
数据库执行查询SQL的内部过程解析
用户提交一条查询SQL背后发生了什么?
在传统关系型数据库中,SQL处理器的组件主要包括以下几种:
• Query Parsing
负责进行词法和语法分析,把程序从人类高可读的格式(即SQL)转化成机器高可读的格式(AST,抽象语法树)。
词法分析指的是把SQL中的字符序列分解成一个个独立的词法单元——Token(<类型,值>)。
语法分析指的是从词法分析器输出的token中识别各类短语,并构造出一颗抽象语法树。而按照构造抽象语法树的方向,又可以把语法分析分成自顶向下和自底向上分析两种。而ClickHouse采用的则是手写一个递归下降的语法分析器。
• Query Rewrite
即通常我们说的"Logical Optimizer"或基于规则的优化器(Rule-Based Optimizer,即RBO)。
其负责应用一些启发式规则,负责简化和标准化查询,无需改变查询的语义。
常见操作有:谓词和算子下推,视图展开,简化常量运算表达式,谓词逻辑的重写,语义的优化等。
• Query Optimizer
即通常我们所说的"Physical
Optimizer",负责把内部查询表达转化成一个高效的查询计划,指导DBMS如何去取表,如何进行排序,如何Join。如下图所示,一个查询计划可以被认为是一个数据流图,在这个数据流图中,表数据会像在管道中传输一样,从一个查询操作符(operator)传递到另一个查询操作符。
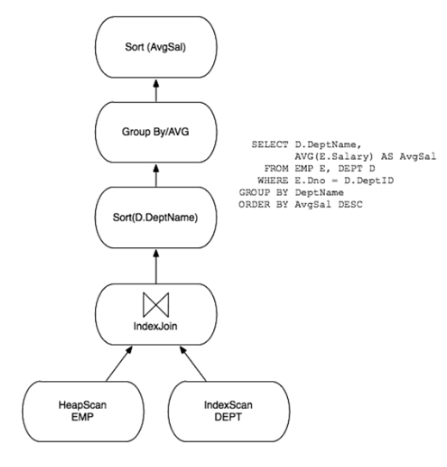
一个查询计划
• Query Executor
查询执行器,负责执行具体的查询计划,从存储引擎中获取数据并且对数据应用查询计划得到结果。
执行引擎也分为很多种,如经典的火山模型(Volcano Model),还有ClickHouse采用的向量化执行模型(Vectorization Model)。
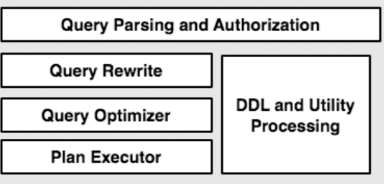
(图来自经典论文 Architecture Of Database System)
但不管是传统的关系型数据库,还是非关系型数据库,SQL的解析和生成执行计划过程都是大同小异的,而纵览ClickHouse的源代码,可以把用户提交一条查询SQL背后的过程总结如下:
1.服务端接收客户端发来的SQL请求,具体形式是一个网络包,Server的协议层需要拆包把SQL解析出来
2.Server负责初始化上下文与Network Handler,然后 Parser 对Query做词法和语法分析,解析成AST
3.Interpreter的 SyntaxAnalyzer 会应用一些启发式规则对AST进行优化重写
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java