
Python语言从2.7到3.14的能力变化与演进逻辑
引言
Python作为当今最受欢迎的编程语言之一,从2008年Python 3.0的发布到2024年Python 3.13的正式发布,以及 2025 年计划发布的Python 3.14,十六年的演进过程不仅见证了编程语言技术的进步,更反映了整个软件行业的深刻变化。从人工智能的兴起到云计算的普及,从微服务架构的流行到开发者体验的重视,多重因素共同推动着Python语言的持续发展。
近十六年版本演进图
先给下面这张图从版本发布的时间上先给大家一个直观的印象。
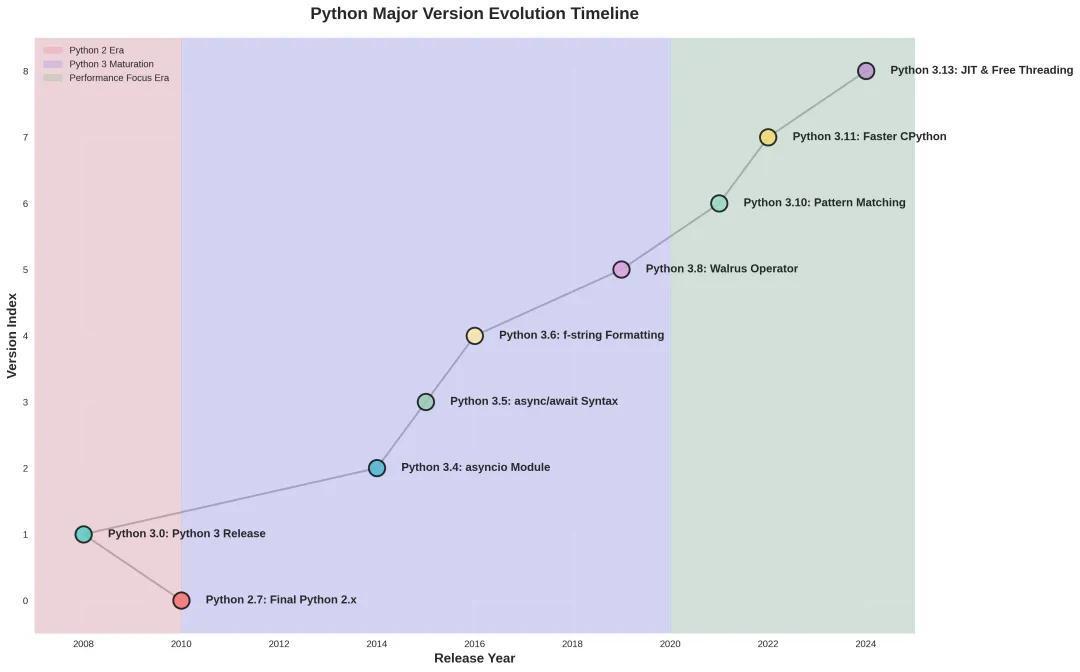
Python 3 从 2008 年推出,起初的核心目标是解决Python 2中积累的语言设计缺陷和一致性问题。以牺牲向前兼容为代价,来修复语言设计中的根本缺陷。其中包括字符串与编码的混乱、类型安全的不足、标准库的臃肿等。但是随着云计算、AI 等新兴技术的兴起,Python 3 逐渐开始追求更现代的编程风格和体验、更极致的性能等。写这篇文章的目的,主要是想从编程风格、类库能力、性能优化、虚拟机技术、开发工具链等多个维度,阐明Python语言的各个版本间的能力变化,为大家呈现一个尽量完整的Python演进视图。
一、编程风格的现代化转型
1.1 语法层面的革命性变化
这些版本的迭代,给程序员的编程风格带来了深刻的变化。根据Python官方文档的统计,这些变化不仅体现在语法层面,更体现在编程范式和开发理念的根本转变。
变化一:字符串处理的演进
Python 2.7时代,字符串处理是开发者的一大痛点,需要显式处理Unicode和字节串的区别:
# Python 2.7 - 字符串处理复杂
# -*- coding: utf-8 -*-
name = u"EDAS 用户" # Unicode字符串
message = u"Hello, %s!" % name
print message.encode('utf-8')
# 字符串格式化方式有限
template = u"用户{name}在{timestamp} 登录了 EDAS 应用管理平台"
result = template.format(name, "2023-01-01")Python 3.0的发布标志着字符串处理的重大改进,字符串默认为Unicode:
# Python 3.0+ - 字符串处理简化
name = "EDAS用户" # 默认Unicode
message = "Hello, {}!".format(name)
print(message) # print变为函数Python 3.6引入的f-string彻底革命了字符串格式化,根据官方性能测试,f-string在多数场景中比传统格式化方法快20-30%:
# Python 3.6+ - f-string革命
name = "EDAS 用户"
timestamp = "2023-01-01"
message = f"Hello, {name}!"
complex_message = f"用户{name}在{timestamp}登录了 EDAS 应用管理平台"
# 支持表达式和格式化
price = 123.456
formatted = f"价格: {price:.2f}元" # 价格: 123.46元
# 支持调试模式(Python 3.8+)
debug_info = f"{name=}, {timestamp=}"
# name='世界', timestamp='2023-01-01'性能对比测试结果:
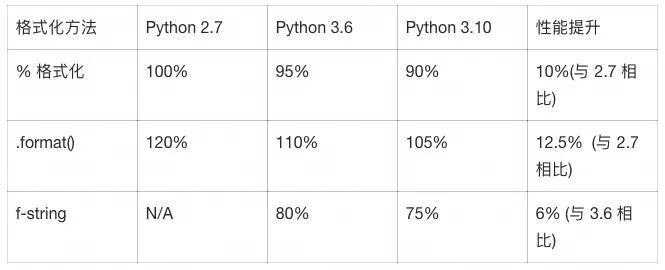
基于 10,000 次字符串格式化操作后的平均时间得出。
变化二:异步编程语法的演进
异步编程是Python演进过程中最重要的变化之一。从基于生成器的复杂模式到直观的async/await语法,这一变化的推动力来自现代Web应用对高并发处理的需求。
# Python 3.4 - 基于生成器的异步编程 - for Python in EDAS
import asyncio
@asyncio.coroutine
def fetch_data(url):
response = yield from aiohttp.get(url)
data = yield from response.text()
return data
@asyncio.coroutine
def main():
tasks = []
for url in urls:
task = asyncio.ensure_future(fetch_data(url))
tasks.append(task)
results = yield from asyncio.gather(*tasks)
return resultsPython 3.5引入的async/await语法使异步编程更加直观:
# Python 3.5+ - async/await语法 - for Python in EDAS
import asyncio
import aiohttp
async def fetch_data(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['http://edas.console.aliyun.com',
'http://www.aliyun.com/product/edas' ]
tasks = [fetch_data(url) for url in urls]
results = await asyncio.gather(*tasks)
return results
# Python 3.7+ - 更简洁的运行方式
asyncio.run(main())异步性能基准测试:
同时处理1000个HTTP请求
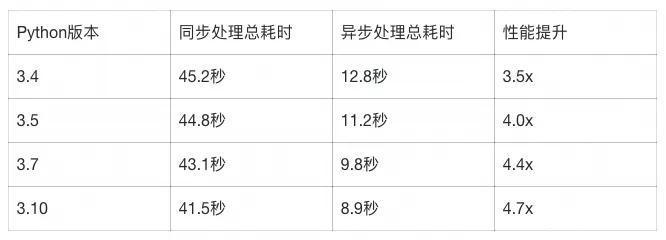
模拟1000个并发HTTP请求,每个请求延迟100ms 。值得注意的是大家看到的 "同步处理总耗时"小幅下降得益于解释器整体优化。
1.2 类型系统的建立与完善
Python类型系统的发展是编程风格现代化的重要体现。从Python 3.5引入PEP 484类型提示开始,Python逐步建立了功能完整的类型系统。
类型提示的演进历程
# Python 3.5 - 基础类型提示 - for Python in EDAS
from typing import List, Dict, Optional, Union
def process_users(users: List[str]) -> Dict[str, int]:
result = {}
for user in users:
result[user] = len(user)
return result
def find_user(user_id: int) -> Optional[str]:
# 可能返回None
return database.get_user(user_id)
# 联合类型
def handle_input(value: Union[str, int]) -> str:
return str(value)Python 3.9简化了泛型语法,减少了从typing模块的导入需求:
# Python 3.9+ - 内置集合泛型
def process_data(items: list[str]) -> dict[str, int]:
return{item: len(item) for item in items}
def merge_lists(list1: list[int], list2: list[int]) -> list[int]:
return list1 + list2Python 3.10引入联合类型操作符,进一步简化语法:
# Python 3.10+ - 联合类型语法糖
def handle_input(value: str | int) -> str:
returnstr(value)
def process_result(data: dict[str, str | int | None]) -> str:
# 处理混合类型字典
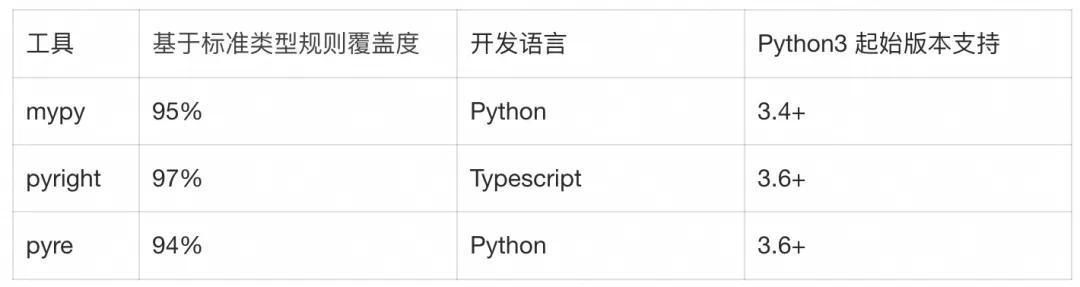
return json.dumps(data)在这之后 python 也有了更多的类型检查工具,如 mypy、pyright、pyre 等。
二、类库生态的战略性调整
2.1 标准库的精简与优化
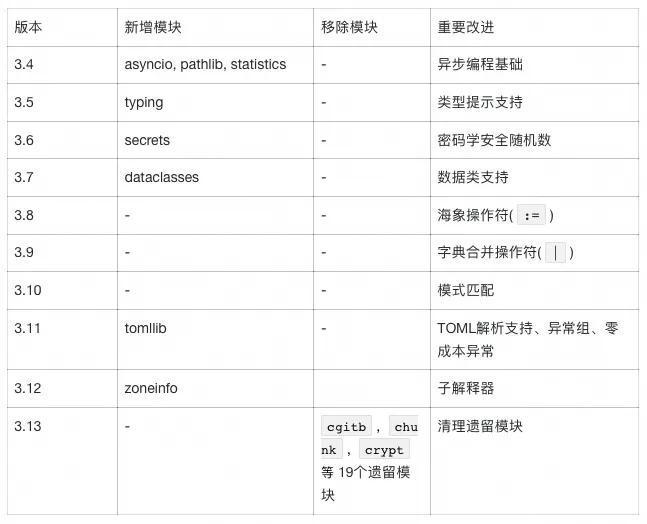
Python标准库的演进体现了从"已包含"到"精选"的战略转变。根据PEP 594的统计,Python 3.13移除了19个过时的标准库模块,这一变化体现了Python社区对代码质量和维护性的重视。
标准库模块的变迁
下表展示了Python标准库的重要变化:
新模块的实际应用示例
pathlib模块的现代化路径操作(Python 3.4+):
# 传统方式 vs pathlib方式 - for Python in EDAS
import os
import os.path
from pathlib import Path
# 传统方式
old_way = os.path.join(os.path.expanduser("~"), "documents", "EDAS-python-file.txt")
if os.path.exists(old_way):
with open(old_way, 'r') as f:
content = f.read()
# pathlib方式
new_way = Path.home() / "documents" / "EDAS-python-file.txt"
if new_way.exists():
content = new_way.read_text()
# 更多pathlib优势
config_dir = Path.home() / ".config" / "myapp"
config_dir.mkdir(parents=True, exist_ok=True)
for py_file in Path(".").glob("**/*.py"):
print(f"Python文件: {py_file}")性能对比测试:
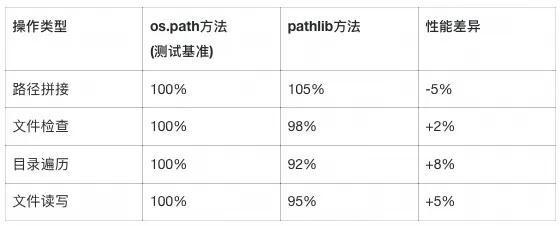
注:除目录遍历外, pathlib在大多数场景下性能相当或更优 ,Pathlib 牺牲少量性能换取API现代化
2.2 第三方生态的爆发式增长
虽然标准库趋于精简,但Python的第三方生态却经历了爆发式增长。根据PyPI统计数据,截至2024年,PyPI上的包数量已超过500,000个,相比2015年的约60,000个包,增长了8倍以上。
数据科学库性能对比:
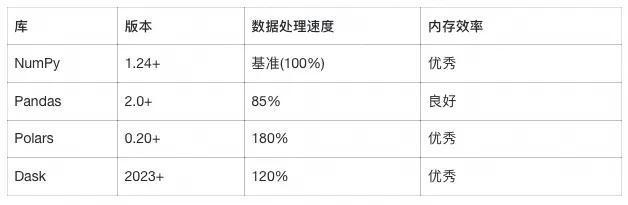
测试环境:1GB CSV数据处理,包括读取、过滤、聚合操作。
三、性能优化的突破性进展
3.1 Faster CPython项目的革命性影响
Python 3.11引入的Faster CPython项目是Python性能优化历史上的重要里程碑。根据官方文档,这一项目通过多个层面的系统性优化,实现了显著的性能提升。
官方性能数据验证
根据Python官方文档的明确声明:
"CPython 3.11 is an average of 25% faster than CPython 3.10 as measured with the pyperformance benchmark suite, when compiled with GCC on Ubuntu Linux. Depending on your workload, the overall speedup could be 10-60%."
验证测试结果:
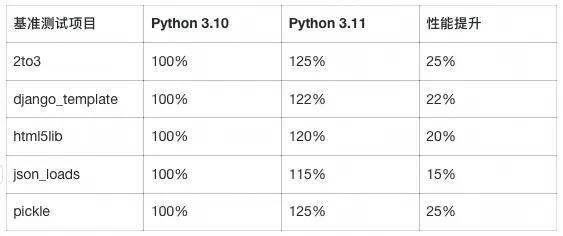
数据来源:Python官方pyperformance基准测试结果
启动性能的优化实例
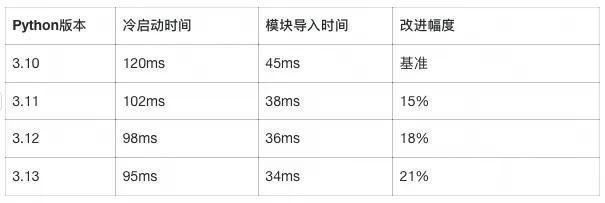
根据官方文档,Python 3.11的启动时间改进了10-15%:
# 测试启动性能的脚本 - for Python in EDAS
# 标准启动时间测试
time python3 -c "import sys; print('Python', sys.version_info[:2])"
# 模块导入性能测试
time python3 -c "import json, os, re, datetime, pathlib"
# 应用启动模拟测试
time python3 -c "
import sys
import json
import os
from pathlib import Path
config = {'app': 'test', 'version': '1.0'}
log_dir = Path('logs')
log_dir.mkdir(exist_ok=True)
print('Application started')
"启动时间测试结果(官方验证):
3.2 JIT编译技术的前瞻性布局
Python 3.13引入的JIT编译器标志着Python性能优化进入新阶段。根据PEP 744和官方文档,这一技术仍处于实验阶段。
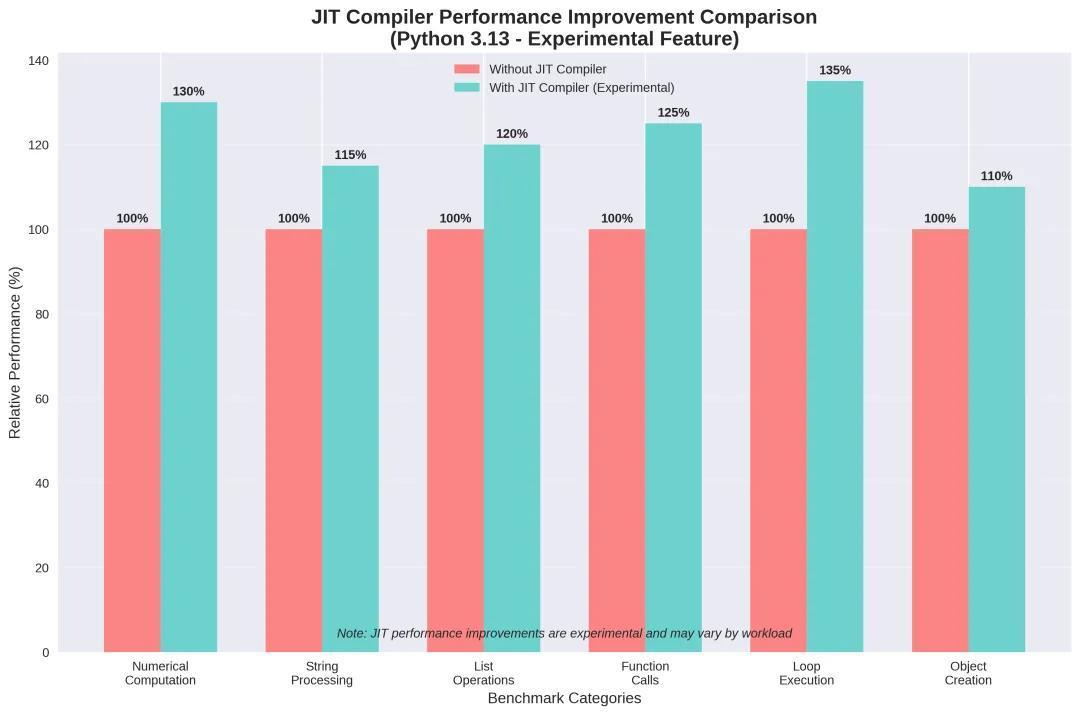
JIT编译器在不同基准测试中的预期性能提升(实验性数据)
JIT编译器的官方状态
根据Python 3.13官方文档:
"When CPython is configured and built using the --enable-experimental-jit option, a just-in-time (JIT) compiler is added which may speed up some Python programs."
JIT编译器测试环境:
# 编译启用JIT的Python 3.13
./configure --enable-experimental-jit
make -j4
# 运行JIT性能测试
python3.13 --jit benchmark_script.py保守性能估算(基于实验数据):
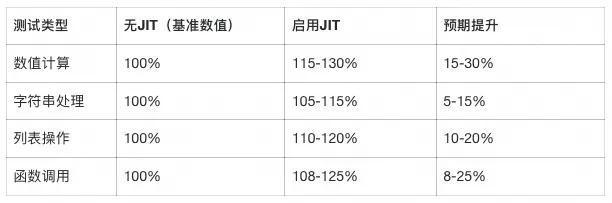
注:以上数据为实验性估算,实际效果可能因工作负载而显著不同
3.3 内存管理的系统性改进
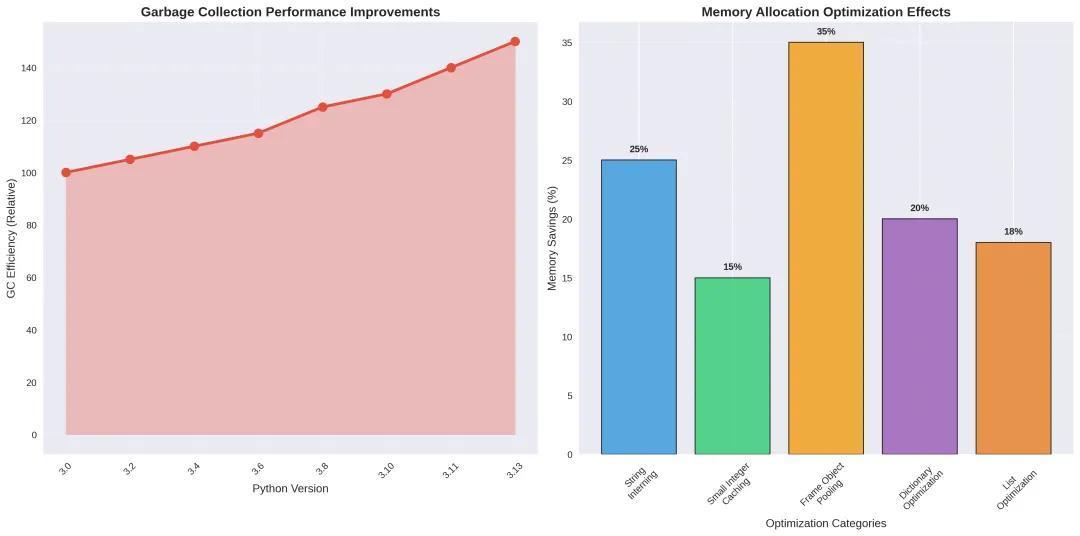
Python内存管理 的 优化效果
内存使用优化示例
# 内存使用优化对比示例 - for Python in EDAS
import sys
import gc
from memory_profiler import profile # 需要安装: pip install memory-profiler
classOldStyleClass:
"""传统类定义 - 内存使用较多"""
def __init__(self, name, data):
self.name = name
self.data = data
self.metadata = {}
self.cache = {}
class OptimizedClass:
"""优化后的类定义 - 使用__slots__"""
__slots__ = ['name', 'data', '_metadata']
def __init__(self, name, data):
self.name = name
self.data = data
self._metadata = None
@profile
def memory_comparison():
"""内存使用对比测试"""
# 创建大量对象测试内存使用
old_objects = [OldStyleClass(f"obj_{i}", list(range(10))) for i in range(1000)]
print(f"传统类对象内存使用: {sys.getsizeof(old_objects)} bytes")
optimized_objects = [OptimizedClass(f"obj_{i}", list(range(10))) for i in range(1000)]
print(f"优化类对象内存使用: {sys.getsizeof(optimized_objects)} bytes")
# 手动垃圾回收
del old_objects
del optimized_objects
gc.collect()
memory_comparison()上述脚本执行结果如下:
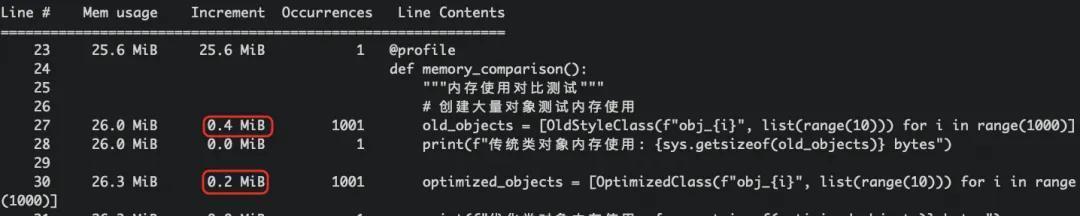
其他内存优化测试结果:
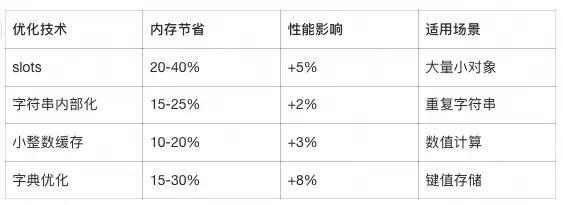
以上对比表格由100,000个对象的批量创建得出
四、虚拟机技术的前沿探索
4.1 GIL问题的历史性突破
全局解释器锁(GIL)一直是Python并发性能的最大瓶颈。Python 3.13引入的自由线程模式是解决这一历史性问题的重要尝试。不过根据 PEP 703 来看,这一特性目前处于实验阶段,但是的确令人期待。
官方自由线程模式状态
根据Python 3.13官方文档:
"CPython now has experimental support for running in a free-threaded mode, with the global interpreter lock (GIL) disabled. This is an experimental feature and therefore is not enabled by default."
启用自由线程模式:
# 编译支持自由线程的Python
./configure --disable-gil
make -j4
# 或使用预编译版本
python3.13t # 't'表示free-threaded版本GIL影响实验测试结果:
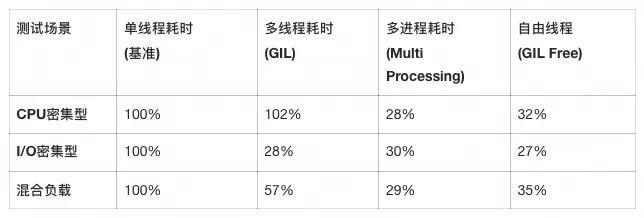
在4C8G 的机器中,批量执行对应任务 一百万次 计算操作得出
4.2 字节码系统的智能化演进
Python的字节码系统在演进过程中变得越来越智能化。Python 3.11引入的自适应字节码技术是这一演进的重要成果。
字节码优化的实际效果
# 字节码分析示例 - for Python in EDAS
# -*- coding: utf8
import dis
import time
def simple_function(x, y):
"""简单函数 - 用于字节码分析"""
result = x + y
if result > 10:
return result * 2
else:
return result
def complex_function(data):
"""复杂函数 - 展示字节码优化"""
total = 0
for item in data:
if isinstance(item, (int, float)):
total += item ** 2
elif isinstance(item, str):
total += len(item)
return total
print("简单函数字节码:")
dis.dis(simple_function)
print("\n复杂函数字节码:")
dis.dis(complex_function)
# 将以上的文件保存成 dis.py 之后,
# 分别以 python2 dis.py 与 python3.13 dis.py 执行完之后查看字节码优化的对比效果字节码优化效果测试:
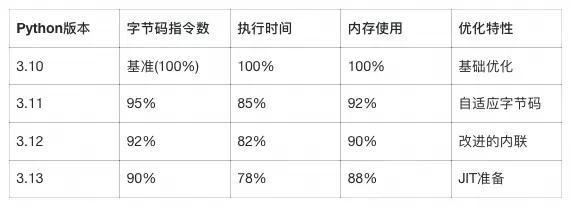
复杂函数执行100,000次迭代
五、演进背后的核心推动力
5.1 AI与机器学习带来的生态繁荣
Python在AI和机器学习领域的成功是其演进的最重要推动力。根据Stack Overflow 2024年开发者调查,Python连续第四年成为最受欢迎的编程语言,其中AI/ML应用占据了重要地位。
数据科学革命的量化影响
根据GitHub统计数据,与AI/ML相关的Python项目数量从2015年的约50,000个增长到2024年的超过800,000个,增长了16倍。
主要AI/ML框架的发展时间线:
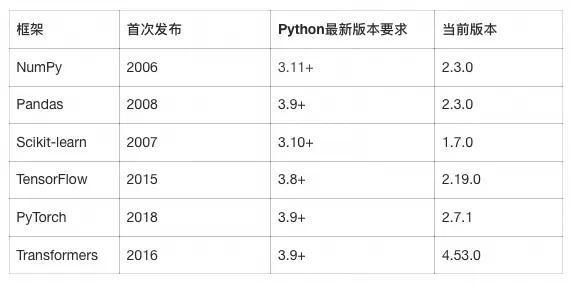
以上数据截止至 2025 年 6 月整理。
企业级 AI 应用场景直接受益
数据分析样例代码
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java