
ActiveMQ 和 Kafka 在 OpenShift 上的实现分布式消息和数据流平台
前言
随着容器和 Kubernetes 的兴起,微服务逐渐受到很多企业客户的关注。与此同时,微服务之间的通信也成为了企业必要考虑的问题。本文将着重分析 ActiveMQ 和 Kafka 这两款优秀的消息中间件的架构以及在 OpenShift 上的实现。在正式介绍之前,我们先简单介绍服务之间的通信机制。
服务之间的通信
通信方式的划分
服务之间的通信遵循 IPC 标准(Inter-Process Communication,进程间通信)。它们之间的通信方式,可以按照以下两个维度进行分析:
同步通信或异步通信
一对一通信或一对多通信
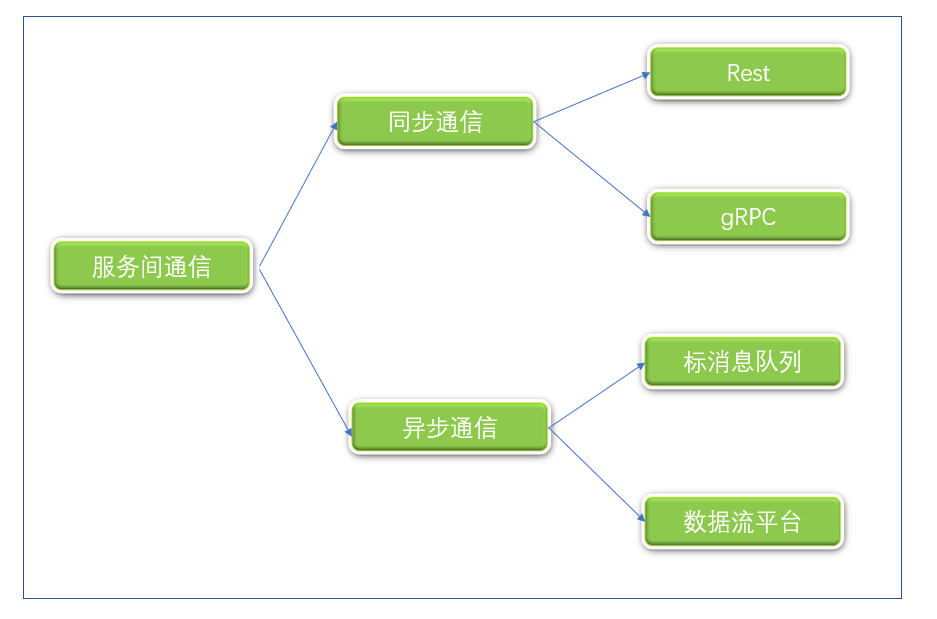
服务之间同步通信,可以采取基于 gRPC 的方式或 http 的 Rest 方式,如下图 1 所示。在 Rest 方式中,调用 http 的方法进行同步访问,如:GET、POST、PUT、DELETE。
服务之间异步通信,需要借助于标准消息队列或数据流平台。
图 1. 服务之间通信
从同步或异步方式分析了服务之间的通信方式后,我们从另外一个维度来看服务间的通信,即一对一或一对多,如下图 2 所示:
图 2. 服务之间通信
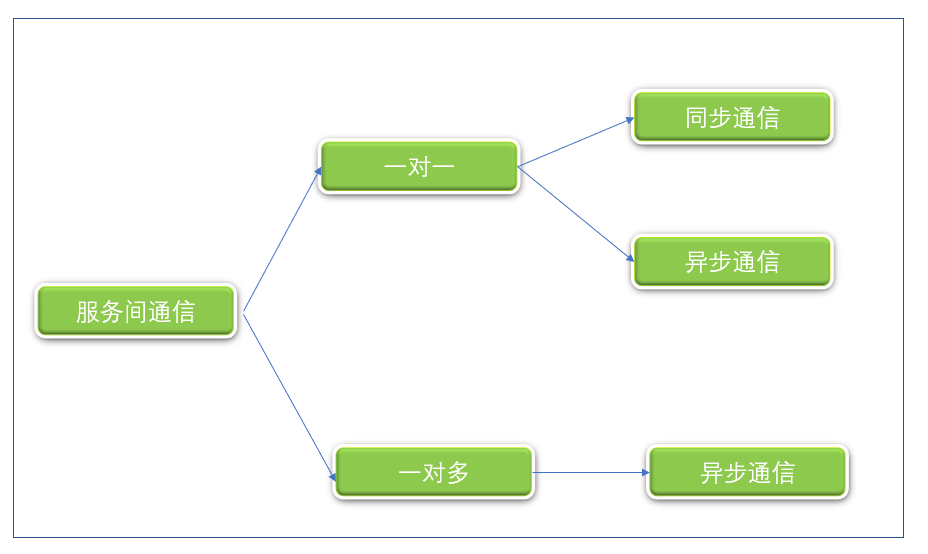
程序之间一对一通信的情况下,有同步和异步两种通信方式:
同步通信时:一个客户端向服务器端发起请求,等待响应,这也是阻塞模式。可通过上文提到的 Rest 或 gRPC 方式实现。
异步通信:客户端请求发送到服务端,但是并不强制需要服务端立即响应,服务端对请求可以进行异步响应。一对一的异步通信主要通过消息队列(Queue)实现。
程序之间一对多的通信,只有异步通信的方式,主要通过发布/订阅模式实现。即:客户端发布通知消息,被一个或者多个相关联(订阅了主题)的服务消费。
接下来,我们介绍服务之间异步通信的实现方式。
异步通信实现
在一个分布式系统中,服务之间相互异步通信最常见的方式是发送消息。我们把负责将发送方的正式消息传递协议转换为接收方的正式消息传递协议的工具叫做 Message Broker(消息代理)。市面上有不少 Message Broker 软件,如 ActiveMQ、RabbitMQ、Kafka 等。
服务之间消息传递主要有两种模式:队列(Queue)和主题(Topic)。
Queue 模式是一种一对一的传输模式。在这种模式下,消息的生产者(Producer)将消息传递的目的地类型是 Queue。Queue 中一条消息只能传递给一个消费者(Consumer),如果没有消费者在监听队列,消息将会一直保留在队列中,直至消息消费者连接到队列为止,消费者会从队列中请求获得消息。
Topic 是一种一对多的消息传输模式。在这种模式下,消息的生产者(Producer)将消息传递的目的地类型是 Topic。消息到达 Topic 后,消息服务器将消息发送至所有订阅此主题的消费者。
消息的分类
严格意义上讲,服务之间发送的消息通常有三种:普通 Messages(消息)、Events(事件)、Commands(命令),如下图 3 所示:
图 3. 消息的分类

Messages 是服务之间沟通的基本单位,消息可以是 ID、字符串、对象、命令、事件等。消息是通用的,它没有特殊意图,也没有特殊的目的和含义。也正是由于这个原因,Events 和 Commands 才应运而生。
Events 是一种 Messages,它的目的是向监听者(Listeners)通知发生了什么事情。Events 由 Producer 发送,Producer 不关心 Events 的 Consumers,如下图 4 所示。
图 4. Event 的传递
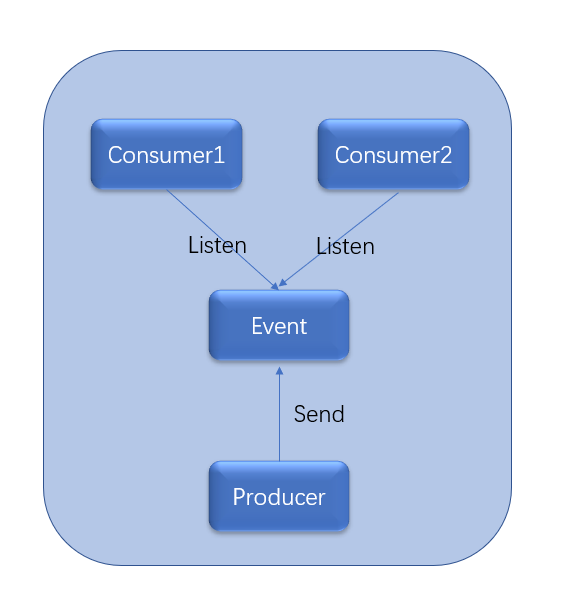
举例说明:有一个电商系统,当消费者下订单时电商平台会发布 OrderSubmittedEvent,以通知其他系统(例如物流系统)新订单的信息。此时,电商平台作为 Event 的 Producer,并不关心 Event 的 Consumer。只有订阅了此 Topic 的消费者才能获取到这个 OrderSubmittedEvent。
Commands 是 Producer 给 Consumer 发送的一对一的指令。Producer 会将 Command 发送到消息队列,然后 Consumer 主动从队列获取 Commands。与 Events 不同,Commands 触发将要发生的事情,如下图 5 所示:
图 5. Command 的传递
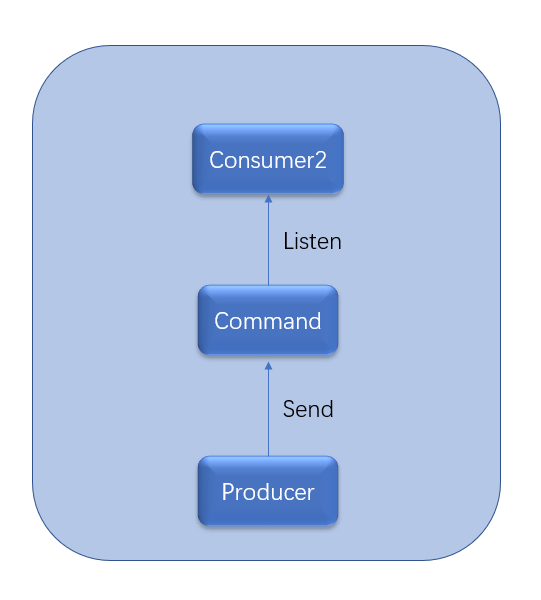
举例说明 Events:在电商系统中客户下订单后,电商将 BillCustomerCommand 命令发送到计费系统以触发发送发票动作。
在介绍了服务之间的异步通信实现和消息的分类后,我们接下来介绍一种消息中间件 ActiveMQ。
AMQ 在 OpenShift 上的企业级实现
在本小节中,我们先介绍标准消息中间件的规范,然后介绍 ActiveMQ 在 RHEL 操作系统和 OpenShift 上的企业级实现。
标准消息中间件规范
目前业内主要的异步消息传递协议有:
Java 消息传递服务(Java Messaging Service (JMS)),它面向 Java 平台的标准消息传递 API。
面向流文本的消息传输协议(Streaming Text Oriented Messaging Protocol (STOMP)): WebSocket 通信标准。
高级消息队列协议(Advanced Message Queueing Protocol (AMQP)):独立于平台的底层消息传递协议,用于集成多平台应用程序。
消息队列遥测传输(Message Queueing Telemetry Transport (MQTT)):为小型无声设备之间通过低带宽发送短消息而设计。使用 MQTT 可以管理 IOT 设备。
目前市面上消息中间件的种类很多,Apache ActiveMQ Artemis 是最流行的开源、基于 Java 的消息服务器。ActiveMQ Artemis 支持点对点的消息传递(Queue)和订阅/发布模式(Topic)。
ActiveMQ Artemis 支持标准 Java NIO(New I/O,同步非阻塞模式)和 Linux AIO 库(Asynchronous I/O,异步非阻塞 I/O 模型)。AMQ 支持多种协议,包括 MQTT、STOMP、AMQP 1.0、JMS 1.1 和 TCP。
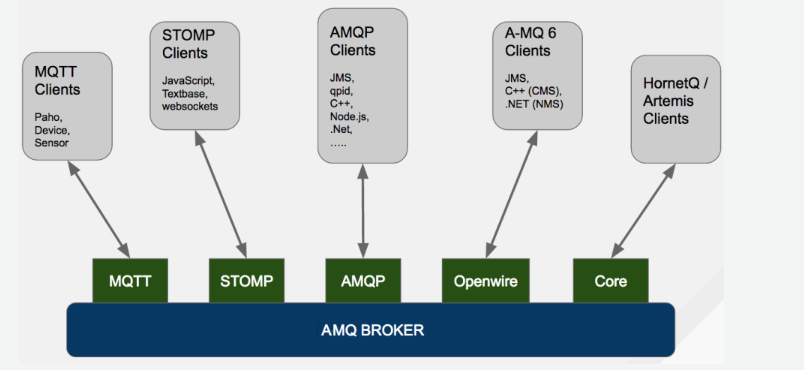
红帽 JBoss AMQ 7 Broker 是基于 Apache ActiveMQ Artemis 项目的企业级消息中间件,在客户生产系统被大量使用。功能上 JBoss AMQ 7 Broker 与 Apache ActiveMQ Artemis 是一一对应的,其支持的协议如下图 6 所示。因为本文主要是面向生产环境的进行介绍,因此下文我们使用 JBoss AMQ 7 Broker 进行功能验证,部署过程不进行赘述。
图 6. AMQ 支持的协议
在 RHEL 中配置 AMQ7
接下来,我们在 RHEL 上配置 JBoss AMQ7。
首先创建目录:
1 2 |
|
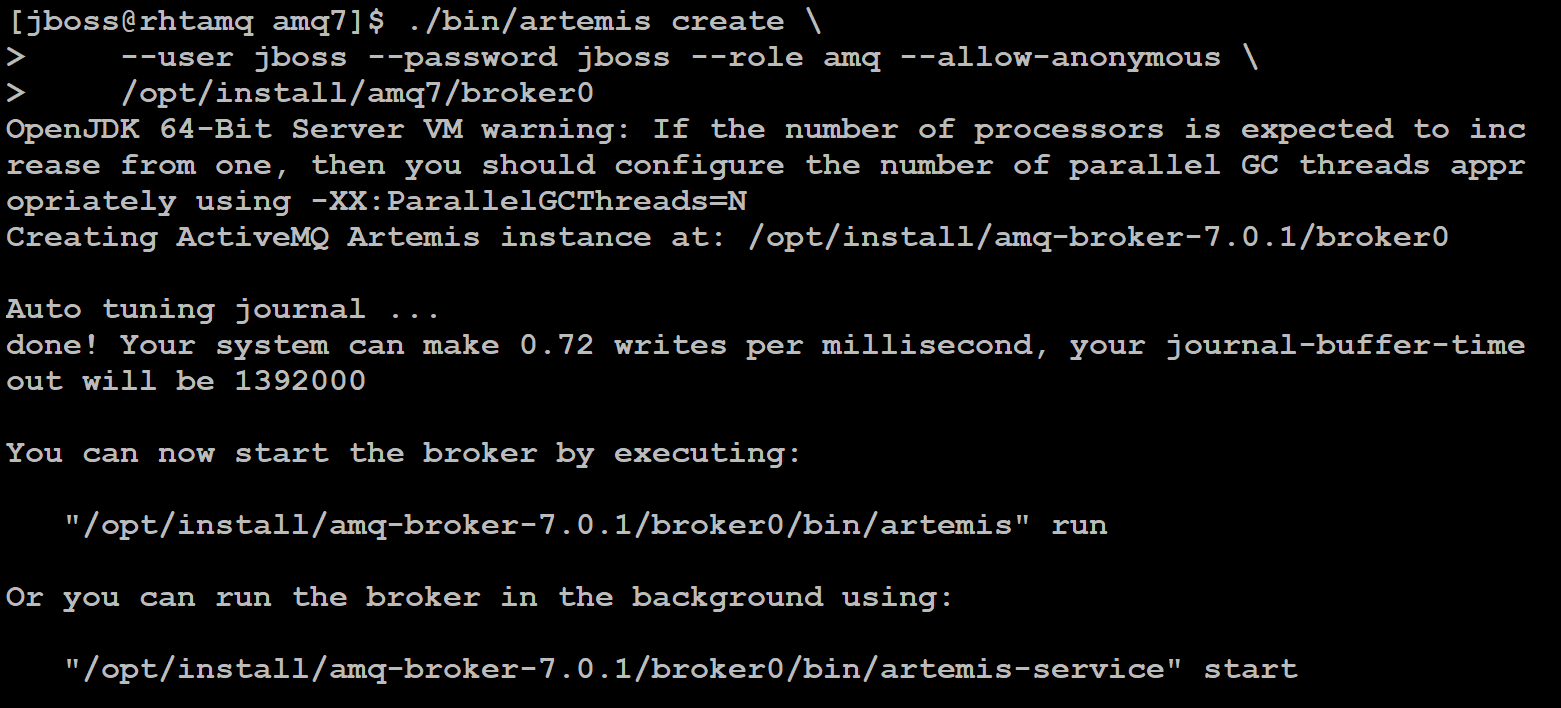
创建名为 broker0 的 JBoss AMQ Broker 实例,并指定 guest 用户和角色的凭据,执行结果如下图 7 所示:
1 2 3 |
|
图 7. 创建 AMQ Broker
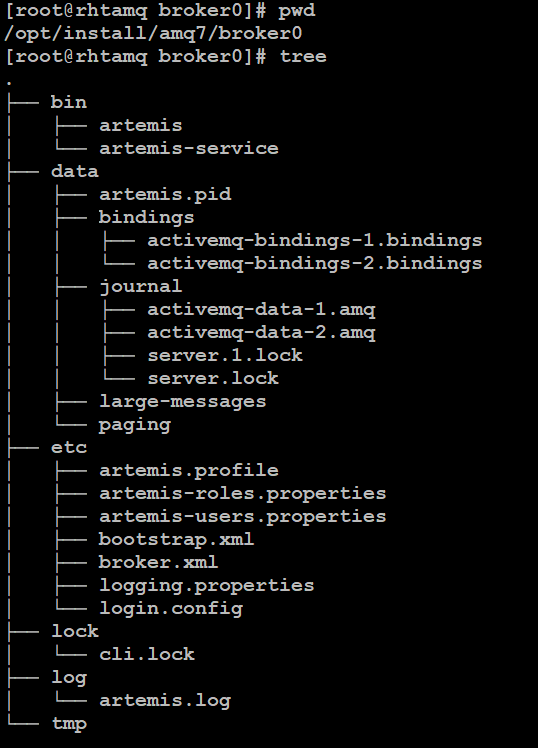
执行完上述所述命令后,RHEL 中/opt/install/amq7/broker0 目录中有一个 broker instance ,其中包含运行 JBoss AMQ 7 所需的库,配置和实用程序,如下图 8 所示:
图 8. AMQ Broker 目录结构
执行命令启动 broker0:
1 2 3 |
|
通过 ps 命令行确认 Broker 已经启动,如下图 9 所示:
图 9. 确认 Broker 已经启动
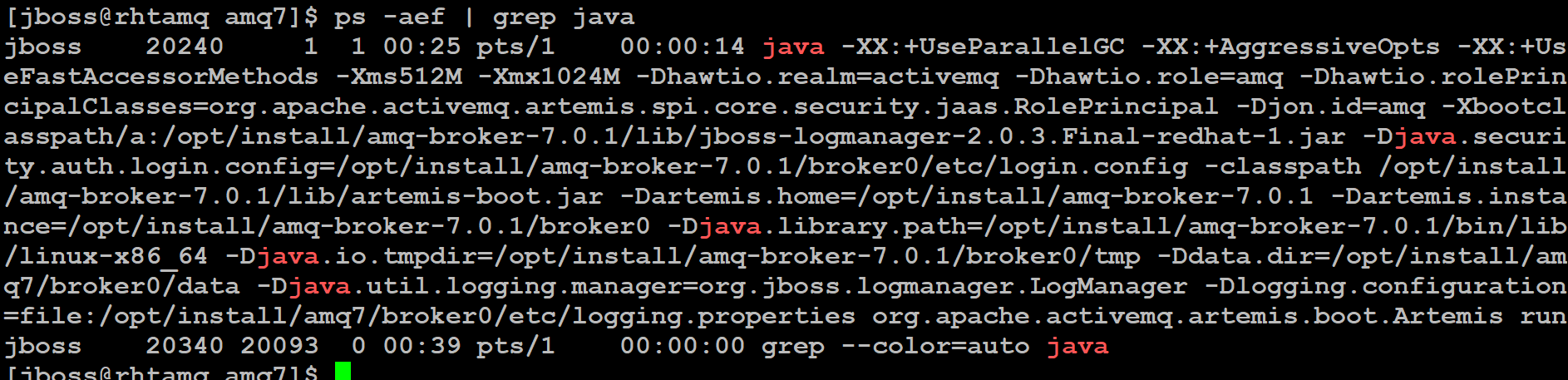
在上图的执行结果中,我们需要到如下参数:
-Ddata.dir=/opt/install/amq7/broker0/data,这是 Broker 文件系统的绝对路径。
-Xms512M -Xmx1024M 表示确定为 Broker 分配的内存的最小值和最大值。
查看 AMQ 的多协议支持
AMQ Broker 默认启动多种协议侦听与其通信的客户端连接(CORE、MQTT、AMQP、STOMP、HORNETQ 和 OPENWIRE)。
首先查看系统的 Java 监听端口,如下图 10 所示:
图 10. 查看 AMQ 的监听端口

从上图可以看出,Broker 正在监听如下端口:61613、61616、1883、8161、5445 和 5672。
通过查看 Broker 日志文件,确认每个端口侦听对应的协议。例如 AMQP 的监听端口是 5672,如清单 1 所示:
清单 1. 查看 AMQ 日志
1 2 3 4 5 6 7 8 |
|
创建持久队列
接下来,使用 JBoss AMQ 7 提供的 artemis 建持久的消息传递地址和队列。
如前文所述:AMQ 支持队列和主题模式。JBOSS AMQ7 中的 Topic 是用 Queue 实现的。在创建 Queue 时通过可以指定参数实现。Multicast 方式是 Topic,Anycast 就是 Queue。
创建名为 DavidAddress 的 Anycast 地址,执行结果如下图 11 所示:
1 |
|
图 11. 创建 AMQ Anycast 消息队列

接下来,创建持久的 Anycast 队列与此前创建的 Anycast 地址相关联:
1 2 |
|
Queue 创建成功以后,可以在 AMQ7 管理控制台中查看新创建的 Address 和 Queue,如下图 12 所示:
图 12. AMQ Console 查看消息队列
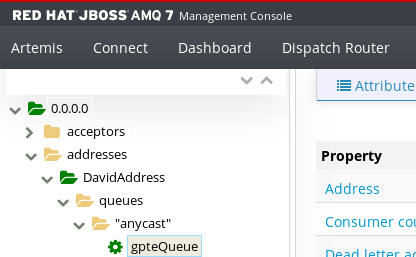
截止到目前,我们已经创建了消息地址和队列。我们关注队列的几个数值。
Consumer Count:访问此队列 Consumer 的数量
Message Count:队列中的消息数。
Messages Acknowledged:队列中的消耗的消息数。
Messages Added:队列中被添加消息数。
目前这几个数值均为零,如下图 13 所示:
图 13. AMQ Console 查看消息队列
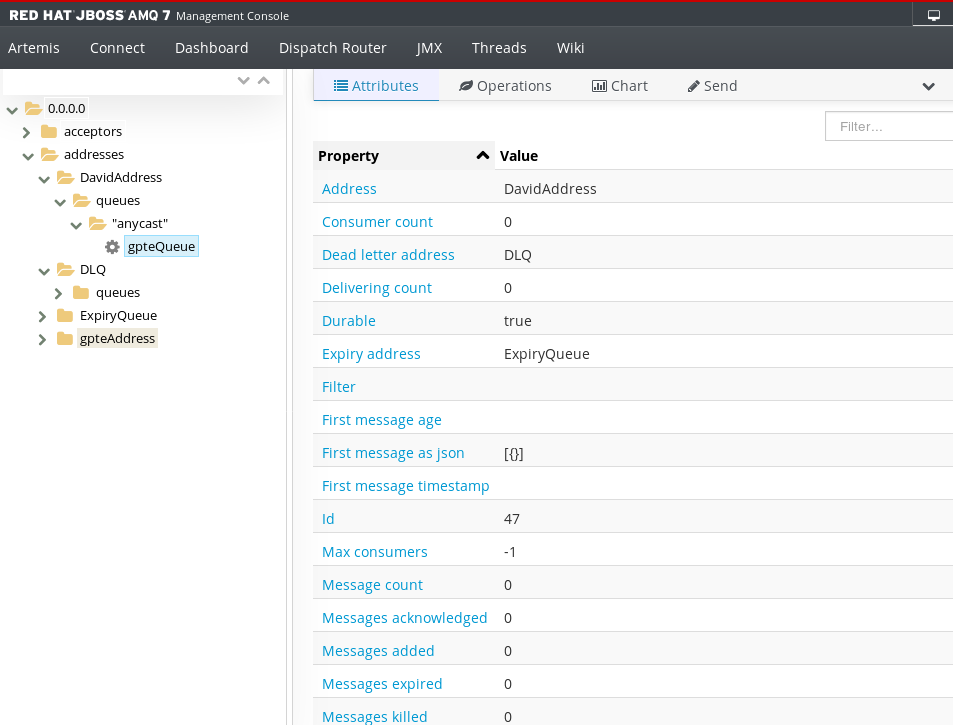
接下来,使用 artemis 创建两个并行线程,向消息队列发送总共 20 个 10 字节消息,每条消息之间有一秒休眠,执行结果如下图 14 所示:
1 2 |
|
图 14. 向队列发送 20 条消息

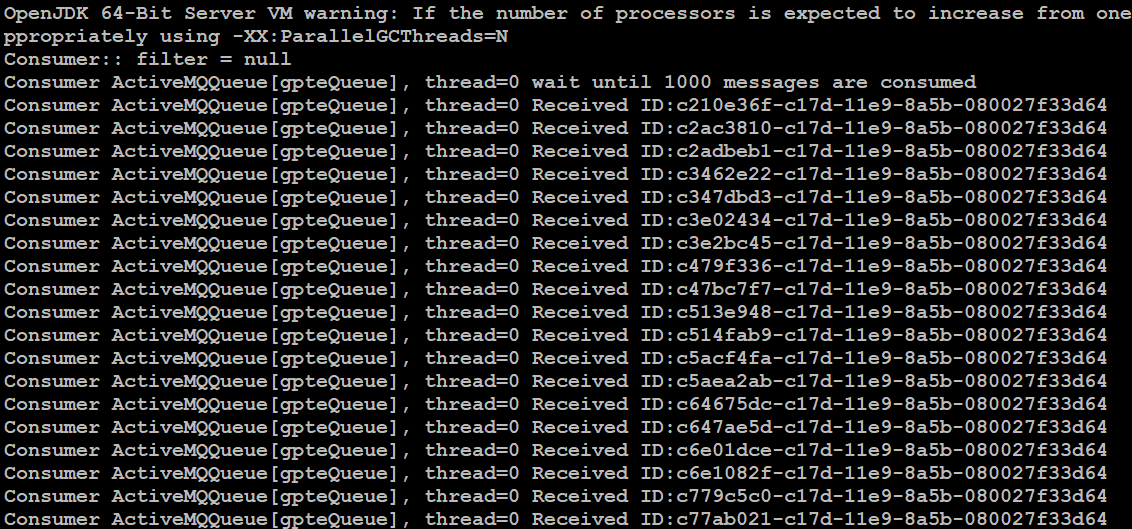
启动两个 Consumer,第一个 Consumer 读取队列中一条消息,第二个 Consumer 读取队列中其余的消息,执行结果如下图 15 所示:
启动第一个 Consumer,执行结果如下图所示,获取到一条消息后 Consumer 程序退出。
1 2 |
|
图 15. 启动第一个 Consumer

启动第二个 Consumer,执行结果如下图 16 所示,获取到 19 条消息后 Consumer 程序退出。
1 |
|
图 16. 启动第二个 Consumer
我们再次查看 AMQ Console,如下图 17 所示:
Consumer Count: 访问此队列 Consumer 的数量,数值为 2;
Message Count:队列中的消息数,数值为 0,因为消息已经被读取;
Messages Acknowledged:队列中的消耗的消息数,数值为 20,队列中被消耗了 20 条消息;
Messages Added:队列中被添加消息数,数值为 20,队列中被发送了 20 条消息。
图 17. AMQ Console 查看消息队列
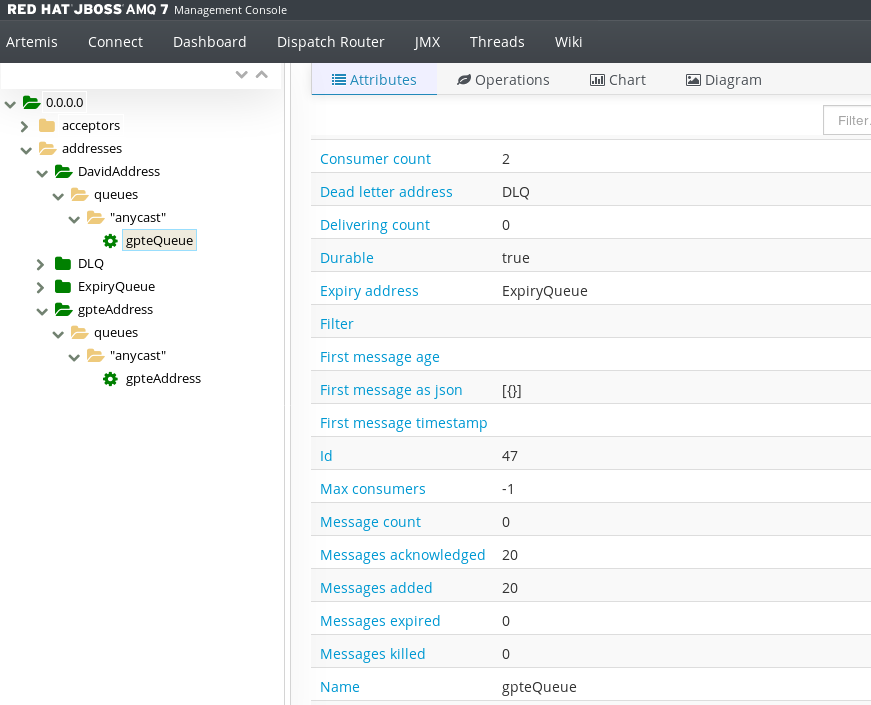
从 AMQ Console 我们得到的反馈结果,符合我们的预期。
AMQ 在 OpenShift 上的部署
在 OpenShift 上我们可以直接用现成的模板部署 AMQ7。针对生产环境我们需要注意以下三点:
AMQ HA 的实现
在 OpenShift 中,AMQ 的高可用是通过对一个 AMQ 创建多个 pod 来实现的,而无需通过 AMQ 本身的 HA 机制。当 AMQ 的一个 pod 出现问题,OpenShift 的 scaledown controller 可以实现 AMQ 的 HA。
在 OpenShift 中,StatefulSet 用于保证有状态应用。当 StatefulSet 发生 scaled down,有状态 pod 实例时会被删除,与被删除 pod 关联的 PersistentVolumeClaim 和 PersistentVolume 将保持不变。当 pod 新创建以后,PVC 会被重新挂在到 Pod 中,之前的数据可以访问。
但如果 AMQ 使用 Queue sharding,StatefulSet 的这种方式就不太合适。使用 sharding 的应用,当出现应用实例减少时,会要求将数据重新分发到剩余的应用程序实例上,而不是一直等待故障 pod 的重启。这种情况下就需要用到 StatefulSet Scale-Down Controller。StatefulSet Scale-Down Controller 允许我们在 StatefulSet 规范中指定 cleanup pod 的 template,该模板将用于创建一个新的 cleanup pod,该 cleanup pod 将挂在被删除的 pod 释放的 PersistentVolumeClain。cleanup pod 可以访问已删除的 pod 实例的数据,并且可以执行 app 所需的任何操作。cleanup pod 完成任务后,控制器将删除 pod 和 PersistentVolumeClaim,释放 PersistentVolume。
AMQ 的访问方式
如果访问 AMQ 的客户端在 OpenShift 内部,那么使用 AMQ 的 Service IP 和端口号即可。如果访问 AMQ 的客户端在 OpenShift 外部,则需要考虑使用 NodePort 的方式。
在 OpenShift 上部署一个 AMQ 单实例
首先,我们先基于一个基础模板部署一个单实例的 AMQ。这种部署方式适合于测试环境。
使用模板创建 AMQ:
1 2 3 |
|
查看 pod,AMQ Broker 已经创建成功:
1 2 3 |
|
登陆 AMQ pod,通过 Producer 向队列中发送消息,可以成功,如清单 2 所示:
清单 2. 向队列发送消息
1 2 3 4 5 6 7 8 |
|
AMQ Console 用于图形化管理。我们为 AMQ Console 在 OpenShift 中创建路由,首先创建路配置文件,如清单 3 所示:
清单 3. AMQ Console 路由配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
应用配置如下:
1 2 |
|
查看新创建的 Console 路由:
1 2 3 4 |
|
通过浏览器可以访问 Console,如下图 18 所示:
图 18. AMQ Console 查看消息队列

在 OpenShift 上部署 AMQ Cluster
OpenShift 提供面向生产的 AMQ Cluster 部署模板,这个模板创建的 AMQ 包含持久化存储:
查看模板:
1 2 3 4 |
|
接下来,通过命令行或者 OpenShift UI 界面,使用模板创建 AMQ 集群。以使用 OpenShift UI 为例如下图 19 所示:
图 19. 选择 AMQ Cluster 模板
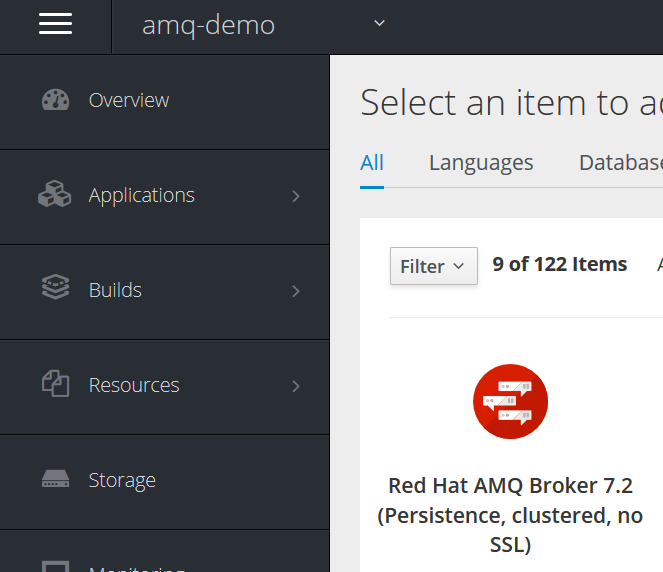
填写 AMQ 集群相应的参数,如下图 20 所示:
图 20. 输入 AMQ 集群参数
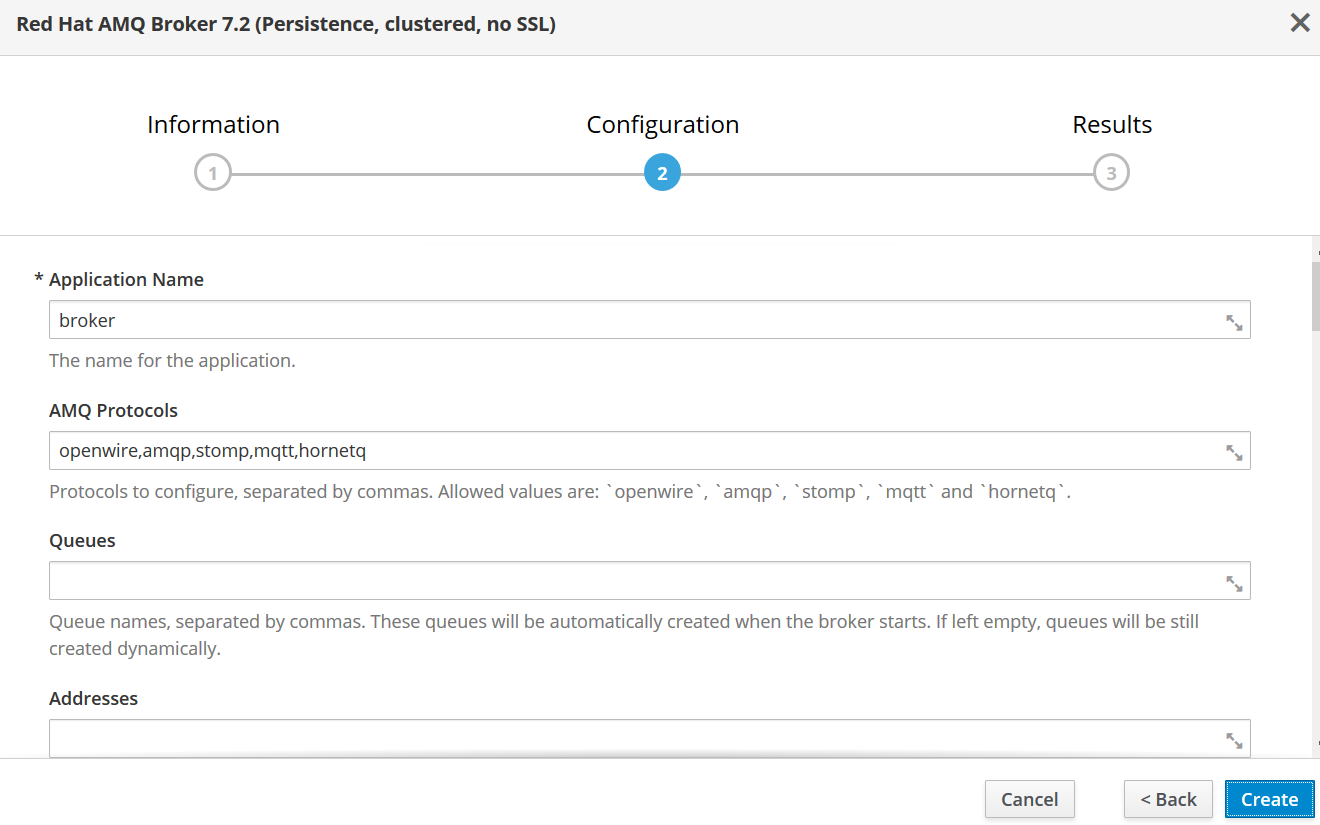
部署成功以后,将 AMQ 的 statefulset 增加到 3 个,设置完成后,OpenShift 中会部署 3 个 AMQ Broker 的 pod,如下图 21 所示:
1 2 |
|
图 21. 查看 AMQ Pod

为了让 AMQ 集群能够被外部客户端访问,我们为 AMQ Broker 配置 NodePort。配置文件如清单 4 所示:
清单 4. AMQ Console 路由配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
应用配置文件:
1 2 |
|
在 AMQ 的 pod 中发起 Producer,向 demoQueue 中发送消息:
1 2 |
|
客户端启动 Consumer,连接 demoQueue,可以读取到消息。如清单 5 所示。
清单 5. Consumer 读取消息队列信息
1 2 3 4 5 |
|
至此,ActiveMQ 在 OpenShift 上成功实现。
接下来,我们介绍 Kafka 的架构以及在 OpenShift 上的实现。
从分布式消息平台到数据流平台
在本小节中,我们主要介绍了 ActiveMQ 的架构以及其在 OpenShift 上的实现。我们知道,传统的应用大多使用 Java EE 架构。这种框架下开发的应用之间的异步通信大多采用 JMS 的方式、以一对一通信为主,因此使用 ActiveMQ Queue 的方式被大量使用。
随着微服务的兴起,一个单体应用被拆分成多个微服务、服务之间的调用骤然增多、服务之间交换的信息量也迅速增加,要求的吞吐量比传统模式下高的多。例如,在常见的日志收集系统 EFK 中,Fluentd 作为数据收集器会收集多个对象(如操作系统、容器等)的大量日志,然后然后将数据传递到 Elasticsearch 集群。多个 Fluentd 收集的大量日志,在向 Elasticsearch 传递时往往就会造成大量阻塞,这时我们使用 ActiveMQ 的消息队列就不是很合适,就需要使用到数据流平台。而在数据流平台中,Kafka 是性能很高、被大量使用的一个开源解决方案。
Kafka 在 OpenShift 上的实现
Kafka 的基本概念
Kafka 是一个分布式数据流平台,开发它的目的是使微服务和其他应用程序组件尽可能快地交换大量数据,以进行实时事件处理。
Kafka 是提供了发布/订阅功能的分布式数据流平台。它适用于两类应用:
构建实时流式数据管道,在系统或应用程序之间可靠地获取数据
构建对数据流进行转换或响应的实时流应用程序
Kafka 有四个核心 API,他们的作用如下:
Producer API:应用将记录流发布到一个或多个 Topic 上。
Consumer API:应用订阅一个或多个 Topic 并处理生成的记录流。
Streams API:应用程序充当流处理器,消耗来自一个或多个 Topic 的输入流并生成到一个或多个输出 Topic 的输出流,从而有效地将输入流转换为输出流。
Connector API:允许将 Kafka Topic 连接到现有应用程序或数据系统的、可重用 Producer 或 Consumer。例如,关系数据库的 Connector 可以捕获对表的每个更改。
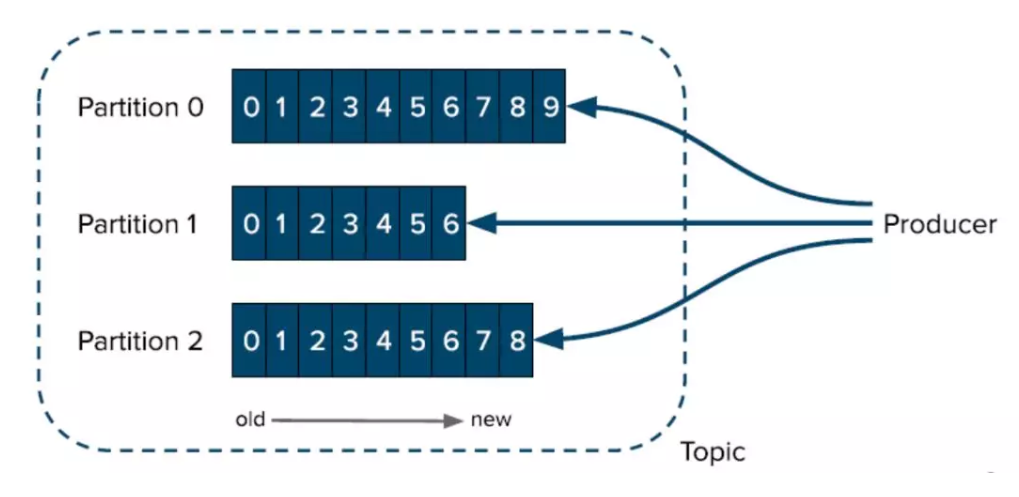
Kafka 中每个 topic 可以有一个或多个 partition(分区)。不同的分区对应着不同的数据文件,不同的数据文件可以存放到不同的节点上,以实现数据的高可用。此外,Kafka 使用分区支持物理上的并发写入和读取,从而大大提高了吞吐量,如下图 22 所示:
图 22. Kafka 的 partition
Kafka 集群在 OpenShift 集群上的实现方式
随着越来越多的应用程序部署到 OpenShift 上,Kafka 集群运行 OpenShift 的场景也越来越多。将 Kafka 部署到 OpenShift 集群上主要有如下两个好处:
可以为 event-driven microservices 提供服务
可以利用到 OpenShift 平台的功能,如弹性伸缩、高可用等。
Topic 是本身无状态的,但 Kafka 作为分布式数据流平台,需要实现状态保持。因此需要实现以下几点:
Kafka 集群中多个 Broker 之间的通信
Broker 的状态持久化(即消息)
Broker 出现问题后可以快速恢复
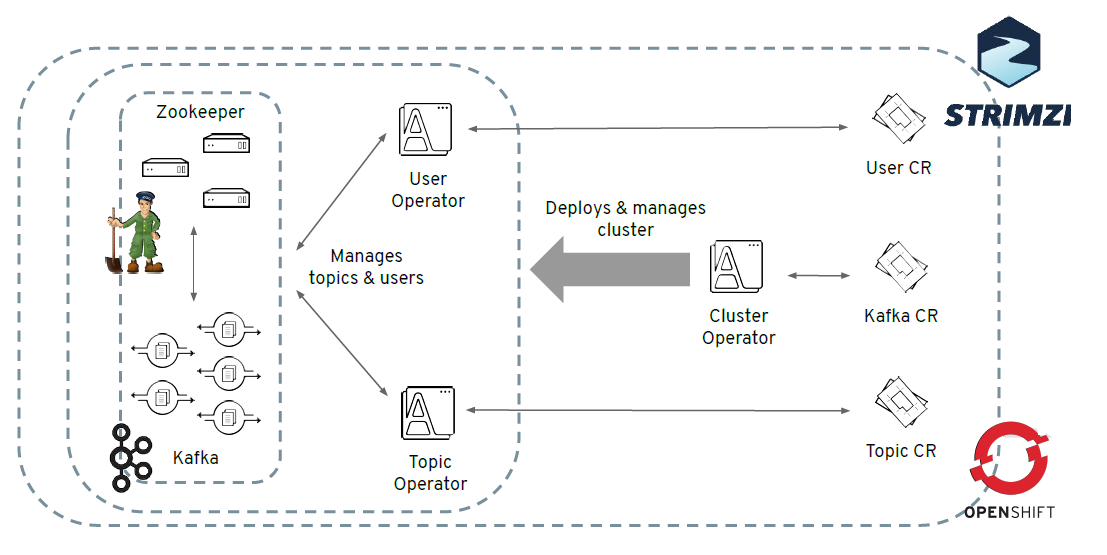
原生 Kubernetes 实现 Kafka 的有状态化较为繁琐,需要使用 Stateful Sets 和 Persistent Volumes。在 OpenShift 中可以通过 Operator 来方便地管理 Kafka 集群,实现状态化。
OpenShift 通过 Operator 管理 Kafka 集群会用到 Strimzi。Strimzi 是一个开源项目,它为在 Kubernetes 和 OpenShift 上运行 Kafka 提供了 Container Image 和 Operator。
Kafka 使用 Zookeeper:
对管理 Kafka Broker 和 Topic Partition 的 Leader 选举。
管理构成集群的 Kafka Brokers 服务发现。
将拓扑更改发送到 Kafka,因此集群中的每个节点都知道新 Broker 何时加入、退出;Topic 被删除或被添加等。
如下图 23 所示:
图 23. 在 OpenShift 集群上实现 Kafka 集群
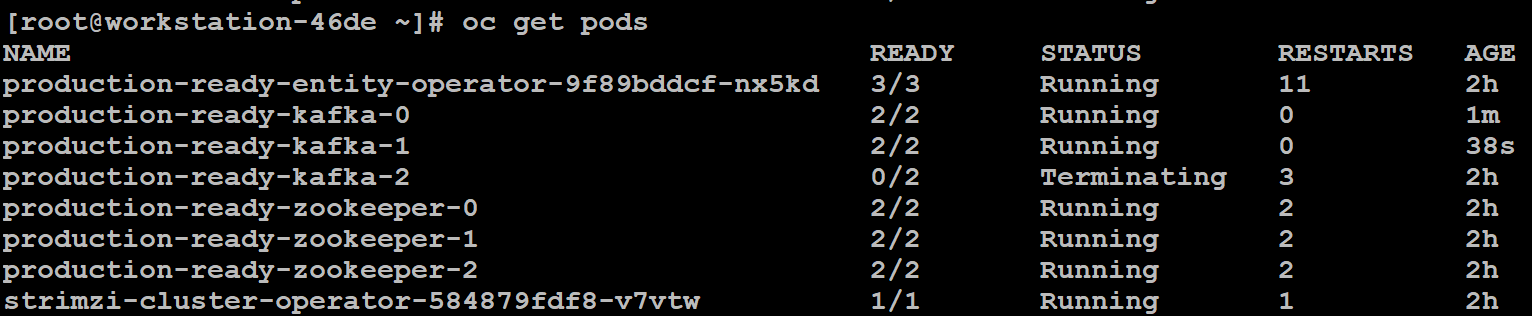
一个 Kafka 集群可以配置很多个 Broker。生产环境中,至少部署 3 个 Broker。接下来,我们展示在 OpenShift 上部署 Kafka 集群。
在 OpenShift 上部署 Kafka 集群
首先下载 Kafka 在 OpenShift 上的安装文件,解压缩后如下图 24、25 所示:
图 24. Kafka 安装包

图 25. Kafka 安装包
由于篇幅有限,我们不会详细介绍配置文件的内容。这些配置文件是在 OpenShift 集群上设置 AMQ Streams 所需的完整资源集合。文件包括:
Service Account
cluster roles and and bindings
一组 CRD(自定义资源定义),用于 AMQ Streams 集群 Operators 管理的对象
Operator 的 Deployment
在安装集群 Operator 之前,我们需要配置它运行的 Namespace。我们将通过修改 RoleBinding.yaml 文件以指向新创建的项目 amq-streams 来完成此操作。只需通过 sed 编辑所有文件即可完成此操作。
1 2 |
|
确认更改生效,如清单 6 所示:
清单 6. Consumer 读取消息队列信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
接下来,部署 Kafka Operator,执行结果如下图 26 所示:
1 2 |
|
图 26. 部署 Kafka Operator
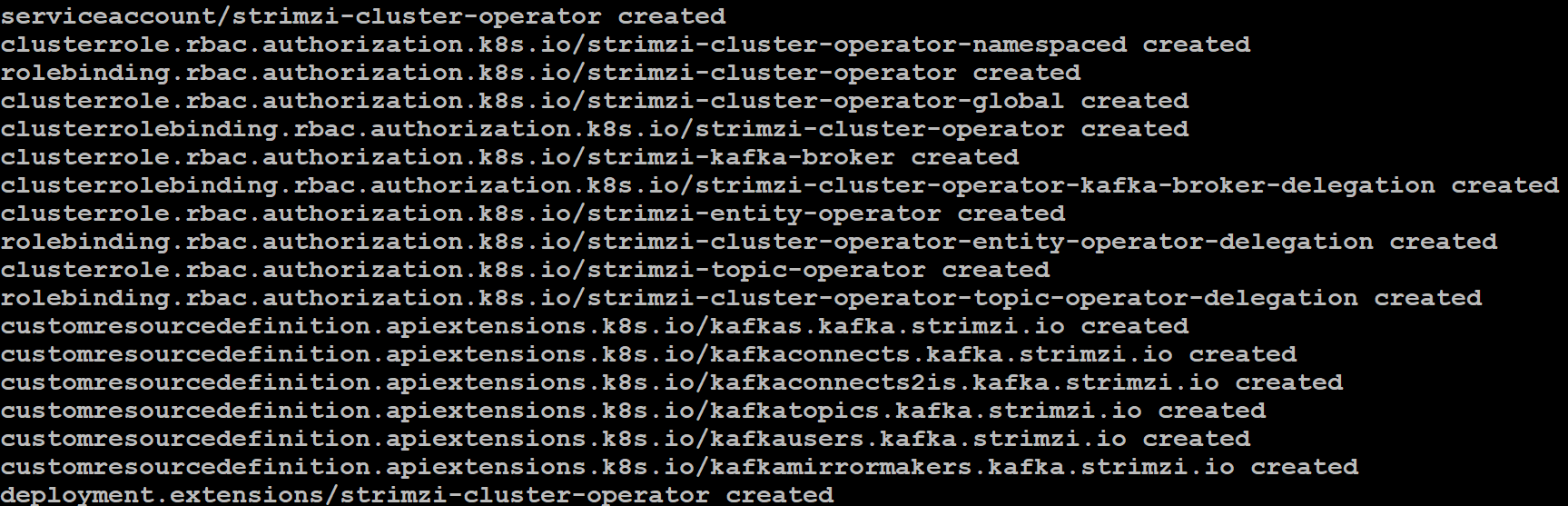
查看部署结果,如下图 27 所示:
图 27. 确认部署 Kafka Operator 部署成功

我们通过配置文件部署 Kafka 集群,如清单所示。
配置文件中包含如下设置:
3 个 Kafka broker- 这是生产部署的最小建议数值
3 ZooKeeper 节点 - 这是生产部署的最小建议数量
持久声明存储,确保将持久卷分配给 Kafka 和 ZooKeeper 实例
清单 7. Kafka 集群配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
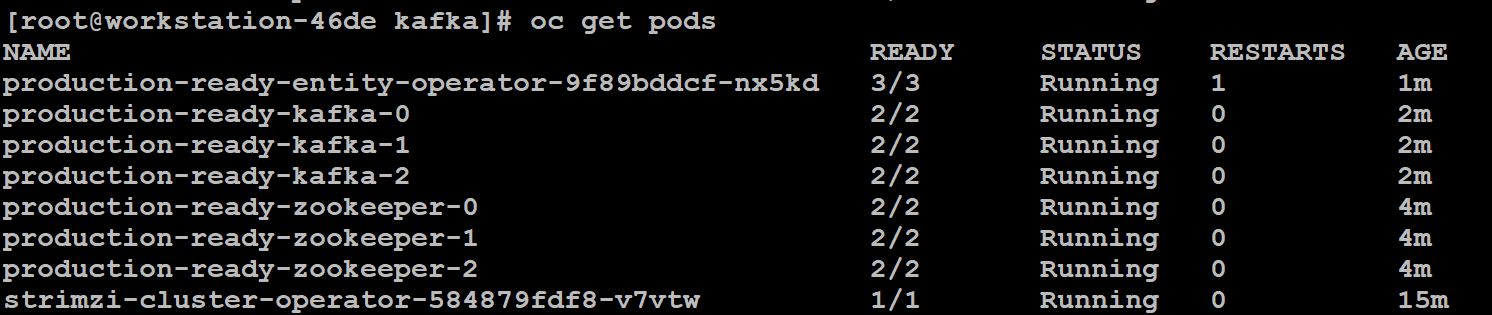
应用配置,查看部署结果如下图 28 所示:
1 2 |
|
图 28. Kafka 集群部署成功
通过配置文件创建 Kafka Topic,配置文件如清单 8 所示:
清单 8. Topic 配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
在上面的配置中:
metadata.name,这是 topic 的名称
metadata.labels [strimzi.io/cluster]是 topic 的目标集群
spec.partitions 是 topic 的分区数
spec.replicas,即每个分区的副本数
spec.config 包含其他配置选项,例如保留时间和段大小
应用配置:
1 2 |
|
我们来获取 Topic 信息。
首先登陆 Kafka 的 pod,然后利用 kafka-topics.sh 脚本查看 Topic 的信息,如清单 9 所示,我们可以看到分区是两个:
清单 9. 查看 Topic 信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
增加 Partition 数量,首先需要修改配置文件,如清单 10 所示
清单 10. 修改 Topic 配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
应用配置:
1 2 |
|
首先登陆 Kafka 的 pod,然后利用 kafka-topics.sh 脚本查看 Topic 的信息,分区数量已经从两个增加到了十个,如清单 11 所示
清单 11. 查看 Topic 信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
接下来,通过 kafka-console-producer.sh 脚本启动 Producer,如清单所示:
清单 12. 启动 Producer
1 2 3 4 5 6 7 8 9 10 |
|
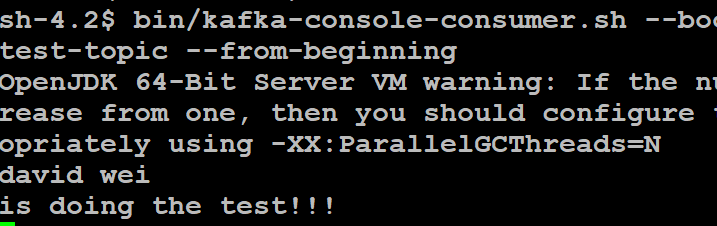
我们发送信息到到 Topic 中,第一次发送"david wei",第二次发送"is doing the test!!!"如下图 29 所示:
图 29. 向 Topic 中发送信息

接下来,使用 kafka-console-consumer.sh 脚本启动 Consumer 监听 Topic,如清单 13 所示:
清单 13 启动 Producer
1 2 3 4 5 6 7 8 |
|
Consumer 可以读取到 Topic 中此前 Producer 发送的消息,如图 30 所示:
图 30. Consumer 读取 Topic 信息
配置 Kafka 外部访问
在某些情况下,需要从外部访问部署在 OpenShift 中的 Kafka 群集。接下来我们介绍配置的方法。首先,使用包含外部 Listener 配置内容的文件重新部署 Kafka 集群,如清单 14 所示:
清单 14. Kafka 集群配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
应用配置文件:
1 2 |
|
应用配置文件以后,Operator 会对 Kafka 集群上启动滚动更新,逐个重新启动每个代理以更新其配置,如图 31 所示,以便在 OpenShift 中的每个 Broker 都有一个路由。
图 31. Kafka 集群滚动升级
查看 Kafka Broker 的路由,如清单 15 所示:
清单 15. Kafka 集群路由
1 2 3 4 5 6 |
|
接下来,我们在 OpenShift 集群外部配置代理与 OpenShift 中的 Kafka 进行交互,外部客户端必须使用 TLS。首先,我们需要提取服务器的证书。
1 2 3 |
|
然后,我们需要将其安装到 Java keystore。
1 2 3 |
|
使用此证书 Producer 和 Consumer 两个应用,下载两个 JAR。
1 2 3 4 |
|
使用新的配置设置启动两个应用程序。
首先启动 Consumer 应用,访问 OpenShift 内部的 Kafka Broker,执行结果如下所示:
1 2 3 4 5 |
|
启动 Producer 应用:
1 2 3 4 5 |
|
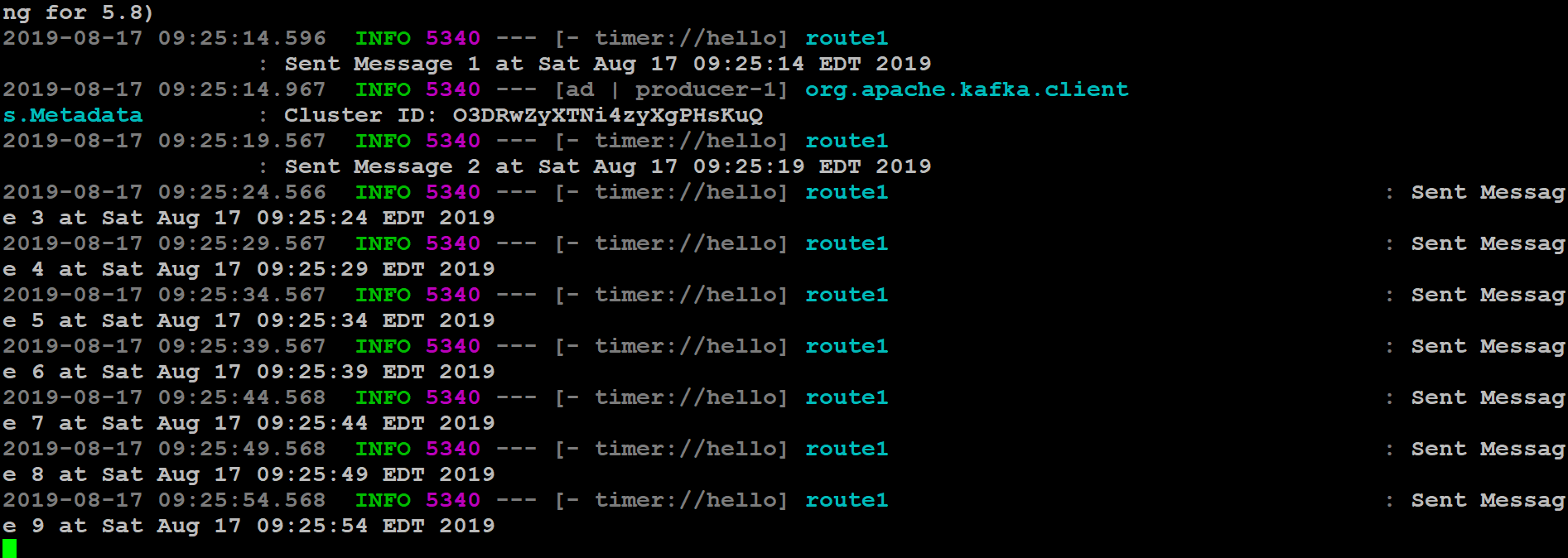
两个应用都启动后,我们观察日志可以看到,Producer 从外部通过 OpenShift 上 Kafka 的路由向 Topic 中发送消息,Consumer 应用从外部通过 OpenShift 上 Kafka 的路由监听 Topic,获取到 Topic 中的信息。如下图 32、33 所示:
图 32. Consumer 应用

图 33. Producer 应用
在 OpenShift 集群中启动 Consumer 监听 Topic,可以看到结果如图 34 所示,与外部 Consumer 看到信息一致:
1 2 |
|
图 34. 获取 Topic 中消息
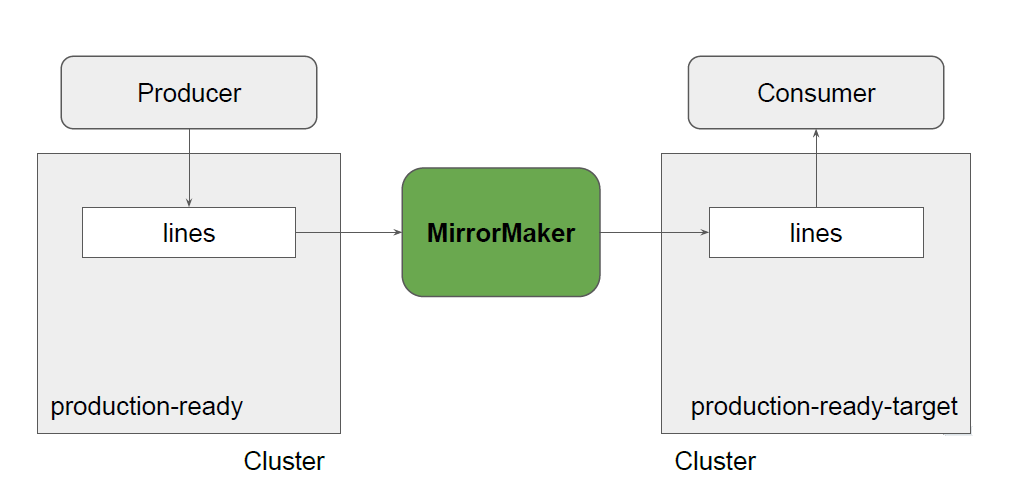
配置 Mirror Maker
很多情况下,应用程序需要跨 Kafka 集群在彼此之间进行通信。数据可能在数据中心的 Kafka 中被摄取并在另一个数据中心中被消费。接下来,我们将展示如何使用 MirrorMaker 在 Kafka 集群之间复制数据,如图 35 所示:
图 35. Kafka 集中的 MirrorMaker
部署第二套 Kafka 集群:Production-ready-target,作为现有 Production-ready Kafka 集群的目标端。集群部署配置文件如清单 16 所示:
清单 16. Kafka 集群配置文件
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java