
Flink+Hologres亿级用户实时UV精确去重最佳实践
对于实时计算场景,可以使用Flink+Hologres方式,并基于RoaringBitmap,实时对用户标签去重。这样的方式,可以较细粒度的实时得到用户UV、PV数据,同时便于根据需求调整最小统计窗口(如最近5分钟的UV),实现类似实时监控的效果,更好的在大屏等BI展示。相较于以天、周、月等为单位的去重,更适合在活动日期进行更细粒度的统计,并且通过简单的聚合,也可以得到较大时间单位的统计结果。
主体思想
- Flink将流式数据转化为表与维表进行JOIN操作,再转化为流式数据。此举可以利用Hologres维表的insertIfNotExists特性结合自增字段实现高效的uid映射。
- Flink把关联的结果数据按照时间窗口进行处理,根据查询维度使用RoaringBitmap进行聚合,并将查询维度以及聚合的uid存放在聚合结果表,其中聚合出的uid结果放入Hologres的RoaringBitmap类型的字段中。
- 查询时,与离线方式相似,直接按照查询条件查询聚合结果表,并对其中关键的RoaringBitmap字段做or运算后并统计基数,即可得出对应用户数。
- 处理流程如下图所示
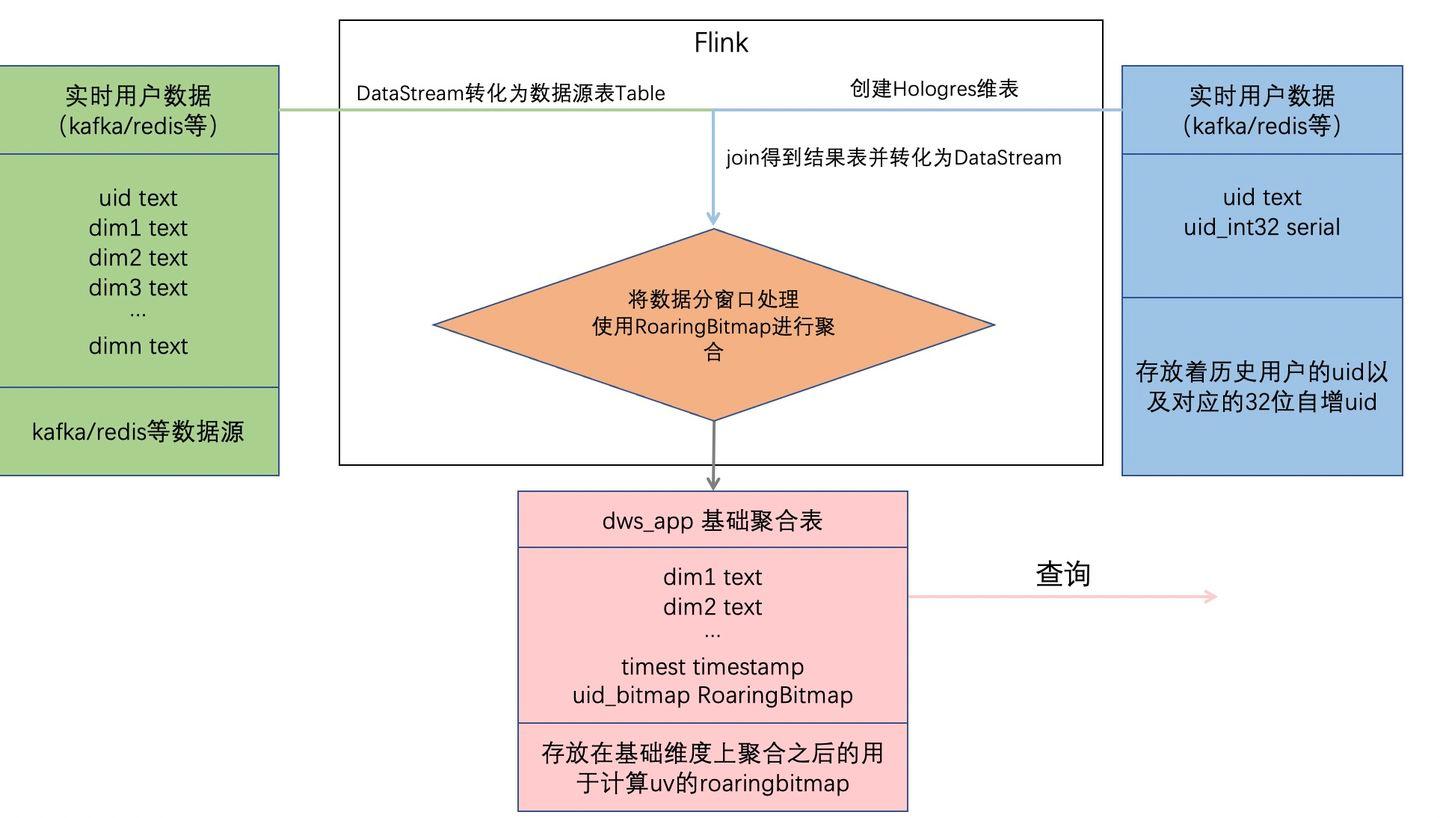
方案最佳实践
1.创建相关基础表
1)创建表uid_mapping为uid映射表,用于映射uid到32位int类型。
- RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(即用户ID最好连续)。常见的业务系统或者埋点中的用户ID很多是字符串类型或Long类型,因此需要使用uid_mapping类型构建一张映射表。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
- 由于是实时数据, 设置该表为行存表,以提高Flink维表实时JOIN的QPS。
BEGIN;
CREATE TABLE public.uid_mapping (
uid text NOT NULL,
uid_int32 serial,
PRIMARY KEY (uid)
);
--将uid设为clustering_key和distribution_key便于快速查找其对应的int32值
CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid');
CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid');
CALL set_table_property('public.uid_mapping', 'orientation', 'row');
COMMIT;2)创建表dws_app为基础聚合表,用于存放在基础维度上聚合后的结果。
- 使用RoaringBitmap前需要创建RoaringBitmap extention,同时也需要Hologres实例为0.10版本
CREATE EXTENSION IF NOT EXISTS roaringbitmap;- 为了更好性能,建议根据基础聚合表数据量合理的设置Shard数,但建议基础聚合表的Shard数设置不超过计算资源的Core数。推荐使用以下方式通过Table Group来设置Shard数
--新建shard数为16的Table Group,
--因为测试数据量百万级,其中后端计算资源为100core,设置shard数为16
BEGIN;
CREATE TABLE tg16 (a int); --Table Group哨兵表
call set_table_property('tg16', 'shard_count', '16');
COMMIT;- 相比离线结果表,此结果表增加了时间戳字段,用于实现以Flink窗口周期为单位的统计。结果表DDL如下:
BEGIN;
create table dws_app(
country text,
prov text,
city text,
ymd text NOT NULL, --日期字段
timetz TIMESTAMPTZ, --统计时间戳,可以实现以Flink窗口周期为单位的统计
uid32_bitmap roaringbitmap, -- 使用roaringbitmap记录uv
primary key(country, prov, city, ymd, timetz)--查询维度和时间作为主键,防止重复插入数据
);
CALL set_table_property('public.dws_app', 'orientation', 'column');
--日期字段设为clustering_key和event_time_column,便于过滤
CALL set_table_property('public.dws_app', 'clustering_key', 'ymd');
CALL set_table_property('public.dws_app', 'event_time_column', 'ymd');
--等价于将表放在shard数为16的table group
call set_table_property('public.dws_app', 'colocate_with', 'tg16');
--group by字段设为distribution_key
CALL set_table_property('public.dws_app', 'distribution_key', 'country,prov,city');
COMMIT;2.Flink实时读取数据并更新dws_app基础聚合表
完整示例源码请见alibabacloud-hologres-connectors examples
1)Flink 流式读取数据源(DataStream),并转化为源表(Table)
//此处使用csv文件作为数据源,也可以是kafka等
DataStreamSource odsStream = env.createInput(csvInput, typeInfo);
// 与维表join需要添加proctime字段,详见https://help.aliyun.com/document_detail/62506.html
Table odsTable =
tableEnv.fromDataStream(
odsStream,
$("uid"),
$("country"),
$("prov"),
$("city"),
$("ymd"),
$("proctime").proctime());
// 注册到catalog环境
tableEnv.createTemporaryView("odsTable", odsTable);2)将源表与Hologres维表(uid_mapping)进行关联
其中维表使用insertIfNotExists参数,即查询不到数据时自行插入,uid_int32字段便可以利用Hologres的serial类型自增创建。
// 创建Hologres维表,其中nsertIfNotExists表示查询不到则自行插入
String createUidMappingTable =
String.format(
"create table uid_mapping_dim("
+ " uid string,"
+ " uid_int32 INT"
+ ") with ("
+ " 'connector'='hologres',"
+ " 'dbname' = '%s'," //Hologres DB名
+ " 'tablename' = '%s',"//Hologres 表名
+ " 'username' = '%s'," //当前账号access id
+ " 'password' = '%s'," //当前账号access key
+ " 'endpoint' = '%s'," //Hologres endpoint
+ " 'insertifnotexists'='true'"
+ ")",
database, dimTableName, username, password, endpoint);
tableEnv.executeSql(createUidMappingTable);
// 源表与维表join
String odsJoinDim =
"SELECT ods.country, ods.prov, ods.city, ods.ymd, dim.uid_int32"
+ " FROM odsTable AS ods JOIN uid_mapping_dim FOR SYSTEM_TIME AS OF ods.proctime AS dim"
+ " ON ods.uid = dim.uid";
Table joinRes = tableEnv.sqlQuery(odsJoinDim);3)将关联结果转化为DataStream,通过Flink时间窗口处理,结合RoaringBitmap进行聚合
DataStream<Tuple6<String, String, String, String, Timestamp, byte[]>> processedSource =
source
// 筛选需要统计的维度(country, prov, city, ymd)
.keyBy(0, 1, 2, 3)
// 滚动时间窗口;此处由于使用读取csv模拟输入流,采用ProcessingTime,实际使用中可使用EventTime
.window(TumblingProcessingTimeWindows.of(Time.minutes(5)))
// 触发器,可以在窗口未结束时获取聚合结果
.trigger(ContinuousProcessingTimeTrigger.of(Time.minutes(1)))
.aggregate(
// 聚合函数,根据key By筛选的维度,进行聚合
new AggregateFunction<
Tuple5<String, String, String, String, Integer>,
RoaringBitmap,
RoaringBitmap>() {
@Override
public RoaringBitmap createAccumulator() {
return new RoaringBitmap();
}
@Override
public RoaringBitmap add(
Tuple5<String, String, String, String, Integer> in,
RoaringBitmap acc) {
// 将32位的uid添加到RoaringBitmap进行去重
acc.add(in.f4);
return acc;
}
@Override
public RoaringBitmap getResult(RoaringBitmap acc) {
return acc;
}
@Override
public RoaringBitmap merge(
RoaringBitmap acc1, RoaringBitmap acc2) {
return RoaringBitmap.or(acc1, acc2);
}
},
//窗口函数,输出聚合结果
new WindowFunction<
RoaringBitmap,
Tuple6<String, String, String, String, Timestamp, byte[]>,
Tuple,
TimeWindow>() {
@Override
public void apply(
Tuple keys,
TimeWindow timeWindow,
Iterable<RoaringBitmap> iterable,
Collector<
Tuple6<String, String, String, String, Timestamp, byte[]>> out)
throws Exception {
RoaringBitmap result = iterable.iterator().next();
// 优化RoaringBitmap
result.runOptimize();
// 将RoaringBitmap转化为字节数组以存入Holo中
byte[] byteArray = new byte[result.serializedSizeInBytes()];
result.serialize(ByteBuffer.wrap(byteArray));
// 其中 Tuple6.f4(Timestamp) 字段表示以窗口长度为周期进行统计,以秒为单位
out.collect(
new Tuple6<>(
keys.getField(0),
keys.getField(1),
keys.getField(2),
keys.getField(3),
new Timestamp(
timeWindow.getEnd() / 1000 * 1000),
byteArray));
}
});4)写入结果表
需要注意的是,Hologres中RoaringBitmap类型在Flink中对应Byte数组类型
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java