
详解GaussDB(for MySQL)服务:复制策略与可用性分析
简介
数据持久性和服务可用性是数据库服务的关键特征。
在实践中,通常认为拥有 3 份数据副本,就足以保证持久性。
但是 3 份副本,对于可用性的要求是不够的。维护 3 份一致的副本意味着,这些副本必须同时在线,系统才能保证可用。当数据库跨多个节点分片时,某些节点不可用的概率会随着节点数量的增加而呈指数增长。
在 GaussDB(for MySQL) 中,我们针对日志和数据采用不同副本策略,并采用一种新颖的恢复算法,来解决可用性的问题。
下面首先介绍写路径,然后介绍读路径,最后分析理论上的可用性估计,并与其它副本策略进行比较。
写路径
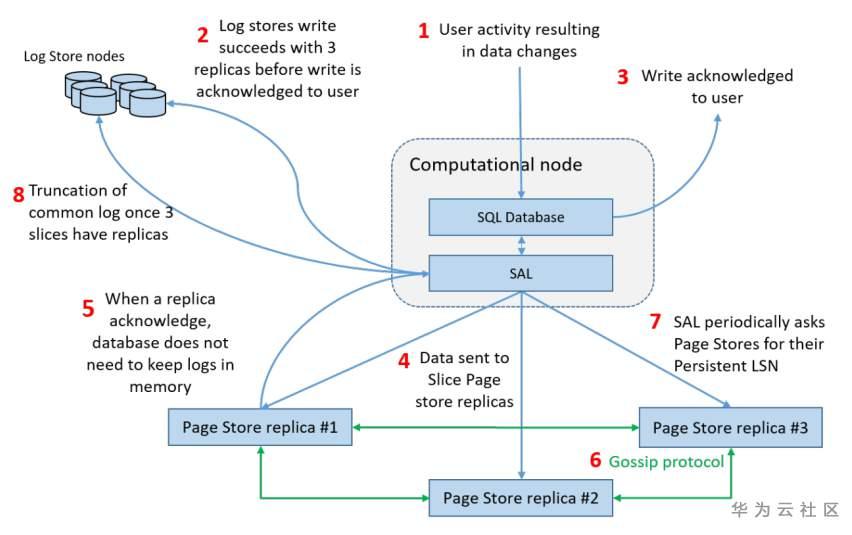
写路径如上图所示,下面对每一个步骤进行说明。
1)用户事务导致对数据库页面的更改,从而生成描述更改的日志记录(redo log,下面简称 redo)。
2)将 redo 写入到 Log Stores。写入 3 份副本,并且采用强一致性,即 3 份均写入成功才算成功。
3)将事务标记为已提交(committed)。
只要集群中有三个或以上的 Log Stores 可用,该数据库就可以进行写操作(因为写入只需要选择可用的节点即可,并不规定一定要写入某个节点)。对于成千上万个节点的群集,这实际上意味着 100% 的写入可用性。
4)redo 写入 Log Stores 之后,会将此 redo 放入到 SAL 的 write buffer 中,之后将此 buffer 写入到管理对应 slice 的 Page Store 上。
5)当任何一个 Page Store 副本返回成功,此写入成功,SAL 的 write buffer 被释放。
6)不同的 Page Store 副本之间使用 gossip 协议检测和修复缺失的日志。
空间回收
数据库运行过程中,会源源不断地产生 redo 日志。如果不将不需要的 redo 删除,可以预见,最终肯定会耗尽磁盘空间。在成功将 redo 写入所有 Slice 副本,并且所有数据库的读副本(read replica)都可以看到该记录之后,就可以将该日志从 Log Store 中删除。独立地跟踪每条 redo 的持久性很费资源,因此我们选择基于 LSN 来跟踪持久性。
对于 Page Store 的每个 slice,都有一个 persistent LSN,它的含义是 slice 接收到的所有日志记录中,保证连续(没有空洞)的最大 LSN。(譬如某个 slice 接收到 LSN 为 1 的 redo log 后,persistent LSN 变为 1,此时如果接收到 LSN 为 3 的 redo log,persistent LSN 依然为 1。之后如果接收到 LSN 为 2 的 redo log,即补齐了空洞之后, persistent LSN 变为 3)。
7)SAL 可以通过定期调用 api 或者在读写接口中获取每个 slice 的 persistent LSN(在恢复中也会使用)。
8)SAL 也会跟踪每个 PLog 的 LSN 范围。如果 PLog 中的所有 redo 的 LSN 都小于数据库 persistent LSN(3 副本中最小 persistent LSN),该 PLog 可被删除。
通过上面的机制,我们能够保证每条 redo 都至少会有三个节点上存在副本(一开始在 Plog Store 节点上有 3 副本,保证在 Page Store 节点上有 3 副本之后,将 Plog Store 节点上的副本删除,以回收磁盘资源)。
读路径
数据库前端以 page 粒度读取数据。
读取或者修改数据时,相应的 page 必须在 buffer pool 中。当 buffer pool 已满,我们又需要引入一个 page 时,必须将某些页面从 buffer pool 中淘汰。
我们对淘汰算法进行了修改,保证只有当所有相关 redo 日志都写入至少 1 个 Page Store 副本后,脏页才能被淘汰。因此,在最新的 redo 记录到达 Page Store 之前,保证相应的页面可从 buffer pool 中获得。 之后,可以从 Page Store 中读取页面。
对于每一个 slice,SAL 保存最新 redo log 的 LSN。主节点读取 page 时,读请求首先到达 SAL,SAL 会使用上述 LSN 下发读请求。读请求会被路由到时延最低的 Page Store。如果被选择的 Page Store 不可用或者还没有收到提供 LSN 之前的所有 redo,会返回错误。之后 SAL 会尝试下一个 Page Store,遍历所有副本,直到读请求可以被正确响应。
可用性分析
quorum replication
目前业界最广泛使用的强一致性复制技术基于 quorum replication。如果每份数据在 N 个节点上存在副本,每个读取操作必须从NR个节点接收响应,并写入NW个节点。
为了保证强一致性,必须满足 NR + NW > N 。业界许多系统使用 quorum replication 的不同组合方式。 例如,
1)RAID1 磁盘阵列中通常使用 N = 3,NR = 1,NW = 3;
2)PolarDB 中,N = 3,NR = 2,NW = 2;
3)Aurora 中,N = 6,NR = 3,NW = 4。
下面的分析中,仅考虑节点单独出现不可用的场景(不考虑譬如因为断点导致所有节点不可用的场景)。
假设 1 个节点不可用的概率为 x,则当 N - NW + 1 到 N 个节点同时不可用时,写请求会失败。 即一个写请求失败的概率可用如下公式计算:
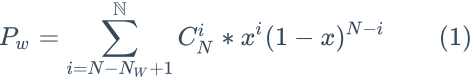
同理,一个读请求失败的概率计算公式如下:
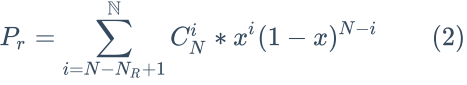
GaussDB(for MySQL)
写
在前面的写路径一节中已经提到,GaussDB(for MySQL) 的写 redo,不需要写到特定的 Log Store 上,所以公式 (1) 并不适用。对于写请求,只有当所有 PLog Store 都不可用时,才会失败。如果集群中 Log Store 足够多,这个概率几乎接近于 0。
读
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java