
聊聊自然语言处理与学习方向。
随着最近这几年人工智能的快速发展,自然语言处理技术的应用已经比较普及。但是自然语言处理的学习路径依然没有一个系统的认识。
下面分别从自然语言处理介绍、入门基础及研究方向、工作原理、技术现状、实际应用等角度出发,概要地介绍自然语言处理及相关的机器学习技术。
自然语言处理介绍——什么是自然语言处理?
自然语言处理是一门与语言学、计算机科学、数学、心理学、信息论、声学相联系的交叉性学科,是计算机通过可计算的方法对自然语言(所谓“自然”乃是寓意自然进化形成,是为了区分一些人造语言,类似C++、Java 等人为设计的语言)的各级语言单位进行转换、传输、存储、分析等加工处理的科学。
此领域探讨如何处理及运用自然语言,自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。
- 自然语言认知和理解是让电脑把输入的语言变成有意思的符号和关系,然后根据目的再处理。
- 自然语言生成系统则是把计算机数据转化为自然语言,从而可以代替人类做一些文书类的工作,例如咨询、售后、海量数据处理以及公文阅读与处理等。
自然语言处理入门基础
数学基础:
线性代数:向量、 矩阵、距离计算(余弦距离、欧式距离、曼哈顿距离、明可夫斯基距离、切比雪夫距离、杰卡德距离、汉明距离、标准欧式距离、皮尔逊相关系数)
概率论:随机试验、条件概率、全概率、贝叶斯定理、信息论
统计学:
图形可视化(饼图、条形图、热力图、折线图、箱线图、散点图、雷达图、仪表盘)
数据度量标准(平均数、中位数、众数、期望、方差、标准差)
概率分布(几何分布、二项分布、正态分布、泊松分布)
统计假设检验
语言学基础:语音、词汇、语法
Python基础
机器学习基础
深度学习基础:CNN、RNN、LSTM
自然语言处理的理论基础
自然语言处理研究方向
自然语言处理热门的研究方向包括:语言学方向、数据处理方向、语言工程方向、人工智能和认知科学这四大方向。
在此基础上又细分为:口语输入、书面语输入、语言分析理解、语言资源、语言生成、口语输入技术、话语分析与对话、文献自动处理、多语问题的计算机处理、信息传输和信息存储、自然语言处理中的数学方法、 多模态的计算机处理、自然语言处理系统的评测这十三个方面。
自然语言处理工作原理
自然语言处理通过机器学习(ML)进行。机器学习系统像其他任何形式的数据一样存储单词及其组合方式。将短语、句子,有时甚至整本书的内容都输入机器学习引擎,并根据语法规则和人们的现实语言习惯(或两者兼而有之)进行处理。然后,计算机使用这些数据来查找模式并推断出下一步的工作。
具象的流程我们可以理解为:形式化描述(将要研究的问题在语言上建立出一个形式化模型,用数学形式展现出来)➡️数学模型算法化(把建立的数学模型表示为算法)➡️程序化(计算机根据算法进行了实现,建立语言系统)➡️应用化(对系统改进满足实用需求))
自然语言实际应用
自然语言处理无数不在,它是如此普遍。
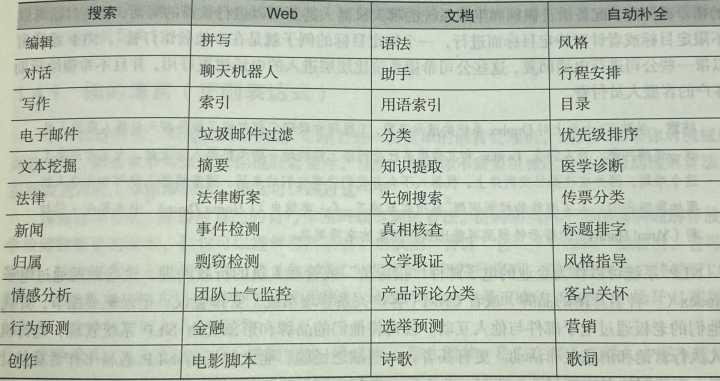 各种类型的NLP应用
各种类型的NLP应用
如果在索引网页或文档库时考虑了自然语言文本的含义,那么搜索引擎可以提供更有意义的结果。自动补全(autocomplete)功能使用 NLP 技术来完成所想语句的输入,这在搜索引擎和手机键盘中十分常见。许多文字处理器、浏览器插件和文本编辑器都有拼写校正、语法检查、索引生成等功能,特别是近年来,还出现了写作风格指导的功能。一些对话引擎(聊天机器人)使用自然语言搜索来为对话消息查找相应的回复。
美联社使用 NLP“机器人记者”撰写完整的金融新闻和体育赛事等报道。也许是因为人类气象学家使用了带有 NLP 功能的文字处理器来起草天气预报的脚本,机器人编写的天气预报听起来和家乡天气预报员的播报并没有什么两样。
早期电子邮件系统中的 NLP 垃圾邮件过滤器助力电子邮件,使其在 20 世纪 90 年代超越了电话和传真这两个传统通信渠道。在垃圾邮件过滤器和垃圾邮件制造者之间的这场“猫鼠游戏”中,前者保持了优势地位,但是在像社交网络这类场景下并非如此。据估计,有关 2016 年美国总统大选的推文中有 20% 由聊天机器人自动撰写而成。这些机器人放大了它们的所有者或开发者的观点,而这些“傀儡”的操纵者往往是政府或大公司,他们具备影响主流观点的资源和动机。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java