
图解MySQL 8.0优化器查询解析篇
一 背景和架构
我们都知道,利用编写程序来动态实现我们应用所需要的逻辑,从而程序执行时得到我们需要的结果。那么数据库就是一种通过输入SQL字符串来快速获取数据的应用。当然,假设没有数据库这种系统应用,用程序如何实现呢?我们可能会发现,即使不管数据如何存储、数据是否并发访问,仍然需要不断通过修改程序处理不同应用对数据的不同请求。比如大数据领域,我们通常通过非关系型数据库的API,实现对数据的获取。然而这种方式虽然入门简单,但是维护极难,而且通用性不强,即使不断进行软件架构设计或者抽象重构,仍然需要不断地变换应用,这也是为何非关系型数据库回头拥抱数据库SQL优化器的原因。
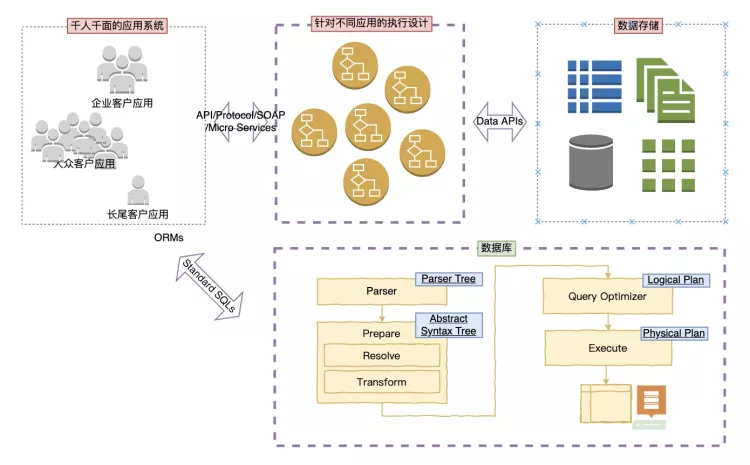
SQL优化器本质上是一种高度抽象化的数据接口的实现,经过该设计,客户可以使用更通用且易于理解的SQL语言,对数据进行操作和处理,而不需要关注和抽象自己的数据接口,极大地解放了客户的应用程序。
本文就来通过图形解说的方式介绍下MySQL 8.0 SQL优化器如何把一个简单的字符串(SQL),变成数据库执行器可以理解的执行序列,最终将数据返还给客户。强大的优化器是不需要客户关注SQL如何写的更好来更快获得需要的数据,因此优化器对原始SQL一定会做一些等价的变化。在《MySQL 8.0 Server层最新架构详解》一文中我们重点介绍了MySQL最新版本关于Server层解析器、优化器和执行器的总体介绍,包括一些代码结构和变化的详细展示,并且通过simple_joins函数抛砖引玉展示了MySQL优化器在逻辑变换中如何简化嵌套Join的优化。本文我们会一步一步带你进入神奇的优化器细节,详细了解优化器优化部分的每个步骤如何改变着一个SQL最终的执行。
本文基于最新MySQL8.0.25版本,因为优化器转换部分篇幅比较长,我们分成两篇文章来介绍,第一部分介绍基于基本结构的Setup和Resolve的解析转换过程,第二部分介绍更为复杂的子查询、分区表和连接的复杂转换过程,大纲如下:
Setup and Resolve
- setup_tables : Set up table leaves in the query block based on list of tables.
- resolve_placeholder_tables/merge_derived/setup_table_function/setup_materialized_derived : Resolve derived table, view or table function references in query block.
- setup_natural_join_row_types : Compute and store the row types of the top-most NATURAL/USING joins.
- setup_wild : Expand all '*' in list of expressions with the matching column references.
- setup_base_ref_items : Set query_block's base_ref_items.
- setup_fields : Check that all given fields exists and fill struct with current data.
- setup_conds : Resolve WHERE condition and join conditions.
- setup_group : Resolve and set up the GROUP BY list.
- m_having_cond->fix_fields : Setup the HAVING clause.
- resolve_rollup : Resolve items in SELECT list and ORDER BY list for rollup processing.
- resolve_rollup_item : Resolve an item (and its tree) for rollup processing by replacing items matching grouped expressions with Item_rollup_group_items and updating properties (m_nullable, PROP_ROLLUP_FIELD). Also check any GROUPING function for incorrect column.
- setup_order : Set up the ORDER BY clause.
- resolve_limits : Resolve OFFSET and LIMIT clauses.
- Window::setup_windows1: Set up windows after setup_order() and before setup_order_final().
- setup_order_final: Do final setup of ORDER BY clause, after the query block is fully resolved.
- setup_ftfuncs : Setup full-text functions after resolving HAVING.
- resolve_rollup_wfs : Replace group by field references inside window functions with references in the presence of ROLLUP.
二 详细转换过程
转换的整个框架是由Query_expression到Query_block调用prepare函数(sql/http://sql_resolver.cc)并且根据不同转换规则的要求自顶向下或者自底向上的过程。
图片
1 传递null到join的内表列表(propagate_nullability)
prepare开始先要处理nullable table,它指的是table可能包含全为null的row,根据JOIN关系(top_join_list)null row可以被传播。如果能确定一个table为nullable会使得一些优化退化,比如access method不能为EQ_REF、outer join不能优化为inner join等。
2 解析设置查询块的leave_tables(setup_tables)
SELECT
t1.c1
FROM t1,
(SELECT
t2.c1
FROM t2,
(SELECT
t3.c1
FROM t3
UNION
SELECT
t4.c1
FROM t4) AS t3a) AS t2a;未在setup_table调用之前,每个Query_block的leaf_tables是为0的。
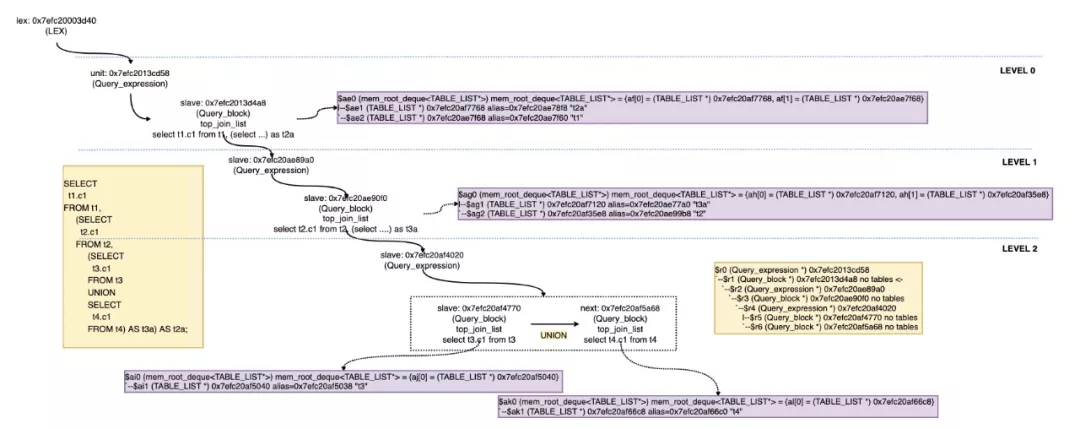
该函数的作用就是构建leaf_tables,包括base tables和derived tables列表,用于后续的优化。setup_tables并不会递归调用,而是只解决本层的tables,并统计出本层derived table的个数。但是随后会调用resolve_placeholder_tables()->resolve_derived()->derived(Query_expression)::prepare->Query_block::prepare来专门递归处理derived table对应的Query_expression。
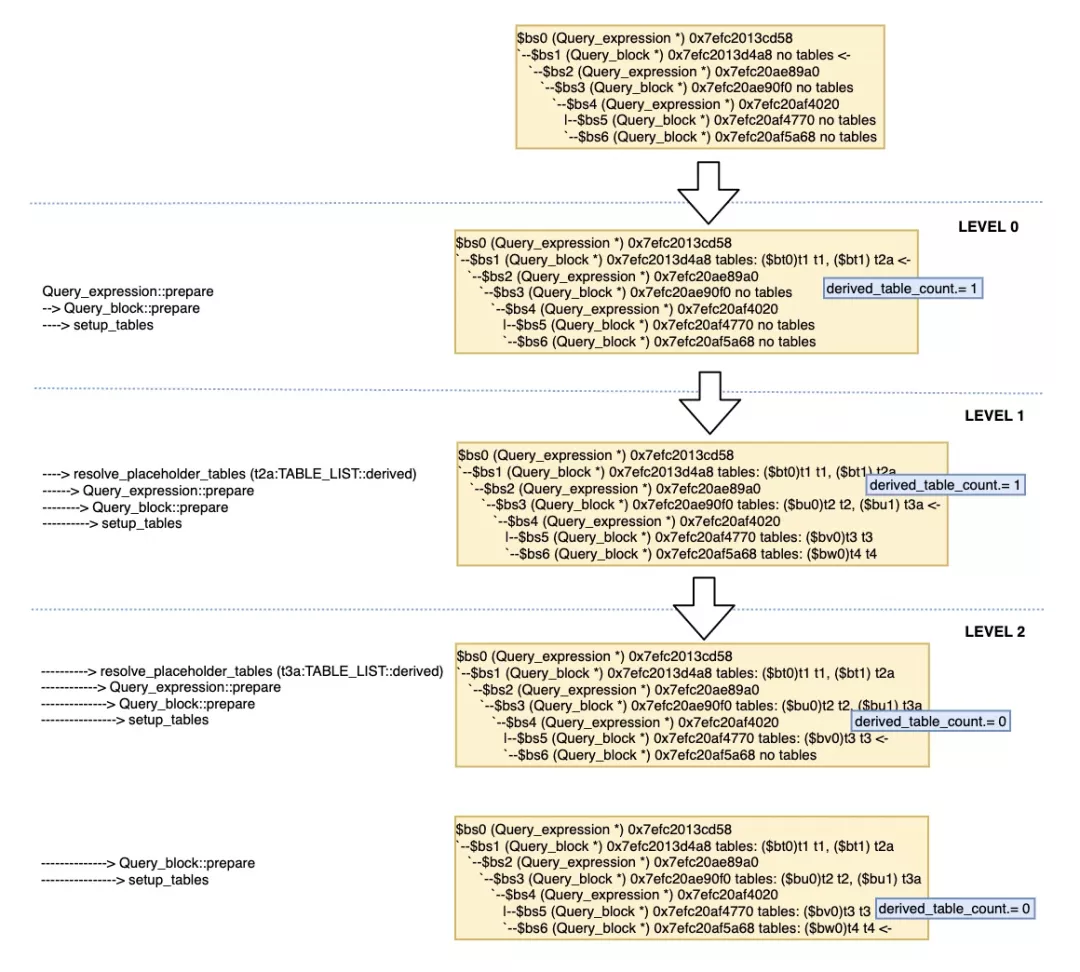
接下来我们根据prepare的调用顺序,继续看下针对于derived table处理的函数resolve_placeholder_tables。
3 解析查询块Derived Table、View、Table函数 (resolve_placeholder_tables)
这个函数用于对derived table、view和table function的处理,如果该table已经merged过了,或者是由于使用transform_grouped_to_derived()被调用到,已经决定使用materialized table方式,则直接忽略。
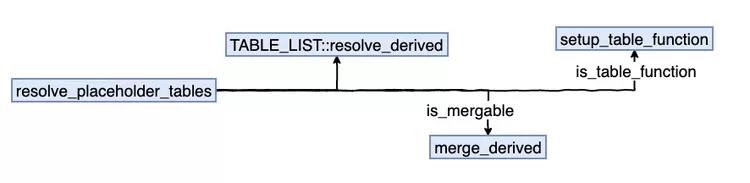
前面已经介绍过resolve_derived()的作用,我们重点介绍merge_derived()函数,merge_derived是改变Query_expression/Query_block框架结构,将derived table或者view合并到到query block中。
merge_derived 处理和合并Derived table
1)merge_derived transformation的先决条件
外层query block是否允许merge(allow_merge_derived)
- 外层query block为nullptr
- 外层query expression的子查询为nullptr,derived table是第一层子查询
- 外层的外层query block可以allow_merge_derived=true,或者不包括外层的外层query block话是否为SELECT/SET
- 外层lex是否可以支持merge(lex->can_use_merged()+lex->can_no_use_merged())
- derived table是否已经被标记为需要物化materialize,比如创建视图的方法是CREATE ALGORITHM=TEMPTABLE VIEW(derived_table->algorithm == VIEW_ALGORITHM_TEMPTABLE)
整个dervived table所在的查询表达式单元中,不能是(Query_expression::is_mergeable() ):
- Union查询
- 包含聚集、HAVING、DISTINCT、WINDOWS或者LIMIT
- 没有任何table list
- HINT或者optimizer_switch没有禁止derived_merge
heuristic建议合并(derived_query_expressionmerge_heuristic())
- 如果derived table包含的子查询SELECT list依赖于自己的列时,不支持
- 如果是dependant subquery需要多次执行时,不支持
- derived table中如果查询块包含SEMI/ANTI-JOIN,并指定STRAIGHT_JOIN时,不支持
- 如果合并的derived table和现有query block的leaf table count大约 MAX_TABLES时,不支持
2)merge_derived transformation的转换过程
- 利用derived_table->nested_join结构来辅助处理OUTER JOIN的情况。
- 把derived table中的表merge到NESTED_JOIN结构体(derived_table->merge_underlying_tables())
- 将derived table中的所有表连接到父查询的table_list列表中,同时把derived table从父查询中删除。
- 对父查询的所有相关数据结构进行重新计算(leaf_table_count,derived_table_count,table_func_count,materialized_derived_table_count,has_sj_nests,has_aj_nests,partitioned_table_count,cond_count,between_count,select_n_having_items)
- 传播设置父查询OPTION_SCHEMA_TABLE(add_base_options())和如果是外查询JOIN的内表,传播设置nullable属性(propagate_nullability())
- 合并derived table的where条件到外查询中(merge_where())
- 建立对derived table需要获取的列的引用(create_field_translation())
- 将Derived table的结构从父查询中删除(exclude_level())
- 将derived table中的列或者表的重命名合并到父查询(fix_tables_after_pullout()/repoint_contexts_of_join_nests())
- 因为已经把derived table中包含的表merge到了父查询,所以需要对TABLE_LIST中的表所在的位置进行重新定位(remap_tables())
- 将derived table合并到父查询之后,需要重新修改原来derived table中所有对derived table中所有列的引用(fix_tables_after_pullout())
如果derived table中包含ORDER By语句,如果满足下列条件,derived table将会保留ORDER BY并合并到父查询中,其他情况ORDER BY将会被忽略掉:
- 如果父查询允许排序并且正好是只有derived table
- 不是一个UNION
- 可以有WHERE条件,但是不能有group by或聚合函数
- 本身并不是有序的
过程简化为:
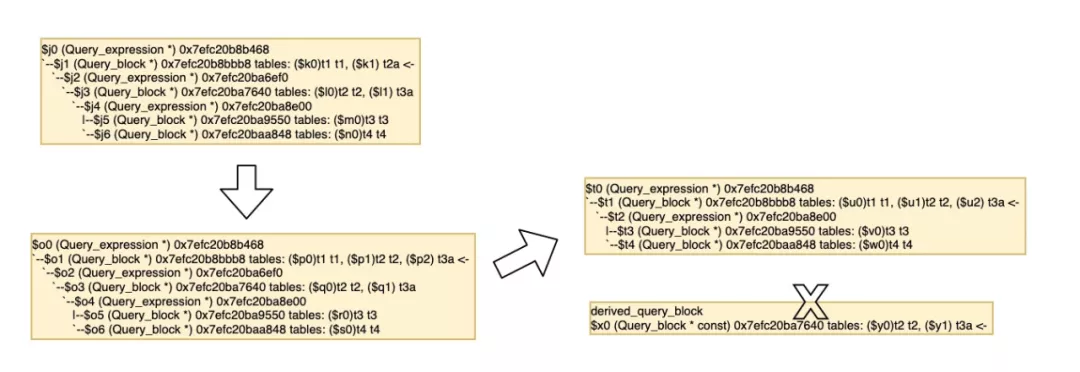
merge_derived 图解过程
看起来官方的derived merge还是不够完美,无法自底向上的递归merge
包含的opt trace:
trace_derived.add_utf8_table(derived_table)
.add("select#", derived_query_block->select_number)
.add("merged", true);
trace_derived.add_alnum("transformations_to_derived_table", "removed_ordering");该优化可以通过set optimizer_switch="derived_merge=on/off"来控制。
setup_materialized_derived 设置物化Derived Table
对于剩下不能采用 merge 算法的 derived table ,会转为materialize 物化方式去处理。但此时只是做一些变量设置等预处理,实际的物化执行是在executor阶段执行。
- setup_materialized_derived_tmp_table(): 设置一个临时表包含物化Derived Table的所有行数据。
- check_materialized_derived_query_blocks(): 设置属于当前Derived Table所在的查询块结构。
trace_derived.add_utf8_table(this)
.add("select#", derived->first_query_block()->select_number)
.add("materialized", true);setup_table_function 处理表函数
如果 query block 中有 table function,整个过程会处理两遍。第一遍会跳过 table function 的 table ,第二遍才专门再对table function 的 table 执行一遍上述逻辑。这里的考虑应该是先 resolve 了外部环境(相对于table function),因为有可能函数参数会有依赖外部的 derived table。
trace_derived.add_utf8_table(this)
.add_utf8("function_name", func_name, func_name_len)
.add("materialized", true);4 将SELECT *的通配符展开成具体的fields(setup_wild)
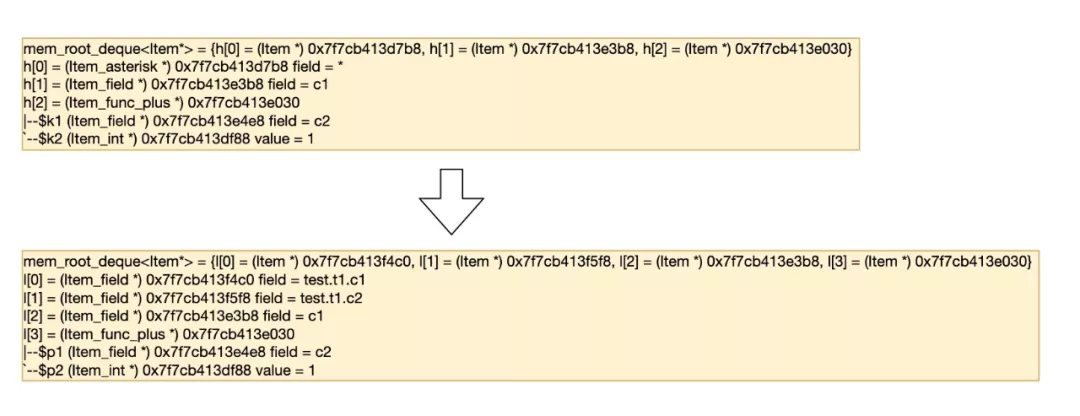
5 建立Query_block级别的base_ref_items(setup_base_ref_items)
base_ref_items记录了所有Item的位置,方便查询块的其他Item可以进行引用,或者通过Item_ref及其Item_ref子类进行直接引用,例如子查询的引用(Item_view_ref)、聚合函数引用(Item_aggregate_ref)、外查询列的引用(Item_outer_ref)、subquery 子查询产生NULL value的引用辅助(Item_ref_null_helper)。
举例说明比较复杂的Item_outer_ref:
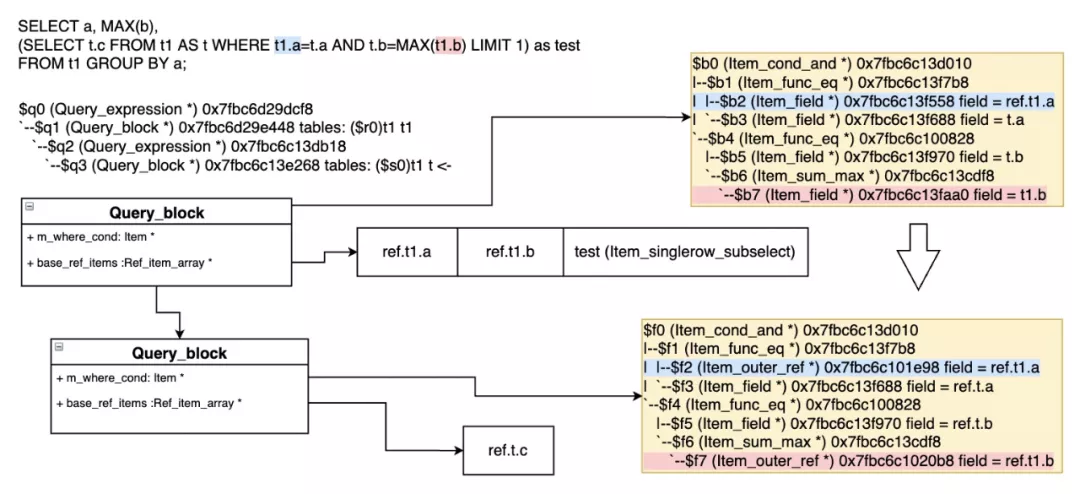
6 对select_fields进行fix_fields()和列权限检查(setup_fields)
下图是比较复杂的带子查询的fixed field过程。有些field和表关联,有的要添加相应的Item_xxx_ref引用。
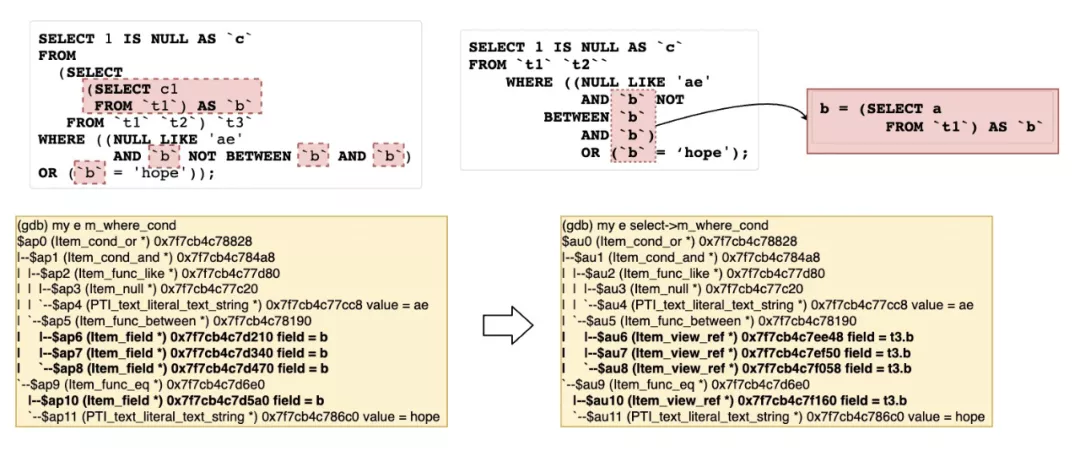
7 解析和fixed_fields WHERE条件和Join条件(setup_conds)
setup_join_cond如果有nested_join会递归调用setup_join_cond进行解析和设置。这里也顺带介绍下simplify_const_condition函数的作用,如果发现可以删除的const Item,则会用Item_func_true/Item_func_false来替代整个的条件,如图。

8 解析和设置ROLLUP语句(resolve_rollup)
在数据库查询语句中,在 GROUP BY 表达式之后加上 WITH ROLLUP 语句,可以使得通过单个查询语句来实现对数据进行不同层级上的分析与统计。
SELECT YEAR,
country,
product,
SUM(profit) AS profit
FROM sales
GROUP BY YEAR,
country,
product WITH ROLLUP;
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | Finland | NULL | 1600 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | India | NULL | 1350 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2000 | USA | NULL | 1575 |
| 2000 | NULL | NULL | 4525 |
| 2001 | Finland | Phone | 10 |
| 2001 | Finland | NULL | 10 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2001 | USA | NULL | 3000 |
| 2001 | NULL | NULL | 3010 |
| NULL | NULL | NULL | 7535 |
+------+---------+------------+--------+
相当于做了下面的查询:
SELECT *
FROM
(SELECT YEAR,
country,
product,
SUM(profit) AS profit
FROM sales
GROUP BY YEAR,
country,
product
UNION ALL SELECT YEAR,
country,
NULL,
SUM(profit) AS profit
FROM sales
GROUP BY YEAR,
country
UNION ALL SELECT YEAR,
NULL,
NULL,
SUM(profit) AS profit
FROM sales
GROUP BY YEAR
UNION ALL SELECT NULL,
NULL,
NULL,
SUM(profit) AS profit
FROM sales) AS sum_table
ORDER BY YEAR, country, product;
+------+---------+------------+--------+
| YEAR | country | product | profit |
+------+---------+------------+--------+
| NULL | NULL | NULL | 7535 |
| 2000 | NULL | NULL | 4525 |
| 2000 | Finland | NULL | 1600 |
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | India | NULL | 1350 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | USA | NULL | 1575 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2001 | NULL | NULL | 3010 |
| 2001 | Finland | NULL | 10 |
| 2001 | Finland | Phone | 10 |
| 2001 | USA | NULL | 3000 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
+------+---------+------------+--------+排序由于有NULL的问题,所以分级汇总的效果非常难弄,而且group 列不同改变,SQL复杂度来回变化,而ROLLUP很简单就可以实现效果,下面看下rollup在解析过程做了什么样的转换达到了意想不到的效果。

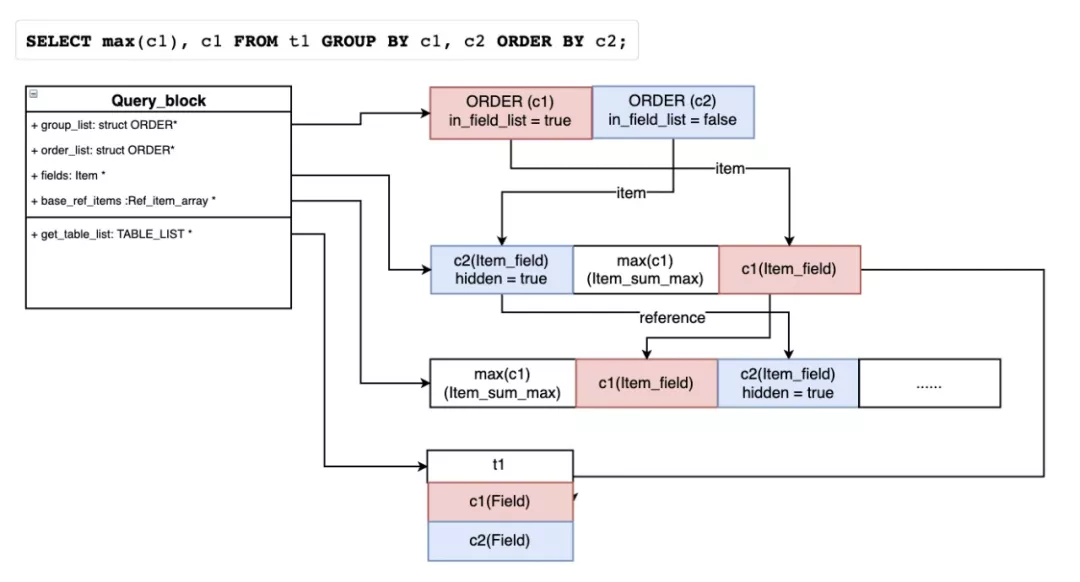
9 解析和设置GROUP BY/ORDER BY语句(setup_group/setup_order)
其中一个函数find_order_in_list(): 尝试在select fields里去寻找可以映射的列,否则就得在最后投影的all fields里加上当前列,同时也做fix_fields。
- m_having_cond->fix_fields : 对having条件进行fixed_fields。
- resolve_limits : 处理OFFSET和LIMIT子句(offset_limit和select_limit的Items)。
- setup_ftfuncs : 如果有full-text的函数,对相关Item进行fix_fields。
remove_redundant_subquery_clause : 对于Table Subquery的表达式,通常是IN/ANY/ALL/EXISTS/etc,如果没有聚合函数和Having子句,通常可以考虑删除不必要的ORDER/DISTINCT/GROUP BY。该函数支持三种REMOVE_ORDER | REMOVE_DISTINCT | REMOVE_GROUP,如果是SINGLEROW_SUBS的子查询,只考虑删除REMOVE_ORDER。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java