
hash算法的扩展应用:SimHash、GeoHash、布隆过滤器。
1 SimHash
simHash是google用于海量文本去重的一种方法,它是一种局部敏感hash。那什么叫局部敏感呢,假定两个字符串具有一定的相似性,在hash之后,仍然能保持这种相似性,就称之为局部敏感hash。普通的hash是不具有这种属性的。simhash被Google用来在海量文本中去重。
simHash算法的思路大致如下:
将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的多个(feature, weight)。记为 feature_weight_pairs = [fw1, fw2 … fwn],其中 fwn = (feature_n,weight_n)。
对每个feature_weight_pairs中的feature进行hash。然后对hash_weight_pairs进行位的纵向累加,如果该位是1,则+weight,如果是0,则-weight,最后生成bits_count个数字,大于0标记1,小于0标记0
最后转换成一个64位的字节,判断重复只需要判断他们的特征字的距离是不是<n (n根据经验一般取3),就可以判断两个文档是否相似。

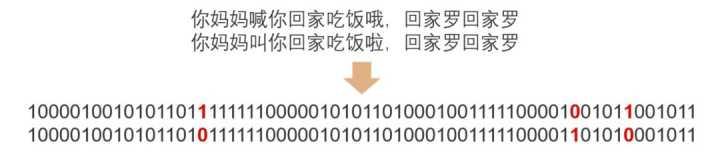
如下图所示,当两个文本只有一个字变化时,如果使用普通Hash则会导致两次的结果发生较大改变,而SimHash的局部敏感特性,会导致只有部分数据发生变化。
2 GeoHash
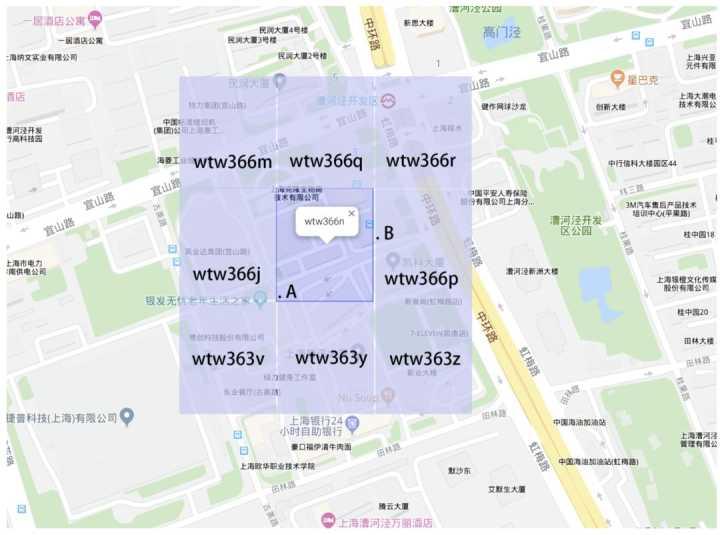
GeoHash将地球作为为一个二维平面进行递归分解。每个分解后的子块在一定经纬度范围内拥有相同的编码。以下图为例,这个矩形区域内所有的点(经纬度坐标)都共享相同的GeoHash字符串,这样既可以保护隐私(只表示大概区域位置而不是具体的点),又比较容易做缓存。
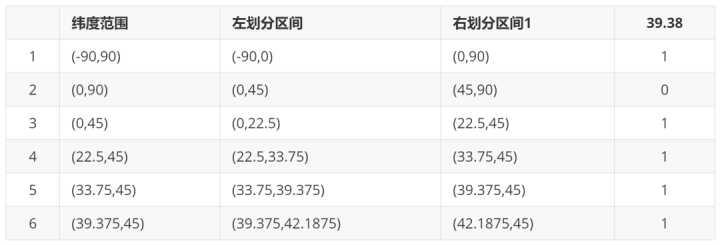
下面以一个例子来理解下这个算法,我们对纬度39.3817进行逼近编码 :
地球纬度区间是[-90,90],对于这个区间进行二分划分左区间[-90,0), 右区间[0,90]。39.3817属于右区间,标记为1
将右区间[0,90]继续进行划分,左区间[0,45) ,右区间[45,90]。39.3817属于左区间,标记为0
递归上面的过程,随着每次迭代,区间[a,b]会不断接近39.3817。递归的次数决定了生成的序列长度。
对于经度做同样的处理。得到的字符串,偶数位放经度,奇数位放纬度,把2串编码组合生成新串。对于新串转成对应10进制查出实际的base32编码就是类似WX4ER的hash值。
整体递归过程如下表所示:
3 布隆过滤器
布隆过滤器被广泛用于黑名单过滤、垃圾邮件过滤、爬虫判重系统以及缓存穿透问题。对于数量小,内存足够大的情况,我们可以直接用hashMap或者hashSet就可以满足这个活动需求了。但是如果数据量非常大,比如5TB的硬盘上放满了用户的参与数据,需要一个算法对这些数据进行去重,取得活动的去重参与用户数。这种时候,布隆过滤器就是一种比较好的解决方案了。
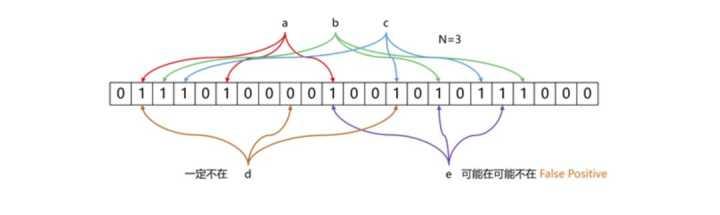
布隆过滤器其实是基于bitmap的一种应用,在1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难,主要用于大数据去重、垃圾邮件过滤和爬虫url记录中。核心思路是使用一个bit来存储多个元素,通过这样的方式来减少内存的消耗。通过多个hash函数,将每个数据都算出多个值,存放在bitmap中对应的位置上。
布隆过滤器的原理见下图所示:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java