
Spark小文件合并优化
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存。Spark的性能,想要它快,就得充分利用好系统资源,尤其是内存和CPU。有时候我们也需要做一些优化调整来减少内存占用,例如将小文件进行合并的操作。
一、问题现象
我们有一个15万条总数据量133MB的表,使用SELECT * FROM bi.dwd_tbl_conf_info全表查询耗时3min,另外一个500万条总数据量6.3G的表ods_tbl_conf_detail,查询耗时23秒。两张表均为列式存储的表。
大表查询快,而小表反而查询慢了,为什么会产生如此奇怪的现象呢?
二、问题探询
数据量6.3G的表查询耗时23秒,反而数据量133MB的小表查询耗时3min,这非常奇怪。我们收集了对应的建表语句,发现两者没有太大的差异,大部分为String,两表的列数也相差不大。
CREATE TABLE IF NOT EXISTS `bi`.`dwd_tbl_conf_info` (
`corp_id` STRING COMMENT '',
`dept_uuid` STRING COMMENT '',
`user_id` STRING COMMENT '',
`user_name` STRING COMMENT '',
`uuid` STRING COMMENT '',
`dtime` DATE COMMENT '',
`slice_number` INT COMMENT '',
`attendee_count` INT COMMENT '',
`mr_id` STRING COMMENT '',
`mr_pkg_id` STRING COMMENT '',
`mr_parties` INT COMMENT '',
`is_mr` TINYINT COMMENT 'R',
`is_live_conf` TINYINT COMMENT ''
)CREATE TABLE IF NOT EXISTS `bi`.`ods_tbl_conf_detail` (
`id` string,
`conf_uuid` string,
`conf_id` string,
`name` string,
`number` string,
`device_type` string,
`j_time` bigint,
`l_time` bigint,
`media_type` string,
`dept_name` string,
`UPDATETIME` bigint,
`CREATETIME` bigint,
`user_id` string,
`USERAGENT` string,
`corp_id` string,
`account` string
)因为两张表均为很简单的SELECT查询操作,无任何复杂的聚合join操作,也无UDF相关的操作,所以基本确认查询慢的应该发生的读表的时候,我们将怀疑的点放到了读表操作上。通过查询两个查询语句的DAG和任务分布,我们发现了不一样的地方。
查询快的表,查询时总共有68个任务,任务分配比如均匀,平均7~9s左右,而查询慢的表,查询时总共1160个任务,平均也是9s左右。如下图所示:
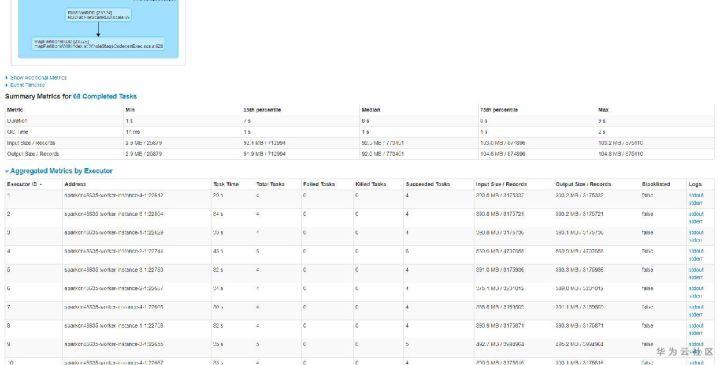
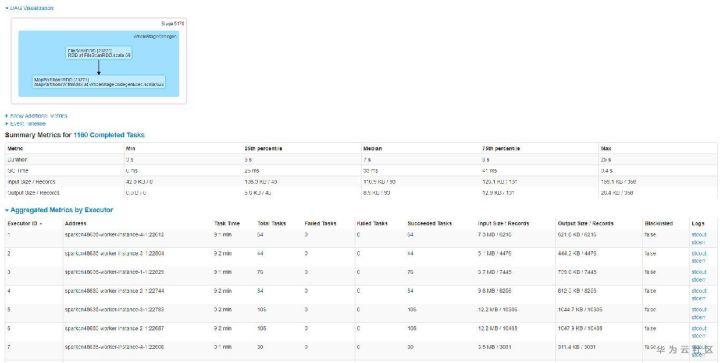
至此,我们基本发现了猫腻所在。大表6.3G但文件个数小,只有68个,所以很快跑完了。而小表虽然只有133MB,但文件个数特别多,导致产生的任务特别多,而由于单个任务本身比较快,大部分时间花费在任务调度上,导致任务耗时较长。
那如何才能解决小表查询慢的问题呢?
三、业务调优
那现在摆在我们面前就存在现在问题:
1、为什么小表会产生这么小文件
2、已经产生的这么小文件如何合并
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java