
计算机视觉的可解释性 AI 探讨
简介: 准确性与可解释性是不能同时达到的吗?来自 IEEE 研究员 Cuntai Guan 这样认为:“许多机器决策仍然没有得到很好的理解”。大多数论文甚至提出在准确性和可解释性之间进行严格区分。
准确性与可解释性是不能同时达到的吗?来自 IEEE 研究员 Cuntai Guan 这样认为:“许多机器决策仍然没有得到很好的理解”。大多数论文甚至提出在准确性和可解释性之间进行严格区分。
神经网络是准确的,但无法解释;在计算机视觉中,决策树是可解释的,但不准确。可解释性 AI(XAI) 试图弥合这一分歧,但正如下面所解释的那样,“XAI 在不直接解释模型的情况下证明了决策的合理性”。
这意味着金融和医学等应用领域的从业者被迫陷入两难境地:选择一个无法解释的、准确的模型,还是一个不准确的、可解释的模型。
什么是“可解释的”?
定义计算机视觉的可解释性是一项挑战:解释像图像这样的高维输入的分类意味着什么?正如下面讨论的,两种流行的定义都涉及到显著图和决策树,但是这两种定义都有缺点。
可解释性 AI 不能解释什么
显著图:
许多 XAI 方法产生的热图被称为显著图,突出显示影响预测的重要输入像素。然而,显著图映射只关注输入,而忽略了解释模型如何决策。

拍摄原始图像

使用一种称为 Grad-CAM 的方法的显著图

和另一种使用引导反向传播方法的图像
显著图不能解释什么
为了说明为什么显著图不能完全解释模型如何预测,这里有一个例子:下列显著图是相同的,但是预测结果不同。
为什么?尽管两个显著图都突出显示了正确的对象,但有一个预测结果是不正确的。回答这个问题可以帮助改进模型,但是如下所示,显著图不能解释模型的决策过程。

模型预测结果为有耳朵的鸟

模型预测结果为有角的鸟
这些是使用 Caltech-UCSDBirds-200-2011 (或简称CUB 2011) 在 ResNet18 模型上运用 Grad-CAM 方法得到的结果。虽然显著图看起来非常相似,但是模型的预测结果不同。因此,显著图并不能解释模型是如何达到最终预测的。
决策树
另一种方法是用可解释的模型代替神经网络。深度学习之前,决策树是准确性和可解释性的黄金标准。下面演示决策树的可解释性,它通过将每个预测分解为一系列决策来工作。
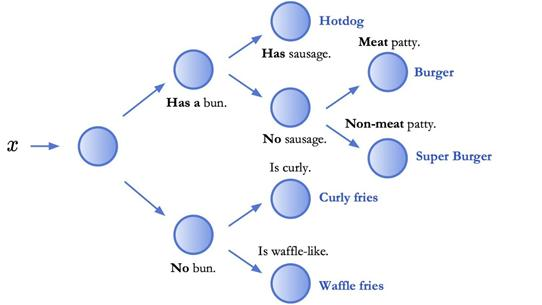
与仅仅预测“大汉堡”或“华夫饼”不同,上面的决策树将输出一系列导致最终预测的决策。然后可以分别对这些中间决策进行验证或质疑。因此,经典的机器学习将这种模型称为“可解释的”。
但是,就准确性而言,决策树在图像分类数据集²上落后于神经网络达 40%。神经网络和决策树混合算法也表现不佳,甚至在数据集 CIFAR10 上无法匹配神经网络,该数据集有如下所示的 32x32微小图像。

该示例展现了 32x32 有多小。这是来自 CIFAR10 数据集的一个样本。
这种精度差距损害了可解释性:需要高精度、可解释的模型来解释高精度的神经网络。
进入神经支持的决策树
通过建立既可解释又准确的模型来改良这种错误的二分法。关键是将神经网络与决策树相结合,在使用神经网络进行低级决策时保留高级的可解释性。
如下所示,将这些模型称为神经支持的决策树(NBDTs),并证明它们能够在保持决策树可解释性的同时,与神经网络的准确性相匹配。
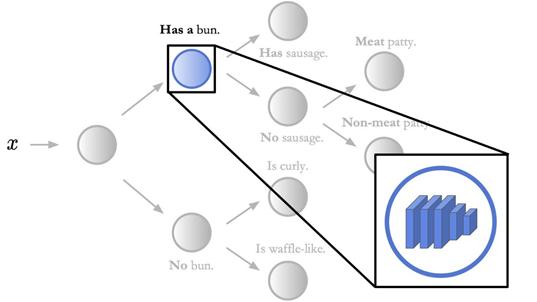
在此图中,每个节点都包含一个神经网络。该图仅突出显示了一个这样的节点和内部的神经网络。在神经支持的决策树中,通过决策树进行预测,以保留高级解释性。
但是,决策树中的每个节点都是做出低级决策的神经网络。上面的神经网络做出的“低级”决定是“有香肠”或“没有香肠”。
NBDT 与决策树一样可解释。
与当今的神经网络不同,NBDT 可以输出中间决策来进行预测。例如,给定图像,神经网络可以输出 Dog。但是,NBDT 可以同时输出Dog和Animal,Chordate, Carnivore(下图)。

在此图中,每个节点都包含一个神经网络。该图仅突出显示了一个这样的节点和内部的神经网络。在神经支持的决策树中,通过决策树进行预测,以保留高级解释性。
但是,决策树中的每个节点都是做出低级决策的神经网络。上面的神经网络做出的“低级”决定是“有香肠”或“没有香肠”。上面的照片是根据 Pexels 许可从 http://pexels.com 获取的。
NBDT 实现了神经网络的准确性。
与其他任何基于决策树的方法不同,NBDT 在 3 个图像分类数据集上都匹配神经网络精度(差异小于 1%)。 NBDT 还能在ImageNet上实现神经网络 2% 范围内波动的准确性,ImageNet 是拥有 120 万张 224x224 图像的最大图像分类数据集之一。
此外,NBDT 为可解释的模型设置了新的最新精度。 NBDT 的 ImageNet 准确度达到 75.30%,比基于决策树的最佳竞争方法高出整整 14%。为了准确地说明这种准确性的提高:对于不可解释的神经网络,类似的 14% 的增益花费了 3 年的研究时间。
神经支持的决策树可以解释什么,如何解释
个人预测的理由
最有见地的理由是根据该模型从未见过的对象。例如,考虑一个 NBDT (如下),并在斑马上进行推断。尽管此模型从未见过斑马,但下面显示的中间决策是正确的——斑马既是动物又是蹄类动物。单个预测的正确性的能力对于没见过的物体至关重要。
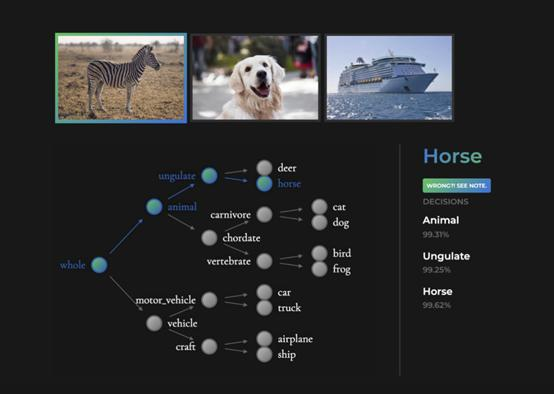
NBDT 甚至可以为没见过的物体做出准确的中间决策。在此,该模型在 CIFAR10 上进行了训练,并且之前从未见过斑马。尽管如此,NBDT 仍正确地将斑马识别为动物和蹄类动物。上面的照片是根据 Pexels 许可从 http://pexels.com 获取的。
模型行为的理由
此外,发现可以使用 NBDT 后,可解释性的准确性得到了提高。这与简介中的二分法背道而驰:NBDT 不仅具有准确性和可解释性,还使准确性和可解释性成为同一目标。
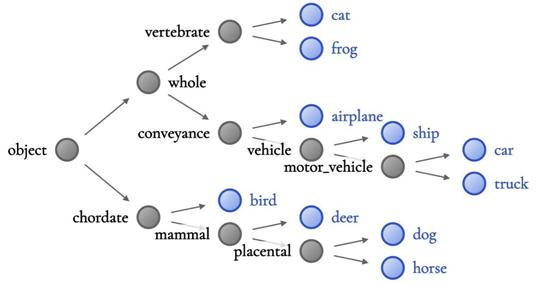
ResNet10层次结构
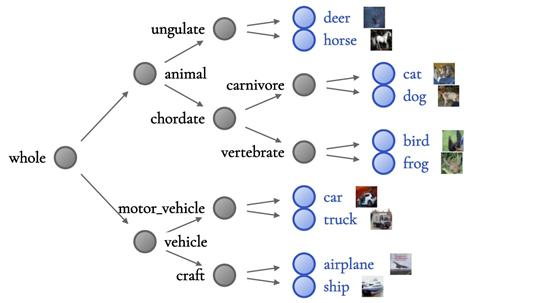
WideResNet层次结构
在前者中,“猫”,“青蛙”和“飞机”位于同一子树下。相比之下,WideResNet 层次结构在每一侧干净地分割了 Animals 和 Vehicles。上面的图片来自 CIFAR10 数据集。
例如,较低精度的ResNet⁶层次结构将青蛙,猫和飞机分组在一起的意义较小。这是“不太明智的”,因为很难找到所有三类共有的明显视觉特征。
相比之下,准确性更高的 WideResNet 层次结构更有意义,将 Animal 与 Vehicle 完全分开——因此,准确性越高,NBDT 的解释就越容易。

图源:unsplash
了解决策规则
使用低维表格数据时,决策树中的决策规则很容易解释,例如,如果盘子中有面包,那么选择右侧节点,如下所示。但是,决策规则对于像高维图像这样的输入而言并不那么直接。
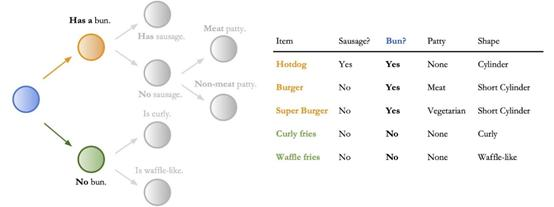
此示例演示了如何使用低维表格数据轻松解释决策规则。右侧是几个项目的表格数据示例。左侧是根据此数据训练的决策树。
此时,决策规则(蓝色)是“是否有面包?”所有带有面包(橙色)的项目都发给最上面的节点,而所有没有面包(绿色)的项目都发给最下面的节点。该模型的决策规则不仅基于对象类型,而且还基于上下文、形状和颜色。
为了定量地解释决策规则,使用了称为 WordNet7 的现有层次;通过这种层次结构,可以找到类之间最具体的共享含义。例如,给定类别 Cat 和 Dog,WordNet 将提供哺乳动物。如下图所示,定量地验证了这些 WordNet 假设。

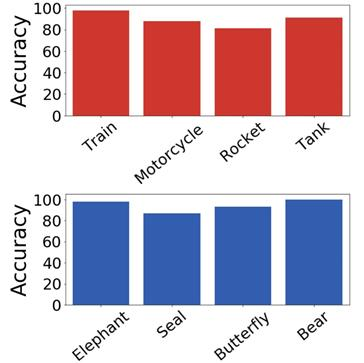
左子树(红色箭头)的 WordNet 假设是 Vehicle。右边(蓝色箭头)的 WordNet 假设是 Animal。为了定性地验证这些含义,针对没见过的物体类别对 NBDT 进行了测试:
查找训练期间未见过的图像。
根据假设,确定每个图像属于哪个节点。例如,大象是动物,所以*可以找到正确的子树。
现在,可以通过检查将多少图像传递给正确的节点来评估假设。例如,检查将多少张大象图像发送到“Animal”子树。
这些分类的正确性显示在右侧,没见过的动物(蓝色)和没见过的 Vehicle (红色)都显示较高的准确性。
请注意,在具有 10 个类别(即 CIFAR10)的小型数据集中,可以找到所有节点的 WordNet 假设。但是,在具有 1000 个类别的大型数据集(即 ImageNet)中,只能找到节点子集的 WordNet 假设。
一分钟内尝试 NBDT
现在有兴趣尝试 NBDT 吗?无需安装任何软件,就可以在线查看更多示例输出,甚至可以尝试 Web 示例。或者,使用命令行实用程序来运行推理(使用 pip installnbdt 安装)。下面对猫的图片进行推断。
nbdthttps://images.pexels.com/photos/126407/pexels-photo-126407.jpeg?auto=compress&cs=tinysrgb&dpr=2&w=32 # this can also be a path to local image
这将输出类别预测和所有中间决策。
Prediction: cat // Decisions: animal (99.47%), chordate(99.20%), carnivore (99.42%), cat (99.86%)
也可以只用几行 Python 代码加载预训练的 NBDT。使用以下内容开始,支持几种神经网络和数据集。
from nbdt.model import HardNBDTfrom nbdt.models importwrn28_10_cifar10model = wrn28_10_cifar10()model = HardNBDT( pretrained=True, dataset='CIFAR10', arch='wrn28_10_cifar10', modelmodel=model)
作为参考,请参见上面运行的命令行工具的脚本。仅约 20 行就能进行转换输入和运行推理。
运作原理
神经支持决策树的训练和推理过程可以分为四个步骤。
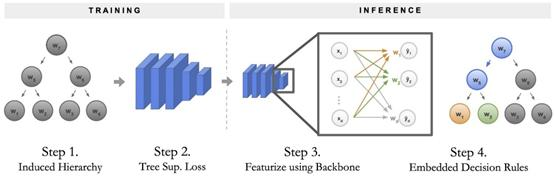
训练 NBDT 分为两个阶段:首先,构建决策树的层次结构。其次,训练带有特殊损失项的神经网络。要进行推理,请将样本输入神经网络主干。最后,将最后一个完全连接的层作为决策规则序列运行。
- 构建决策树的层次结构。此层次结构确定了 NBDT 必须在哪些类之间进行决策。将此层次结构称为归纳层次结构。
- 此层次结构产生一个特定的损失函数,称为树监督损失 5。使用此新损失函数训练原始神经网络,无需任何修改。
- 通过使样本输入神经网络主干来开始推理。主干是最终完全连接层之前的所有神经网络层。
- 通过将最终的全连接层作为决策规则序列,称为嵌入式决策规则来完成推理。这些决策形成最终的预测。
可解释性 AI 不能完全解释神经网络如何实现预测:现有方法可以解释图像对模型预测的影响,但不能解释决策过程。决策树解决了这个问题,但其准确性还存在个挑战。
因此,将神经网络和决策树结合在一起。与采用相同混合设计的前代产品不同,神经支持决策树(NBDT)同时解决了以下问题:
- 神经网络无法提供理由;
- 决策树无法达到较高的准确性。
这为医学和金融等应用提供了一种新的准确、可解释的 NBDT。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java