
深入浅出理解 Spark 部署与工作原理
一、Spark 概述
Spark 是 UC Berkeley AMP Lab 开源的通用分布式并行计算框架,目前已成为 Apache 软件基金会的顶级开源项目。Spark 支持多种编程语言,包括 Java、Python、R 和 Scala,同时 Spark 也支持 Hadoop 的底层存储系统 HDFS,但 Spark 不依赖 Hadoop。
1.1 Spark 与 Hadoop
Spark 基于 Hadoop MapReduce 算法实现的分布式计算,拥有 Hadoop MapReduce 所具有的优点,并且具有更高的运算速度。Spark 能够比 Hadoop 运算更快,主要原因是:Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁盘中,第二次 MapReduce 运算时在从磁盘中读取数据,两次对磁盘的操作,增加了多余的 IO 消耗;而 Spark 则是将数据一直缓存在内存中,运算时直接从内存读取数据,只有在必要时,才将部分数据写入到磁盘中。除此之外,Spark 使用最先进的 DAG(Directed Acyclic Graph,有向无环图)调度程序、查询优化器和物理执行引擎,在处理批量处理以及处理流数据时具有较高的性能。按照Spark 官网的说法,Spark 相对于 Hadoop 而言,Spark 能够达到 100 倍以上的运行负载。

(图片来源:Apache Spark™)
1.2 Spark 架构及生态
Spark
除了 Spark Core 外,还有其它由多个组件组成,目前主要有四个组件:Spark SQL、Spark
Streaming、MLlib、GraphX。这四个组件加上 Spark Core 组成了 Spark 的生态。通常,我们在编写一个 Spark
应用程序,需要用到 Spark
Core 和其余 4 个组件中的至少一个。Spark 的整体构架图如下图所示:
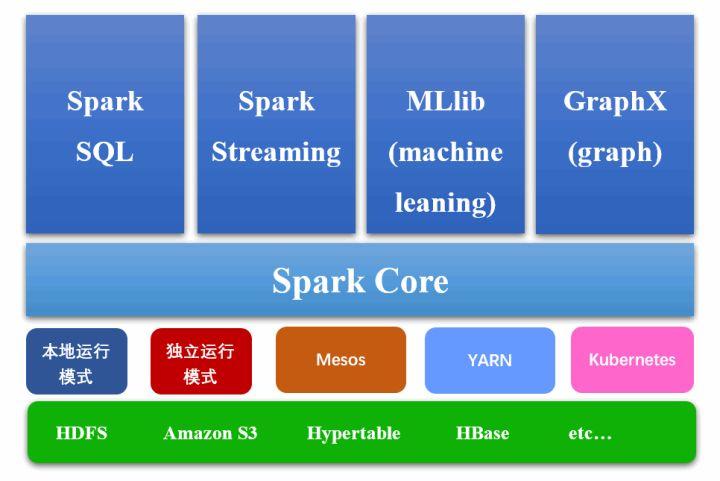
Spark Core:是 Spark 的核心,主要负责任务调度等管理功能。Spark
Core 的实现依赖于 RDDs(Resilient Distributed Datasets,
弹性分布式数据集)的程序抽象概念。
Spark SQL:是 Spark 处理结构化数据的模块,该模块旨在将熟悉的 SQL 数据库查询与更复杂的基于算法的分析相结合,Spark
SQL 支持开源 Hive 项目及其类似 SQL 的 HiveQL 查询语法。Spark
SQL 还支持 JDBC 和 ODBC 连接,能够直接连接现有的数据库。
Spark Streaming:这个模块主要是对流数据的处理,支持流数据的可伸缩和容错处理,可以与 Flume(针对数据日志进行优化的一个系统)和 Kafka(针对分布式消息传递进行优化的流处理平台)等已建立的数据源集成。Spark Streaming 的实现,也使用 RDD 抽象的概念,使得在为流数据(如批量历史日志数据)编写应用程序时,能够更灵活,也更容易实现。
MLlib:主要用于机器学习领域,它实现了一系列常用的机器学习和统计算法,如分类、回归、聚类、主成分分析等算法。
GraphX:这个模块主要支持数据图的分析和计算,并支持图形处理的 Pregel API 版本。GraphX 包含了许多被广泛理解的图形算法,如 PageRank。
1.3 Spark 运行模式
Spark 有多种运行模式,由图 2 中,可以看到 Spark 支持本地运行模式(Local 模式)、独立运行模式(Standalone 模式)、Mesos、YARN(Yet Another Resource Negotiator)、Kubernetes 模式等。
本地运行模式是 Spark 中最简单的一种模式,也可称作伪分布式模式。
独立运行模式为 Spark 自带的一种集群管理模式,Mesos 及 YARN 两种模式也是比较常用的集群管理模式。相比较 Mesos 及 YARN 两种模式而言,独立运行模式是最简单,也最容易部署的一种集群运行模式。
Kubernetes 是一个用于自动化部署、扩展和管理容器化应用程序的开源系统。
Spark 底层还支持多种数据源,能够从其它文件系统读取数据,如 HDFS、Amazon S3、Hypertable、HBase 等。Spark 对这些文件系统的支持,同时也丰富了整个 Spark 生态的运行环境。
二、Spark 部署模式
Spark 支持多种分布式部署模式,主要支持三种部署模式,分别是:Standalone、Spark on YARN和 Spark on Mesos模式。
Standalone模式为 Spark 自带的一种集群管理模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。它是 Spark 实现的资源调度框架,其主要的节点有 Driver 节点、Master 节点和 Worker 节点。Standalone模式也是最简单最容易部署的一种模式。
Spark on YARN模式,即 Spark 运行在Hadoop YARN框架之上的一种模式。Hadoop YARN(Yet Another Resource
Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
Spark on Mesos模式,即 Spark 运行在Apache Mesos框架之上的一种模式。Apache Mesos是一个更强大的分布式资源管理框架,负责集群资源的分配,它允许多种不同的框架部署在其上,包括YARN。它被称为是分布式系统的内核。
三种架构都采用了Master/Worker(Slave)的架构,Spark 分布式运行架构大致如下:

本文主要介绍 Spark 的Standalone模式的部署。
三、环境准备
出于学习的目的,本文将 Spark 部署在安装有 CentOS7 系统的 VirtualBox 虚拟机中。
搭建 Spark 集群,需要准备以下文件及环境:
jdk-8u211-linux-x64.tar.gz
spark-2.4.3-bin-hadoop2.7.tgz
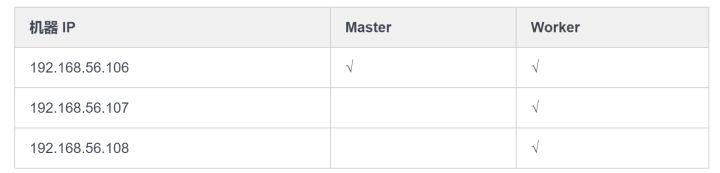
3 个独立的 CentOS7 虚拟机系统,机器集群规划如下:
四、安装
4.1. 配置 jdk 环境
解压文件:
tar -zxf jdk-8u211-linux-x64.tar.gz配置环境变量:
export JAVA_HOME=/path/to/jdk1.8.0_211
export PATH=\$PATH:\$JAVA_HOME/bin4.2. 配置 Spark 环境
解压文件:
tar -xf **park-2.4.3-bin-hadoop2.7.tgz**配置环境变量:
export SPARK_HOME=/path/to/spark-2.4.3-bin-hadoop2.7
export PATH=\$PATH:\$SPARK_HOME/bin修改spark-env.sh 文件
cd spark-2.4.3-bin-hadoop2.7
cp conf/spark-env.sh.template conf/spark-env.sh
vim conf/spark-env.sh
\# 增加如下内容:
export JAVA_HOME=/path/to/jdk1.8.0_211
export SPARK_MASTER_HOST=192.168.56.106修改slaves文件
cp conf/slaves.template conf/slaves
vim conf/slaves
# 增加如下内容:
192.168.56.106
192.168.56.107
192.168.56.1084.3. 配置 ssh 免密登录
配置 ssh 免密登录,是为了能够在master机器上来启动所有worker节点,如果不配置免密登录,则在启动每个worker时,都需要输入一遍密码,会很麻烦。当然,如果机器少的话,也可以登录到worker节点上,手动一个一个启动worker。
执行:ssh-keygen -t rsa,一直按回车即可。最后会生成类似这样的日志:
并且在用户目录下会自动生成.ssh目录执行ls ~/.ssh可以看到两个文件:
id_rsa生成的私钥文件
id_rsa.pub生成的公钥文件
将id_rsa.pub复制到其它机器上,执行以下几条命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub royran@192.168.56.106: # master所在的主机,如果master不做woker可以不需要。
ssh-copy-id -i ~/.ssh/id_rsa.pub royran@192.168.56.107:
ssh-copy-id -i ~/.ssh/id_rsa.pub royran@192.168.56.108:4.4 配置其它 worker 节点
当前已在master节点配置好了环境,还需要在其它worker节点上配置相类似的环境。
配置其它worker节点很简单,只需要将jdk1.8.0_211及spark-2.4.3-bin-hadoop2.7两个目录复制到其它worker节点机器上即可。但要注意,这两个目录在其它 worker 上的绝对路径需要与 master 上的绝对路径一致,不然无法直接在 master 上启动其它 worker 节点。
依次执行以下命令(如果已经配置好 ssh 免密,可以发现执行 scp 指令不需要两次输入密码):
scp -r /path/to/jdk1.8.0_211username@192.168.56.107:/path/to/jdk1.8.0_211
scp -r /path/to/jdk1.8.0_211username@192.168.56.108:/path/to/jdk1.8.0_211
scp -r /path/to/spark-2.4.3-bin-hadoop2.7username@192.168.56.107:/path/to/spark-2.4.3-bin-hadoop2.7
scp -r /path/to/spark-2.4.3-bin-hadoop2.7username@192.168.56.108:/path/to/spark-2.4.3-bin-hadoop2.74.5 启动master
执行:
sbin/start-master.sh输入jps指令(该指令在
不能识别此Latex公式: JAVA_HOME/bin 目录下)可以查看 java 进程名,如输入jps后,会显示这样的信息:

看到有Master字样,说明master进程启动成功了,启动master后,spark 默认会监听8080端口,并可以通过浏览器打开 web 界面,在地址栏输入http://192.168.56.106:8080,查看集群状态。如下图所示:
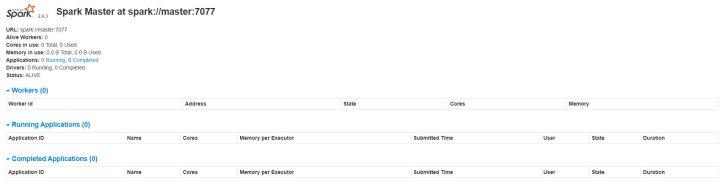
当前只启动了master,所以看不到任何worker信息。
4.6 启动 worker 节点
执行:
sbin/slaves.sh会看到类似这样的输出:
再输入jps,会列出当前启动的java进程,显示Worker字样,说明worker进程启动成功了。

此时再刷新下打开的浏览器界面(http://192.168.56.106:8080),可以看到当前启动了三个Worker节点。
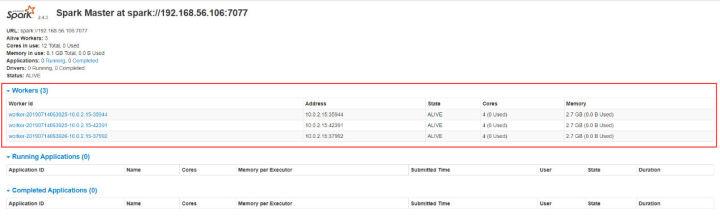
也许你会发现界面上显示的 Address 列,怎么是 10 开头的 ip 地址,并且都是一样的,而不是 192 开头的三个不同的 ip 地址。

这是因为虚拟机内有两块虚拟网卡,Spark 会读取环境变量SPARK_LOCAL_IP,如果没设置这个变量,Spark 就会使用getHostByName来获取 ip 地址,会得到10.0.2.15这个 ip 地址。

要解决这个问题,有两种方法:
(1) 将仅主机(Host-Only)网络设置为网卡 1,将网络地址转换(NAT)设置为网卡 2。不过如果使用这种方法,重启虚拟机后,如果是动态 ip,则 ip 地址会变化,会影响之前的配置。
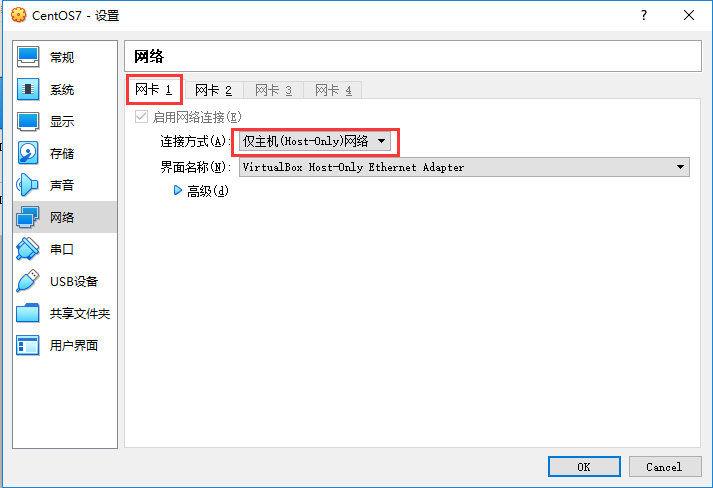

(2) 另一种方法,可在conf/spark-env.sh中设置SPARK_LOCAL_IP这个变量,可以固定为一个 ip 地址,
vim conf/spark-env.sh
# 添加一行:
export SPARK_LOCAL_IP=192.168.56.106在其他机器上同样需要手动添加这一行,不过要修改为对应的机器 ip。觉得这样有点麻烦。可以通过脚本动态获取本机 ip 地址,在conf/spark-env.sh中添加这两行:
SPARK_LOCAL_IP=`python -c "import socket;import fcntl;import struct;print([(socket.inet_ntoa(fcntl.ioctl(s.fileno(),0x8915,struct.pack('256s', 'enp0s8'))[20:24]), s.close()) for s in [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][0])"`
export SPARK_LOCAL_IP这样就可以自动获取本机的enp0s8这块网卡的 ip 地址。
最后将修改后的conf/spark-env.sh这个文件复制到其它机器上:
执行:
scp conf/spark-env.sh username@192.168.56.107:/path/to/spark-2.4.3-bin-hadoop2.7/conf/spark-env.sh
scp conf/spark-env.sh username@192.168.56.108:/path/to/spark-2.4.3-bin-hadoop2.7/conf/spark-env.sh重新启动所有节点:
sbin/stop-all.sh
sbin/start-all.sh最后刷新浏览器界面,可以看到有 3 个Woker启动了,并且在 Address 列也可以看到都变为 192 开头的 ip 地址了。

五、测试
在{SPARK_HOME}/examples/src/main目录下,有一些 spark 自带的示例程序,有 java、python、r、scala 四种语言版本的程序。这里主要测试 python 版的计算PI的程序。
cd \${SPARK_HOME}/examples/src/main/python将pi.py程序提交到 spark 集群,执行:
spark-submit --master spark://192.168.56.106:7077 pi.py
最后可以看到输出这样的日志:
刷新浏览器界面,在Completed Applications栏可以看到一条记录,即刚才执行的计算PI的 python 程序。

另外,如果觉得在终端中输出的日志太多,可以修改日志级别:
cp ${SPARK_HOME}/conf/log4j.properties.template ${SPARK_HOME}/conf/log4j.properties
vim ${SPARK_HOME}/conf/log4j.properties修改日志级别为WARN:

再重新执行:spark-submit --master spark://192.168.56.106:7077 pi.py,可以看到输出日志少了很多。

除了提交 python 程序外,spark-submit 还可以提交打包好的java、scala程序,可以执行spark-submit --help看具体用法。
Spark 配置文件说明
在下载下来的spark-2.4.3-bin-hadoop2.7.tgz中,conf 目录下会默认存在这几个文件,均为 Spark 的配置示例模板文件:

这些模板文件,均不会被 Spark 读取,需要将.template后缀去除,Spark 才会读取这些文件。这些配置文件中,在 Spark 集群中主要需要关注的是log4j.properties、slaves、spark-defaults.conf、spark-env.sh这四个配置文件。
log4j.properties的配置,可以参考Apache Log4j官网上的 Propertities 属性配置说明。
slaves的配置,里面为集群的所有worker节点的主机信息,可以为主机名,也可以为 ip 地址。
spark-defaults.conf的配置,可以参考Spark 官网的属性配置页。比如指定 master 节点地址,可以设置spark.master属性;指定 executor 的运行时的核数,可以设置spark.executor.cores属性等。
spark-env.sh是 Spark 运行时,会读取的一些环境变量,在本文中,主要设置了三个环境变量:JAVA_HOME、SPARK_HOME、SPARK_LOCAL_IP,这是 Spark 集群搭建过程中主要需要设置的环境变量。其它未设置的环境变量,Spark 均采用默认值。其它环境变量的配置说明,可以参考Spark 官网的环境变量配置页。
至此,Spark 集群的Standalone模式部署全部结束。
对于 Spark 的学习,目前我掌握还比较浅,还在学习过程中。如果文章中有描述不准确,或不清楚的地方,希望给予指正,我会及时修改。谢谢!
关于 Spark 的学习,可以根据 Spark 官网上的指导快速入门:
https://spark.apache.org/docs/latest/quick-start.html
六、 Spark 中的计算模型
6.1 Spark 中的几个主要基本概念
在 Spark 中,有几个基本概念是需要先了解的,了解这些基本概念,对于后续在学习和使用 Spark 过程中,能更容易理解一些。
Application:基于 Spark 的用户程序,即由用户编写的调用 Spark API 的应用程序,它由集群上的一个驱动(Driver)程序和多个执行器(Executor)程序组成。其中应用程序的入口为用户所定义的 main 方法。
SparkContext:是 Spark 所有功能的主要入口点,它是用户逻辑与 Spark 集群主要的交互接口。通过SparkContext,可以连接到集群管理器(Cluster Manager),能够直接与集群 Master 节点进行交互,并能够向 Master 节点申请计算资源,也能够将应用程序用到的 JAR 包或 Python 文件发送到多个执行器(Executor)节点上。
Cluster Manager:即集群管理器,它存在于 Master 进程中,主要用来对应用程序申请的资源进行管理。
Worker Node:任何能够在集群中能够运行 Spark 应用程序的节点。
Task:由SparkContext发送到Executor节点上执行的一个工作单元。
Driver:也即驱动器节点,它是一个运行Application中main()函数并创建SparkContext的进程。Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调 Task 的调度。Driver节点可以不运行于集群节点机器上。
Executor:也即执行器节点,它是在一个在工作节点(Worker Node)上为Application启动的进程,它能够运行 Task 并将数据保存在内存或磁盘存储中,也能够将结果数据返回给Driver。
根据以上术语的描述,通过下图可以大致看到 Spark 程序在运行时的内部协调过程:
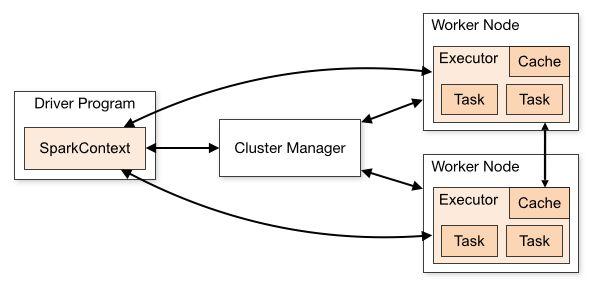
(图片来源:Cluster Mode Overview)
除了以上几个基本概念外,Spark 中还有几个比较重要的概念。
6.2 RDD
6.2.1 基本概念
即弹性分布式数据集(Resilient Distributed Datasets),是一种容错的、可以被并行操作的元素集合,它是 Spark 中最重要的一个概念,是 Spark 对所有数据处理的一种基本抽象。Spark 中的计算过程可以简单抽象为对 RDD 的创建、转换和返回操作结果的过程:

对于 Spark 的 RDD 计算抽象过程描述如下:
makeRDD:可以通过访问外部物理存储(如 HDFS),通过调用 SparkContext.textFile()方法来读取文件并创建一个 RDD,也可以对输入数据集合通过调用 SparkContext.parallelize()方法来创建一个 RDD。RDD 被创建后不可被改变,只可以对 RDD 执行 Transformation 及 Action 操作。
Transformation(转换):对已有的 RDD 中的数据执行计算进行转换,并产生新的 RDD,在这个过程中有时会产生中间 RDD。Spark 对于Transformation采用惰性计算机制,即在 Transformation 过程并不会立即计算结果,而是在 Action 才会执行计算过程。如map、filter、groupByKey、cache等方法,只执行Transformation操作,而不计算结果。
Action(执行):对已有的 RDD 中的数据执行计算产生结果,将结果返回 Driver 程序或写入到外部物理存储(如 HDFS)。如reduce、collect、count、saveAsTextFile等方法,会对 RDD 中的数据执行计算。
6.2.2 RDD 依赖关系
Spark 中 RDD 的每一次Transformation都会生成一个新的 RDD,这样 RDD 之间就会形成类似于流水线一样的前后依赖关系,在 Spark 中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖:
窄依赖(NarrowDependency):每个父 RDD 的一个分区最多被子 RDD 的一个分区所使用,即 RDD 之间是一对一的关系。窄依赖的情况下,如果下一个 RDD 执行时,某个分区执行失败(数据丢失),只需要重新执行父 RDD 的对应分区即可进行数恢复。例如map、filter、union等算子都会产生窄依赖。
宽依赖(WideDependency,或 ShuffleDependency):是指一个父 RDD 的分区会被子 RDD 的多个分区所使用,即 RDD 之间是一对多的关系。当遇到宽依赖操作时,数据会产生Shuffle,所以也称之为ShuffleDependency。宽依赖情况下,如果下一个 RDD 执行时,某个分区执行失败(数据丢失),则需要将父 RDD 的所有分区全部重新执行才能进行数据恢复。例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖。
RDD 依赖关系如下图所示:
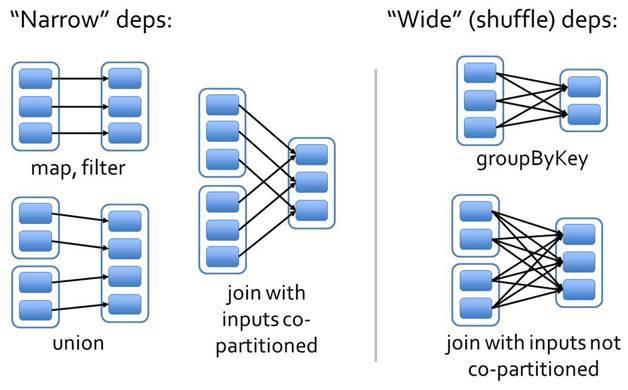
6.3 Partition
6.3.1 基本概念
partition(分区)是 Spark 中的重要概念,它是RDD的最小单元,RDD是由分布在各个节点上的partition 组成的。partition的数量决定了task的数量,每个task对应着一个partition。
例如,使用 Spark 来读取本地文本文件内容,读取完后,这些内容将会被分成多个partition,这些partition就组成了一个RDD,同时这些partition可以分散到不同的机器上执行。RDD 的 partition 描述如下图所示:
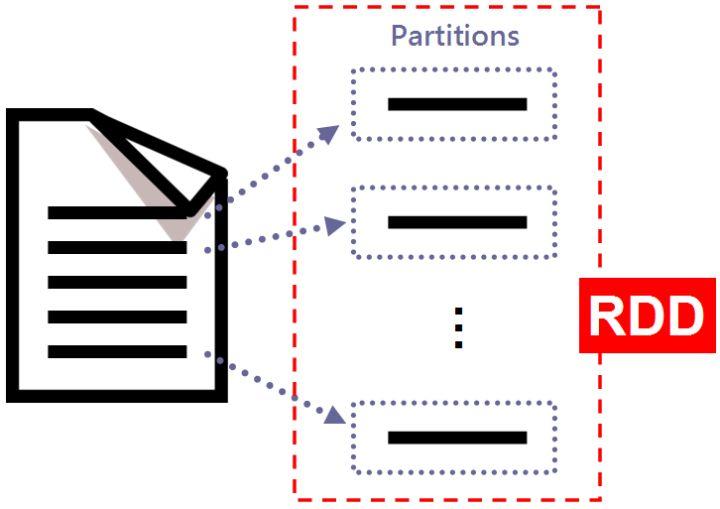
(图片来源:Spark簡易操作)
partition的数量可以在创建 RDD 时指定,如果未指定 RDD 的 partition 大小,则在创建 RDD 时,Spark 将使用默认值,默认值为spark.default.parallelism配置的参数。
6.3.2 Partition 数量影响及调整
Partition 数量的影响:
如果 partition 数量太少,则直接影响是计算资源不能被充分利用。例如分配 8 个核,但 partition 数量为 4,则将有一半的核没有利用到。
如果 partition 数量太多,计算资源能够充分利用,但会导致 task 数量过多,而 task 数量过多会影响执行效率,主要是 task 在序列化和网络传输过程带来较大的时间开销。
根据Spark RDD Programming Guide上的建议,集群节点的每个核分配 2-4 个partitions比较合理。

Partition 调整:
Spark 中主要有两种调整 partition 的方法:coalesce、repartition
参考 pyspark 中的函数定义:
def coalesce(self, numPartitions, shuffle=False):
"""
Return a new RDD that is reduced into \`numPartitions\` partitions.
"""
def repartition(self, numPartitions):
"""
*Return a new RDD that has exactly numPartitions partitions.*
*Can increase or decrease the level of parallelism in this RDD.*
*Internally, this uses a shuffle to redistribute data.*
*If you are decreasing the number of partitions in this RDD, consider*
*using \`coalesce\`, which can avoid performing a shuffle.*
*"""
return self.coalesce(numPartitions, shuffle=True)从函数接口可以看到,reparation是直接调用coalesce(numPartitions, shuffle=True),不同的是,reparation函数可以增加或减少 partition 数量,调用repartition函数时,还会产生shuffle操作。而coalesce函数可以控制是否shuffle,但当shuffle为False时,只能减小partition数,而无法增大。
6.4 Job
前面提到,RDD 支持两种类型的算子操作:Transformation和Action。Spark 采用惰性机制,Transformation算子的代码不会被立即执行,只有当遇到第一个Action算子时,会生成一个Job,并执行前面的一系列Transformation操作。一个Job包含N个Transformation和 1 个Action。
而每个Job会分解成一系列可并行处理的Task,然后将Task分发到不同的Executor上运行,这也是 Spark 分布式执行的简要流程。
6.5 Stage
Spark 在对Job中的所有操作划分Stage时,一般会按照倒序进行,依据 RDD 之间的依赖关系(宽依赖或窄依赖)进行划分。即从Action开始,当遇到窄依赖类型的操作时,则划分到同一个执行阶段;遇到宽依赖操作,则划分一个新的执行阶段,且新的阶段为之前阶段的Parent,之前的阶段称作Child Stage,然后依次类推递归执行。Child Stage需要等待所有的Parent Stage执行完之后才可以执行,这时Stage之间根据依赖关系构成了一个大粒度的 DAG。
如下图所示,为一个复杂的 DAG Stage 划分示意图:

(图片来源:Job物理执行图)
上图为一个 Job,该 Job 生成的 DAG 划分成了 3 个 Stage。上图的 Stage 划分过程是这样的:从最后的Action开始,从后往前推,当遇到操作为NarrowDependency时,则将该操作划分为同一个Stage,当遇到操作为ShuffleDependency时,则将该操作划分为新的一个Stage。
6.6 Task
Task为一个Stage中的一个执行单元,也是 Spark 中的最小执行单元,一般来说,一个 RDD 有多少个Partition,就会有多少个Task,因为每一个Task 只是处理一个Partition上的数据。在一个Stage内,所有的 RDD 操作以串行的 Pipeline 方式,由一组并发的Task完成计算,这些Task的执行逻辑完全相同,只是作用于不同的Partition。每个Stage里面Task的数目由该Stage最后一个 RDD 的Partition 个数决定。
Spark 中Task分为两种类型,ShuffleMapTask 和 ResultTask,位于最后一个 Stage 的 Task 为 ResultTask,其他阶段的属于 ShuffleMapTask。ShuffleMapTask 和 ResultTask 分别类似于 Hadoop 中的 Map 和 Reduce。
七、Spark 调度原理
7.1 Spark 集群整体运行架构

(图片来源:SparkInternals-Overview)
Spark 集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 Executors。
Driver 为用户编写的 Spark 应用程序所运行的进程。Driver 程序可以运行在 Master 节点上,也可运行在 Worker 节点上,还可运行在非 Spark 集群的节点上。
7.2 Spark 调度器
Spark 中主要有两种调度器:DAGScheduler 和 TaskScheduler,DAGScheduler 主要是把一个 Job 根据 RDD 间的依赖关系,划分为多个 Stage,对于划分后的每个 Stage 都抽象为一个由多个 Task 组成的任务集(TaskSet),并交给 TaskScheduler 来进行进一步的任务调度。TaskScheduler 负责对每个具体的 Task 进行调度。
7.2.1 DAGScheduler
当创建一个 RDD 时,每个 RDD 中包含一个或多个分区,当执行 Action 操作时,相应的产生一个 Job,而一个 Job 会根据 RDD 间的依赖关系分解为多个 Stage,每个 Stage 由多个 Task 组成(即 TaskSet),每个 Task 处理 RDD 中的一个 Partition。一个 Stage 里面所有分区的任务集合被包装为一个 TaskSet 交给 TaskScheduler 来进行任务调度。这个过程由是由 DAGScheduler 来完成的。DAGScheduler 对 RDD 的调度过程如下图所示:

(图片来源:Core Services behind Spark Job Execution)
7.2.2 TaskScheduler
DAGScheduler 将一个 TaskSet 交给 TaskScheduler 后,TaskScheduler 会为每个 TaskSet 进行任务调度,Spark 中的任务调度分为两种:FIFO(先进先出)调度和 FAIR(公平调度)调度。
FIFO 调度:即谁先提交谁先执行,后面的任务需要等待前面的任务执行。这是 Spark 的默认的调度模式。
FAIR 调度:支持将作业分组到池中,并为每个池设置不同的调度权重,任务可以按照权重来决定执行顺序。
在 Spark 中使用哪种调度器可通过配置spark.scheduler.mode参数来设置,可选的参数有 FAIR 和 FIFO,默认是 FIFO。
FIFO 调度算法为 FIFOSchedulingAlgorithm,该算法的 comparator 方法的 Scala 源代码如下:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java