
精准推断用户习惯和用户画像的模型
摘要:推导迁移学习对计算机视觉和 NLP 领域产生了重大影响,但尚未在推荐系统广泛使用。虽然大量的研究根据建模的用户-物品交互序列生成推荐,其中很少尝试表征和迁移这些模型从而用于下游任务(数据样本通常非常有限)。
在本文中,我们深入研究了通过学习单一用户表征用户各种不同的下游任务,包括跨域推荐和用户画像预测。优化一个大型预训练网络并将其适配到下游任务是解决此类问题的有效方法。但是,微调通常要重新训练整个网络,优化大量的模型参数,因此从参数量角度微调是非常低消效的。为了克服这个问题,我们开发了一种参数高效的迁移学习架构,称为 PeterRec。PeterRec 可以快速动态地配置成各种下游任务。具体来说,PeterRec 通过注入一些的的小型但是极具表达力的神经网络,使得预训练参数在微调过程中保持不变。我们进行大量的实验和对比测试以展示学习到的用户表示在五个下游任务中有效的。此外,我们证实了 PeterRec 可以在多个领域进行高效的迁移学习时可以达到与微调所有参数相当或有时更好的性能。
序言:
在过去的十年中,社交媒体平台和电子商务系统(例如抖音,Amazon 或 Netflix)越来愈多的被使用。大量的点击和购买互动,以及其他用户反馈是在此类系统中显式或隐式创建的。
以抖音为例,常规用户在每个周可能观看成百上千个短视频。与此同时,大量的研究表明这些用户交互行为可以用来建模用户对于物品的喜好。比较有代表性的深度学习模型,例如 GRU4Rec 和 NextItNet 在时序推荐系统任务中都取得了较大的成功。然而绝大多数已有工作仅仅研究推荐任务在同一平台的场景,很少的工作尝试学习一个通用用户表征,并且将该用户表征应用到下游任务中,例如冷启动用户场景,用户画像预测。
为了解决这个挑战,本文尝试一种无监督训练方式预训练一个神经网络,然后将此神经网络迁移到下游任务中。为此,论文需要至少解决三个问题;(1)构造一个有效的预训练模型,能够建模超长用户点击序列;(2)设计一种微调策略,能够将预训练网络适配到下游任务。目前为止,没有相关文献证实这种无监督学习的用户表征是否对其他场景有帮助。(3)设计一个适配方法,能够使得不同任务都能充分利用预训练网络参数,从而不需要微调整个网络,达到更加高效的迁移学习方式。
注意:PeterRec 不需要借助于任何图像和文本特征,仅需要用户点击物品 ID 即可。中间网络为大量堆叠的空洞卷积网络。
为了达到以上目标,研究者提出采用空洞卷积神经网络构建大型的预训练模型,采用一定空洞率设置的多层卷积网络可以实现可视域指数级增长,从而捕获和建模超长的用户点击行为,这一优势是目前很多时序网络难以达到的,例如经典的 RNN 网络建模长序列时通常会遇到梯度消失和爆炸问题,并且并行训练低效,Transformer 等知名 NLP 网络对显存需求和复杂度也会随着序列长度以二次方的级增加。同时为了实现对预训练网络参数的最大化共享,论文提出了一种模型补丁方式,类似于植物嫁接技术,只需要在预训练网络插入数个的模型补丁网络,既可以实现预训练网络的快速迁移,效果甚至好于对整个模型全部微调。研究主要贡献:
- 提出一种通用用户表征学习架构,首次证实采用无监督或者自监督的预训练网路学习用户点击行为可以内用来推测用户的属性信息。这一发现将有望改进很多公共服务,带来更大的商业利润,同时也会引发甚至推动对于隐私保护的相关问题的研究。
- 论文提出了一种非常有效的模型补丁网络,网络相对于原来的空洞卷积层参数量更小,但是具有同等表达能力。
- 论文提出了两种模型补丁的插入方式,并行插入和串行插入
- 论文通过分割实验报告了很多有洞察的发现,可能会成为这个领域的未来一些研究方向
- 论文开源相关代码和高质量的数据集,从而推动推荐系统领域迁移学习的研究,建立相关基准。
方法:

本研究预训练网络采用空洞卷积网络,每层空洞因子以 增加,通过叠加空洞卷积层达到可视域指数级的增加,这一设计主要遵循时序模型 NextItNet[1],如图 1 所示。预训练优化方式,本文采用了两种自监督方式,分别是单向自回归方式[1]以及双向遮掩法[2],分别对应因果卷积和非因果卷积网络,如图 2 所示。
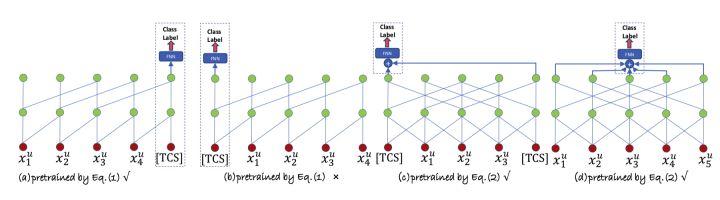
本文的微调方式非常简单,采用直接移除预训练 softmax 层,然后添加新任务的分类层,另外,本文的主要贡献是在预训练的残差块(图 3(a))插入了模型补丁网络,每个模型补丁有一个瓶颈结构的残差块构成,如图 3(f)所示。本研究提出了几种可选择的插入方式,如图 3(b)(c)(d)。注意(e)的设计效果非常差,文章分析很可能是因为模型补丁的和操作,并行插入的和操作与原始残差网络的和操作夹杂在一起,影响最终优化效果。另外文中给出分析,通常模型补丁的参数量仅有原始空洞卷积不到十分之一的参数量,但是可以达到与所有参数一起优化类似或者更好的效果。

实验:
本文作者进行了大量的实验,并且论文会开源代码和相关脱敏后的数据集。
实验 1
论文首次证实采用无监督预训练方式非常有效,论文对比 PeterRec 的两种设置,有无预训练下的实验效果,如图 4. 图中所示 PeterRec 大幅度超越 PeterZero,证实了本研究预训练的有效性。

实验 2
几种微调方式比较,如图 5 所示。图中证实 PeterRec 仅仅微调模型补丁和 softmax 层参数达到了跟微调所有参数一样的效果,但是由于仅有少数参数参与优化,可以很好的抗过拟合现象。

FineAll 微调所有参数,FineCLS 只微调最后 softmax 层,FineLast1 微调最后一个空洞卷积层,FineLast2 微调最后两个空洞卷积层。
实验 3
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java