
弹幕避开人脸,人脸识别 AI 跟随弹幕技术详解。
在 AI 算法的加持下,弹幕的呈现形式也花样翻新。优酷的很多剧都上线了基于 AI 人脸识别的跟随弹幕,与剧情更贴合,可玩性也更高。这类弹幕是如何实现的?有哪些核心技术?
1、技术面临的问题:识别放到端侧还是云端?
一是识别剧中人物,人像识别本身已经有成熟的算法,既可以放到端侧,也可以放到云端,那么应该把识别能力放在哪?核心的识别能力如果放到客户端上,识别的功耗和性能开销是很大的。如果是针对某些垂类场景,仅需在短时间内识别,放在客户端完全没有问题;但如果是长视频,从头到尾都有一个客户端的识别引擎在跑,端侧设备的性能、耗电就难以接受了。
二是客户端识别的精准度,因为算法识别直接输出结果,很难达到产品化的要求。在这一过程中,还要对识别结果进行二次加工和处理,包括平滑处理、降噪。这些处理都需要更多的工作时长,如果都放到客户端,难以保证实时性。所以我们将整个识别引擎都放到云端,通过云端识别输出数据,经过优化处理再将这些数据打包下发到端侧,实现投放和互动。
2、算法和工程如何对接?
工程和算法如何对接、工程如何解决算法输出后的各类问题?包括识别精度、数据抖动、视频文件变更之后导致的数据不一致的问题;另外,端侧要解决核心的体验问题。在播放过程中,镜头频繁切换时,这些人像在镜头中变化的问题,手机界面横竖屏的适应;还有气泡样式的弹幕,在不同剧中和内容的氛围如何融合等。
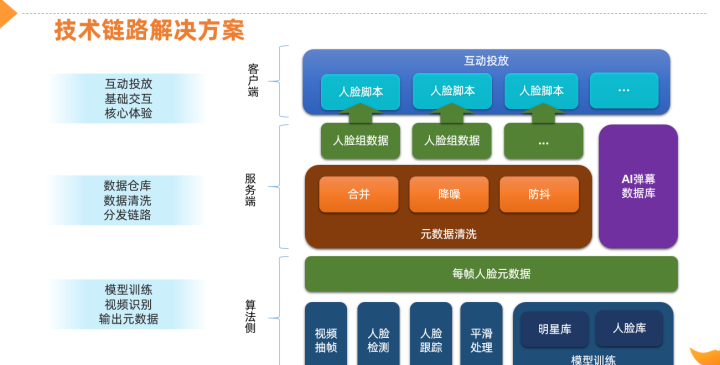
上图是我们的技术链路,由下到上,依次是算法层、服务端、客户端。在算法层,我们通过模型训练进行抽帧,对每一帧的画面进行识别,通过人脸检测和跟踪来抓取每一帧的人脸数据,再传输到服务端进行预加工,包括数据合并和降噪,最后将人脸数据打包,通过互动投放引擎投放到端侧,实现核心交互和基础体验。
3. 算法侧具体的技术细节如下:

1)视频抽帧与识别
抽帧现在按每秒 25 帧来抽取,这也是一个视频的基础帧率,对于高帧率的视频当然可以抽更多,但这与机器开销和耗时是成正比的。另外在算法侧,人脸的识别引擎有几部分,一是标准的人脸识别,能够识别大多数人脸的场景;二是优酷还针对明星和人物角色做了单独优化,我们会抽取一些剧中的明星和角色数据,作为数据集去训练,提升剧中主角和明星的识别率。
2)人脸跟踪
算法会识别出视频中每一帧的人脸和对应坐标,坐标用来标注人脸对应的位置,每个人脸帧也对应有人脸的特征值,相同特征值能够识别为同一个人。这样通过坐标和特征值,我们就能识别出一个镜头从入场到出场的序列帧里同一个人的人脸运动轨迹。
3)平滑处理,防抖动
我们知道算法是基于单帧对人脸做识别的,人脸的位置和大小的识别结果是有像素级的误差的,同一个人脸哪怕运动很轻微,上一帧和下一帧的识别结果的方框是不会严丝合缝对齐的。这样把连续的每一帧的识别结果像放动画片一样串起来,这种像方框一样的识别结果在播放场景中就会看到明显的抖动。
我们在工程侧对抖动做了检测和计算,将抖动限定在一个范围之内,让整个人脸的轨迹更平滑。

视频2

视频3
视频 2 是算法直接输出的人脸轨迹的识别结果,大家可以看到人脸的识别结果是伴随人物运动在抖动的,既有位置的抖动,也有大小的抖动。视频 3 是经过平滑处理后的结果,人物在整个镜头中走动,我们的识别结果输出是稳定平滑的,抖动效果已经被平滑消除掉。
4. 服务端对算法层输出的人脸原数据要做一系列的处理:
技术详解:基于人脸识别的AI弹幕
1)降噪,过滤掉镜头中不重要的人脸杂音。所谓不重要,是因为镜头中有大量的路人镜头,很多是一闪而过的,这些镜头的人脸对于用户交互来说不具备太大价值。所以我们要把路人、一晃而过的镜头中的人脸都过滤掉;
2)防抖。我们会对原数据进行平滑处理;
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java