
自然语言理解
计算机语言多数是符合 BNF 的上下文无关语言,从表达能力上分为 DSL 和 GPL 两类;而人类语言属于上下文有关语言,其实正是由于这一点,才给在 NLP(自然语言理解)领域带来了不少困难。
好,知道了这些英文缩写,再去读那些专业文章会简单得多。
这些其实都是在 静态层面 上对语言的描述,为了实际执行这些语言,就需要对其进行解析,还原出语言本身所描述的信息结构。这件事,在计算机领域的课程叫《编译原理》,在智能科学与技术的课程叫《自然语言理解》。
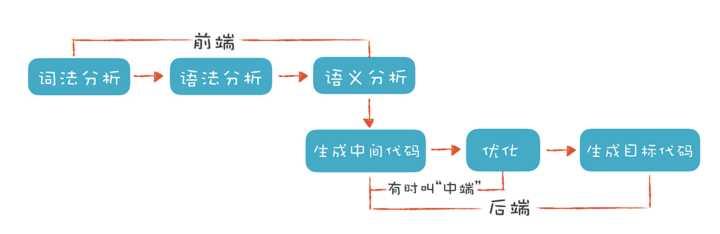
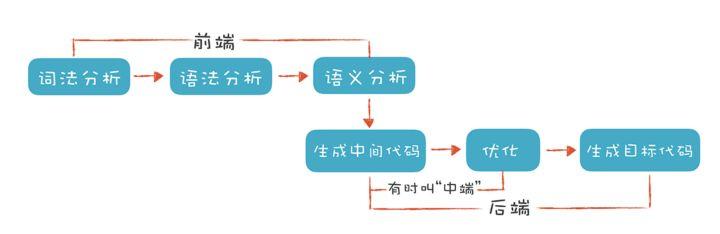
- 编译原理(一张图):
- 自然语言理解(两张图):
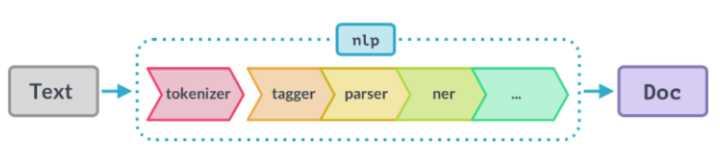
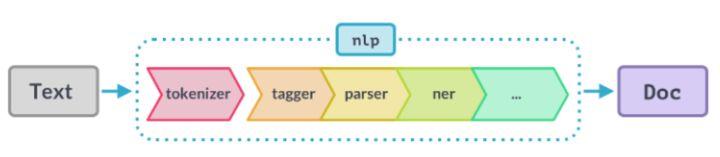
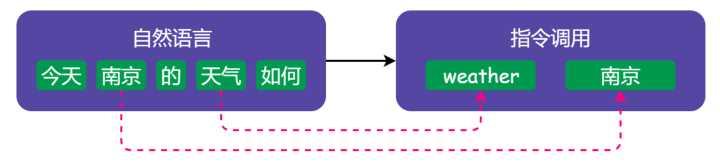
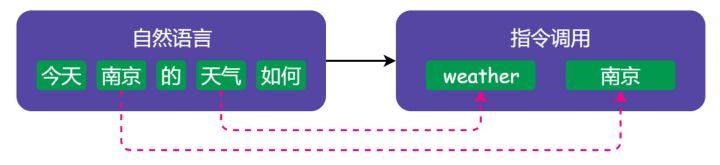
不难看出,两者的流程惊人的相似:
- 都需要先进行 tokenize 处理,编译器做的是词法分析(常用工具搜 lexer),NLP 做的是 分词(最常见的是 jieba 分词)
- 词法分析的产物是有含义的 token,下面都需要进行语法分析(即 parser),NLP 里通常会做 向量化(最常见的是 word2vec 方法)
- 这两步完成后,编译器前端得到的产物是 AST(Abstract Syntax Tree,抽象语法树),NLP 得到的产物是一段话的向量化表示
两者的共同点止步于此,鉴于 NLP 技术仍在高速发展(而编译原理早就是老生常谈了),向量化得到的产物难以处理同义词,所以后面的步骤也局限于分析一句话的意图、和提取有效信息(利用这些可以做一个简陋版的 Siri)。最新(其实是两年前了)的进展是 BERT 模型和衍生出来的许多研究上下文关系的方法,现在的 NLP 技术已经可以做阅读理解问题了。
此外,DSL 和 GPL 的共同点也止步于此。要记得,DSL 是面向特定用途的语言,以 JSON 为例,得到 AST 就已经有完整的信息结构了,在面向对象语言里无非再多一步:利用反射将其映射到一个 class 的所有字段里;以 HTML 为例,得到 AST 就已经有完整的 DOM 树了,浏览器已经具备渲染出整个网页所需的大部分信息。
最后,对 GPL 语言来说,编译型语言目的是生成机器可执行的代码,解释型语言的目的是生成虚拟机认识的中间代码。这部分职责由编译器后端承担,现代编译器领域的最佳拍档就是 Clang + LLVM。
2.3 别慌:英文缩写都是纸老虎
现在我们知道了事情的来龙去脉,也就明白了开头的需求属于哪种问题。对工程师来说,解决问题的第一步就是先知道你面对的是什么问题:使用编译原理的知识来解析开头的表达式,相当于定义一个简陋的 DSL 语言,并编写词法解析器和语法解析器(lexer & parser)来将其转换成 AST(抽象语法树),进而对其进行处理。
在进行工程实践之前,还有些术语不得不先行了解。
首先是前面提到的终结符和非终结符,重复一下上面解释 BNF 时举的抽象表达式:<符号> ::= <使用符号的表达式>。可以这样来理解:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java