
怎么让开发中少产生BUG?
软件开发中的缺陷隐含着极高的价值,但是许多组织都仅仅忍受了缺陷带来的成本和后果,却让价值白白溜掉了。
缺陷的价值是其触发的学习和成长的机会。把握缺陷带来的学习机会,可以快速提高组织的能力,未来的缺陷更少,成本更低,更容易成功。但同时,有效的缺陷分析和跟踪行动需要有效的方法和相应的组织的支持。
缺陷隐含着极高的价值
最近我们做了一次关于缺陷分析的工作坊。
“发生缺陷是一件好事吗?” 在工作坊开始的时候,我这么问参与的同学。
“那当然是一件坏事了。”
“不管是不是好事,它就在那儿。我觉得无所谓好不好,这是一件正常的事情。”
“这么说好像也对,但是缺陷很麻烦,我没法喜欢缺陷。”
是的,没有人喜欢缺陷,它消耗研发成本,影响开发周期,但同时,缺陷又和软件开发如影随形,无论多少,始终都在。这是为什么呢?
看下面的这张图:
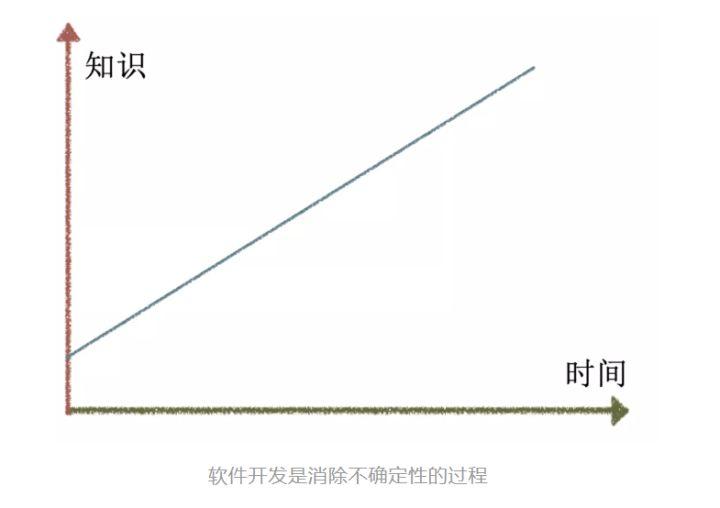
软件开发和工业生产完全不同。工业生产通过消除过程中的各种可变性,能够逐步逼近零缺陷的目标。所以,六西格玛方法在工业生产中非常行之有效。
软件开发的过程则恰恰相反。每一次开发,都是不确定的,我们往往都是在项目临近结束的时候,对整个项目的各种问题和细节才变得清晰。在这种假设下,与其追求零缺陷,倒不如说是我们应该追求降低缺陷的影响,比如,在缺陷产生的第一时间(注入时间甚至注入之前)就发现缺陷——因为这时候缺陷的成本几乎为零,这也就可以等价为“零缺陷”了吧。
如果说工业生产中的六西格玛方法来自于对生产系统的打造,那么,在软件开发中,“零缺陷”对应的系统是什么呢?它当然包含软件研发的流程和工具,但是,在我看来,最重要的,应该是打造软件的核心主体——人。通过缺陷分析来持续学习,才能不浪费缺陷所消耗的成本。
为什么会重复踩坑
有不少团队是有缺陷原因分析的。我曾经仔细分析过一个团队的缺陷原因分析,发现了下面这些缺陷原因的高频词:
- 编码有问题,下次写代码的时候想的更仔细一些。
- 代码评审做的不好。下次代码评审要充分。
- 业务场景分析不全面,下次分析的更全面一些。
- ......
我相信,写下上述原因分析的同学,内心一定是很真诚的,也是真心觉得自己当时代码写的不够好,业务场景分析的不全面,代码评审不够充分。但是,这个分析带来的行动,却往往是不可达成的。是真的想的不仔细吗,还是就是想不到?这次评审做的不好,下次就肯定能做好了吗?这次场景分析不全,那么怎么才能更全呢?
这种原因分析过于宽泛了,以至于很难产生实际有效的改进行动,下次往往还是会在同样的地方跌倒——大家只要看一下在既往的原因分析中,有多少次类似的答案?每一次重复,就是一次新的踩坑。
还有一类原因分析,恰恰相反,又过于具体化了,具体化到了没有学习价值的层面上。例如,这是当时设计的不对,A 服务就不该调用 B 服务,A
服务应该考虑到B服务调用中的异常场景,等等。好吧,缺陷现在已经修复了,A 服务调用 B 服务出现的异常场景已经固化在代码中了,下一次如果是 C
服务调用 D 服务的异常场景应该怎么办呢?
最合适的缺陷原因应该基于这样的标准:这些原因需要形成系统化的可行动的结果。这个标准的检验方式是:下一次如果发生某某场景,我们的应对方案是否有效?
做好缺陷分析的 5 个要点
在实践中,我们总结了 5 个要点,来最大化出于学习目的的缺陷分析的实践操作。它们是:
- 及时总结,设置卡点
- 结对分析,小组总结
- 负面清单支持下的全量分析
- 可操作的结果
- 团体学习,机制建设
及时总结,设置卡点
“缺陷分析很重要,但是研发同学都太忙了,我们两个月集中做一次怎么样?”
别那么紧张——及时才是最节约的方式。要从忙碌中解放出来,每次花 15 分钟,做一次有效的缺陷分析,时间已经妥妥的啦。
缺陷分析的最好时间是缺陷修复完成的时间。此时记忆最新鲜、也能早收益。如果一个缺陷已经过去了两个月,那么缺陷分析的成本就变高了,得找回原来的记忆和当时的上下文,这个记忆准确不准确还是另一回事。
怎样才能保证及时地做,从而保证这些重要而不紧急的事情发生呢?一个比较有效的方式,是设置流程中的卡点:当缺陷被设定为已修复状态、或者设定为已关闭状态时,强制把缺陷分析设定为一个流程卡点,这样就能形成比较好的驱动。
结对分析,小组总结
谁来负责缺陷分析?是让具体这个缺陷的同学来做,还是召集整个团队一起?
召集整个团队来做缺陷分析,有时候代价过于高昂。即使仅仅分析比较后期的线上问题,即使每个缺陷仅仅分析 15 分钟:100 个缺陷,每个团队 8 个人,乘积就是 12,000分钟,合 200 个小时,也是一个惊人的数字,投入产出不成比例。
解决缺陷的同学确实是对这个缺陷理解最好。但是,这会不会形成“单点问题”,降低问题分析的有效性?
我们的方案是:
把结对分析作为制度
让解决缺陷的同学担任负责人,搭配上一个小伙伴。结对既形成了知识方面的互补,一定程度上消除了思维盲点,也通过结对形成了更深入的讨论,也提前进行结果的“验收”,提高分析的质量。如果有必要,结对的小组可以自主决定是否引入其他人参与。
团队定期讨论学习
团队定期对重要的缺陷分析结果进行讨论,既是对小组成果的验收,更有利于在团队成员间形成传播,互相学习。
负面清单支持下的全量分析
缺陷分析的目的是提升,所以,重在解决那些“未知的未知”的问题。显然不是每个缺陷都应该深入分析。但是,如果我们针对每个缺陷都定义它该不该分析,又会导致决策成本过高,而且质量也不可靠。所以,我们的做法是在默认全量的基础上,使用负面清单进行过滤。凡是负面清单不存在的,都进行缺陷分析。负面清单是团队级别的。每个团队都应该维护自己的列表,例如:
- 偶发问题
- 已经列在改进项中的问题(不断扩充)
这个事情和淘金有些类似,明确不要什么,能更高效地避免那些真正值得做的事情不被淹没。事实上,每次缺陷分析都会扩充负面清单的长度,所需的缺陷分析数量将越来越少,问题越来越聚焦,时间也越来越节省。
可操作的结果
缺陷分析应该产生有价值的洞见,足够的深度是重点。在如何产生深度洞见方面已经有非常多成熟的方法,最典型的是 5
Whys,此外还有鱼骨图等著名工具可用。为了控制篇幅,本文略去对这些方法的介绍,只通过一个实例来说明在实际的缺陷分析中,我们是如何产生深度洞见的。
某缺陷描述了如下的场景(该实例在不影响问题说明的情况下做了适度抽象):
用户持有某个虚拟设备,该设备有一些附属资源,当用户删除设备时,该设备的附属资源应该被释放。但是,发现在一种特殊场景下,这个附属资源并没有得到释放。
代码如下:
void releaseResources (resoure_id){ if
(failedOfHardwareResourceRelease(resource_id)){
writeLog("resource release failed"); } }
下面是关于这个问题的对话:
“原因是什么?”
“我们没有在需求分析阶段考虑到这种释放不成功的场景。”
“OK。需求分析是问题,这是一个改进点。——但是更重要的:最后发现这个问题的最直接的机会点是哪个时间点?”
“写代码的时候。”
“写代码的时候我们注意到这个问题了吗?”
“注意到了啊,所以写了 log,但是没仔细想应该怎么处理。这说明我们对这段代码的职责定义不清晰。”
“也许我们可以在编程规范中加入一条:出现异常场景时不应该只记录 log,而应该和负责人澄清场景和处理方案。在未来,当出现了仅仅出现写错误 log,但是没有其他处理的时候,我们就能注意到这一点。”
检验分析深度是否足够,最直接的指标就是产生的结果是否是“可行动的”。如果一个结果是不可行动的,往往意味着深度或者抽象不够。
团体学习,机制建设
学习型组织并不总是容易建立。除了上述心智模型和操作方法之外,组织机制往往是成功的重点。我们总结了如下几点:
- 是长期存在的团队
- 建立持续学习的心智模型
- 持续维护和利用本组织的智力资产
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java