
大数据计算引擎 Spark 工作原理及基础概念
一、Spark 介绍及生态
1. Spark相对于hadoop的优势
基于“血统”(Lineage)的数据恢复:spark引入了弹性分布式数据集RDD的抽象,它是分布在一组节点中的只读的数据的集合,这些集合是弹性的且是相互依赖的,如果数据集中的一部分的数据发生丢失可以根据“血统”关系进行重建。
CheckPoint容错:RDD计算时可以通过checkpoint进行容错,checkpoint有两种检测方式:通过冗余数据和日志记录更新操作。在RDD中的doCheckPoint方法相当于通过冗余数据来缓存数据,而“血统”是通过粗粒度的记录更新操作来实现容错的。CheckPoint容错是对血统检测进行的容错辅助,避免“血统”(Lineage)过长造成的容错成本过高。
spark相对于hadoop map reduce两种操作还提供了更为丰富的操作,分为action(collect,reduce,save…)和transformations(map,union,join,filter…),同时在各节点的通信模型中相对于hadoop的shuffle操作还有分区,控制中间结果存储,物化视图等。
2. spark 生态介绍

二、spark 原理及特点
1. spark core
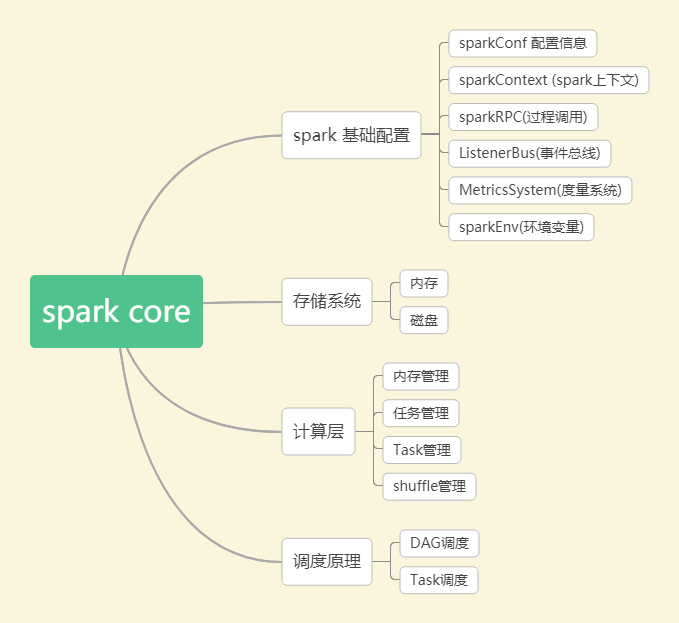
(3)spark 调度系统
具体调度算法有FIFO,FAIR:
FIFO调度:先进先出,这是Spark默认的调度模式。
FAIR调度:支持将作业分组到池中,并为每个池设置不同的调度权重,任务可以按照权重来决定执行顺序。
2. spark sql
3. spark streaming
4. spark特点

相较于以前离线任务采用mapreduce实现,实时任务采用storm实现,目前这些都可以通过spark来实现,降低来开发的成本。同时spark 通过spark SQL降低了用户的学习使用门槛,还提供了机器学习,图计算引擎等。
三、spark 运行模式及集群角色
1. spark运行模式
2. spark集群角色

worker节点通过注册机向cluster manager汇报自身的cpu,内存等信息。
worker 节点在spark master作用下创建并启用executor,executor是真正的计算单元。
spark master将任务Task分配给worker节点上的executor并执行运用。
worker节点同步资源信息和executor状态信息给cluster manager。

Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调Task的调度。
3. spark其它核心概念
Transformation(转换):是对已有的RDD进行换行生成新的RDD,对于转换过程采用惰性计算机制,不会立即计算出结果。常用的方法有map,filter,flatmap等。
Action(执行):对已有对RDD对数据执行计算产生结果,并将结果返回Driver或者写入到外部存储中。常用到方法有reduce,collect,saveAsTextFile等。



任务集的调度管理;
状态结果跟踪;
物理资源调度管理;
任务执行;
获取结果。

Task是spark中最独立的计算单元,由Driver Manager发送到executer执行,通常情况一个task处理spark RDD一个partition。Task分为ShuffleMapTask和ResultTask两种,位于最后一个Stage的Task为ResultTask,其他阶段的属于ShuffleMapTask。
四、spark作业运行流程
1. spark作业运行流程
sparkContext向cluster Manager申请CPU,内存等计算资源。
cluster Manager分配应用程序执行所需要的资源,在worker节点创建executor。
sparkContext将程序代码和task任务发送到executor上进行执行,代码可以是编译成的jar包或者python文件等。接着sparkContext会收集结果到Driver端。

sparkContext创建RDD对象,计算RDD间的依赖关系,并组成一个DAG有向无环图。
DAGScheduler将DAG划分为多个stage,并将stage对应的TaskSet提交到集群的管理中心,stage的划分依据是RDD中的宽窄依赖,spark遇见宽依赖就会划分为一个stage,每个stage中包含来一个或多个task任务,避免多个stage之间消息传递产生的系统开销。
taskScheduler 通过集群管理中心为每一个task申请资源并将task提交到worker的节点上进行执行。
worker上的executor执行具体的任务。

3. yarn资源管理器介绍
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java