
浅析 rust 热门库 Tokio
Tokio可以说是rust中最热门的库,对于异步与并发进行了很好的支持。大多数基于rust的开源框架都使用到了Tokio,因此在介绍这些实现开源框架时经常会被问到:底层的异步和并发是怎么实现的?我只能回答:底层的异步和并发都是由Tokio控制的。这显然不是一个令人满意的回答。因此本文章将对于Tokio的基本方法和底层逻辑进行分析。
概述
一句话概括
Tokio 可以理解成一个“任务池”和一个“调度器”,负责把所有在任务池中的任务调度运行起来。
更具体一点,Tokio 可以类比为一个“异步操作系统”:
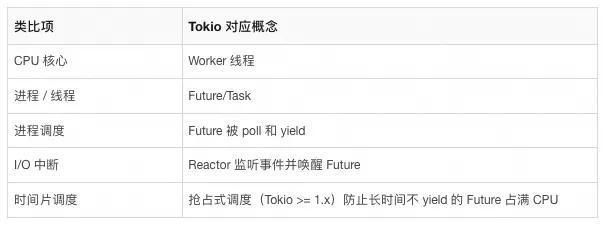
Tokio 的优势主要体现在以下方面:
- 高效
通过内部的优化机制(调度算法、无锁队列与内存池管理等)与 rust 的语言优势,Tokio 效率较高,在早期的实验中,官方给出了性能对比图:
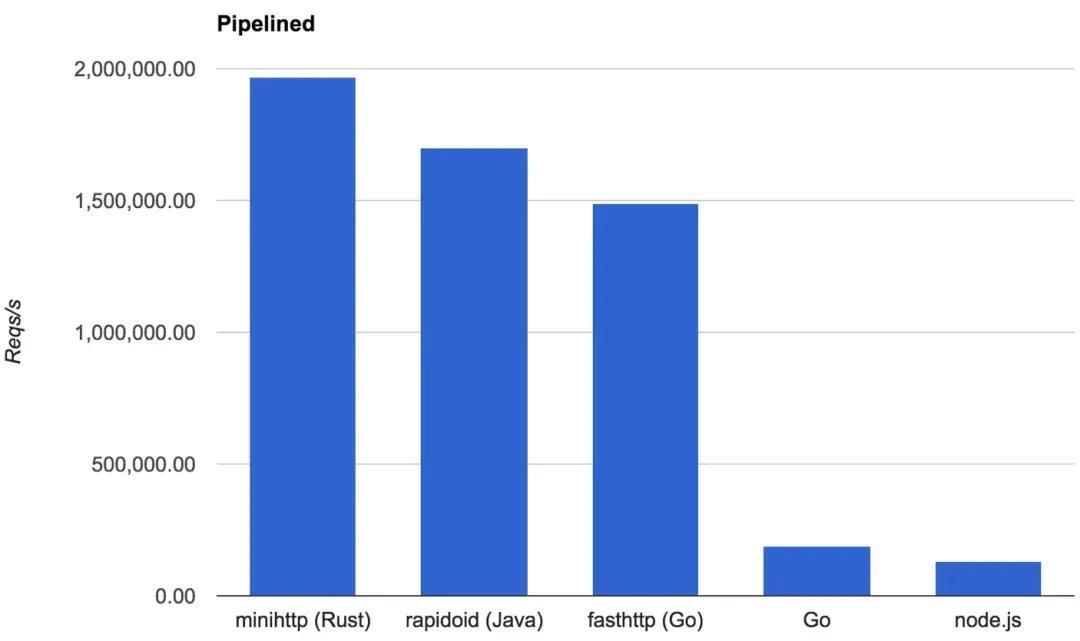
- 通用
在 rust 发展之初,社区出现了很多运行时库,但是,大浪淘沙,随着时间的流逝,Tokio 越来越亮眼,无论是性能、功能还是社区、文档,它在各个方面都异常优秀,时至今日,可以说已成为事实上的标准。新出现的rust运行时库(例如 Bytedance 的 monoio)宣传性能优于 Tokio,但还是雷声大雨点小,没有被广泛应用。
Tokio 的身影遍布在各种类型的 rust 库中,例如HTTP库(Hyper)、Web框架(Axum / Warp)、gRPC(Tonic)、TLS库(Rustls)、数据库支持(SeaORM)等。同时各大厂商也广泛使用,例如AWS、Azure、Google等。
Tokio 更加适合频繁切换的场景,例如网络服务、微服务、代理、数据库连接池、实时通信系统等。而不适合并行计算或密集计算等场景。
因此,如果需要使用 rust 中的高性能异步并发,且对于 Tokio 内部工作原理不敏感,看到这里放心使用就好了。后文将从rust语言的异步来着手,分析Tokio的架构以及具体调度的生命周期,最后分析与Nginx的对比以未来的一些方向。
rust 语言的异步
对 Future/async/await非常熟悉可以跳过。
Golang/Nodejs等语言的异步内置于语言本身,做了很好的封装且开箱即用,虽然能够简化使用但不灵活无法更改。rust作为系统级语言,并不想把异步的具体实现单一化与局限化,因此在rust std中只实现了异步的基本功能与框架(例如 Future/async/await 等),而把异步调度进行了开放,由第三方库来具体实现。
Future
Future 是 Rust 异步编程的核心抽象,它是一个状态机,通过多次 poll 推进其状态,直到完成。它与 Waker、Runtime、I/O 驱动紧密配合,构成了整个非阻塞异步系统的基础。
Future 其实就是一个trait,定义如下:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}Future 与 任务(task)的区别: Future 是 rust 原生支持的异步 trait,许多第三方异步库在此基础上将 Future 封装为 task 用来完成调度。
async
通常不会用上述的trait来创建 Future,而是结合使用 async,编译器会将被 async 修饰的函数或代码块转化为 Future。也就是说调用 async fn 的具体函数并不会立刻执行,而只是创建 Future 等待 poll 来推动状态机。
// async fn
async fn fetch_data() -> Result<String, Error> {
let resp = reqwest::get("https://example.com").await?;
Ok(resp.text().await?)
}
// async 代码块
let future = async {
// 异步逻辑
let data = expensive_computation().await;
format!("Result: {}", data)
};await
上述 Future trait中,poll 是核心方法,用于推进状态机的进行。我们的代码不会直接调用 poll,而是通过 Rust 的关键字 .await 来执行这个 Future,await 会被 rust 在编译时生成代码来调用 poll,返回 Poll(见下),如果是 Pending 则被 runtime 挂起(比如重新放到任务队列中)。当有 event 产生时,挂起的 future 会被唤醒,Rust 会再次调用 future 的 poll,如果此时返回 Ready 就执行完成。
pub enumPoll<T> {
Ready(T),
Pending,
}多级 Future 嵌套时,只有遇到类似 .await 才会推动执行,是协同式调度而不是抢占式调度(Tokio 1.x版本引入抢占机制来缓解饥饿问题,但rust原生基础是协同式调度)。因此 rust 无需提前为 Future 分配独立的栈或堆上内存,是一种零成本抽象。
总结
如下图所示,rust std 中的异步只维护 Future 以及内部方法 poll,具体的任务队列和调度方法由第三方的 runtime 来实现。每次代码执行到 .await 时会进行一次poll,poll 若 ready 则直接退出表示执行完成,poll 若遇到阻塞,则挂起等待事件池来唤醒。当有事件(例如I/O等)唤醒之后,会把该挂起 Future 封装为 task,加入到任务队列中等待调度,runtime 会不断地从任务队列中拿出任务来执行。
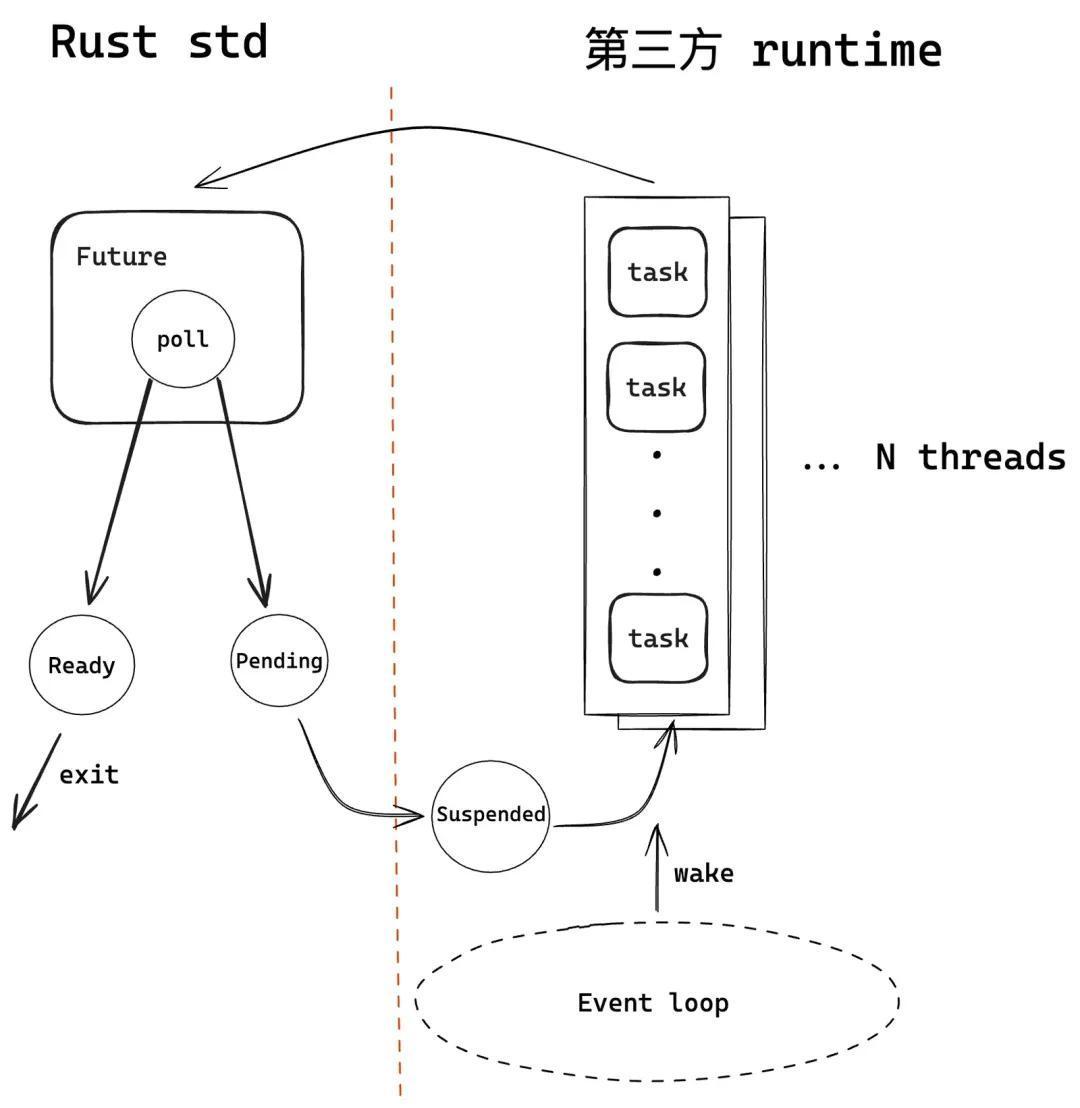
Tokio 架构与构造过程
架构
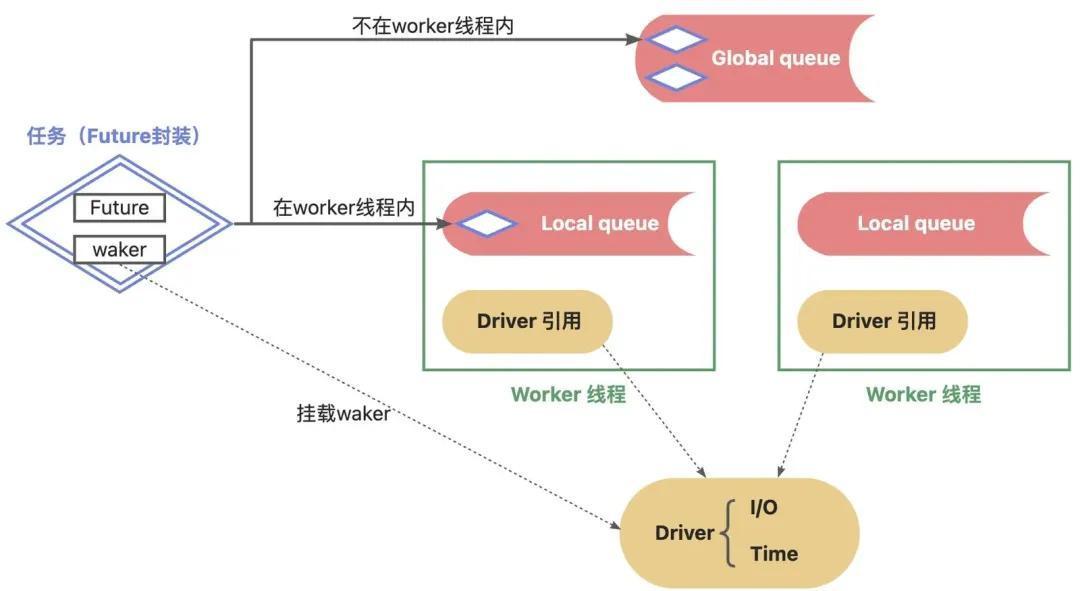
承接上文,这一部分主要介绍 Tokio 实现的 runtime架构,如下图所示:
- Tokio 会启动很多 Worker,每个 Worker 对应一个线程,并发完成异步任务。Worker 内部又主要包括 任务队列 和 Driver引用。
- Driver 是异步运行时中的“驱动引擎”,它通过操作系统提供的 I/O 多路复用机制(如 Linux 上的 epoll、Windows 上的 IOCP、macOS 上的 kqueue)来监听 I/O 事件和定时器事件,并在事件就绪后唤醒对应的 Future 继续执行。Tokio 中的 Driver 又分为I/O和Time,I/O负责监听socket和文件读写,Time负责sleep等定时任务。
- Tokio 将 Future 封装为任务,其中主要包含了waker,waker挂载到 Driver 中,当 Driver 有新事件时会回调 waker 来停止阻塞,并加入到任务队列中。
- 任务会加入到任务队列中,任务队列又分为每个 Worker 内部的,以及全局的队列。通常在 Worker 创建的任务即加入到内部队列,全局创造的加入到全局队列,全局队列的任务会被任何 Worker 线程执行到。
构造(build)
Tokio 中的 Runtime 结构体如下:
pub structRuntime {
/// Task scheduler
scheduler: Scheduler,
/// Handle to runtime, also contains driver handles
handle: Handle,
/// Blocking pool handle, used to signal shutdown
blocking_pool: BlockingPool,
}blocking线程 和 worker线程:worker线程是我们要重点关注的运行时轻量级线程,负责调度和任务执行;blocking线程是在这个过程中的所有的阻塞任务,其数量等于所有的worker线程数量+其他控制线程数量,原因是worker线程本身就是一个blocking任务,其他控制线程又包括信号与通道等。
其中 BlockingPool 是专门用来运行阻塞任务的线程池,上述解释已简单概括;Handle 维护了过程中各种handler,本文不重点关注这两项。Scheduler 是“任务池”和“调度器”的封装,也是 Runtime 最核心的部分。
想要使用 Runtime 必须要经过初始化:
tokio::runtime::Builder::new_multi_thread()
.enable_all().worker_threads(threads).thread_name(name)
.build().unwrap(),build() 即构造了 Runtime 结构,其中最重要的是 Driver 和 Worker 。
Driver 构造的过程
Driver 封装了 I/O 和 Timer 的驱动,并加入了部分机制(例如内存slab),下面以I/O Driver为例,详细说明:
pub(crate) fn new(nevents: usize) -> io::Result<(Driver, Handle)> {
let poll = mio::Poll::new()?;
#[cfg(not(target_os = "wasi"))]
let waker = mio::Waker::new(poll.registry(), TOKEN_WAKEUP)?;
let registry = poll.registry().try_clone()?;
let driver = Driver {
signal_ready: false,
events: mio::Events::with_capacity(nevents),
poll,
};
let (registrations, synced) = RegistrationSet::new();
let handle = Handle {
registry,
registrations,
synced: Mutex::new(synced),
#[cfg(not(target_os = "wasi"))]
waker,
metrics: IoDriverMetrics::default(),
};
Ok((driver, handle))
}- 初始化mio的poll,底层就是 epoll/kqueue 对象。
- 初始化waker,其是向poll注册一个特殊的事件 TOKEN_WAKEUP
- 初始化driver后同时创建hadle,可以被线程共享,用于传入worker中。
worker构造的过程
pub(super) fn create(
size: usize,
park: Parker,
driver_handle: driver::Handle,
blocking_spawner: blocking::Spawner,
seed_generator: RngSeedGenerator,
config: Config,
) -> (Arc<Handle>, Launch) {
let mut cores = Vec::with_capacity(size);
let mut remotes = Vec::with_capacity(size);
let mut worker_metrics = Vec::with_capacity(size);
// Create the local queues
for _ in 0..size {
let (steal, run_queue) = queue::local();
let park = park.clone();
let unpark = park.unpark();
let metrics = WorkerMetrics::from_config(&config);
let stats = Stats::new(&metrics);
cores.push(Box::new(Core {
tick: 0,
lifo_slot: None,
lifo_enabled: !config.disable_lifo_slot,
run_queue,
is_searching: false,
is_shutdown: false,
is_traced: false,
park: Some(park),
global_queue_interval: stats.tuned_global_queue_interval(&config),
stats,
rand: FastRand::from_seed(config.seed_generator.next_seed()),
}));
remotes.push(Remote { steal, unpark });
worker_metrics.push(metrics);
}
let (idle, idle_synced) = Idle::new(size);
let (inject, inject_synced) = inject::Shared::new();
let remotes_len = remotes.len();
let handle = Arc::new(Handle {
task_hooks: TaskHooks::from_config(&config),
shared: Shared {
remotes: remotes.into_boxed_slice(),
inject,
idle,
owned: OwnedTasks::new(size),
synced: Mutex::new(Synced {
idle: idle_synced,
inject: inject_synced,
}),
shutdown_cores: Mutex::new(vec![]),
trace_status: TraceStatus::new(remotes_len),
config,
scheduler_metrics: SchedulerMetrics::new(),
worker_metrics: worker_metrics.into_boxed_slice(),
_counters: Counters,
},
driver: driver_handle,
blocking_spawner,
seed_generator,
});
let mut launch = Launch(vec![]);
for (index, core) in cores.drain(..).enumerate() {
launch.0.push(Arc::new(Worker {
handle: handle.clone(),
index,
core: AtomicCell::new(Some(core)),
}));
}
(handle, launch)
}为 Tokio 多线程运行时创建一组 Worker 线程,每个 Worker 都绑定了一个本地任务队列(Local Queue)、I/O 和定时器驱动(Driver),并准备好参与异步任务调度。其中:
- 创建本地任务队列和任务窃取队列。本地任务队列是一个无锁双端队列,可以用于其他线程的窃取,有关任务窃取在后文详细介绍。
- 也创建了Handle,该Handle可以用来提交新任务、同步执行 Future和提交阻塞任务等。
- (隐式)通过参数传入 Driver,在线程中即可以通过 Driver 和 Driver Handle 完成 Wake 挂载、I/O事件、推进定时器等。
- 每个Worker 会被传入到 Launch,启动调度循环(无限循环从队列中拿出任务poll)。
Tokio task 生命周期
构造出基本的 runtime 架构后,就等待有任务被加入到 runtime 中被调度与执行,这一部分详细说明任务从被构造到执行完成的流程。
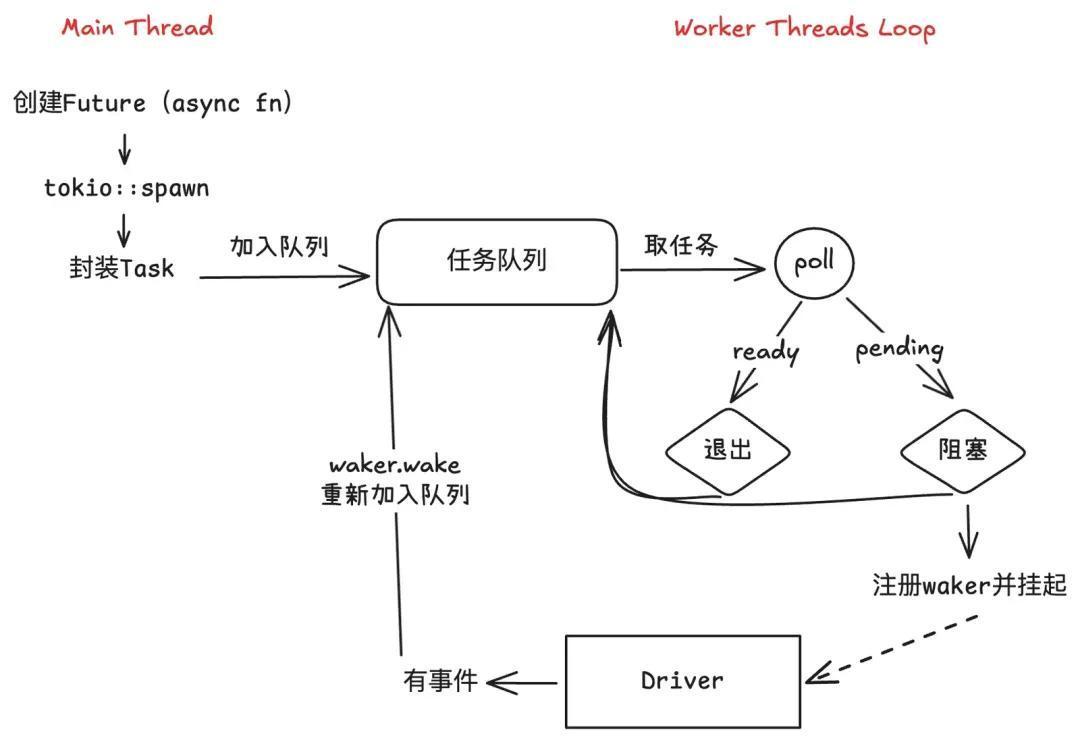
如上图所示,Worker 在创建后执行调度循环,不断地从任务队列中取任务,执行poll,若结果为阻塞则注册waker并挂起,之后取新任务poll。当 Driver 有新事件时会调用 waker 来唤醒任务,重新加入到任务队列中待新一轮调用。
任务队列
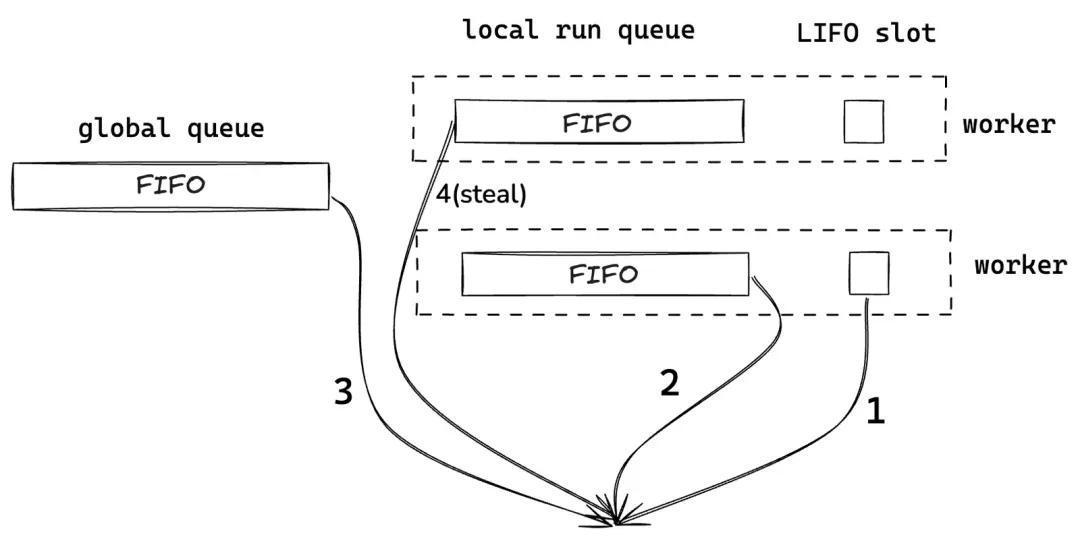
- 全局队列(global queue) 有且仅有一个,全局队列是必要的,因为有些任务不属于某个worker,只能加到全局队列中。全局队列是FIFO的设计架构。
- 只有全局队列就会面临所有 worker都从全局队列拿任务,需要加锁影响性能。因此每个worker一个维护本地队列(local run queue),在worker内产生的任务会直接加到自己的本地队列中。
- 本地队列也是FIFO的,保证了公平性,但是不同任务之间的资源会被割裂,调度会浪费CPU缓存,因此又多增了LIFO slot。LIFO slot可以理解为本地队列中的“特权”任务,例如某些任务spawn出新的任务,且该新任务对旧任务有大量的资源依赖,此时可以将新任务加入到LIFO slot中;或者某些任务通过信号通知其他任务可以被执行,此时该任务可以被加入到LIFO slot中,避免排队带来的延迟。由于LIFO slot会带来不公平的问题,因此只有一个槽位,被占就只能到本地队列的末尾排队。
- 任务窃取:当本地和全局队列中都没有要执行的任务时(此时该worker已经空闲),会尝试窃取其他worker的本地队列的任务。这一机制保障了线程的负载均衡,同时提高系统整体的运行效率。窃取时会从末端开始,因此不会干扰worker的正常进行,该队列也无需加锁。
最终,任务队列的执行顺序是:本地LIFO slot --->> 本地任务队列 --->> 全局任务队列 --->> 窃取其他线程的任务。
任务饥饿问题
饥饿问题有以下两种场景:
1.某任务是密集计算型任务,不断占据cpu而不释放;
2.本地任务更新太快太频繁,全局任务无法被执行到;
第一种场景,Tokio 从 1.x开始,引入了抢占式调度来缓解饿死问题,简单来说就是会定期强制任务挂起来让出资源。但是需要说明的是,这种场景本质上和rust的异步并发冲突,更加推荐使用tokio::task::spawn_blocking,来将任务转化为并行计算任务。
第二种场景经常会遇到,本质上是由于三种不同的队列有优先级,可能会导致低优先级的队列被饿死。例如I/O频繁的TCP连接会不断地加入到本地队列,而无法处理全局队列任务。Tokio 的解决的方法是为每个任务加入循环次数,当其循环加入队列次数超过一定上限后会先搁置,优先处理低优先级(例如全局队列)的任务。
总之,Tokio 设计了相关的机制来平衡公平性和效率,同时还有一些其他算法或异步runtime优化了部分过程,取得了更好的效果(例如horaedb(Apache、Ant)、Monoio(bytedance))。虽然并非完美,但是各方都在努力完善公平性和性能,这或许就是rust设计开放runtime的初衷。
其他
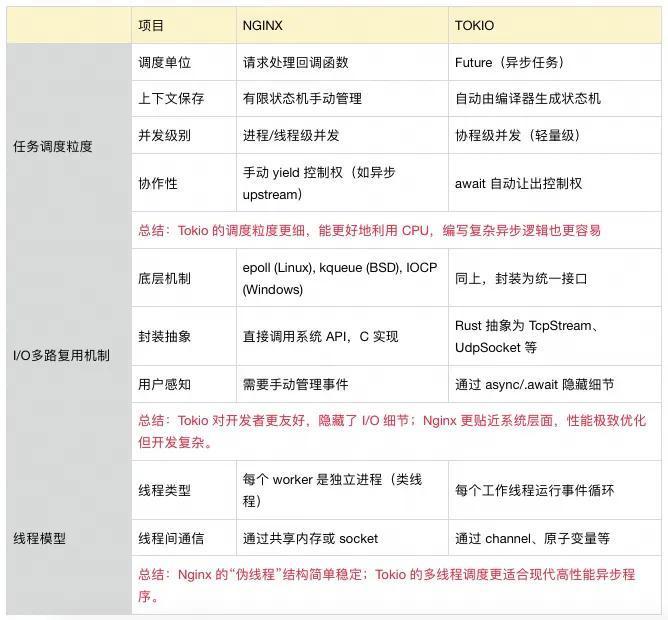
与Nginx的调度对比
Nginx采用 多worker进程单线程 + 非阻塞I/O + 事件驱动 的模型。
- 多进程单线程:最开始时,Nginx会创建多个worker进程,每个进程创建后即可以视为是完全独立的存在,后续的任务执行和资源占用互不干预。所有的worker进程会统一绑定监听某个或某些端口,当某端口有数据时,操作系统会分配给某个worker。(分配方法又分为 SO_REUSEPORT 和 accept_mutex机制,这里的详细机制后续会出一篇文章来详细说明,简单来说就是 SO_REUSEPORT 减少了惊群效应,去除了锁,提高了CPU负载均衡,但是会增加时延不均衡性)。
- 事件驱动:当某个worker 接收到数据后,会将其注册到epoll事件中,并在相应的阶段调用相应的回调函数,主进程(即线程)会轮询执行这些事件回调。主进程是串行执行,无抢占式调度和锁的开销。
- 非阻塞I/O:系统采用非阻塞I/O与多路复用机制(即epoll)来完成高并发处理。
两者的对比如下:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java