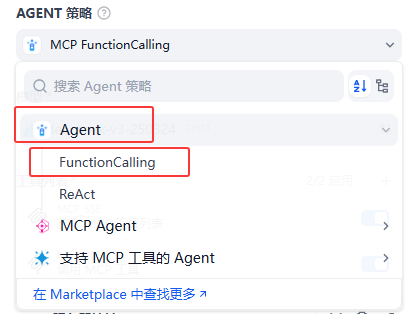
AGENT节点
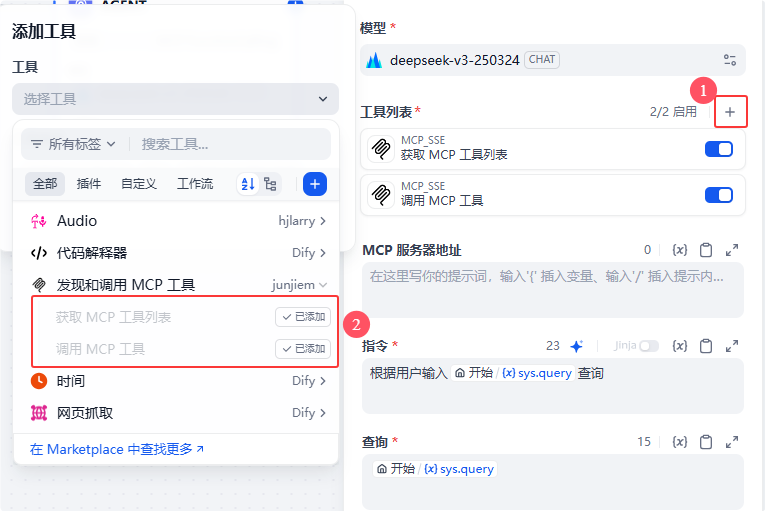
首先是需要选择AGENT策略,我这里选择的是Dify Agent策略插件,选择的是FunctionCalling:

选择完成后会需要选择模型,这里我使用的是火山的V3模型
,这里选择能够支持工具调用的模型即可:
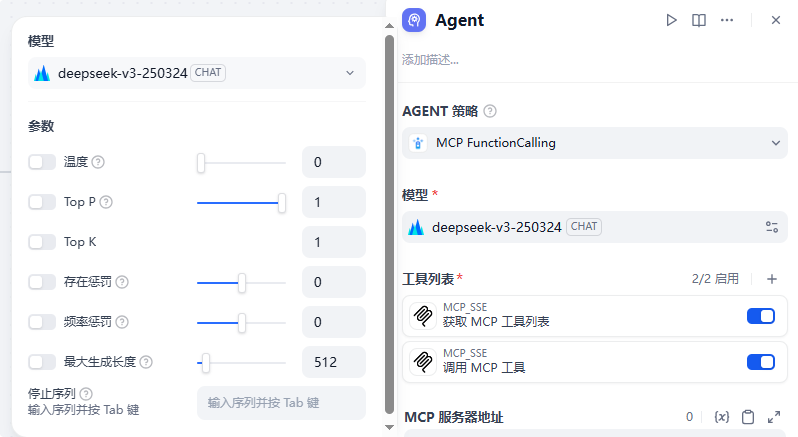
下面就是工具列表,也就是我们之前说的MCP_SSE插件,它有两个工具,一个是获取MCP工具列表,一个是调用MCP工具,这里我们需要两个都选择:
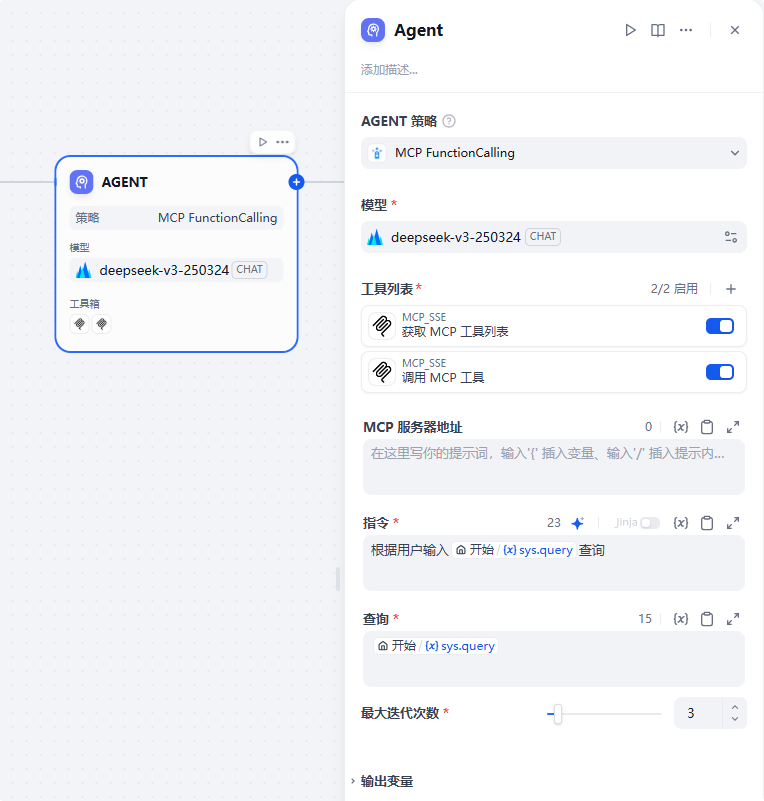
下面就是指令和查询,这两部分根据实际情况进行prompt提示词的输入,我这就是个简单的demo,就写的很简单,根据用户输入进行查询:
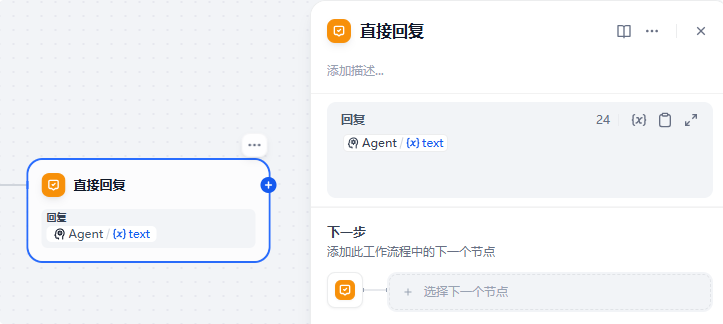
直接回复节点也很简单,就是把AGENT节点的输出作为参数进行回复
最大迭代次数就是调用工具后的一个迭代次数,默认是3次,简单的使用是够了,如果使用过程中发现不够可以调整。
好了,上面都配置好之后我们开始看看效果了。
我的数据库里面有有学生表,班级表等数据,下面我们的提问都是围绕这些内容进行:

首先我们可以看看,能够使用哪些工具:
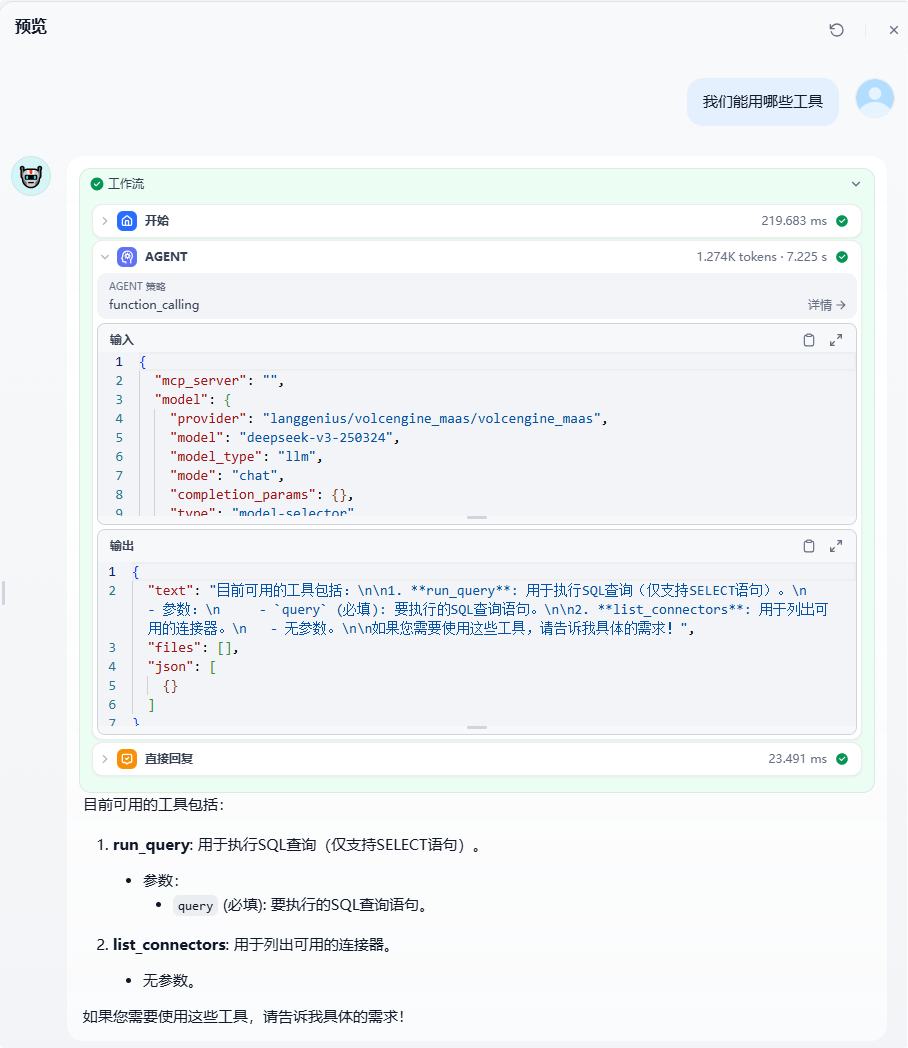
可以看到,工作流是走了MCP服务的。
在Agent策略中,进行了两次迭代,
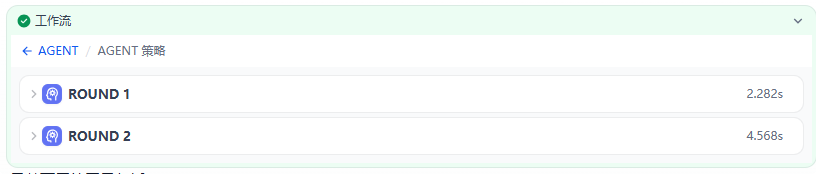
第一次是调用工具mcp_sse_list_tools然后获取了对应的工具信息:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java