
MongoDB 一致性模型设计与实现
MongoDB 可调一致性(Tunable Consistency)概念及理论支撑
我们都知道,早期的数据库系统往往是部署在单机上的,随着业务的发展,对可用性和性能的要求也越来越高,数据库系统也进而演进为一种分布式的架构。这种架构通常表现为由多个单机数据库节点通过某种复制协议组成一个整体,称之为「Shared-nothing」,典型的如 MySQL,PG,MongoDB。
另外一种值得一提是,伴随着「云」的普及,为了发挥云环境下资源池化的优势而出现的「云原生」的架构,典型的如 Aurora,PolarDB,因这种架构通常采用存储计算分离和存储资源共享,所以称之为「Shared-storage」。
不管是哪种架构,在分布式环境下,根据大家耳熟能详的 CAP 理论,都要解决所谓的一致性(Consistency)问题,即在读写发生在不同节点的情况下,怎么保证每次读取都能获取到最新写入的数据。这个一致性即是我们今天要讨论的MongoDB 可调一致性模型中的一致性,区别于单机数据库系统中经常提到的 ACID 理论中的一致性。

CAP 理论中的一致性直观来看是强调读取数据的新近度(Recency),但个人认为也隐含了对持久性(Durability)的要求,即,当前如果已经读取了最新的数据,不能因为节点故障或网络分区,导致已经读到的更新丢失。关于这一点,我们后面讨论具体设计的时候也能看到 MongoDB 的一致性模型对持久性的关注。
既然标题提到了是可调(Tunable)一致性,那这个可调性具体又指的是什么呢?
这里就不得不提分布式系统中的另外一个理论,PACELC。PACELC 在 CAP 提出 10 年之后,即 2012 年,在一篇 Paper 中被正式提出,其核心观点是,根据 CAP,在一个存在网络分区(P)的分布式系统中,我们面临在可用性(A)和一致性(C)之间的选择,但除此之外(E),即使暂时没有网络分区的存在,在实际系统中,我们也要面临在访问延迟(L)和一致性(C)之间的抉择。所以,PACELC 理论是结合现实情况,对 CAP 理论的一种扩展。

而我们今天要讨论的 MongoDB 一致性模型的可调之处,指的就是调节 MongoDB 读写操作对 L 和 C 的选择,或者更具体的来说,是调节对性能(Performance——Latency、Throughput)和正确性(Correctness——Recency、Durability)的选择(Tradeoff)。
MongoDB 一致性模型设计
在讨论具体的实现之前,我们先来尝试从功能设计的角度,理解 MongoDB 的可调一致性模型,这样的好处是可以对其有一个比较全局的认知,后续也可以帮助我们更好的理解它的实现机制。
在学术中,对一致性模型有一些标准的划分和定义,比如我们听到过的线性一致性(Linearizable Consistency),因果一致性(Causal Consistency)等都在这个标准当中,MongoDB 的一致性模型设计自然也不能脱离这个标准。
但是,和很多其他的数据库系统一样,设计上需要综合考虑和其他子系统的关联,比如复制、存储引擎,具体的实现往往和标准又不是完全一致的。下面的第一个小节,我们就详细探讨标准的一致性模型和 MongoDB 一致性模型的关系,以对其有一个基本的认识。
在这个基础上,我们再来看在具体的功能设计上,MongoDB 的一致性模型是怎么做的,以及在实际的业务场景中是如何被使用的。
标准一致性模型和 MongoDB 一致性模型的关系
以复制为基础构建的分布式系统中,一致性模型通常可按照「以数据为中心(Data-centric)」和「以客户端为中心(Client-centric)」来划分,下图中的「Linearizable」,「Sequential」,「Causal」,「Eventual」即属于 Data-centric 的范畴,对一致性的保证也是由强到弱。
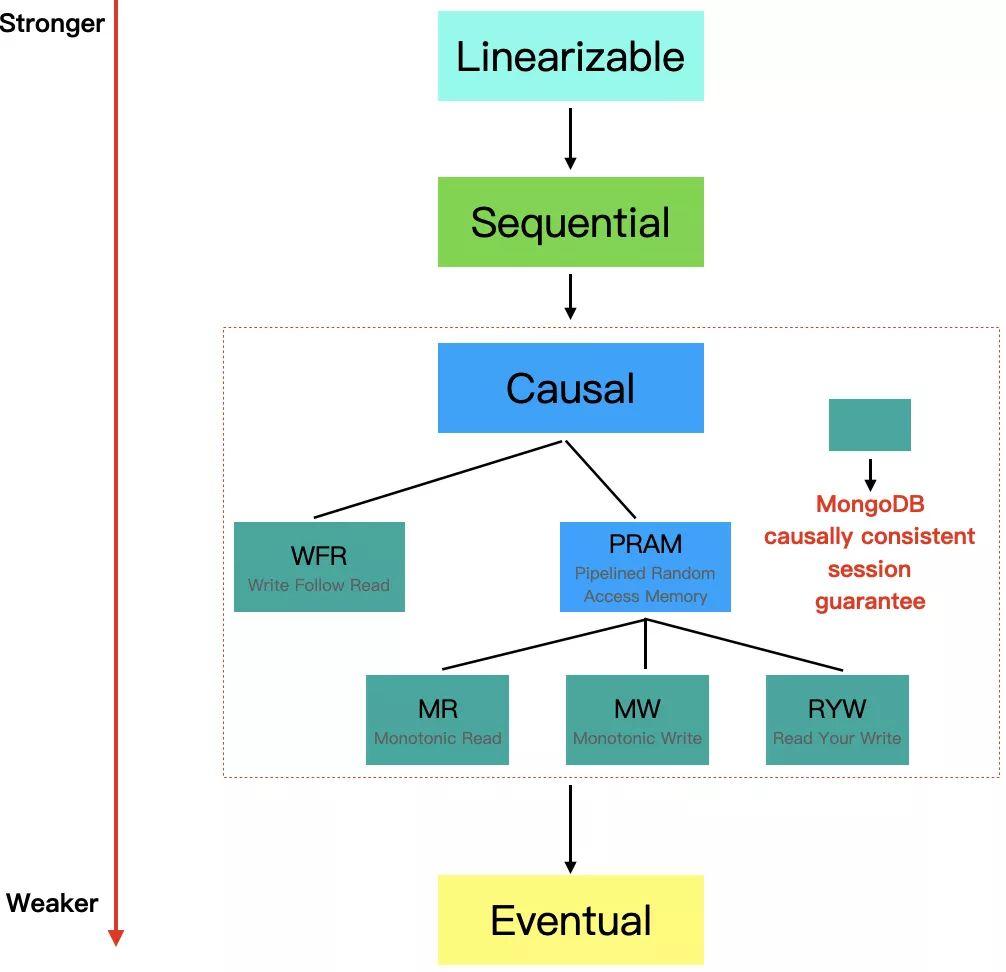
Data-centric 的一致性模型要求我们站在整个系统的角度看,所有访问进程(客户端)的读写顺序满足同一个特定的约束,比如,对于线性一致性(Linearizable)来说,它要求这个读写顺序和操作真实发生的时间(Real Time)完全一致,是最强的一致性模型,实际系统中很难做到,而对于因果一致性来说,只约束了存在因果关系的操作之间的顺序。
Data-centric 一致性模型虽然对访问进程提供了全局一致的视图,但是在真实的系统中,不同的读写进程(客户端)访问的往往是不同的数据,维护这样的全局视图会产生不必要的代价。举个例子,在因果一致性模型下,P1 执行了 Write1(X=1),P2 执行了 Read1(X=1),Write2(X=3),那么 P1 和 P2 之间就产生了因果关系,进而导致P1:Write1(X=1) 和 P2:Write2(X=3) 的可见顺序存在一个约束,即,需要其他访问进程看到的这两个写操作顺序是一样的,且 Write1 在前,但如果其他进程读的不是 X,显然再提供这种全局一致视图就没有必要了。
由此,为了简化这种全局的一致性约束,就有了 Client-centric 一致性模型,相比于 Data-centric 一致性模型,它只要求提供单客户端维度的一致性视图,对单客户端的读写操作提供这几个一致性承诺:「RYW(Read Your Write)」,「MR(Monotonic Read)」,「MW(Monotonic Write)」,「WFR(Write Follow Read)」。关于这些一致性模型的概念和划分,本文不做太详细介绍,感兴趣的可以看 CMU 的这两篇 Lecture(Lec1,Lec2),讲的很清晰。
MongoDB 的 Causal Consistency Session 即提供了上述几个承诺:RYW,MR,MW,WFR。但是,这里是 MongoDB 和标准不太一样的地方,MongoDB 的因果一致性提供的是 Client-centric 一致性模型下的承诺,而非 Data-centric。这么做主要还是从系统开销角度考虑,实现 Data-centric 下的因果一致性所需要的全局一致性视图代价过高,在真实的场景中,Client-centric 一致性模型往往足够了,关于这一点的详细论述可参考 MongoDB 官方在 SIGMOD'19 上 Paper 的 2.3 节。
Causal Consistency 在 MongoDB 中是相对比较独立一块实现,只有当客户端读写的时候开启 Causal Consistency Session 才提供相应承诺。
没有开启 Causal Consistency Session 时,MongoDB 通过 writeConcern 和 readConcern 接口提供了可调一致性,具体来说,包括线性一致性和最终一致性。最终一致性在标准中的定义是非常宽松的,是最弱的一致性模型,但是在这个一致性级别下 MongoDB 也通过 writeConcern 和 readConcern 接口的配合使用,提供了丰富的对性能和正确性的选择,从而贴近真实的业务场景。
MongoDB 可调一致性模型功能接口 —— writeConcern 和 readConcern
在 MongoDB 中,writeConcern 是针对写操作的配置,readConcern 是针对读操作的配置,而且都支持在单操作粒度(Operation Level)上调整这些配置,使用起来非常的灵活。writeConcern 和 readConcern 互相配合,共同构成了 MongoDB 可调一致性模型的对外功能接口。
writeConcern —— 唯一关心的就是写入数据的持久性(Durability)
我们首先来看针对写操作的 writeConcern,写操作改变了数据库的状态,才有了读操作的一致性问题。同时,我们在后面章节也会看到,MongoDB 一些 readConcern 级别的实现也强依赖 writeConcern 的实现。
MongoDB writeConcern 包含如下选项,
{ w: <value>, j: <boolean>, wtimeout: <number> }w,指定了这次的写操作需要复制并应用到多少个副本集成员才能返回成功,可以为数字或 “majority”(为了避免引入过多的复杂性,这里忽略基于 tag 的自定义 writeConcern)。w:0时比较特殊,即客户端不需要收到任何有关写操作是否执行成功的确认,具有最高性能。w: majority需要收到多数派节点(含 Primary)关于操作执行成功的确认,具体个数由 MongoDB 根据副本集配置自动得出。j,额外要求节点回复确认时,写操作对应的修改已经被持久化到存储引擎日志中。wtimeout,Primary 节点在等待足够数量的确认时的超时时间,超时返回错误,但并不代表写操作已经执行失败。
从上面的定义我们可以看出,writeConcern 唯一关心的就是写操作的持久性,这个持久性不仅仅包含由 j 决定、传统的单机数据库层面的持久性,更重要的是包含了由 w 决定、整个副本集(Cluster)层面的持久性。w 决定了当副本集发生重新选主时,已经返回写成功的修改是否会“丢失”,在 MongoDB 中,我们称之为被回滚。w 值越大,对客户端来说,数据的持久性保证越强,写操作的延迟越大。

这里还要提及两个概念,「local committed」 和 「majority committed」,对应到 writeConcern 分别为 w:1 和 w: majority,它们在后续实现分析中会多次涉及。每个 MongoDB 的写操作会开启底层 WiredTiger 引擎上的一个事务,如下图,w:1 要求事务只要在本地成功提交(local committed)即可,而 w: majority 要求事务在副本集的多数派节点提交成功(majority committed)。

readConcern —— 关心读取数据的新近度(Recency)和持久性(Durability)
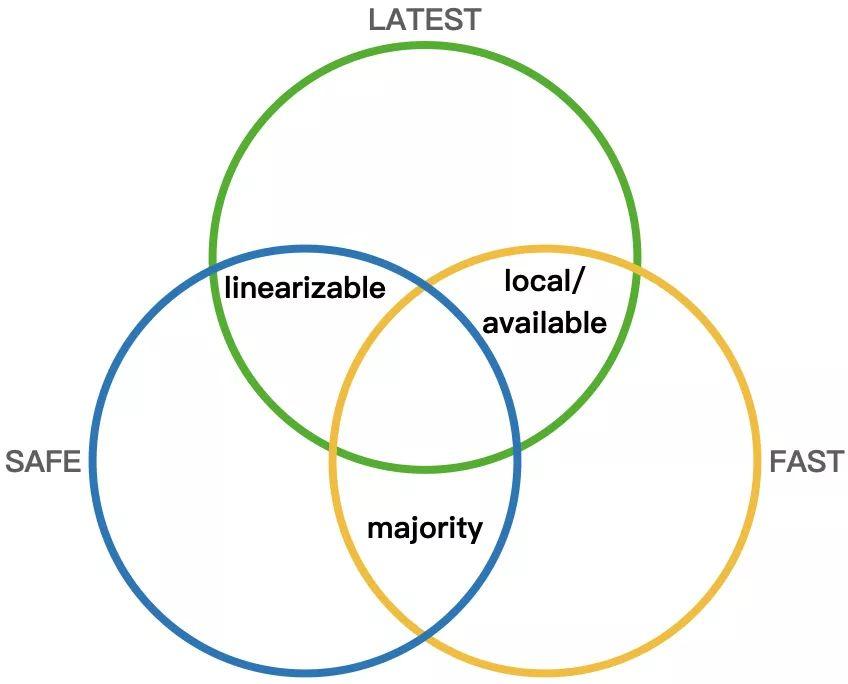
在 MongoDB 4.2 中包含 5 种 readConcern 级别,我们先来看前 4 种:「local」, 「available」, 「majority」, 「linearizable」,它们对一致性的承诺依次由弱到强。其中,「linearizable」即对应我们前面提到的标准一致性模型中的线性一致性,另外 3 种 readConcern 级别代表了 MongoDB 在最终一致性模型下,对 Latency 和 Consistency(Recency & Durability) 的取舍。
下面我们结合一个三节点副本集复制架构图,来简要说明这几个 readConcern 级别的含义。在这个图中,oplog 代表了MongoDB 的复制日志,类似于 MySQL 中的 binlog,复制日志上最新的x=<value>,表示了节点的复制进度。

- local/available:local 和 available 的语义基本一致,都是读操作直接读取本地最新的数据。但是,available 使用在 MongoDB 分片集群场景下,含特殊语义(为了保证性能,可以返回孤儿文档),这个特殊语义和本文的主题关联不大,所以后面我们只讨论 local readConcern。在这个级别下,发生重新选主时,已经读到的数据可能会被回滚掉。
- majority:读取「majority committed」的数据,可以保证读取的数据不会被回滚,但是并不能保证读到本地最新的数据。比如,对于上图中的 Primary 节点读,虽然
x=5已经是最新的已提交值,但是由于不是「majority committed」,所以当读操作使用 majority readConcern 时,只返回x=4。 - linearizable:承诺线性一致性,即,既保证能读取到最新的数据(Recency Guarantee),也保证读到数据不会被回滚(Durability Guarantee)。前面我们说了,线性一致性在真实系统中很难实现,MongoDB 在这里采用了一个相当简化的设计,当读操作指定 linearizable readConcern level 时,读操作只能读取 Primary 节点,而考虑到写操作也只能发生在 Primary,相当于 MongoDB 的线性一致性承诺被限定在了单机环境下,而非分布式环境,实现上自然就简单很多。考虑到会有重新选主的情况,MongoDB 在这个 readConcern level 下唯一需要解决的问题就是,确保每次读发生在真正的 Primary 节点上。后面分析具体实现我们可以看到,解决这个问题是以增加读延迟为代价的。
以上各 readConcern level 在 Latency、Durability、Recency 上的 Tradeoff 如下,
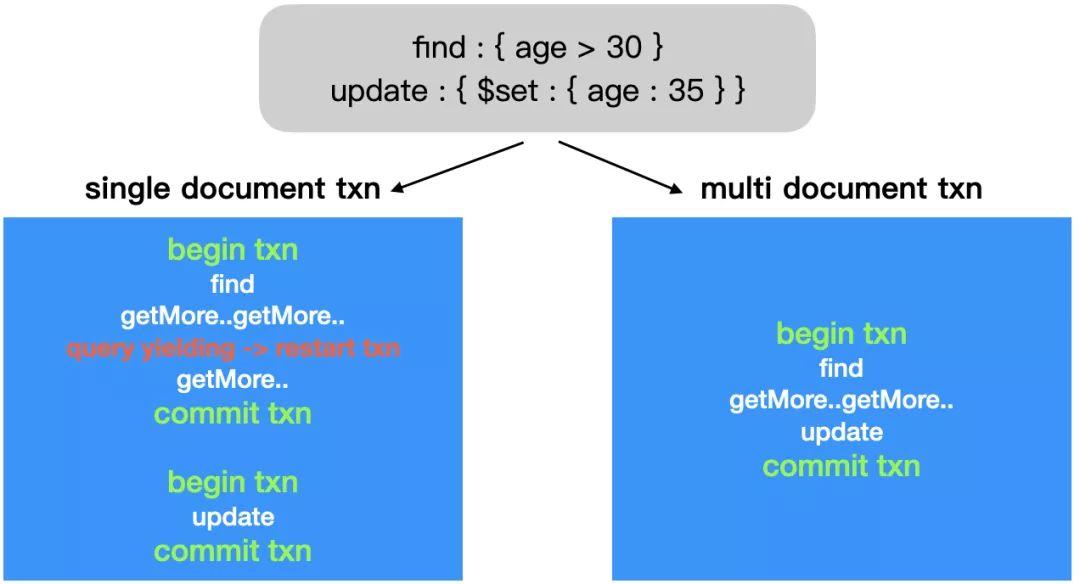
我们还有最后一种 readConcern level 没有提及,即「snapshot readConcern」,放在这里单独讨论的原因是,「snapshot readConcern」是伴随着 4.0 中新出现的多文档事务( multi-document transaction,其他系统也常称之为多行事务)而设计的,只能用在显式开启的多文档事务中。而在 4.0 之前的版本中,对于一条读写操作,MongoDB 默认只支持单文档上的事务性语义(单行事务),前面提到的 4 种 readConcern level 正是为这些普通的读写操作(未显式开启多文档事务)而设计的。
「snapshot readConcern」从定义上来看,和 majority readConcern 比较相似,即,读取「majority committed」的数据,也可能读不到最新的已提交数据,但是其特殊性在于,当用在多文档事务中时,它承诺真正的一致性快照语义,而其他的 readConcern level 并不提供,关于这一点,我们在后面的实现部分再详细探讨。
writeConcern 和 readConcern 的关系
在分布式系统中,当我们讨论一致性的时候,通常指的是读操作对数据的关注,即「what read concerns」,那为什么在 MongoDB 中我们还要单独讨论 writeConcern 呢?从一致性承诺的角度来看,writeConcern 从如下两方面会对 readConcern 产生影响,
- 「linearizable readConcern」读取的数据需要是以「majority writeConcern」写入且持久化到日志中,才能提供真正的「线性一致性」语义。考虑如下情况,数据写入到 majority 节点后,没有在日志中持久化,当 majority 节点发生重启恢复,那么之前使用 「linearizable readConcern」读取到的数据就可能丢失,显然和「线性一致性」的语义不相符。在 MongoDB 中,writeConcernMajorityJournalDefault 参数控制了,当写操作指定 「majority writeConcern」的时候,是否保证写操作在日志中持久化,该参数默认为 true。另外一种情况是,写操作持久化到了日志中,但是没有复制到 majority 节点,在重新选主后,同样可能会发生数据丢失,违背一致性承诺。
- 「majority readConcern」要求读取 majority committed 的数据,所以受限于不同节点的复制进度,可能会读取到更旧的值。但是如果数据是以更高的 writeConcern
w值写入的,即写操作在扩散到更多的副本集节点上之后才返回写成功,显然之后再去读取,「majority readConcern」能有更大的概率读到最新写入的值(More Recency Guarantee)。
所以,writeConcern 虽然只关注了写入数据的持久化程度,但是作为读操作的数据来源,也间接的也影响了 MongoDB 对读操作的一致性承诺。
writeConcern 和 readConcern 在实际业务中的应用
前面是对 writeConcern 和 readConcern 在功能定义上的介绍,可以看到,读写采用不同的配置,每个配置下面又包含不同的级别,这个接口设计对于使用者来说还是稍显复杂的(社区中也有不少类似的反馈),下面我们就来了解一下 writeConcern 和 readConcern 在真实业务中的统计数据以及几个典型应用场景,以加深对它们的理解。
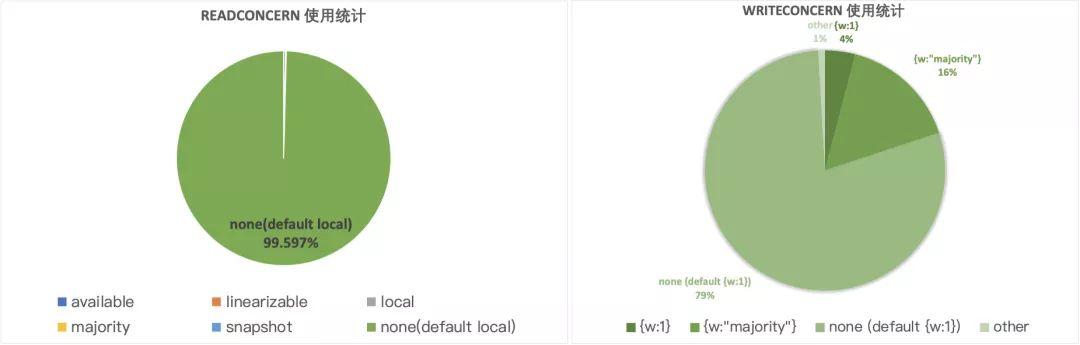
上面的统计数据来自于 MongoDB 自己的 Atlas 云服务中用户 Driver 上报的数据,统计样本在百亿量级,所以准确性是可以保证的,从数据中我们可以分析出如下结论,
- 大部分的用户实际上只是单纯的使用默认值
- 在读取数据时,99% 以上的用户都只关心能否尽可能快的读取数据,即使用 local readConcern
- 在写入数据时,虽然大部分用户也只要求写操作在本地写成功即可,但仍然有不小的比例使用了 majority writeConcern(16%,远高于使用 majority readConcern 的比例),因为写操作被回滚对用户来说通常都是更影响体验的。
此外,MongoDB 的默认配置({w:1} writeConcern, local readConcern)都是更倾向于保护 Latency 的,主要是基于这样的一个事实:主备切换事件发生的概率比较低,即使发生了丢数据的概率也不大。
统计数据给了我们一个 MongoDB readConcern/writeConcern 在真实业务场景下使用情况的直观认识,即,大部分用户更关注 Latency,而不是 Consistency。但是,统计数据同时也说明 readConcern/writeConcern 的使用组合是非常丰富的,用户通过使用不同的配置值来满足需求各异的业务场景对一致性和性能的要求,比如如下几个实际业务场景中的应用案例(均来自于 Atlas 云服务中的用户使用场景),
- Majority reads and writes:在这个组合下,意味着对数据安全性的关注是第一优先级的。考虑一个助学贷款的网站,网站的访问流量并不高,大约每分钟两次写入(提交申请),对于一个申请贷款的学生来说,显然不能接受自己成功提交的申请在后台 MongoDB 数据库发生重新选主时数据“丢失”,同样也不能接受获取到申请通过结果的情况下,再次查询,可能因为读取的数据被回滚,结果发生变化的情形,所以业务选择使用 majority readConcern & writeConcern 的组合,通过牺牲读写延迟来换取数据的安全性。
- Local reads and Majority writes:考虑一个餐饮评价的 App,比如大众点评,用户可能要花很大的精力来编辑一条精彩的评价,如果因为后端 MongoDB 实例发生主备切换导致评论丢失,对用户来说显然是不可接受的,所以用户评价的提交(写)需要使用 majority writeConcern,但是读到一条可能后续会因为回滚而“消失”的评价,对用户来说往往是可以接受,考虑到要兼顾性能,使用 local readConcern 显然是一个更优的选择。
- Multiple Write Concern Values:在同一个业务场景中,也不用只局限于一种 writeConcern/readConcern value,可以在不同的条件下使用不同的值来兼顾性能和一致性。比如,考虑一个文档系统,通常这样的系统在用户编辑文档时,会提供自动保存功能,对于非用户主动触发的发布或保存,自动保存的结果如果产生丢失,用户往往是感知不到的,而自动保存功能相对又是会比较频繁的触发(写压力更大),所以这种写动作使用 local writeConcern 显然更合理,写延迟更低,而低频的主动保存或发布,应该使用 majority writeConcern,因为这种情况用户对要保存的数据有明确的感知,很难接受数据的丢失。
MongoDB 因果一致性模型功能接口 —— Causal Consistency Session
前面已经提及了,相比于 writeConcern/readConcern 构建的可调一致性模型,MongoDB 的因果一致性模型是另外一块相对比较独立的实现,有自己专门的功能接口。MongoDB 的因果一致性是借助于客户端的 causally consistent session 来实现的,causally consistent session 可以理解为,维护一系列存在因果关系的读写操作间的因果一致性的执行载体。
causally consistent session 通过维护 Server 端返回的一些操作执行的元信息(主要是关于操作定序的信息),再结合 Server 端的实现来提供 MongoDB Causal Consistency 所定义的一致性承诺(RYW,MR,MW,WFR),具体原理我们在后面的实现部分再详述。
针对 causally consistent session,我们可以看一个简单的例子,比如现在有一个订单集合 orders,用于存储用户的订单信息,为了扩展读流量,客户端采用主库写入从库读取的方式,用户希望自己在提交订单之后总是能够读取到最新的订单信息(Read Your Write),为了满足这个条件,客户端就可以通过 causally consistent session 来实现这个目的,
""" new order """
with client.start_session(causal_consistency=True) as s1:
orders = client.get_database(
'test', read_concern=ReadConcern('majority'),
write_concern=WriteConcern('majority', wtimeout=1000)).orders
orders.insert_one(
{'order_id': "123", 'user': "tony", 'order_info': {}}, session=s1)
""" another session get user orders """
with client.start_session(causal_consistency=True) as s2:
s2.advance_cluster_time(s1.cluster_time) # hybird logical clock
s2.advance_operation_time(s1.operation_time)
orders = client.get_database(
'test', read_preference=ReadPreference.SECONDARY,
read_concern=ReadConcern('majority'),
write_concern=WriteConcern('majority', wtimeout=1000)).orders
for order in orders.find({'user': "tony"}, session=s2):
print(order)从上面的例子我们可以看到,使用 causally consistent session,仍然需要指定合适的 readConcern/writeConcern value,原因是,只有指定 majority writeConcern & readConcern,MongoDB 才能提供完整的 Causal Consistency 语义,即同时满足前面定义的 4 个承诺(RYW,MR,MW,WFR)。
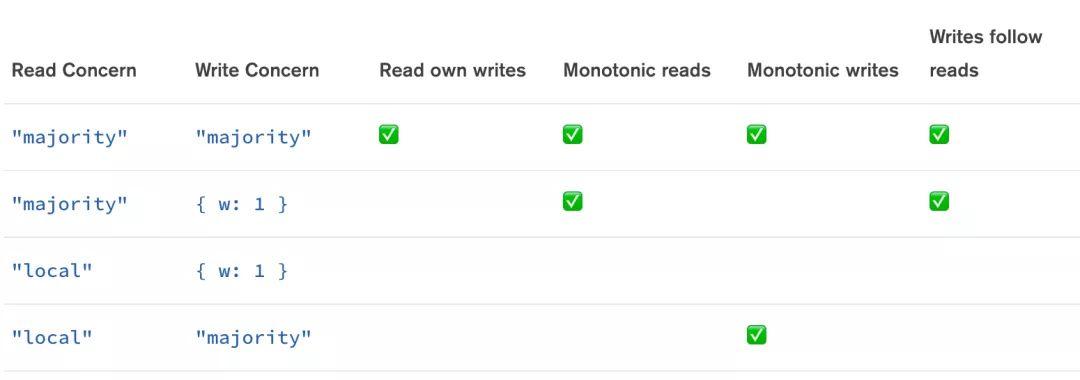
简单起见,我们只举例其中的一种情况:为什么在 {w: 1} writeConcern 和 majority readConcern 下,不能满足 RYW(Read Your Write)?
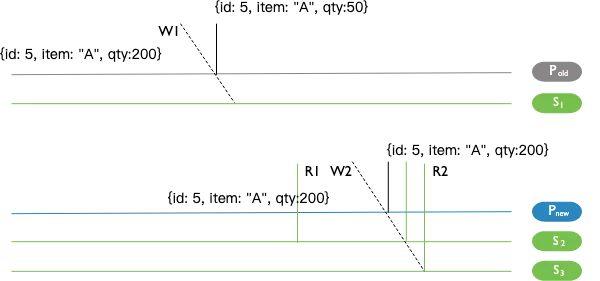
上图是一个 5 节点的副本集,当发生网络分区时(P~old~, S~1~ 和 P~new~, S~2~, S~3~ 分区),在 P~old~ 上发生的 W~1~ 写入因为使用了 {w:1} writeConcern ,会向客户端返回成功,但是因为没有复制到多数派节点,最终会在网络恢复后被回滚掉,R~1~ 虽然发生在 W~1~ 之后,但是从 S~2~ 并不能读取到 W~1~ 的结果,不符合 RYW 语义。其他情况下为什么不能满足 Causal Consistency 语义,可以参考官方文档,有非常详细的说明。
MongoDB 一致性模型实现机制及优化
前面对 MongoDB 的可调一致性和因果一致性模型,在理论以及具体的功能设计层面做了一个总体的阐述,下面我们就深入到内核层面,来看下 MongoDB 的一致性模型的具体实现机制以及在其中做了哪些优化。
writeConcern
在 MongoDB 中,writeConcern 的实现相对比较简单,因为不同的 writeConcern value 实际上只是决定了写操作返回的快慢。w <= 1 时,写操作的执行及返回的流程只发生在本地,并不会涉及等待副本集其他成员确认的情况,比较简单,所以我们只探讨 w > 1 时 writeConcern 的实现。
w>1 时 writeConcern 的实现
每一个用户的写操作会开启 WiredTiger 引擎层的一个事务,这个事务在提交时会顺便记录本次写操作对应的 Oplog Entry 的时间戳(Oplog 可理解为 MongoDB 的复制日志,这里不做详细介绍,可参考文档),这个时间戳在代码里面称之为lastOpTime。
// mongo::RecoveryUnit::OnCommitChange::commit -> mongo::repl::ReplClientInfo::setLastOp
void ReplClientInfo::setLastOp(OperationContext* opCtx, const OpTime& ot) {
invariant(ot >= _lastOp);
_lastOp = ot;
lastOpInfo(opCtx).lastOpSetExplicitly = true;
}引擎层事务提交后,相当于本地已经完成了本次写操作,对于 w:1 的 writeConcern,已经可以直接向客户端返回成功,但是当 w > 1 时就需要等待足够多的 Secondary 节点也确认写操作执行成功,这个时候 MongoDB 会通过执行 ReplicationCoordinatorImpl::_awaitReplication_inlock 阻塞在一个条件变量上,等待被唤醒,被阻塞的用户线程会被加入到 _replicationWaiterList 中。
Secondary 在拉取到 Primary 上的这个写操作对应的 Oplog 并且 Apply 完成后,会更新自身的位点信息,并通知另外一个后台线程汇报自己的 appliedOpTime 和 durableOpTime 等信息给 upstream(主要的方式,还有其他一些特殊的汇报时机)。
void ReplicationCoordinatorImpl::setMyLastAppliedOpTimeAndWallTimeForward(
...
if (opTime > myLastAppliedOpTime) {
_setMyLastAppliedOpTimeAndWallTime(lock, opTimeAndWallTime, false, consistency);
_reportUpstream_inlock(std::move(lock)); // 这里是向 sync source 汇报自己的 oplog apply 进度信息
}
...
}appliedOpTime和durableOpTime的含义和区别如下,appliedOpTime:Secondary 上 Apply 完一批 Oplog 后,最新的 Oplog Entry 的时间戳。durableOpTime:Secondary 上 Apply 完成并在 Disk 上持久化的 Oplog Entry 最新的时间戳, Oplog 也是作为 WiredTiger 引擎的一个 Table 来实现的,但 WT 引擎的 WAL sync 策略默认是 100ms 一次,所以这个时间戳通常滞后于appliedOpTime。
上述信息的汇报是通过给 upstream 发送 replSetUpdatePosition 命令来完成的,upstream 在收到该命令后,通过比较如果发现某个副本集成员汇报过来的时间戳信息比上次新,就会触发,唤醒等待 writeConcern 的用户线程的逻辑。
唤醒逻辑会去比较用户线程等待的 lastOptime 是否小于等于 Secondary 汇报过来的时间戳 TS,如果是,表示有一个 Secondary 节点满足了本次 writeConcern 的要求。那么,TS 要使用 Secondary 汇报过来的那个时间戳呢?如果 writeConcern 中 j 参数指定的是 false,意味着本次写操作并不关注是否在 Disk 上持久化,那么 TS 使用 appliedOpTime, 否则使用 durableOpTime 。当有指定的 w 个节点(含 Primary 自身)汇报的 TS 大于等于 lastOptime,用户线程即可被唤醒,向客户端返回成功。
// TopologyCoordinator::haveNumNodesReachedOpTime
for (auto&& memberData : _memberData) {
const OpTime& memberOpTime =
durablyWritten ? memberData.getLastDurableOpTime() : memberData.getLastAppliedOpTime();
if (memberOpTime >= targetOpTime) {
--numNodes;
}
if (numNodes <= 0) {
return true;
}
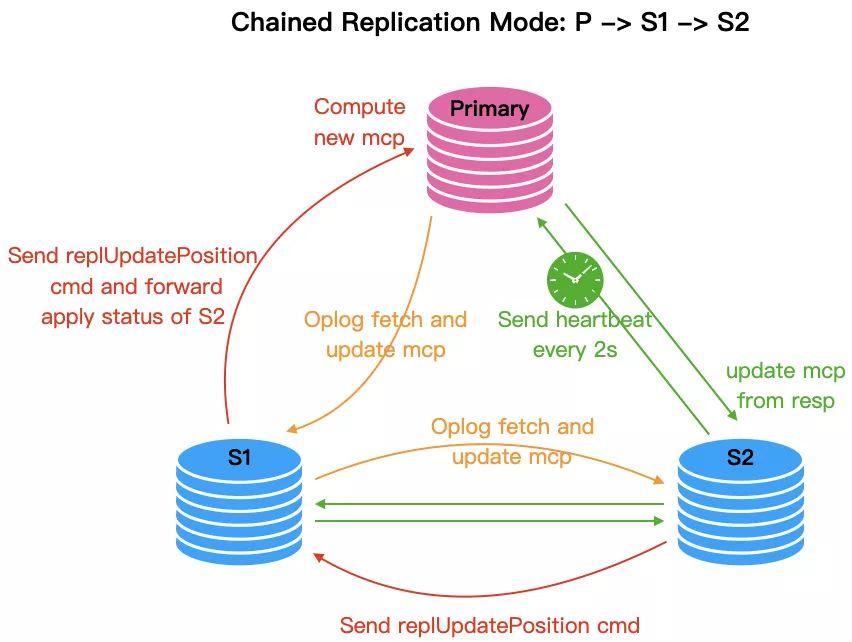
}到这里,用户线程因 writeConcern 被阻塞到唤醒的基本流程就完成了,但是我们还需要思考一个问题,MongoDB 是支持链式复制的,即,P->S1->S2 这种复制拓扑,如果在 P 上执行了写操作,且使用了 writeConcern w:3,即,要求得到三个节点的确认,而 S2 并不直接向 P 汇报自己的 Oplog Apply 信息,那这种场景下 writeConcern 要如何满足?
MongoDB 采用了信息转发的方式来解决这个问题,当 S1 收到 S2 汇报过来的 replSetUpdatePosition 命令,进行处理时(processReplSetUpdatePosition()),如果发现自己不是 Primary 角色,会立刻触发一个 forwardSlaveProgress 任务,即,把自己的 Oplog Apply 信息,连同自己的 Secondary 汇报过来的,构造一个 replSetUpdatePosition 命令,发往上游,从而保证,当任一个 Secondary 节点的 Oplog Apply 进度推进,Primary 都能够及时的收到消息,尽可能降低 w>1 时,因 writeConcern 而带来的写操作延迟。
readConcern
readConcern 的实现相比于 writeConcern,要复杂很多,因为它和存储引擎的关联要更为紧密,在某些情况下,还要依赖于 writeConcern 的实现,同时部分 readConcern level 的实现还要依赖 MongoDB 的复制机制和存储引擎共同提供支持。
另外,MongoDB 为了在满足指定 readConcern level 要求的前提下,尽量降低读操作的延迟和事务执行效率,也做了一些优化。下面我们就结合不同的 readConcern level 来分别描述它们的实现原理和优化手段。
“majority” readConcern
“majority” readConcern 的语义前面的章节已经介绍,这里不再赘述。为了保证客户端读到 majority committed 数据,根据存储引擎能力的不同,MongoDB 分别实现了两种机制用于提供该承诺。
依赖 WiredTiger 存储引擎快照的实现方式
WiredTiger 为了保证并发事务在执行时,不同事务的读写不会互相 block,提升事务执行性能,也采用了 MVCC 的并发控制策略,即不同的写事务在提交时,会生成多个版本的数据,每个版本的数据由一个时间戳(commit_ts)来标识。所谓的存储引擎快照(Snapshot),实际上就是在某个时间点看到的,由历史版本数据所组成的一致性数据视图。所以,在引擎内部,快照也是由一个时间戳来标识的。
前面我们已经提到,由于 MongoDB 采用异步复制的机制,不同节点的复制进度会有差异。如果我们在某个副本集节点直接读取最新的已提交数据,如果它还没有复制到大多数节点,显然就不满足 “majority” readConcern 语义。
这个时候可以采取一个办法,就是仍然读取最新的数据,但是在返回 Client 前等待其他节点确认本次读取的数据已经 apply 完成了,但是这样显然会大幅的增加读操作的延迟(虽然这种情况下,一致性体验反而更好了,因为能读到更新的数据,但是前面我们已经分析了,绝大部分用户在读取时,希望更快的返回的数据,而不是追求一致性)。
所以,MongoDB 采用的做法是在存储引擎层面维护一个 majority committed 数据视图(快照),这个快照对应的时间戳在 MongoDB 里面称之为 majority committed point(后面简称 mcp)。当 Client 指定 majority 读时,通过直接读取这个快照,来快速的返回数据,无需等待。需要注意的一点是,由于复制进度的差异,mcp 并不能反映当前最新的已提交数据,即,这个方法是通过牺牲 Recency 来换取更低的 Latency。
// 以 getMore 命令举例
void applyCursorReadConcern(OperationContext* opCtx, repl::ReadConcernArgs rcArgs) {
...
switch (rcArgs.getMajorityReadMechanism()) {
case repl::ReadConcernArgs::MajorityReadMechanism::kMajoritySnapshot: {
// Make sure we read from the majority snapshot.
opCtx->recoveryUnit()->setTimestampReadSource(
RecoveryUnit::ReadSource::kMajorityCommitted);
// 获取 majority committed snapshot
uassertStatusOK(opCtx->recoveryUnit()->obtainMajorityCommittedSnapshot());
break;
...
}但基于 mcp 快照的实现方式需要解决一个问题,即,如何保证这个快照的有效性? 进一步来说, 如何保证 mcp 视图所依赖的历史版本数据不会被 WiredTiger 引擎清理掉?
正常情况下,WiredTiger 会根据事务的提交情况自动的去清理多版本的数据,只要当前的活跃事务对某个历史版本的数据没有依赖,即可以从内存中的 MVCC List 里面删掉(不考虑 LAS 机制,WT 的多版本数据设计上只存放在内存中)。但是,所谓的 majority committed point,实际上是 Server 层的概念,引擎层并不感知,如果只根据事务的依赖来清理历史版本数据,mcp 依赖的历史版本版本数据可能就会被提前清理掉。
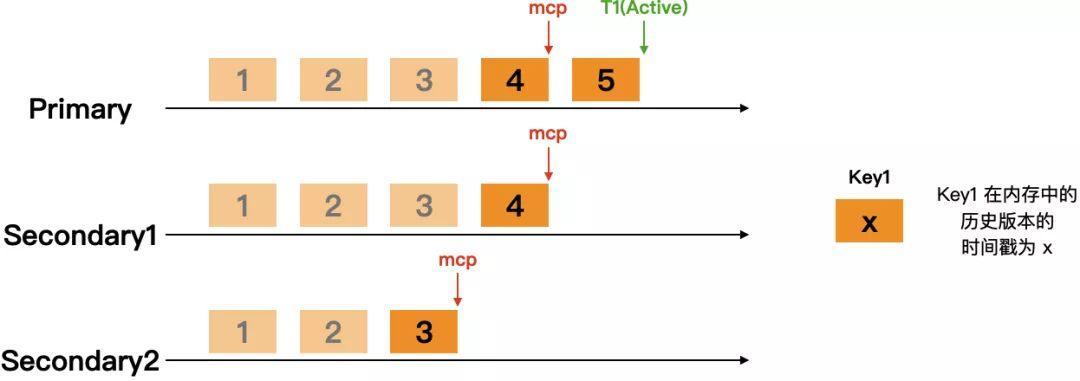
举个例子,在下图的三节点副本集中,如果 Client 从 Primary 节点读取并且指定了 majority readConcern,由于 mcp = 4,那么 MongoDB 只能向 Client 返回 commit_ts = 4 的历史值。但是,对于 WiredTiger 引擎来说,当前活跃的事务列表中只有 T1,commit_ts = 4 的历史版本是可以被清理的,但清理掉该版本,mcp 所依赖的 snapshot 显然就无法保证。所以,需要 WiredTiger 引擎层提供一个新机制,根据 Server 层告知的复制进度,即, mcp 位点,来清理历史版本数据。
在 WiredTiger 3.0 版本中,开始提供「Application-specified Transaction Timestamps」功能,来解决 Server 层对事务提交顺序(基于 Application Timestamp)的需求和 WiredTiger 引擎层内部的事务提交顺序(基于 Internal Transaction ID)不一致的问题(根源来自于基于 Oplog 的复制机制,这里不作展开)。进一步,在这个功能的基础上,WT 也提供了所谓的「read "as of" a timestamp」功能(也有文章称之为 「Time Travel Query」),即支持从某个指定的 Timestamp 进行快照读,而这个特性正是前面提到的基于 mcp 位点实现 "majority" readConcern 的功能基础。
WiredTiger 对外提供了 set_timestamp() 的 API,用于 Server 层来更新相关的 Application Timestamp。WT 目前包含如下语义的 Application Timestamp,

要回答前面提到的关于 mcp snapshot 有效性保证的问题,我们需要重点关注红框中的几个 Timestamp。
首先,stable timestamp 在 MongoDB 中含义是,在这个时间戳之前提交的写,不会被回滚,所以它和 majority commit point(mcp) 的语义是一致的。stable timestamp 对应的快照被存储引擎持久化后,称之为「stable checkpoint」,这个 checkpoint 在 MongoDB 中也有重要的意义,在后面的「"local" readConcern」章节我们再详述。
MongoDB 在 Crash Recovery 时,总是从 stable checkpoint 初始化,然后重新应用增量的 Oplog 来完成一次恢复。所以为了提升 Crash Recovery 效率及回收日志空间,引擎层需要定期的产生新的 stable checkpoint,也就意味着stable timestamp 也需要不断的被 Server 层推进(更新)。而 MongoDB 在更新 stable timestamp 的同时,也会顺便去基于该时间戳去更新 oldest timestamp,所以,在基于快照的实现机制下,oldest timestamp 和 stable timestamp 的语义也是一致的。
...
->ReplicationCoordinatorImpl::_updateLastCommittedOpTimeAndWallTime()
->ReplicationCoordinatorImpl::_setStableTimestampForStorage()
->WiredTigerKVEngine::setStableTimestamp()
->WiredTigerKVEngine::setOldestTimestampFromStable()
->WiredTigerKVEngine::setOldestTimestamp()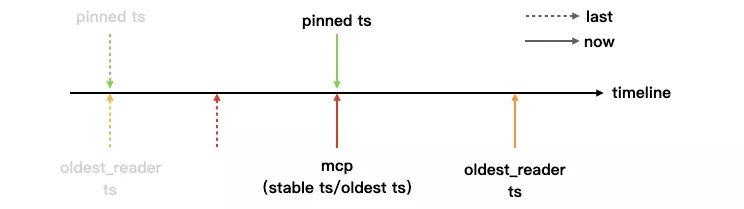
当前 WiredTiger 收到新的 oldest timestamp 时,会结合当前的活跃事务(oldest_reader)和 oldest timestamp 来计算新的全局 pinned timestamp,当进行历史版本数据的清理时,pinned timestamp 之后的版本不会被清理,从而保证了 mcp snapshot 的有效性。
// 计算新的全局 pinned timestamp
__conn_set_timestamp->__wt_txn_global_set_timestamp->__wt_txn_update_pinned_timestamp->
__wt_txn_get_pinned_timestamp {
...
tmp_ts = include_oldest ? txn_global->oldest_timestamp : 0;
...
if (!include_oldest && tmp_ts == 0)
return (WT_NOTFOUND);
*tsp = tmp_ts;
...
}
// 判断历史版本是否可清理
static inline bool
__wt_txn_visible_all(WT_SESSION_IMPL *session, uint64_t id, wt_timestamp_t timestamp)
{
...
__wt_txn_pinned_timestamp(session, &pinned_ts);
return (timestamp <= pinned_ts);
}在分析了 mcp snapshot 有效性保证的机制之后,我们还需要回答下面两个关键问题,整个细节才算完整。
- Secondary 的复制进度,以及进一步由复制进度计算出的 mcp 是由 oplog 中的 ts 字段来标识的,而数据的版本号是由 commit_ts 来标识的,他们之间有什么关系,为什么是可比的?
- 前面提到了引擎的 Crash Recovery 需要 stable timestamp(mcp)不断的推进来产生新的 stable checkpoint,那 mcp 具体是如何推进的?
要回答第一个问题,我们需要先看下,对于一条 insert 操作,它所对应的 oplog entry 的 ts 字段值是怎么来的,以及这条 oplog 和 insert 操作的关系。
首先,当 Server 层收到一条 insert 操作后,会提前调用 LocalOplogInfo::getNextOpTimes() 来给其即将要写的 oplog entry 生成 ts 值,获取这个 ts 是需要加锁的,避免并发的写操作产生同样的 ts。然后, Server 层会调用 WiredTigerRecoveryUnit::setTimestamp 开启 WiredTiger 引擎层的事务,并且把这个事务中后续写操作的 commit_ts 都设置为 oplog entry 的 ts,insert 操作在引擎层执行完成后,会把其对应的 oplog entry 也通过同一事务写到 WiredTiger Table 中,之后事务才提交。

也就是说 MongoDB 是通过把写 oplog 和写操作放到同一个事务中,来保证复制日志和实际数据之间的一致性,同时也确保了,oplog entry ts 和写操作本身所产生修改的版本号是一致的。
对于第二个问题,mcp 如何推进,在前面的 writeConcern 实现章节我们提到了,downstream 在 apply 完一批 oplog 之后会向 upstream 汇报自己的 apply 进度信息,upstream 同时也会向自己的 upstream 转发这个信息,基于这个机制,对 Primary 来说,显然最终它能不断的获取到整个副本集所有成员的 oplog apply 进度信息,进而推进自己的 majority commit point(计算的方式比较简单,具体见TopologyCoordinator::updateLastCommittedOpTimeAndWallTime)。
但是,上述是一个单向传播的机制,而副本集的 Secondary 节点也是能够提供读的,同样需要获取其他节点的 oplog apply 信息来更新 mcp 视图,所以 MongoDB 也提供了如下两种机制来保证 Secondary 节点的 mcp 是可以不断推进的:
1. 基于副本集高可用的心跳机制:
i. 默认情况下,每个副本集节点都会每 2 秒向其他成员发送心跳(replSetHeartBeat 命令)
ii. 其他成员返回的信息中会包含 $replData 元信息,Secondary 节点会根据其中的 lastOpCommitted 直接推进自己的 mcp
$replData: { term: 147, lastOpCommitted: { ts: Timestamp(1598455722, 1), t: 147 } ...2. 基于副本集的增量同步机制:
i. 基于心跳机制的 mcp 推进方式,显然实时性是不够的,Primary 计算出新的 mcp 后,最多要等 2 秒,下游才能更新自己的 mcp
ii. 所以,MongoDB 在 oplog 增量同步的过程中,upstream 同样会在向 downstream 返回的 oplog batch 中夹带 $replData 元信息,下游节点收到这个信息后同样会根据其中的 lastOpCommitted 直接推进自己的 mcp
iii. 由于 Secondary 节点的 oplog fetcher 线程是持续不断的从上游拉取 oplog,只要有新的写入,导致 Primary mcp 推进,那么下游就会立刻拉取新的 oplog,可以保证在 ms 级别同步推进自己的 mcp
另外一点需要说明的是,心跳回复中实际上也包含了目标节点的 lastAppliedOpTime 和 lastDurableOpTime 信息,但是 Secondary 节点并不会根据这些信息自行计算新的 mcp,而是总是等待 Primary 把 lastOpCommittedOpTime 传播过来,直接 set 自己的 mcp。
Speculative Read —— 不依赖快照的实现方式

类似于 MySQL,MongoDB 也是支持插件式的存储引擎体系的,但是并非每个支持的存储引擎都实现了 MVCC,即具备快照能力,比如在 MongoDb 3.2 之前默认的 MMAPv1 引擎就不具备。
此外,即使对于具备 MVCC 的 WiredTiger 引擎,维护 majority commit point 对应的 snapshot 是会带来存储引擎 cache 压力上涨的,所以 MongoDB 提供了 replication.enableMajorityReadConcern 参数用于关闭这个机制。
所以,结合以上两方面的原因,MongoDB 需要提供一种不依赖快照的机制来实现 majority readConcern,MongoDB 把这个机制称之为 Speculative Read ,中文上我觉得可以称为“未决读”。
Speculative Read 的实现方式非常简单,上一小节实际上也基本描述了,就是直接读当前最新的数据,但是在实际返回 Client 前,会等待读到的数据在多数节点 apply 完成,故可以满足 majority readConcern 语义。本质上,这是一种后验的机制,在其他的数据库系统中,比如 Hekaton,VoltDB ,事务的并发控制中也有类似的做法。
在具体的实现上,首先在命令实际执行前会通过 WiredTigerRecoveryUnit::setTimestampReadSource() 设置自己的读时间戳,即 readTs,读事务在执行的过程中只会读到 readTs 或之前的版本。
在命令执行完成后,会调用 waitForSpeculativeMajorityReadConcern() 确保 readTs 对应的时间点及之前的 oplog 在 majority 节点应用完成。这里实际上最终也是通过调用 ReplicationCoordinatorImpl::_awaitReplication_inlock 阻塞在一个条件变量上,等待足够多的 Secondary 节点汇报自己的复制进度信息后才被唤醒,完全复用了 majority writeConcern 的实现。所以,writeConcern,readConcern 除了在功能设计上有强关联,在内部实现上也有互相依赖。
需要注意的是,Speculative Read 机制 MongoDB 并不打算提供给普通用户使用,如果把 replication.enableMajorityReadConcern 设置为 false 之后,继续使用 majority readConcern,MongoDB 会返回 ReadConcernMajorityNotEnabled 错误。目前在一些内部命令的场景下才会使用该机制,测试目的的话,可以在 find 命令中加一个特殊参数: allowSpeculativeMajorityRead: true,强制开启 Speculative Read 的支持。
针对 readConcern 的优化 —— Query Yielding
考虑到后文逻辑上的依赖,在分析其他 readConcern level 之前,需要先看一个 MongoDB 针对 readConcern 的优化措施。
默认情况下,MongoDB Server 层面所有的读操作在 WiredTiger 上都会开启一个事务,并且采用 snapshot 隔离级别。在 snapshot isolation 下,事务需要读到一个一致性的快照,且读取的数据是事务开始时最新提交的数据。而 WiredTiger 目前的多版本数据只能存放在内存中,所以在这个规则下,执行时间太久的事务会导致 WiredTiger 的内存压力升高,进一步会影响事务的执行性能。
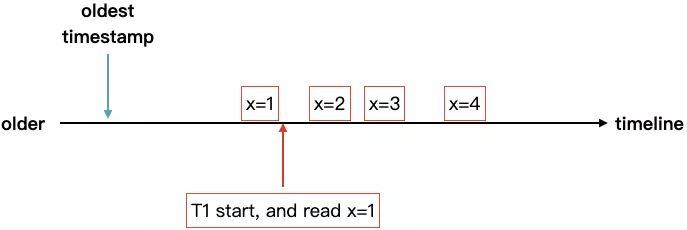
比如,在上图中,事务 T1 开始后,根据 majority commit point 读取自己可见的版本,x=1,其他的事务继续对 x 产生修改并且提交,会产生的新的版本 x=2,x=3……,T1 只要不提交,那么 x=2 及之后的版本都不能从内存中清理,否则就会违反 snapshot isolation 的语义。
面对上述情况,MongoDB 采用了一种称之为「Query Yielding」的手段来“优化” 这个问题。

「Query Yielding」的思路其实非常简单,就是在事务执行的过程中,定期的进行 yield,即释放锁,abort 当前的 WiredTiger 事务,释放 hold 的 snapshot,然后重新打开事务,获取新的 snapshot。显然,通过这种方式,对于一个执行时间很长的 MongoDB 读操作,它在引擎层事务的 read_ts 是不断推进的,进而保证 read_ts 之后的版本能够被及时从内存中清理。
之所以在优化前面加一个引号的原因是,这种方式虽然解决了长事务场景下,WT 内存压力上涨的问题,但是是以牺牲快照隔离级别的语义为代价的(降级为 read committed 隔离级别),又是一个典型的牺牲一致性来换取更好的访问性能的应用案例。
"local" 和 "majority" readConcern 都应用了「Query Yielding」机制,他们的主要区别是,"majority" readConcern 在 reopen 事务时采用新推进的 mcp 对应的 snapshot,而 "local" readConcern 采用最新的时间点对应的 snapshot。
Server 层在一个 Query 正常执行的过程中(getNext()),会不断的调用 _yieldPolicy->shouldYieldOrInterrupt() 来判定是否需要 yield,目前主要由如下两个因素共同决定是否 yield:
internalQueryExecYieldIterations:shouldYieldOrInterrupt()调用累积次数超过该配置值会主动 yield,默认为 128,本质上反映的是从索引或者表上获取了多少条数据后主动 yield。yield 之后该累积次数清零。internalQueryExecYieldPeriodMS:从上次 yield 到现在的时间间隔超过该配置值,主动 yield,默认为 10ms,本质上反映的是当前线程获取数据的行为持续了多久需要 yield。
最后,除了根据上述配置主动的 yield 行为,存储引擎层面也会因为一些原因,比如需要从 disk load page,事务冲突等,告知计划执行器(PlanExecutor)需要 yield。MongoDB 的慢查询日志中会输出一些有关执行计划的信息,其中一项就是 Query 执行期间 yield 的次数,如果数据集不变的情况下,执行时长差别比较大,那么就可能和要访问的 page 在 WiredTiger Cache 中的命中率相关,可以通过 yield 次数来进行一定的判断。
“snapshot” readConcern
前面我们已经提到了 "snapshot" readConcern 是专门用于 MongoDB 的多文档事务的,MongoDB 多文档事务提供类似于传统关系型数据库的事务模型(Conversational Transaction),即通过 begin transaction 语句显示开启事务, 根据业务逻辑执行不同的操作序列,然后通过 commit transaction 语句提交事务。"snapshot" readConcern 除了包含 "majority" readConcern 提供的语义,同时它还提供真正的一致性快照语义,因为多文档事务中的多个操作只会对应到一个 WiredTiger 引擎事务,并不会应用「Query Yielding」。
这里这么设计的主要考虑是,和默认情况下为了保证性能而采用单文档事务不同,当应用显示启用多文档事务时,往往意味着它希望 MongoDB 提供类似关系型数据库的,更强的一致性保证,「Query Yielding」导致的 snapshot “漂移”显然是无法接受的。而且在目前的实现中,如果应用使用了多文档事务,即使指定 "majority" 或 "local" readConcern,也会被强制提升为 "snapshot" readConcern。
// If "startTransaction" is present, it must be true due to the parsing above.
const bool upconvertToSnapshot(sessionOptions.getStartTransaction());
auto newReadConcernArgs = uassertStatusOK(
_extractReadConcern(invocation.get(), request.body, upconvertToSnapshot)); // 这里强制提升为 "snapshot" readConcern不采用 「Query Yielding」也就意味着存在上节所说的“WiredTiger Cache 压力过大”的问题,在 “snapshot” readConcern 下,当前版本没有太好的解法(在 4.4 中会通过 durable history,即支持把多版本数据写到磁盘,而不是只保存在内存中来解决这个问题)。MongoDB 目前采用了另外一个比较简单粗暴的方式来缓解这个问题,即限制事务执行的时长,transactionLifetimeLimitSeconds 配置的值决定了多文档事务的最大执行时长,默认为 60 秒。
超出最大执行时长的事务由后台线程负责清理,默认每 30 秒进行一次清理动作。每个多文档事务都会和一个 Logical Session 关联,清理线程会遍历内存中的 SessionCatalog 缓存找到所有过期事务,清理和事务关联的 Session,然后 abortTransaction(具体可参考killAllExpiredTransactions())。
"snapshot" readConcern 为了同时维持分布式环境下的 "majority" read 语义和事务本地执行的一致性快照语义,还会带来另外一个问题:事务因为写冲突而 abort 的概率提升。
在单机环境下,事务的写冲突往往是因为并发事务的执行修改了同一份数据,进而导致后提交的事务需要 abort(first-writer-win)。但是通过后面的解释我们会看到,"snapshot" readConcern 为了同时维持两种语义,即使在单机环境下看起来是非并发的事务,也会因为写冲突而 abort。
要说明这个问题,先来简单看下事务在 snapshot isolation 下的读写规则。

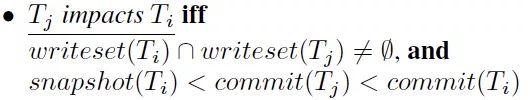
- 对于读:
- 对任意事务 $T_i$ ,如果它读到了数据 $X$ 的版本 $X_j$,而 $X_j$ 是由事务 $T_j$ 修改产生,则 $T_j$ 一定已经提交,且 $T_j$ 的提交时间戳一定小于事务 $T_i$ 的快照读时间戳,即只有这样, $T_j$ 的修改对 $T_i$ 才是可见的。这个规则保证了事务只能读取到自己可见范围内的数据。
- 另外,对任意事务 $T_k$,如果它修改了 $X$ 并且产生了新的版本 $X_k$,且 $T_k$ 已提交,那么 $T_k$ 要么在事务 $T_j$ 之前提交($commit(T_k) < commit(T_j)$),要么在事务 $T_i$ 的快照读时间戳之后提交。这个规则保证了事务在可见范围内读取最新的数据。
- 对于写:
- 对于任意事务 $T_i$ 和 $T_j$,他们都成功提交的前提是没有产生冲突。
- 冲突的定义:如果 $T_j$ 的提交时间戳在事务 $T_i$ 的观测时间段([$snapshot(T_i)$, $commit(T_i)$])内,且二者的修改数据集存在交集,则二者存在冲突。这种情况下 $T_i$ 需要 abort。
- 对这个规则可以有一个通俗的理解,即事务的并发控制存在一个基本原则:「过去不能修改将来」,$snapshot(T_i) < commit(T_j)$ 表明 $T_i$ 相对于 $T_j$ 发生在过去(此时 $T_i$ 看不到 $T_j$ 产生的修改), $T_i$ 如果正常提交,因为 $commit(T_i) > commit(T_j)$,也就意味着发生在过去的 $T_i$ 的写会覆盖将来的 $T_j$。
然后再回到前面的问题:为什么在 "snapshot" readConcern 下事务冲突 abort 的概率会提升?这里我们结合一个例子来进行说明,

上图中,C1 发起的事务 T1 在主节点(P)上提交后,需要复制到一个从节点(S) 并且 apply 完成才算是 majority committed。在事务从 local committed 变为 majority committed 这个延迟内(上图中的红圈),如果 C2 也发起了一个事务 T2,虽然 T2 是在 T1 提交之后才开始的,但根据 "majority" read 语义的要求,T2 不能够读取 T1 刚提交的修改,而是基于 mcp 读取 T1 修改前的版本,这个是符合前面的 snapshot read rule 的( D1 规则)。
但是,如果 T2 读取了这个更早的版本并且做了修改,因为 T2 的 commit_ts(有递增要求) 大于 T1 的,根据前面的 snapshot commit rule(D2 规则),T2 需要 abort。
需要说明的是,应用对数据的访问在时间和空间上往往呈现一定的局部性,所以上述这种 back-to-back transaction workload(T1 本地修改完成后,T2 接着修改同一份数据)在实际场景中是比较常见的,所以很有必要对这个问题作出优化。
MongoDB 对这个问题的优化也比较简单,采用了和 "majority" readConcern 一样的实现思路,即「speculative read」。MongoDB 把这种基于「speculative read」机制实现的 snapshot isolation 称之为「speculative snapshot isolation」。
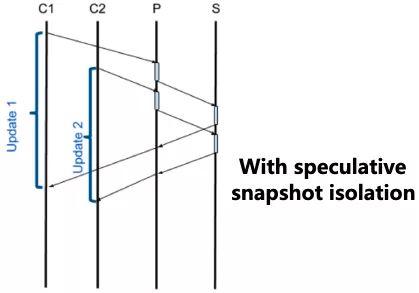
仍然使用上面的例子,在「speculative snapshot isolation」机制下,事务 T2 在开始时不再基于 mcp 读取 T1 提交前的版本,而是直接读取最新的已提交值(T1 提交),这样 $snapshot(T_2) >= commit(T_1)$ ,即使 T2 修改了同一条数据,也不会违反 D2 规则。
但是此时 T1 还没有被复制到 majority 节点,T2 如果直接返回客户端成功,显然违反了 "majority" read 的语义。MongoDB 的做法是,在事务 T2 提交时,如果要维持 "majority" read 的语义,其必须也以 "majority" writeConcern 提交。这样,如果 T2 产生了修改,在其等待自身的修改成为 majority committed 时,发生它之前的事务 T1 的修改显然也已经是 majority committed(这个是由 MongoDB 复制协议的顺序性和 batch 并发 apply 的原子性保证的),所以自然可保证 T2 读取到的最新值满足 "majority" 语义。
这个方式本质上是一种牺牲 Latency 换取 Consistency 的做法,和基于 snapshot 的 "majority" readConcern 做法正好相反。这里这么设计的原因,并不是有目的的去提供更好的一致性,主要还是为了降低事务冲突 abort 的概率,这个对 MongoDB 自身性能和业务的影响非常大,在这个基础上,也可以说,保证业务读取到最新的数据总是更有用的。
关于牺牲 Latency,实际上上述实现机制,对于写事务来说并没有导致额外的延迟,因为事务自身以 "majority" writeConcern 提交进行等待以满足自身写的 majority committed 要求时,也顺便满足了 「speculative read」对等待的需求,缺点就是事务的提交必须要和 "majority" readConcern 强绑定,但是从多文档事务隐含了对一致性有更高的要求来看,这种绑定也是合理的,避免了已提交事务的修改在重新选主后被回滚。
真正产生额外延迟的是只读事务,因为事务本身没有做任何修改,仍然需要等待。实际上这个延迟也可以被优化掉,因为事务如果只是只读,不管读取了哪个时间点的快照,都不会和其他写事务形成冲突,但是 MongoDB 目前并没有提供标记多文档事务为只读事务的接口,期待后续的优化。
“local” readConcern
"local" readConcern 在 MongoDB 里面的语义最为简单,即直接读取本地最新的已提交数据,但是它在 MongoDB 里面的实现却相对复杂。
首先我们需要了解的是 MongoDB 的复制协议是一种类似于 Raft 的复制状态机(Replicated State Machine)协议,但它和 Raft 最大区别是,Raft 先把日志复制到多数派节点,然后再 Apply RSM,而 MongoDB 是先 Apply RSM,然后再异步的把日志复制到 Follower(Secondary) 去 Apply。
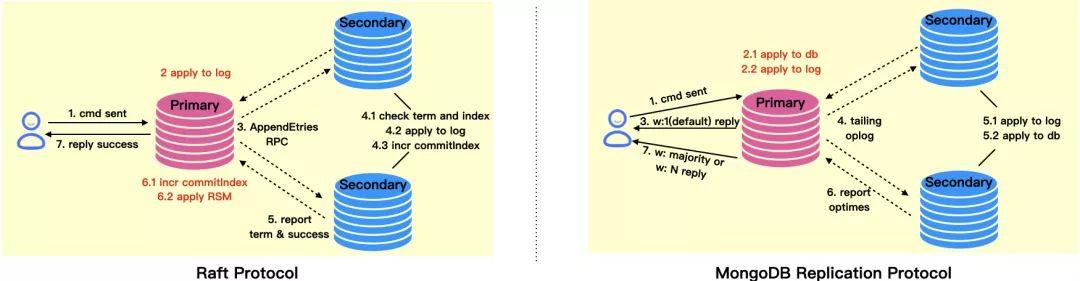
这种实现方式除了可以降低写操作(在 default writeConcern下)的延迟,也为实现 "local" readConcern 提供了机会,而 Recency,前面的统计数据已经分析了,正是大部分的业务所更加关注的。
MongoDB 的这种设计虽然更贴近于用户需求,但也为它的 RSM 协议引入了额外的复杂性,这点主要体现在重新选举时。
重新选主时可能会发生,已经在之前的 Primary 上追加的部分 log entry 没有来及复制到新的 Primary 节点,那么在前任 Primary重新加入集群时,需要把这部分多余的 log entry 回滚掉(注:这种情况,除了旧主可能发生,其他节点也可能发生)。对于 Raft 来说这个回滚动作特别简单,只需对 replicated log 执行 truncate,移除尾部多余的 log entry,然后重新从现任 Primary 追日志即可。
但是,对于 MongoDB 来说,由于在追加日志前就已经对状态机进行了 apply,所以除了 Log Truncation,还需要一个状态机回滚(Data Rollback)流程。Data Rollback 是一个代价比较大的过程,而 MongoDB 本身的日志复制是通常是很快的,真正在发生重新选举时,未及时同步到新主的 log entry 是比较少的,所以如果能够让新主在接受写操作之前,把旧主上“多余”的日志重新拉取过来并应用,显然可以避免旧主的 Data Rollback。
重选举时的 Catchup Phase
MongoDB 从 3.4 版本开始实现了上述机制(catchup phase),流程如下,
- 候选节点在成功收到多数派节点的投票后,会通过心跳(
replSetHeartBeat命令)向其他节点广播自己当选的消息; - 其他节点的的 heartbeat response 中会包含自己最新的 applied opTime,当选节点会把其中最大的 opTIme 作为自己 catchup 的
targetOpTime; - 从 applied opTime 最大的节点或其下游节点同步数据,这个过程和正常的基于 oplog 的增量复制没有太大区别;
- 如果在超时时间(由
settings.catchUpTimeoutMillis决定,3.4 默认 60 秒)内追上了targetOpTime,catchup 完成; - 如果超时,当选节点并不会 stepDown,而是继续作为新的 Primary 节点。
void ReplicationCoordinatorImpl::CatchupState::signalHeartbeatUpdate_inlock() {
auto targetOpTime = _repl->_topCoord->latestKnownOpTimeSinceHeartbeatRestart();
...
ReplicationMetrics::get(getGlobalServiceContext()).setTargetCatchupOpTime(targetOpTime.get());
log() << "Heartbeats updated catchup target optime to " << *targetOpTime;
...
}上述第 5 步意味着,catchup 过程中如果有超时发生,其他节点仍然需要回滚,所以在 3.6 版本中,MongoDB 对这个机制进行了强化。3.6 把 settings.catchUpTimeoutMillis 的默认值调整为 -1,即不超时。但为了避免 catchup phase 无限进行,影响可用性(集群不可写),增加了 catchup takeover 机制,即集群当前正在被当选节点作为同步源 catchup 的节点,在等待一定的时间后,会主动发起选举投票,来使“不合格”的当选节点下台,从而减少 Data Rollback 的几率和保证集群尽快可用。
这个等待时间由副本集的 settings.catchUpTakeoverDelayMillis 配置决定,默认为 30 秒。
stdx::unique_lock<stdx::mutex> ReplicationCoordinatorImpl::_handleHeartbeatResponseAction_inlock(
...
case HeartbeatResponseAction::CatchupTakeover: {
// Don't schedule a catchup takeover if any takeover is already scheduled.
if (!_catchupTakeoverCbh.isValid() && !_priorityTakeoverCbh.isValid()) {
Milliseconds catchupTakeoverDelay = _rsConfig.getCatchUpTakeoverDelay();
_catchupTakeoverWhen = _replExecutor->now() + catchupTakeoverDelay;
LOG_FOR_ELECTION(0) << "Scheduling catchup takeover at " << _catchupTakeoverWhen;
_catchupTakeoverCbh = _scheduleWorkAt(
_catchupTakeoverWhen, [=](const mongo::executor::TaskExecutor::CallbackArgs&) {
_startElectSelfIfEligibleV1(StartElectionReasonEnum::kCatchupTakeover); // 主动发起选举
});
}
...Data Rollback 是无法彻底避免的,因为 catchup phase 也只能发生在拥有最新 log entry 的节点在线的情况下,即能够向当选节点恢复心跳包,如果在选举完成后,节点才重新加入集群,仍然需要回滚。
MongoDB 目前存在两种 Data Rollback 机制:「Refeched Based Rollback」 和 「Recover To Timestamp Rollback」,其中后一种是在 4.0 及之后的版本,伴随着 WiredTiger 存储引擎能力的提升而演进出来的,下面就简要描述一下它们的实现方式及关联。
Refeched Based Rollback
「Refeched Based Rollback」 可以称之为逻辑回滚,下面这个图是逻辑回滚的流程图,
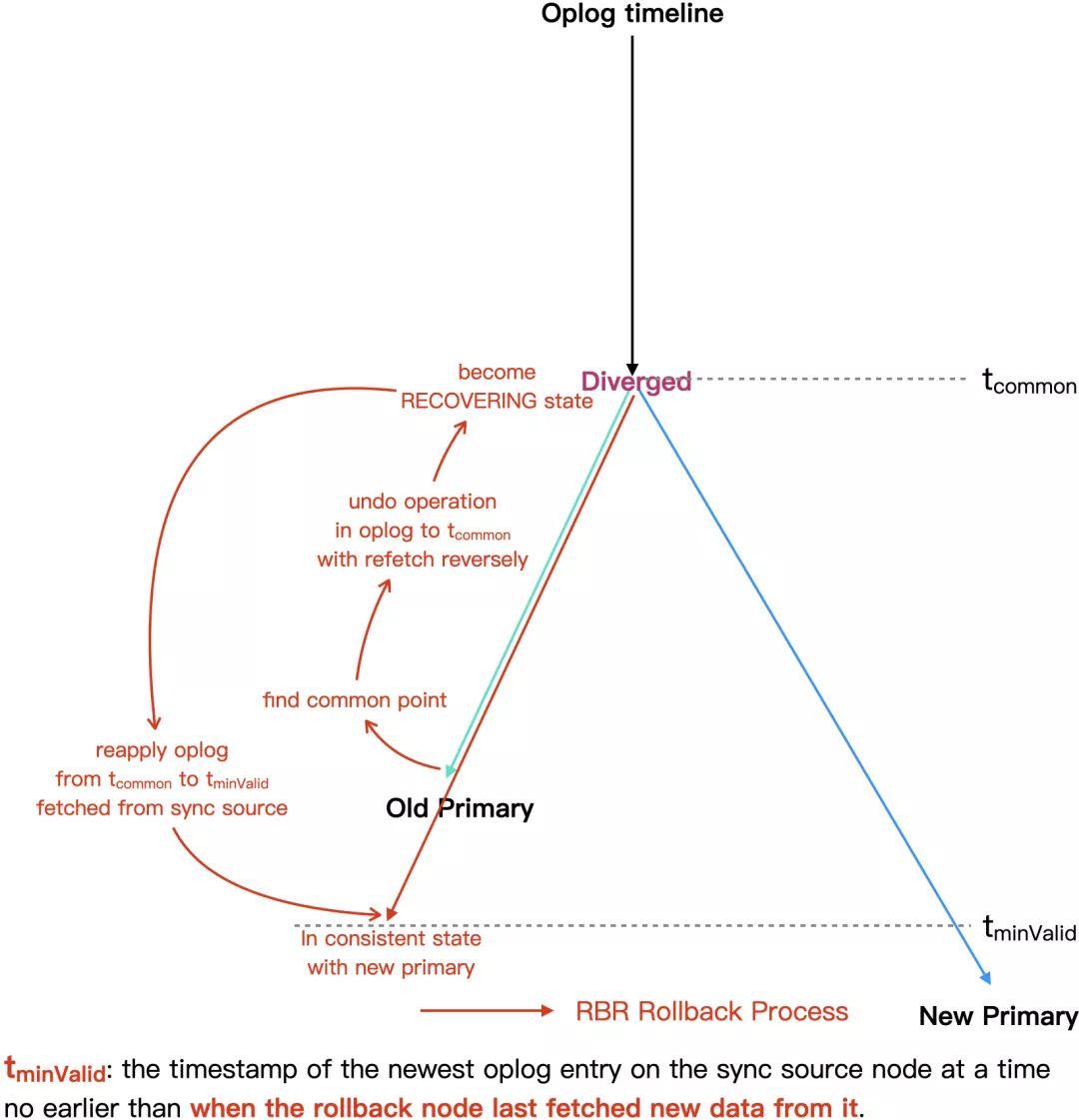
首先待回滚的旧主,需要确认重新选主后,自己的 oplog 历史和新主的 oplog 历史发生“分叉”的时间点,在这个时间点之前,新主和旧主的 oplog 是一致的,所以这个点也被称之为「common point」。旧主上从「common point」开始到自己最新的时间点之间的 oplog 就是未来及复制到新主的“多余”部分,需要回滚掉。
common point 的查找逻辑在 syncRollBackLocalOperations() 中实现,大致流程为,由新到老(反向)从同步源节点获取每条 oplog,然后和自己本地的 oplog 进行比对。本地 oplog 的扫描同样为反向,由于 oplog 的时间戳可以保证递增,扫描时可以通过保存中间位点的方式来减少重复扫描。如果最终在本地找到一条 oplog 的时间戳和 term 和同步源的完全一样,那么这条 oplog 即为 common point。由于在分布式环境下,不同节点的时钟不能做到完全实时同步,而 term 可以唯一标识一个主节点在任期间的修改(oplog)历史,所以需要把 oplog ts 和 term 结合起来进行 common point 的查找。
在找到 common point 之后,待回滚节点需要把当前最新的时间戳到 common point 之间的 oplog 都回滚掉,由于回滚采用逻辑的方式,整个流程还是比较复杂的。
首先,MongoDB 的 oplog 本质上是一种 redo log,可以通过重新 apply 来进行数据恢复,而且 oplog 记录时对部分操作进行了重写,比如 {$inc : {quantity : 1}} 重写为 {$set : {quantity : val}} 等,来保证 oplog 的幂等性,按序重复应用 oplog,并不会导致数据不一致。但是 oplog 并不包含 undo 信息,所以对于部分操作来说,无法实现基于本地信息直接回滚,比如对于 delete,dropCollection 等操作,删除掉的文档在 oplog 并无记录,显然无法直接回滚。
对于上述情况,MongoDB 采用了所谓「refetch」的方式进行回滚,即重新从同步源获取无法在本地直接回滚的文档,但是这个方式的问题在于 oplog 回滚到 tcommon 时,节点可能处于一个不一致的状态。举个例子,在 tcommon 时旧主上存在两条文档 {x : 10} 和 {y : 20},在重新选主之后,旧主上对 x 的 delete 操作并未同步到新主,在新主新的历史中,客户端先后对 x 和 y 做了更新:{$set : {y : 200}} ; {$set : {x : 100}}。在旧主通过「refetch」的方式完成回滚后,它在 tcommon 的状态为: {x : 100} 和 {y : 20},显然这个状态对于客户端来说是不一致的。
这个问题的根本原因在于,「refetch」时只能获取到被删除文档当前最新的状态,而不是被删除前的状态,这个方式破坏了在客户端看来可能存在因果关系的不同文档间的一致性状态。我们具体上面的例子来说,回滚节点在「refetch」时相当于直接获取了 {$set : {x : 100}} 的状态变更操作,而跳过了 {$set : {y : 200}},如果要达到一致性状态,看起来只要重新应用 {$set : {y : 200}} 即可。但是回滚节点基于现有信息是无法分析出来跳过了哪些状态的,对于这个问题,直接但是有效的做法是,把同步源从 tcommon 之后的 oplog 都重新拉取并「reapply」一遍,显然可以把跳过的状态补齐。而这中间也可能存在对部分状态变更操作的重复应用,比如 {$set : {x : 100}},这个时候 oplog 的幂等性就发挥作用了,可以保证数据在最终「reapply」完后的一致性不受影响。
剩下的问题就是,拉取到同步源 oplog 的什么位置为止?对于回滚节点来说,导致状态被跳过的原因是进行了「refetch」,所以只需要记录每次「refetch」时同步源最新的 oplog 时间戳,「reapply」时拉取到最后一次「refetch」对应的这个同步源时间戳就可以保证状态的正确补齐,MongoDB 在实现中把这个时间戳称之为 minValid。
MongoDB 在逻辑回滚的过程中也进行了一些优化,比如在「refetch」之前,会扫描一遍需要回滚的操作(这个不需要专门来做,在查找 common point 的过程即可实现),对于一些存在“互斥”关系的操作,比如 {insert : {_id:1} 和 {delete : {_id:1}},就没必要先 refetch 再 delete 了,直接忽略回滚处理即可。但是从上面整体流程看,「Refeched Based Rollback」仍然复杂且代价高:
- 「refetch」阶段需要和同步源通信,并进行数据拉取,如果回滚的是删表操作,代价很大
- 「reapply」阶段也需要和同步源通信,如果「refetch」阶段比较慢,需要拉取和重新应用的 oplog 也比较多
- 实现上复杂,每种可能出现在 oplog 中的操作都需要有对应的回滚逻辑,新增类型时同样需要考虑,代码维护代价高
所以在 4.0 版本中,随着 WiredTiger 引擎提供了回滚到指定的 Timestamp 的功能后,MongoDB 也用物理回滚的机制取代了上述逻辑回滚的机制,但在某些特殊情况下,逻辑回滚仍然有用武之地,下面就对这些做简要分析。
Recover To Timestamp Rollback
「Recover To Timestamp Rollback」是借助于存储引擎把物理数据直接回滚到某个指定的时间点,所以这里把它称之为物理回滚,下面是 MongoDB 物理回滚的一个简化的流程图,
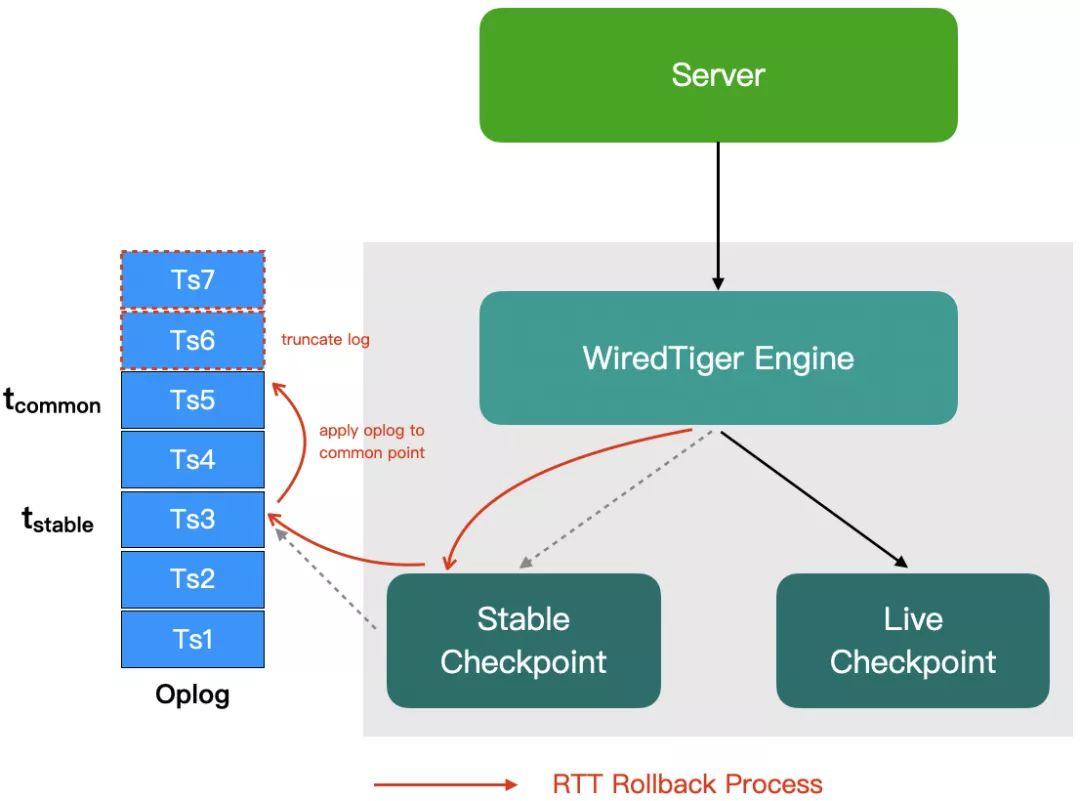
前面已经提到了 stable timestamp 的语义,这里不再赘述,MongoDB 有一个后台线程(WTCheckpointThread)会定期(默认情况下每 60 秒,由 storage.syncPeriodSecs 配置决定)根据 stable timestamp 触发新的 checkpoint 创建,这个 checkpoint 在实现中被称为 「stable checkpoint」。
class WiredTigerKVEngine::WiredTigerCheckpointThread : public BackgroundJob {
public:
...
virtual void run() {
...
{
stdx::unique_lock<stdx::mutex> lock(_mutex);
MONGO_IDLE_THREAD_BLOCK;
_condvar.wait_for(lock,
stdx::chrono::seconds(static_cast<std::int64_t>(
wiredTigerGlobalOptions.checkpointDelaySecs)));
}
...
UniqueWiredTigerSession session = _sessionCache->getSession();
WT_SESSION* s = session->getSession();
invariantWTOK(s->checkpoint(s, "use_timestamp=true"));
...
}
...
}stable checkpoint 本质上是一个持久化的历史快照,它所包含的数据修改已经复制到多数派节点,所以不会发生重新选主后修改被回滚。其实 WiredTiger 本身也可以配置根据生成的 WAL 大小或时间来自动触发创建新的 checkpoint,但是 Server 层并没有使用,原因就在于 MongoDB 需要保证在回滚到上一个 checkpoint 时,状态机肯定是 “stable” 的,不需要回滚。
WiredTiger 在创建 stable checkpoint 时也是开启一个带时间戳的事务来保证 checkpoint 的一致性,checkpoint 线程会把事务可见范围内的脏页刷盘,最后对应到磁盘上就是一个由多个变长数据块(WT 中称之为extent)构成的 BTree。
回滚时,同样要先确定 common point,这个流程和逻辑回滚没有区别,之后, Server 层会首先 abort 掉所有活跃事务,接着调用 WT 提供的 rollback_to_stable() 接口把数据库回滚到 stable checkpoint 对应的状态,这个动作主要是重新打开 checkpoint 对应的 BTree,并重新初始化 catalog 信息,rollback_to_stable() 执行完后会向 Server 层返回对应的 stable timestamp。
考虑到 stable checkpoint 触发的间隔较大,通常 common point 总是大于 stable checkpoint 对应的时间戳,所以 Server 层在拿到引擎返回的时间戳之后会还需要从其开始重新 apply 本地的 oplog 到 common point 为止,然后把 common point 之后的 oplog truncate 掉,从而达到和新的同步源一致的状态。这个流程主要在 RollbackImpl::_runRollbackCriticalSection() 中实现,
Status RollbackImpl::_runRollbackCriticalSection(
OperationContext* opCtx,
RollBackLocalOperations::RollbackCommonPoint commonPoint) noexcept try {
...
killSessionsAbortAllPreparedTransactions(opCtx); // abort 活跃事务
...
auto stableTimestampSW = _recoverToStableTimestamp(opCtx); // 引擎层回滚
...
Timestamp truncatePoint = _findTruncateTimestamp(opCtx, commonPoint); // 查找并设置 truncate 位点
_replicationProcess->getConsistencyMarkers()->setOplogTruncateAfterPoint(opCtx, truncatePoint);
...
// Run the recovery process. // 这里会进行 reapply oplog 和 truncate oplog
_replicationProcess->getReplicationRecovery()->recoverFromOplog(opCtx,
stableTimestampSW.getValue());
...
}此外,为了确保回滚可以正常进行,Server 层在 oplog 的自动回收时还需要考虑 stable checkpoint 对部分 oplog 的依赖。通常来说,stable timestamp 之前的 oplog 可以安全的回收,但是在 4.2 中 MongoDB 增加了对大事务(对应的 oplog 大小超过 16MB)和分布式事务的支持,在 stable timestamp 之前的 oplog 在回滚 reapply oplog 的过程中也可能是需要的,所以在 4.2 中 oplog 的回收需要综合考虑当前最老的活跃事务和 stable timestamp。
StatusWith<Timestamp> WiredTigerKVEngine::getOplogNeededForRollback() const {
...
if (oldestActiveTransactionTimestamp) {
return std::min(oldestActiveTransactionTimestamp.value(), Timestamp(stableTimestamp));
} else {
return Timestamp(stableTimestamp);
}
}整体上来说,基于引擎 stable checkpoint 的物理回滚方式在回滚效率和回滚逻辑复杂性上都要优于逻辑回滚。但是 stable checkpoint 的推进要依赖 Server 层 majority commit point 的推进,而 majority commit point 的推进受限于各个节点的复制进度,所以复制慢时可能会导致 Primary 节点 cache 压力过大,所以 MongoDB 提供了 replication.enableMajorityReadConcern 参数用于控制是否维护 mcp,关闭后存储引擎也不再维护 stable checkpoint,此时回滚就仍然需要进行逻辑回滚,这也是在 4.2 中仍然保留「Refeched Based Rollback」的原因。
“linearizable” readConcern
在一个分布式系统中,如果总是把可用性摆在第一位,那么因果一致性是其能够实现的最高一致性级别。前面我们也通过统计数据分析了在大部分情况下用户总是更关注延迟(可用性)而不是一致性,而 MongoDB 副本集,正是从用户需求角度出发,被设计成了一个在默认情况下总是优先保证可用性的分布式系统,下图是一个简单的例证。
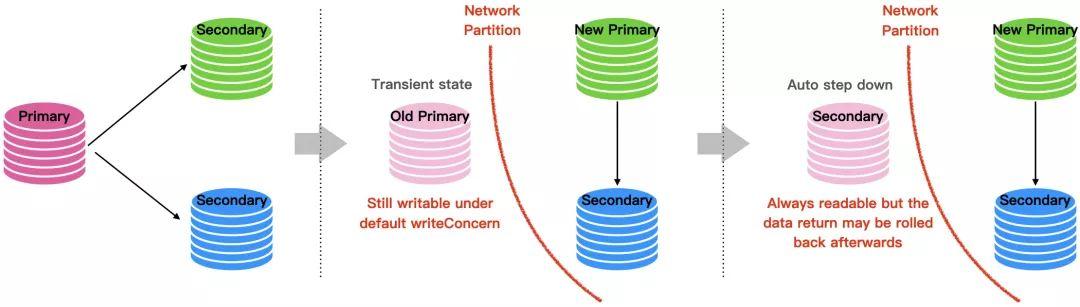
既然如此,那 MongoDB 是如何实现 “linearizable” readConcern,即更高级别的线性一致性呢?MongoDB 的策略很简单,就是把它退化到几乎是单机环境下的问题,即只允许客户端在 Primary 节点上进行 “linearizable” 读。说是“几乎”,因为这个策略仍然需要解决如下两个在副本集这个分布式环境下存在的问题,
- Primary 角色可能会发生变化,“linearizable” readConcern 需要保证每次读取总是能够从当前的 Primary 读取,而不是被取代的旧主。
- 需要保证读取到读操作开始前最新的写,而且读到的结果不会在重新选主后发生回滚。
MongoDB 采用同一个手段解决了上述两个问题,当客户端采用 “linearizable” readConcern 时,在读取完 Primary 上最新的数据后,在返回前会向 Oplog 中显示的写一条 noop 的操作,然后等待这条操作在多数派节点复制成功。显然,如果当前读取的节点并不是真正的主,那么这条 noop 操作就不可能在 majority 节点复制成功,同时,如果 noop 操作在 majority 节点复制成功,也就意味着之前读取的在 noop 之前写入的数据也已经复制到多数派节点,确保了读到的数据不会被回滚。
// src/mongo/db/read_concern_mongod.cpp:waitForLinearizableReadConcern()
...
writeConflictRetry(
opCtx,
"waitForLinearizableReadConcern",
NamespaceString::kRsOplogNamespace.ns(),
[&opCtx] {
WriteUnitOfWork uow(opCtx);
opCtx->getClient()->getServiceContext()->getOpObserver()->onOpMessage(
opCtx,
BSON("msg"
<< "linearizable read")); // 写 noop 操作
uow.commit();
});
...
auto awaitReplResult = replCoord->awaitReplication(opCtx, lastOpApplied, wc); // 等待 noop 操作 majority committed这个方案的缺点比较明显,单纯的读操作既产生了额外的写开销,也增加了延迟,但是这个是选择最高的一致性级别所需要付出的代价。
Causal Consistency
前面几个章节描述的由 writeConcern 和 readConcern 所构成的 MongoDB 可调一致性模型,仍然是属于最终一致性的范畴(特殊实现的 “linearizable” readConcern 除外)。虽然最终一致性对于大部分业务场景来说已经足够了,但是在某些情况下仍然需要更高的一致性级别,比如在下图这个经典的银行存款业务中,如果只有最终一致性,那么就可能导致客户看到的账户余额异常。

这个问题虽然可以在业务端通过记录一些额外的状态和重试来解决,但是显然会导致业务逻辑过于复杂,所以 MongoDB 实现了「Causal Consistency Session」功能来帮助降低业务复杂度。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java