
一文带你了解大模型——智能体(Agent)
大语言模型 vs 人类
大语言模型很强大,就像人类的大脑一样拥有思考的能力。如果人类只有大脑,没有四肢,没有工具,是没办法与世界互动的。如果我们能给大模型配备上四肢和工具呢?大模型是不是就会打破次元壁,从数字世界走向现实世界,与现实世界实现梦幻联动呢?
大语言模型(后文将用 LLM 指代)可以接受输入,可以分析&推理、可以输出文字\代码\媒体。然而,其无法像人类一样,拥有规划思考能力、运用各种工具与物理世界互动,以及拥有人类的记忆能力。
- LLM:接受输入、思考、输出
- 人类:LLM(接受输入、思考、输出)+ 记忆 + 工具 + 规划
如果我们给 LLM 配备上:与物理世界互动的工具、记忆能力、规划思考能力。LLM 是否就可以像人类一样,能够自主思考并规划完成任务的过程,能检索记忆,能使用各种工具提高效率,最终完成某个任务。
智能体是什么
智能体的英文是 Agent,AI 业界对智能体提出了各种定义。个人理解,智能体是一种通用问题解决器。从软件工程的角度看来,智能体是一种基于大语言模型的,具备规划思考能力、记忆能力、使用工具函数的能力,能自主完成给定任务的计算机程序。

图 1. 由 LLM 驱动的智能体系统
如图 1 所示,在基于 LLM 的智能体中,LLM 的充当着智能体的“大脑”的角色,同时还有 3 个关键部分:
- 规划(Planning) : 智能体会把大型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并终止运行。
- 记忆(Memory): 短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
- 工具使用(Tool use) 为智能体配备工具 API,比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具 API,智能体就可以是物理世界交互,解决实际的问题。
智能体能做什么
相信看到这里,我们已经对智能体有了基本的认知。如果你还觉得智能体这个概念有点抽象,没关系,现在我们来点好玩的,一起来看看智能体能玩出什么花样?
智能体之调研员
调研员智能体,可以根据用户的调研问题,从搜索引擎上搜索资料并总结,然后生成调研报告。 这里使用 MetaGPT 框架中的调研员 示例来展示一个智能体的实际作用及其构成。
运行一下试试
- 输入调研课题:调研特斯拉 FSD 和华为 ADS 这两个自动驾驶系统
~ python3 -m metagpt.roles.researcher "特斯拉FSD vs 华为ADS"- 智能体执行调研
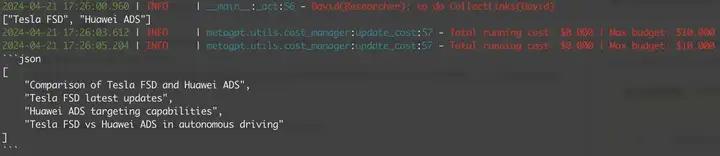
图2. 从搜索引擎进行搜索并获取Url地址列表
(图左为冯·诺依曼;右为奥本海默;背后是世界上第一台冯·诺依曼架构的“现代”计算机)

图3. 浏览网页并总结网页内容
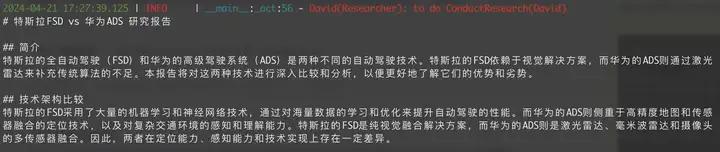
图4.生成调研报告
- 输出调研报告 metaGPT 生成并保存了调研报告

文件:特斯拉FSD vs 华为ADS.md
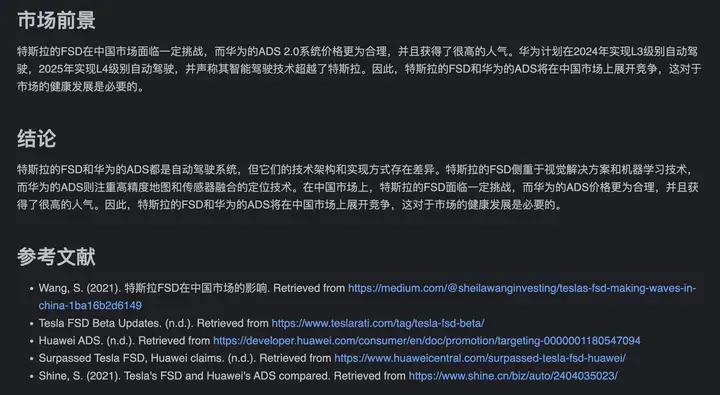
图5
拆解调研员
调研员智能体构成
回到前文所说的,如果仅有 LLM 这个大脑,是无法完成整个调研流程的。在调研员智能体中,为 LLM 大脑配备了规划、工具、记忆的能力,使得他能独立完成调研任务,下面列出其基本构成,构成分三部分:角色、工具、记忆。在角色中,会注册各种工具,定义思考规划的方式,以及本身具备的短期记忆能力。
| 类型 | 名称 | 说明 |
|---|---|---|
| 角色 | Researcher | 调研员智能体,从网络进行搜索并总结报告。通过 LLM 提示工程(Prompt Engineering),让 LLM 以调研员的角色去规划和拆分任务,使用提供的工具,完成调研过程,生成调研报告。在定义角色时,会为其注册下面列出的各项工具 |
| 工具 | CollectLinks | 问题拆解,从搜索引擎进行搜索,并获取 Url 地址列表。该工具基于 LLM 提示工程和搜索引擎实现,其功能如下:(1)将问题拆分成多个适合搜索的子问题(基于 LLM 提示工程)。(2)通过搜索引擎搜索子问题。(3)筛选出与调研问题有关的 Url,并根据网站可靠性对 url 列表进行排序(基于 LLM 提示工程) |
| 工具 | WebBrowseAndSummarize | 浏览网页并总结网页内容。由两个工具组成:浏览网页和总结网络内容。(1)浏览网页是通过封装的 WebBrowserEngine 工具访问搜索引擎实现的。(2)总结搜索结果是通过 LLM 提示工程实现。 |
| 工具 | ConductResearch | 生成调研报告。基于 LLM 提示工程的工具,该工具会整合 WebBrowseAndSummarize 的输出给到 LLM,让 LLM 生成调研报告 |
| 记忆 | short-term memory | 短期记忆能力,metaGPT 框架封装了短期记忆的能力,用于在任务执行周期内保存和检索上下文记忆,如 CollectLinks 和 WebBrowseAndSummarize 等工具的执行结果 |
图解调研员智能体
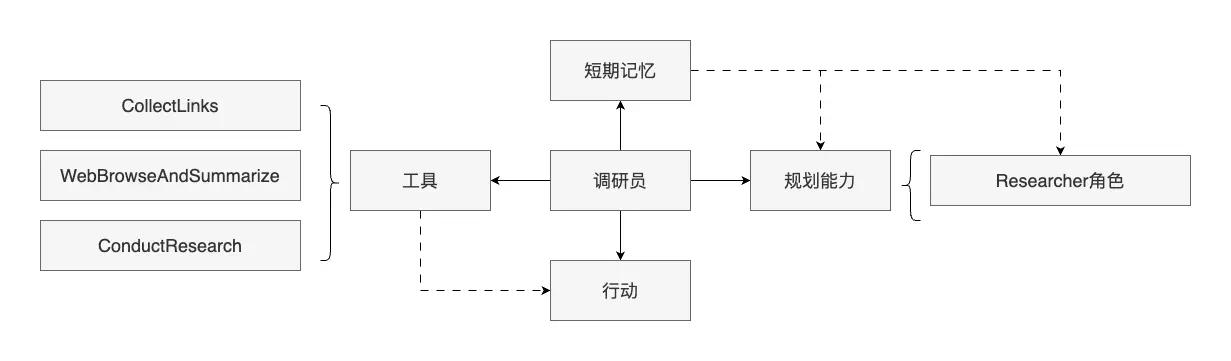
图6
智能体的关键构成

img
智能体 如上图所示,在基于 LLM 的智能体中,LLM 的充当着智能体的“大脑”的角色,同时还有 3 个关键部分:规划(Planning)、记忆(Memory)、工具使用(Tool use)
规划(Planing)
规划,可以为理解观察和思考。如果用人类来类比,当我们接到一个任务,我们的思维模式可能会像下面这样:
- 我们首先会思考怎么完成这个任务。
- 然后我们会审视手头上所拥有的工具,以及如何使用这些工具高效地达成目的。
- 我们会把任务拆分成子任务(就像我们会使用 TAPD 做任务拆分)。
- 在执行任务的时候,我们会对执行过程进行反思和完善,吸取教训以完善未来的步骤
- 执行过程中思考任务何时可以终止
这是人类的规划能力,我们希望智能体也拥有这样的思维模式,因此可以通过 LLM 提示工程,为智能体赋予这样的思维模式。在智能体中,最重要的是让 LLM 具备这以下两个能力:
子任务分解
通过 LLM 使得智能体可以把大型任务分解为更小的、更可控的子任务,从而能够有效完成复杂的任务。
思维链(Chain of Thoughts, CoT)
思维链已经是一种比较标准的提示技术,能显著提升 LLM 完成复杂任务的效果。当我们对 LLM 这样要求「think step by step」,会发现 LLM 会把问题分解成多个步骤,一步一步思考和解决,能使得输出的结果更加准确。这是一种线性的思维方式。
思维链的 prompt 可以像是如下这样(这里只是一个极简的 prompt,实际会按需进行 prompt 调优):
template="Answer the question: Q: {question}? Let's think step by step:"思维树(Tree-of-thought, ToT)
对 CoT 的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来探索思维树,并进行前瞻和回溯。
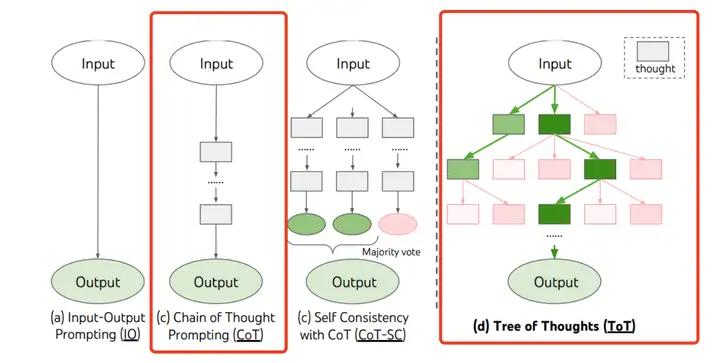
图7
反思和完善
智能体在执行任务过程中,通过 LLM 对完成的子任务进行反思,从错误中吸取教训,并完善未来的步骤,提高任务完成的质量。同时反思任务是否已经完成,并终止任务。
ReAct
(刚接触到这个单词时,脑子里冒出来的是 「React 是由 Facebook 开源的一个进行创建用户界面的一款 JavaScript 库....」,打住,我们好像走错片场了,此 React 非彼 ReAct •﹏• )
ReAct(Yao et al. 2023) ,《ReAct: Synergizing Reasoning and Acting in Language Models》 这篇论文提出一种用于增强大型语言模型的方法,它通过结合推理(Reasoning)和行动(Acting)来增强推理和决策的效果。
- 推理(Reasoning): LLM 基于「已有的知识」或「行动(Acting)后获取的知识」,推导出结论的过程。
- 行动(Acting): LLM 根据实际情况,使用工具获取知识,或完成子任务得到阶段性的信息。
为什么结合推理和行动,就会有效增强 LLM 完成任务的能力?这个问题其实很好回答,我们用上面的「调研员智能体」举例,我提出了问题:「特斯拉 FSD 对比华为 ADS」,下面列出几种不同规划模式的推演:
- 仅推理(Reasoning Only):LLM 仅仅基于已有的知识进行推理,生成答案回答这个问题。很显然,如果 LLM 本身不具备这些知识,可能会出现幻觉,胡乱回答一通。
- 仅行动(Acting Only): 大模型不加以推理,仅使用工具(比如搜索引擎)搜索这个问题,得出来的将会是海量的资料,不能直接回到这个问题。
- 推理+行动(Reasoning and Acting): LLM 首先会基于已有的知识,并审视拥有的工具。当发现已有的知识不足以回答这个问题,则会调用工具,比如:搜索工具、生成报告等,然后得到新的信息,基于新的信息重复进行推理和行动,直到完成这个任务。其推理和行动的步骤会是如下这样:
推理1:当前知识不足以回答这个问题,要回答该问题,需要知道什么是「特斯拉FSD 」和「华为ADS」
行动1:使用搜索工具搜索「特斯拉FSD 」和「华为ADS」的资料
观察1:总结行动1的内容
推理2:基于行动1和观察1的信息,得知这是关于两个自动驾驶提供商的方案对比,基于已有的信息,现在需要生成报告
行动2:使用生成报告的工具,生成调研报告
观察2:任务完成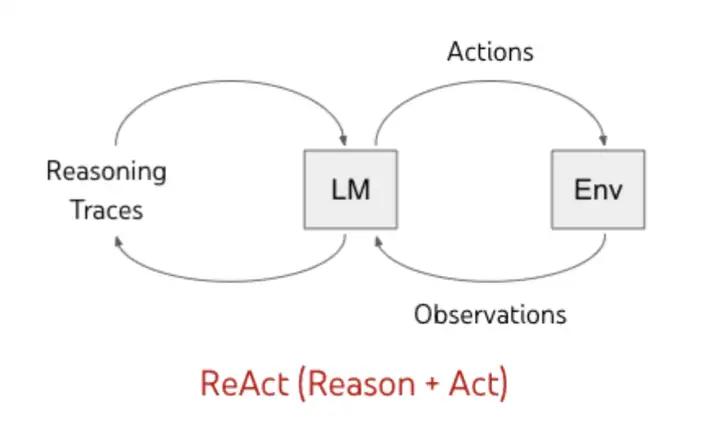
图8
通过巧妙的 promt 提示设计,使得 LLM 重复地执行推理和行动,最终完成任务。ReAct 的 prompt 模版的大致思路为:
Thought(思考): ...
Action(行动): ...
Observation(观察): ...
Thought(思考): ...
Action(行动): ...
Observation(观察): ...
...(Repeated many times(重复多次))记忆(Memory)
记忆是什么?当我们在思考这个问题,其实人类的大脑已经在使用记忆。记忆是大脑存储、保留和回忆信息的能力。记忆可以分为不同的类型:
- 短期记忆(或工作记忆):这是一种持续时间较短的记忆,能够暂时存储和处理有限数量的信息。例如,记住一个电话号码直到拨打完毕。
- 长期记忆:这是一种持续时间较长的记忆,可以存储大量信息,从几分钟到一生。长期记忆可以进一步分为显性记忆和隐性记忆。显性记忆,可以有意识地回忆和表达的信息,显性记忆又可以分为情景记忆(个人经历的具体事件)和语义记忆(一般知识和概念)。隐性记忆,这种记忆通常是无意识的,涉及技能和习惯,如骑自行车或打字。
仿照人类的记忆机制,智能体实现了两种记忆机制:
- 短期记忆:在当前任务执行过程中所产生的信息,比如某个工具或某个子任务执行的结果,会写入短期记忆中。记忆在当前任务过程中产生和暂存,在任务完结后被清空。
- 长期记忆:长期记忆是长时间保留的信息。一般是指外部知识库,通常用向量数据库来存储和检索。
工具使用(Tool use)
LLM 是数字世界中的程序,想要与现实世界互动、获取未知的知识,或是计算某个复杂的公式等,都离不开不工具。所以我们需要为智能体配备各种工具以及赋予它使用工具的能力。
工具是什么?它可以是锤子、螺丝刀,也可以是函数(function)、软件开发工具包(sdk)。工具是人类智慧的具象化,扩展我们的能力,提升工作效率。在智能体中,工具就是函数(Function),工具使用就是调用函数(Call Function)。
在 LLM 中实现函数调用,使用到 LLM 的这个能力:
Function Calling
Function Calling 是一种实现大型语言模型连接外部工具的机制。通过 API 调用 LLM 时,调用方可以描述函数,包括函数的功能描述、请求参数说明、响应参数说明,让 LLM 根据用户的输入,合适地选择调用哪个函数,同时理解用户的自然语言,并转换为调用函数的请求参数(通过 JSON 格式返回)。调用方使用 LLM 返回的函数名称和参数,调用函数并得到响应。最后,如果需求,把函数的响应传给 LLM,让 LLM 组织成自然语言回复用户。
function calling 具体工作流程如下图所示:
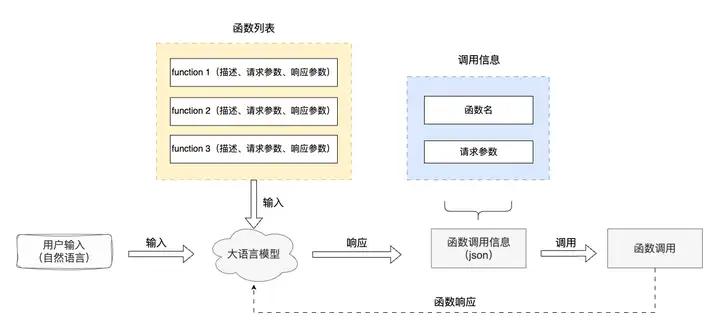
图9
不同 LLM 的 API 接口协议会有所不同,下文将以OpenAI 的 API 协议为例,说明如何实现 Function Calling
函数描述
我们可以按照智能体的需要来实现函数,比如前文的「调研员」智能体,为其实现了这些函数:WebBrowseAndSummarize:浏览网页并总结网页内容;ConductResearch:生成调研报告等。如果是一个智能家居的智能体,可能会需要这些函数:开关灯、开光空调、获取环境信息等。函数的实现在这里不展开赘述,一个函数可以自行编码实现,也可以通过调用外部 API 实现。
假设你的函数已经被实现,我们需要向 LLM 描述这个函数,函数描述的必备要素:
- 函数名
- 函数的功能描述
- 函数的请求参数说明
- 函数的响应参数说明(可选)
「查询最近天气」的函数描述:
tools = [
{
"type": "function",
"function": {
"name": "get_n_day_weather_forecast",
"description": "获取最近n天的天气预报",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市或镇区 如:深圳市南山区",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "要使用的温度单位,摄氏度 or 华氏度",
},
"num_days": {
"type": "integer",
"description": "预测天数",
}
},
"required": ["location", "format", "num_days"]
},
}
}
]调用 LLM 获得函数的请求参数
Function Calling 是通过请求 LLM 的 chat API 实现的,在支持 Function Calling 模型的 chat API 参数中,会有一个 functions 参数 (或 tools,不同 LLM 的参数会有所不同) ,通过传入这个参数,大模型则会知道拥有哪些参数可供使用。并且会根据用户的输入,推理出应该调用哪些函数,并将自然语言转成函数的请求参数,返回给请求方。下面以 OpenAI 的 SDK 举例:
from openai import OpenAI
def chat_completion_request(messages, tools=None, tool_choice=None, model="gpt-3.5-turbo"):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice=tool_choice,
)
return response
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
if __name__ == "__main__":
messages = []
messages.append({"role": "system", "content": "不要假设将哪些值输入到函数中。如果用户请求不明确,请要求澄清"})
messages.append({"role": "user", "content": "未来5天深圳南山区的天气怎么样"})
chat_response = chat_completion_request(
messages, tools=tools
)
tool_calls = chat_response.choices[0].message.tool_calls
print("===回复===")
print(tool_calls)LLM 将会返回get_n_day_weather_forecast函数的调用参数:
===回复===
[ChatCompletionMessageToolCall(id='call_7qGdyUEWp34ihubinIUCTXyH', function=Function(arguments='{"location":"深圳市南山区","format":"celsius","num_days":5}', name='get_n_day_weather_forecast'), type='function')]
// 格式化看看:chat_response.choices[0].message.tool_calls:
[
{
"id": "call_7qGdyUEWp34ihubinIUCTXyH",
"function": {
"arguments": {
"location": "深圳市南山区",
"format": "celsius",
"num_days": 5
},
"name": "get_n_day_weather_forecast"
},
"type": "function"
}
]调用函数
调用方获得 LLM 返回的函数调用信息(函数名称和调用参数)后,自行调用函数,并得到函数执行的响应。如果有需要,还可以把函数执行的响应追加到 chat API 的对话中传给 LLM,让 LLM 组织成自然语言回复用户。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java