
Spark SQL 的入门实践教程
1.Spark SQL概述
Spark SQL是用于处理结构化数据的模块。与Spark RDD不同的是,Spark SQL提供数据的结构信息(源数据)和性能更好,可以通过SQL和DataSet API与Spark SQL进行交互。
2.Spark SQL编程入门
Spark SQL模块的编程主入口点是SparkSession,SparkSession对象不仅为用户提供了创建DataFrame对象、读取外部数据源并转化为DataFrame对象以及执行sql查询的API,还负责记录着用户希望Spark应用如何在Spark集群运行的控制、调优参数,是Spark SQL的上下文环境,是运行的基础。
2.1 创建SparkSession
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();master("local")和new SparkConf().setMaster("local")一个样子,SparkSession包含了SparkContext,SqlContext等,是更强大的入口对象,也是更统一的入口。
appName("SparkSQLDemo1")设置任务名称
config():设置配置属性,并且有多个重载方法:
public synchronized SparkSession.Builder config(String key, String value)
public synchronized SparkSession.Builder config(String key, long value)
public synchronized SparkSession.Builder config(String key, double value)
public synchronized SparkSession.Builder config(String key, boolean value)
public synchronized SparkSession.Builder config(SparkConf conf)Spark 2.0中的SparkSession为Hive提供了强大的内置支持,包括使用HiveQL编写查询语句,访问Hive UDF以及从Hive表读取数据的功能。若是仅以学习为目的去测试这些功能时,并不需要在集群中特意安装Hive即可在Spark本地模式下测试Hive支持。
2.2 创建DataFrame
SparkSession对象提供的API,可以从现有的RDD,Hive表或其他结构化数据源中创建DataFrame对象。
在这里说明一下,DataSet是DataFrame的替代品,比DataFrame更强大。DataFrame等价于DataSet[Row]
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
System.out.println(sparkSession.version());
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
//show方法是展示所有的数据,也可以show(int rownums) 展示前N条数据
json.show();
sparkSession.close();
}样例数据:
{"id":1,"name":"小红","age":"19","phone":"111"}
{"id":2,"name":"王明","age":"20","phone":"222"}
{"id":3,"name":"诸葛亮","age":"21","phone":"333"}
{"id":4,"name":"王茂","age":"23","phone":"444"}
{"id":5,"name":"三毛","age":"17","phone":"555"}
{"id":6,"name":"老张","age":"16","phone":"666"}日志打印:
INFO 2019-11-25 20:26 - org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator[main] - Code generated in 18.6628 ms
+---+---+----+-----+
|age| id|name|phone|
+---+---+----+-----+
| 19| 1| 小红| 111|
| 20| 2| 王明| 222|
| 21| 3| 诸葛亮| 333|
| 23| 4| 王茂| 444|
| 17| 5| 三毛| 555|
| 16| 6| 老张| 666|
+---+---+----+-----+
INFO 2019-11-25 20:26 - org.spark_project.jetty.server.ServerConnector[main] - Stopped Spark@23db87{HTTP/1.1}{0.0.0.0:4040}可以看到,已经解析了json数据文件,并且还解析json中的字段名称,解析成表的字段名称,而且如果你的json的key值中有不一致的,都会解析成字段名称,只不过没有值的默认为null
例如:

日志打印:

看到没有,所有的不同key值都有。
2.3 DataFrame基本操作
DataFrame为我们提供了灵活、强大且底层自带优化的API,例如select、where、orderBy、groupBy、limit、union这样的算子操作,DataFrame提供这一系列算子对开发者来说非常熟悉,而DataFrame正是将SQL select语句的各个组成部分封装为同名API,用以帮助程序员通过select、where、orderBy等DataFrame API灵活地组合实现sql一样的逻辑表达。因此,DataFrame编程仅需像SQL那样简单地对计算条件、计算需求、最终所需结果进行声明式的描述即可,而不需要像RDD编程那样一步步地对数据集进行原始操作。
DataFrame API的使用实例(以上面的json数据为例):
- 以树形格式输出DataSet对象的结构信息
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// 展示DataSet结构信息
json.printSchema();日志打印:
root
|-- age: string (nullable = true)
|-- id: long (nullable = true)
|-- name: string (nullable = true)
|-- phone: string (nullable = true)表的结构信息已经按照树形结构出来了,是根据json文件的value值判定的。
2. 通过DataSet的Select()方法查询数据集中一列或者多列
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// 定义字段
Column id = new Column("id");
Column name = new Column("name");
// 查询单个字段
json.select("id").show();
// 查询多个字段
json.select(id,name).show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();Select 还有一个select(String col, String... cols)第一个参数不是很明白,后面再补充吧。还有这里有个对象Column是非常重要的,以后所有的java开发sparkSQL都会用到这个对象,这个对象就是我们在数据库中用到的字段,并且该对象有丰富的方法对字段做操作。
3. 组合使用DataSet对象的select(),where(),orderBy()方法查找id大于3的同学的id,姓名,年龄以及电话,按id的降序排列
这里为了更能直观的展示结果,我修改了json文件,添加了几行数据:
{"id":1,"name":"小红","age":"19","phone":"111"}
{"id":2,"name":"王明","age":"20","phone":"222"}
{"id":3,"name":"诸葛亮","age":"21","phone":"333"}
{"id":4,"name":"王茂","age":"23","phone":"444"}
{"id":5,"name":"三毛","age":"17","phone":"555"}
{"id":6,"name":"老张","age":"16","phone":"666"}
{"id":7,"name":"张好","age":"16","phone":"777"}
{"id":8,"name":"王流","age":"16","phone":"888"}where条件查询有两种形式:
public Dataset<T> where(Column condition)
public Dataset<T> where(String conditionExpr)第一种是通过Column对象操作条件查询,第二种是通过直接写条件查询
// 条件查询
// id > 3
Column id = new Column("id").gt(3);
// age = 16
Column name = new Column("age").equalTo("16");
// id > 3 and age =16
Column select = id.and(name);
// 直接书写条件
json.select("id","name","age","phone").where("id > 3 and age = 16").orderBy(new Column("id").desc()).show();
// 通过多个where生成 id > 3 and age =16
json.select("id","name","age","phone").where(id).where(name).orderBy(new Column("id").desc()).show();
// 通过Column操作转换得到 id > 3 and age =16
json.select("id","name","age","phone").where(select).orderBy(new Column("id").desc()).show();这三个的写法是一样的,结果也是一样的。

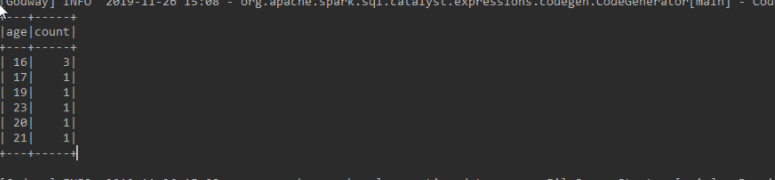
4.使用DataSet对象提供的groupBy()方法进而学生年龄分布
// 分组查询
// 单个字段分组查询
json.groupBy(new Column("age")).count().show();
// 多个字段分组查询
ArrayStack<Column> stack = new ArrayStack<>();
stack.push(new Column("id"));
stack.push(new Column("age"));
json.groupBy(stack).count().show();
// 多个字段分组查询
json.groupBy(new Column("id"),new Column("age")).count().show();group()分组有很多形式:
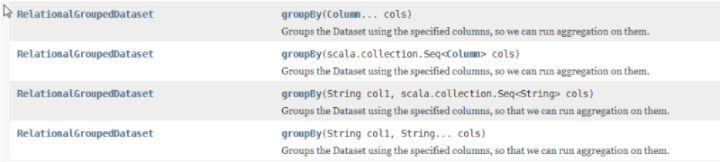
至于你想怎么写,只要正确就可以。

如果你想对字段操作,比如我们经常会这样写sqlselect age+1 from student,呢么sparkSQL完全可以实现,只需要这样既可:new Column("age").plus(1) 这就代表着age + 1
上面的实例中很好地展示了通过灵活组合使用DataSet提供的API可以实现SQL一样清晰简明的逻辑表达,如果采用RDD编程,首先RDD对JSON这种文件格式并不敏感,会像读取文本文件一样按行读取JSON文件,转化为RDD[String],而不会像DataSet那样自动解析JSON格式数据并且自动推断出结构信息(Schema),因此我们必须在程序中首先实例化一个JSON解析器用于解析JSON字符串得到真实数据组成的数组,实际是将RDD[String]转化为由一行行记录着多个共有字段数值的数组组成的RDD[Array[String]],进而使用map、filter、takeOrdered、distinct、union等RDD算子操作进行具体一步步地数据操作来实现业务逻辑。
相比之下,我们看出有时候同样的数据量,同样的分析需求,用RDD编程实现不仅代码量更大,而且会极有可能因为程序员不良操作加重集群的开销,而采用DataFrame API组合编程有时仅需一行代码即可实现复杂的分析需求。
2.4 执行SQL查询
SparkSession为用户提供了直接执行sql语句的SparkSession.sql(String sqlText)方法,sql语句可直接作为字符串传入sql()方法中,sql查询所得到结果依然为DataFrame对象。在Spark SQL模块上直接执行sql语句的查询需要首先将标志着结构化数据源的DataSet对象注册成临时表,进而在sql语句中对该临时表进行查询操作,具体步骤如下例所示:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// 注册临时表
json.createOrReplaceTempView("student");
// sql查询 用select * from student 也可以
Dataset<Row> sql = sparkSession.sql("select id,name,age,phone from student");
sql.show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();结果显示:

由上述操作,可看出DataSet是Spark SQL核心的数据抽象,读取的数据源需要转化成DataSet对象,才能利用DataSet各种API进行丰富操作,也可将DataSet注册成临时表,从而直接执行SQL查询,而DataFrame上的操作之后返回的也是DataFrame对象。
另外,因为本小结所讲述的是如何通过SparkSession提供的SQL接口直接进行SQL查询,而关于具体完成业务需求所需的SQL语句如何来编写,大家可以直接百度查询相关SQL教程进行学习。Spark SQL的SQL接口全面支持SQL的select标准语法,包括SELECT DISTINCT、from子句、where子句、order by字句、group by子句、having子句、join子句,还有典型的SQL函数,例如avg()、count()、max()、min()等,除此之外,Spark SQL在此基础上还提供了大量功能强大的可用函数,可嵌入sql语句中使用,有聚合类函数、时间控制类函数、数学统计类函数、字符串列控制类函数等,感兴趣或有这方面分析需求的读者具体可查看官方文档http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql
2.5 全局临时表
全局临时表(globe temporary view )于临时表(temporary view)是相对的,全局临时表的作用范围是某个Spark应用程序内所有会话(SparkSession),它会持续存在,在所有会话中共享,直到该Spark应用程序终止
因此,在同一个应用中,在不同的session中都需要用到一张临时表,呢么该临时表可以注册为全局临时表,避免多余I/O,提高系统执行效率,当然如果某个临时表只在整个应用中的某个session中使用,仅需要注册为局部临时表,避免不必要的内存存储全局临时表
注意,全局临时表与系统保留的数据库global_temp相关联,引用时需要使用global_temp标识。
实例:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// 注册临时表
json.createOrReplaceTempView("student");
// sql查询
Dataset<Row> sql = sparkSession.sql("select * from student");
sql.show();
// 注册为全局临时表
try {
json.createGlobalTempView("student_glob");
} catch (AnalysisException e) {
e.printStackTrace();
}
// 当前session查询全局临时表
Dataset<Row> sqlGlob = sparkSession.sql("select * from global_temp.student_glob");
sqlGlob.show();
// 创建新的SparkSeesion 查询全局临时表
Dataset<Row> newSqlGlob = sparkSession.newSession().sql("select * from global_temp.student_glob");
newSqlGlob.show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();显示的结果都是一样的。
2.6 DataSet实现WordCount
Dataset[T]中对象的序列化并不使用Java标准序列化或Kryo,而是使用专门的编码器对对象进行序列化以便通过网络进行处理或传输。虽然编码器和标准序列化都负责将对象转换为字节,但编码器是根据Dataset[T]的元素类型(T)动态生成,并且允许Spark无须将字节反序列化回对象的情况下即可执行许多操作(如过滤、排序和散列),因此避免了不必要的反序列化导致的资源浪费,更加高效。
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<String> stringDataset = sparkSession.read().textFile("D:\\sparksqlfile\\jsondata\\word.txt");
// 分割每行的字符串
Dataset<String> dataset = stringDataset.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] split = s.split("\t", -1);
return Arrays.asList(split).iterator();
}
},Encoders.STRING());
// 根据key值分组
KeyValueGroupedDataset<String, String> groupByKey = dataset.groupByKey(new MapFunction<String, String>() {
@Override
public String call(String value) throws Exception {
return value.toLowerCase();
}
},Encoders.STRING());
// 求和展示数据
groupByKey.count().show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();日志打印:
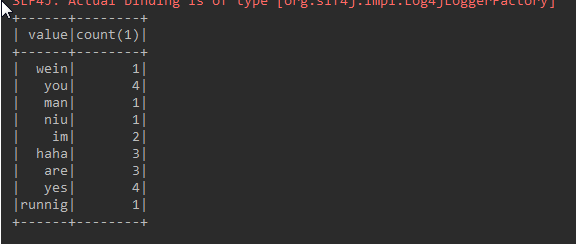
元数据:
im runnig man
you are yes haha
yes you wein im niu
you are yes haha
you are yes haha2.7 将RDDs转化为DataFrame
除了调用SparkSesion.read().json/csv/orc/parquet/jdbc方法从各种外部结构化数据源创建DataFrame对象外,Spark SQL还支持将已有的RDD转化为DataSet对象,但是需要注意的是,并不是由任意类型对象组成的RDD均可转化为DataSet对象,只有当组成RDD[T]的每一个T对象内部具有公有且鲜明的字段结构时,才能隐式或显式地总结出创建DataSet对象所必要的结构信息(Schema)进行转化,进而在DataSet上调用RDD所不具备的强大丰富的API,或执行简洁的SQL查询。
Spark SQL支持将现有RDDs转换为DataSet的两种不同方法,其实也就是隐式推断或者显式指定DataSet对象的Schema。
实例数据:
王明 13 17865321121 南京市天龙寺小区一栋 五年级一班
刘红 14 15643213452 南京市天龙寺小区二栋 五年级一班
张三 15 15678941247 南京市天龙寺小区三栋 五年级二班
诸葛刘芳 14 14578654123 南京市天龙寺小区一栋 五年级一班1.使用反射机制(Reflection)推理出schema结构信息
第一种将RDDs转化为DataFrame的方法是使用SparkSQL内部反射机制自动推断包含特定类型对象的RDD的schema(RDD的结构信息)进行隐士转化。采用这种方式转化为DataSet对象,往往是因为被转化的RDD[T]所包含的T对象本身就是具有典型一维表严格的字段结构的对象,因此SparkSQL很容易就可以自动推断出合理的Schema。这种基于反射机制隐式地创建DataSet的方法往往仅需要简洁的代码即可完成转化,并且运行效果良好。
SparkSQL的Scala接口支持自动包含样例类(case class)对象的RDD转换为DataSet对象。在样例类的声明中已预先定义了表的结构信息,内部通过反射机制即可读取样例类的参数的名称,类型,转化为DataSet对象的Schema。样例类不仅可以包含Int,Double,String,这样的简单数据类型,也可以嵌套或包含复杂类型,例如Seq或Arrays。
实例:将学生样例对象的RDD隐式转换为DataSet对象
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
JavaRDD<String> stringRDD = sparkSession.sparkContext().textFile("D:\\sparksqlfile\\jsondata\\student.txt",1).toJavaRDD();
// JavaRDD<String> 转为 JavaRDD<Person>
JavaRDD<Person> personRDD = stringRDD.map(new Function<String, Person>() {
@Override
public Person call(String v1) {
String[] split = v1.split("\t", -1);
return new Person(split[0],Integer.valueOf(split[1]),split[2],split[3],split[4]);
}
});
// RDD 转换为 DataSet
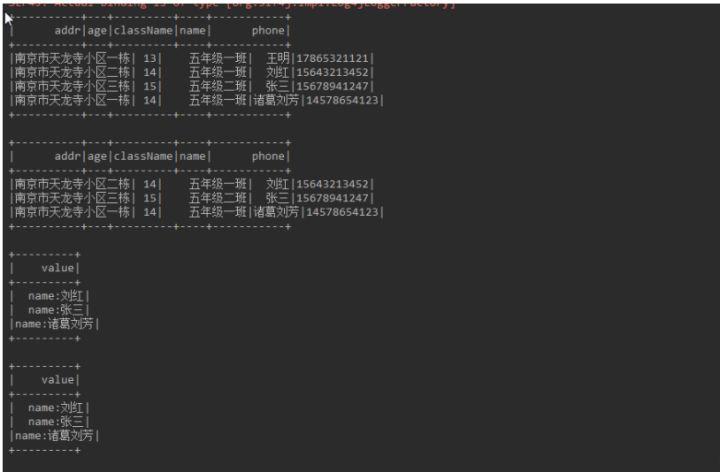
Dataset<Row> personDataSet = sparkSession.createDataFrame(personRDD, Person.class);
personDataSet.show();
// 注册临时表
personDataSet.createOrReplaceTempView("person");
// 查询临时表
Dataset<Row> selectDataSet = sparkSession.sql("select * from person where age between 14 and 15");
selectDataSet.show();
// 遍历DataSet 通过下标获取 name的Ds
Dataset<String> nameDs = selectDataSet.map(new MapFunction<Row, String>() {
@Override
public String call(Row value) {
// Row 的 字段排序是按照字典排序的 所以 第四个才是name字段
return "name:"+value.getString(3);
}
}, Encoders.STRING());
nameDs.show();
// Row通过指定字段名获取字段值 返回Object对象
Dataset<String> nameDs2 = selectDataSet.map(new MapFunction<Row, String>() {
@Override
public String call(Row value) {
return "name:"+value.getAs("name");
}
}, Encoders.STRING());
nameDs2.show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}日志截图:
2.开发者指定Schema
RDD转化为Dataset的第二种方法是通过编程接口,允许先创建一个schema,然后将其应用到现有的RDD[Row],较前一种方法由样例类或基本数据类型(Int,String)对象组成的RDD通过sparkSession.createDataFrame直接隐式转换为iDataset不同,不仅需要根据需求以及数据结构构建schema,而且需要将RDD[T]转化为Row对象组成的RDD[Row],这样方法虽然代码多了一些,但也提供了更高的自由度和灵活性。
当case类不能提前定义时(例如:数据集结构信息已经包含在每一行,一个文本数据集的字段对不同用户来说需要被解析成不同的字段名),这时就可以通过以下三部完成Dataset的转换:
(1):根据需求从源RDD转化为RDD of Rows
(2):创建由符合在步骤1中创建的RDD中的Rows结构的StructType表示的模式。
(3):通过SparkSession提供的createDataFrame方法将模式应用于行的RDD。
由此可见,将RDD转化为Dataset的实质就是,赋予RDD内部包含特定类型对象的结构信息,使Dataset掌握更丰富的结构与信息(可以理解为传统数据库的表头,表头包含个字段名称,类型等信息),如此一来,便更好地说明Dateset支持sql查询了。
实例:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
JavaRDD<String> peopleRDD = sparkSession.sparkContext().textFile("D:\\sparksqlfile\\jsondata\\student.txt",1).toJavaRDD();
String[] schemaString = {"name", "age"};
// 创建自定义schema
List<StructField> fields = new ArrayList<>();
for (String s : schemaString) {
fields.add(DataTypes.createStructField(s,DataTypes.StringType,true));
}
StructType schema = DataTypes.createStructType(fields);
// JavaRDD<String> 转为JavaRDD<Row>行记录
JavaRDD<Row> rowRdd = peopleRDD.map(new Function<String, Row>() {
@Override
public Row call(String v1) {
String[] split = v1.split("\t", -1);
return RowFactory.create(split[0],split[1]);
}
});
// JavaRDD转DataSet
Dataset<Row> personDataset = sparkSession.createDataFrame(rowRdd, schema);
personDataset.show();2.8 用户自定义函数
除了利用Dataset丰富的内置函数变成外,还可以自己编程满足特定分析需求的用户自定义函数(UDF)并加以使用,SparkSQL中主要支持创建用户自定义无类型聚合函数和用户自定义强类型聚合函数
1.用户自定义无类型聚合函数
用户自定义的无类型聚合函数必须继承UserDefinedAggregateFunction抽象类,进而重写父类中的抽象成员变量和成员方法。其实重写父类抽象成员变量,方法的过程即是实现用户自定义函数的输入,输出规范以及计算逻辑的过程。
实例:求取平均值的函数
UDF函数代码:
public class MyAverage extends UserDefinedAggregateFunction {
private StructType inputSchema;
private StructType bufferSchema;
public MyAverage() {
ArrayList<StructField> inputFields = new ArrayList<>();
inputFields.add(DataTypes.createStructField("inputColumn",DataTypes.LongType,true));
inputSchema = DataTypes.createStructType(inputFields);
ArrayList<StructField> bufferFields = new ArrayList<>();
bufferFields.add(DataTypes.createStructField("sum",DataTypes.LongType,true));
bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType,true));
bufferSchema = DataTypes.createStructType(bufferFields);
}
// Data types of input arguments of this aggregate function
// 聚合函数输入参数的数据类型(其实是该函数所作用的Dataset指定列的数据类型)
@Override
public StructType inputSchema() {
return inputSchema;
}
// Data types of values in the aggregation buffer
// 聚合函数的缓冲器结构,返回之前定义了用于记录累加值和累加数的字段结构
@Override
public StructType bufferSchema() {
return bufferSchema;
}
// The data type of the returned value
// 聚合函数返回值的数据类型
@Override
public DataType dataType() {
return DataTypes.DoubleType;
}
// Whether this function always returns the same output on the identical input
// 此函数是否始终在相同输入上返回相同输出
@Override
public boolean deterministic() {
return true;
}
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
// 初始化给定的buffer聚合缓冲器
// buffer 聚合缓冲器其本身是一个Row对象,因此可以调用其标准方法访问buffer内的元素,例如在索引处检索一个值
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0,0L);
buffer.update(1,0L);
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
if (!input.isNullAt(0)){
long updatedSum = buffer.getLong(0) + input.getLong(0);
long updatedCount = buffer.getLong(1)+1;
buffer.update(0,updatedSum);
buffer.update(1,updatedCount);
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
long mergedSum = buffer1.getLong(0) + buffer2.getLong(0);
long mergedCount = buffer1.getLong(1) + buffer2.getLong(1);
buffer1.update(0,mergedSum);
buffer1.update(1,mergedCount);
}
@Override
public Object evaluate(Row buffer) {
return ((double)buffer.getLong(0))/buffer.getLong(1);
}
}运行代码:
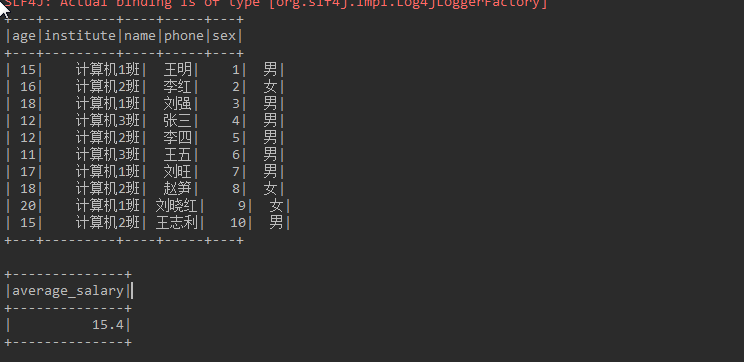
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("XXXXXXXXXX").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件
Dataset<Row> df = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student5.json");
// 注册自定义函数
sparkSession.udf().register("myAverage",new MyAverage());
// 显示原始数据
df.createOrReplaceTempView("student");
df.show();
// 使用自定义UDF求平均值
Dataset<Row> result = sparkSession.sql("SELECT myAverage(age) as average_salary FROM student");
result.show();
}日志打印:
2.用户自定义强类型聚合函数
用户自定义强类型聚合函数需继承Aggregator抽象类,同样需要重写父类抽象方法(reduce,merge,finish)以实现自定义聚合函数的计算逻辑。用户定义的强类型聚合函数相比于前一种UDF,内部与特定数据集的数据类型紧密结合,增强了紧密型,安全性,但降低了适用性。
实例:求用户平均值的强类型聚合函数
数据实体类:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java