
定向网络爬虫技术和反反爬虫策略
导读
爬虫作为搜索引擎核心部件,伴随着互联网规模的发展而壮大。在互联网初期,规模不是很大的时候,网站分类较少,内容也偏少,在互联网查找信息很容易。然而随着网络信息和资源的不断增多,如何快捷的获得用户期望的信息变得非常重要,爬虫作为自动获取网页信息的工具,得到了极大的发展。
爬虫的分类
最早出现的爬虫程序,是Matthew Gray研发的World wide Web Wanderer。刚开始它只能够统计服务器数据量,后来发展到能够搜索网站域名。随着现代互联网的更快速发展,不仅搜索引擎的提供商越来越多,爬虫获取的信息量和网页数量令人震惊,而且爬虫程序对应的分类越来越细致多样。
根据信息量级大小、网站数量多少以及爬取对象的不同,可以大致将爬虫程序的发展过程分为4个方面:
1、通用网络爬虫
这类爬虫是以获取全网内容为目的,主要用于商业化的搜索引擎中,最具代表性的有Google,Bing,Sogou,Baidu,Yahoo等。它们获取到的内容主要以网页文字为主,背后有一个巨大的分布式数据库来保存这些从互联网络上获取的内容,然后查找时根据用户的查询条件进行相关度匹配,将结果返回给用户。
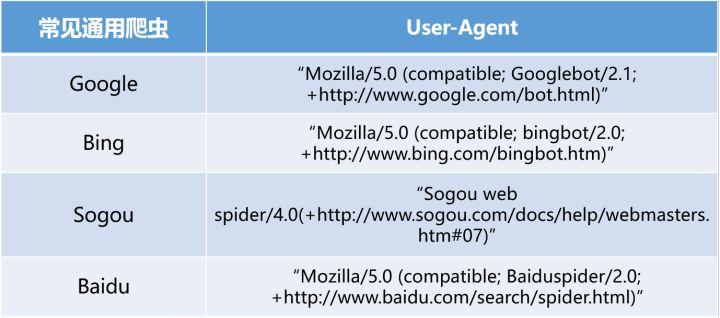 表1 通用网络爬虫的UA标识
表1 通用网络爬虫的UA标识
2、聚焦网络爬虫
根据既定的抓取目标,有选择的访问互联网上的网页与相关链接,获取所需要的信息。这类爬虫主要用于垂直搜索引擎中。与通用爬虫不用,它并不追求大的网页库的覆盖,而将目标定位抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。为了高效率的抓取与主题相关的网络页面,需要在抽取Url列表后增加目标Url和主题相关性计算模块。常用的相关算法有:Best first search、Fish search、Shark search等。聚焦网络爬虫的设计主要评价标准是链接主题预测的准确性,计算的时空复杂度,以及爬虫系统的自适应性3个方面,其中提高链接价值预测的方法可以结合机器学习等工具提高准确度。
3、站点网络爬虫
站点爬虫是针对特定网站进行的全站内容获取的爬虫系统,这类爬虫获取的信息量级相比前两种爬虫类型都要小,爬取的对象主要是网站的富文本网页、视频、图像以及音频内容,数据存储量小,技术复杂度低。这类爬虫在设计实现上与前两种爬虫的区别主要在于不需要大量初始Url列表,新链获取可以采用站内链接,同时避免了新链价值计算以及和与目标主题的相关性计算。
4、定向网络爬虫
定向网络爬虫是针对互联网上特定内容的增量更新式爬虫。这类爬虫以RSS/Atom订阅类爬虫为代表,具有具体的内容对象链接,需要进行重复请求。定向网络爬虫还要求更新请求具有实时性或具有特定格式内容的解析能力。
Mole爬虫系统有关技术
Mole爬虫系统是搜狗社区搜索部研发的定向网络爬虫系统,它类似与传统的Rss/Atom订阅系统。通过预添加的订阅源,可以及时的将各个UGC内容平台的社交内容聚合展示。
其中涉及到的关键技术实现从4个方面阐述:
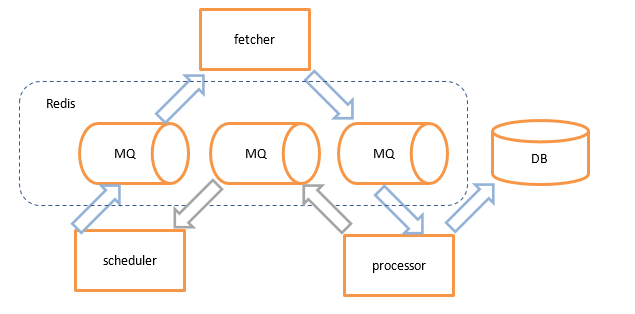
1、分布式设计
Mole核心抓取组件主要分为三部分:Scheduler、Fetcher以及Processor三部分构成:
- Scheduler负责待更新订阅源的调度,新发现详情页面调度,Url滤重以及流速控制等功能。
- Fetcher下载组件用于请求内容的下载,它由四种类型下载器组合而成:
>> 异步Http下载器,基于Tornado异步框架实现,具有强悍的并发请求能力。
>> PhantomJs模拟器,增加了JavaScript脚本执行能力。
>> Pupeteer+chromium下载器:模拟用户浏览器操作行为。
>> Anyproxy+Android模拟器:扩展App类内容的请求能力。 - Processor组件主要是用于结构化内容的抽取,包括Html,xml以及Json等格式的文档。
各个组件之间通过消息队列连接。除了Schedule模块受Url滤重限制需要设计成单点服务外,Fetcher和Processor模块都可以多实例分布式扩展。
2、流速控制
爬虫对目标站点的内容的获取是通过http请求得到的,大量的http请求需要占据目标站点的带宽,为了减小目标站点服务器的压力,需要限制爬虫框架的下载速度。
常用的流量控制算法有漏桶算法和令牌桶算法。Mole爬虫系统采用的是可以很好兼容突发性流量的令牌桶算法。
- 漏桶算法思路比较简单,将待调度的Url看成流动的水,水以一定的速度流入漏桶里,漏桶按照预先设定的速度出水;当水流速度过大就溢出,然后漏桶就拒绝新的流入请求。漏桶的露出速率是固定的参数,当发生突发的请求时,不能让突发的请求很快的处理,因此漏桶算法对于存在突发特性的流量缺乏效率。
 图片来源:quora
图片来源:quora
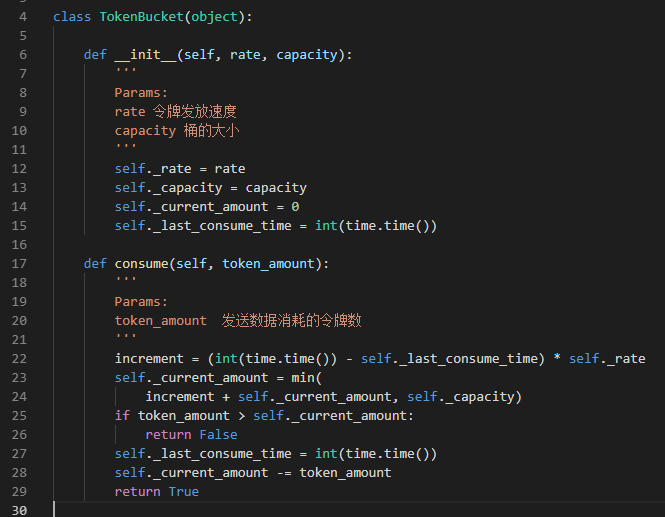
- 令牌桶算法可以很好的支持突发性的流量请求。令牌桶算法主要有以下几个规则构成:按照固定速度R往桶中放入若干枚Token;当桶中token数目达到桶容量capacity时不再增加;当新请求来临时,每个请求都会从桶中拿走若干枚Token;如果没有Token可拿就阻塞或拒绝服务。当有突发性的流量到来时,因为桶中已经有一定量的Token,所以突发性的流量也可能很快处理。
 图片来源:quora
图片来源:quora
代码示例:
3、Url滤重
在网络爬虫运行过程中,当抓取模块完成对网页的下载后,解析模块会对下载到的网页进行解析,抽取嵌套在HTML中的其他网页的Url,将这些Url填充到带抓取队列进行下一轮抓取。已经抓取过的Url有可能又会被重新抽取到,所以如果没有Url滤重,就会让某些页面重复抓取,这无疑会严重影响爬虫系统的运行效率。
常用的Url滤重方法有Hash表、指纹+Hash表、BoomFIlter、数据库滤重四种方法。Hash表方法是将Url作为Key,插入到Hash表中;新抽取的Url如果存在在Hash表中,则丢弃;否则填充到待抓取队列中。指纹+Hash表是将Url通过MD5或SHA-1等签名方法压缩后作为Key,然后进行Hash表存储。这两种方法都是基于内存,查询效率高,具有100%去重准确率。
BoomFilter是基于位存储和Hash计算实现的过滤器,它具有高内存利用率和时间复杂度为O(1)的查询效率,但是存在假阳性错误,即可能将没有抓取过的URL判断为已经抓取过,从而形成漏抓。
Mole中Url滤重算法是采用基于数据库的滤重算法,每个Url对应的Task存在存活期限(age)和强制标志(force),在存活期限内,相同的Url不会重复抓取;如果超过存活期限或强制标记为True,则需要重新调度。这种滤重方法占用存储空间相比较前面三种方法都要多,但是这种方法提供了额外的存储状态,可以实现更加精细化的Url调度策略。
4、数据库存储优化
Mole抓取后的内容存储在ElasticSearch(ES)上,ES是当下流行的企业级搜索引擎,它具有分布式设计,可以通过横向扩展节点数据提高其存储能力。目前,我们在ES上存储了接近50亿的文档数,对ES的写入和存储都带来很大压力,ES的性能优化就变的至关重要。
ES索引的优化:我们针对ES索引的优化,主要工作是重新梳理了存储文档的mapping格式,其中全面禁用了_all字段存储,这个字段对于全面文档的搜索查询非常重要,但是对于特定字段的查询就意义不大;对于不需要建索引的字段需要明确的将index设为no;某些文本字段的doc_value也设置为false。优化完成后,索引文件大小减少为原来的一半,查询效率并没有受到影响。
ES写入性能优化:ES的写入性能受限,主要原因是因为ES写入硬盘策略导致的。ES建索引写入数据,数据最先保存在内存buffer中,然后再刷入到lucene的底层文件segment中;写入segment完毕后再执行refresh操作,才能将数据commit到磁盘中。写性能优化首先要调整了ES的刷新间隔,这个需要根据磁盘IO调整,防止磁盘写入抖动;数据根据读写访问的频次分为冷热数据,冷热数据需要分开存储,读写频率较高的数据迁移到ssd盘上;ES内部数据传输是经过内部操作Bulk实现的,Bulk操作通过队列来控制写入任务的执行顺序,如果Bulk队列挤压时写入任务有可能超时执行,这时不要立即重试,否则会使Bulk任务越积越多。
反反爬虫策略
恶性的网络爬虫以获取互联网内容为目的,通过不计后果的访问目标网站,在获得信息的同时,也会给目标网站造成服务器压力。内容生产网站为了限制恶性的网络爬虫大量无效的流量访问,开发出了多种反爬虫策略,力求在降低恶性网络爬虫请求量的同时又不会对正常用户的请求带来影响。这些爬虫与反爬虫的攻防请求既对网站的开发带来成本,又使得网络信息的获取带来困难。爬虫技术是无害的,但请不要恶意使用爬虫技术。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java