
DeepSeek大模型Prompt工程深度实践
1 概述
1.1 案例介绍
Prompt工程技术即提示工程技术(Prompt Engineering), 是一种通过精心设计输入文本即提示(Prompt)来引导大语言模型(LLM)生成高质量输出的技术。它属于自然语言处理(NLP)领域,Prompt是用户向模型提供的输入指令,通常以自然语言文本的形式出现,核心目标是优化人机交互效率,使模型更精准地理解任务需求并生成符合预期的结果,而无需重新训练或微调模型。Prompt工程是当前 AI 工程化落地的核心技能,广泛应用于客服、编程助手、数据分析等场景。
本案例通过开发者空间部署客户端调用DeepSeek V3模型API,并使用Prompt工程调优技巧以实现控制模型的输出。
通过本案例可以掌握Prompt工程的样本提示、思维链提示和链式提示技巧去控制大模型输出,熟悉提示工程技术的运用。
1.2 案例流程
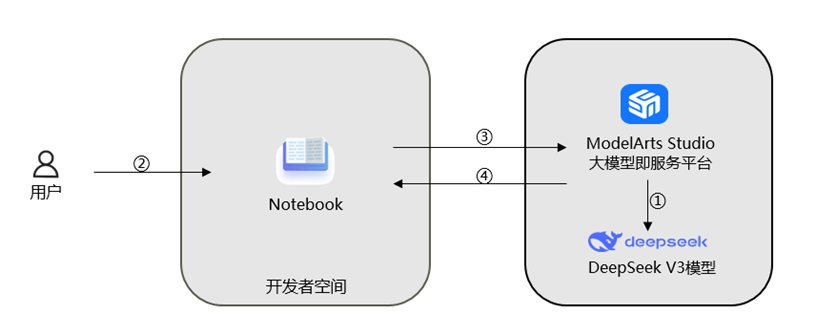
说明:
① 在ModelArts Studio大模型即服务平台中领取DeepSeek V3模型;
② 登录开发者空间,启动Notebook;
③ Notebook运行DeepSeek V3 API调用程序;
④ 调用模型进行Prompt工程实践。
1.3 资源总览
本案例预计花费总计0元。
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
| 开发者空间—Notebook | NPU basic · 1 * NPU 910B · 8v CPU · 24GB euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook | 免费 | 30 |
2 Prompt工程实践
2.1 前置操作
参考“DeepSeek模型API调用及参数调试(开发者空间Notebook版)”案例的第2章节完成DeepSeek V3模型领取和启动Notebook。
参考“DeepSeek模型API调用及参数调试(开发者空间Notebook版)”案例的3.1小节完成参数声明。
2.2 构建目标文章
我们需要一个文章样本作为调优的目标,可以通过调用DeepSeek模型API生成一篇文章,内容要求是3个人物,2个情节500字以内的短篇小说,在新的执行框中输入如下代码并运行。
import requests
import json
class TextGenerationClient:
def __init__(self, api_url, api_key):
self.api_url = api_url
self.api_key = api_key
def generate_text(self, payload):
headers = {
"Content-Type": "application/json",
'Authorization': f'Bearer {self.api_key}'
}
response = requests.post(self.api_url, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
return response.json()['choices'][0]['message']['content']
else:
raise Exception(f"Error: {response.status_code} - {response.text}")
client = TextGenerationClient(api_url,api_key)
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": "你是一个短片小说创作者,写一篇短篇小说,500字以内"},
{"role": "user", "content": "3个人物,2个情节"}
],
"max_tokens": 800,
"top_p": 1,
"temperature":1,
}
generated_text = client.generate_text(payload)
print(generated_text)
content = generated_text运行后结果如下,每个人运行结果不尽相同,内容仅作参考:

2.3 构建基础问答Prompt
下面通过构建一些基础问答的提示词来进行输出内容的控制。比如这里我们提问“根据文章回答段誉干了什么”测试模型输出,在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,以下是文章{content}"},
{"role": "user", "content": "根据文章回答段誉干了什么"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 0.3,
}
generated_text = client.generate_text(payload)
print(generated_text)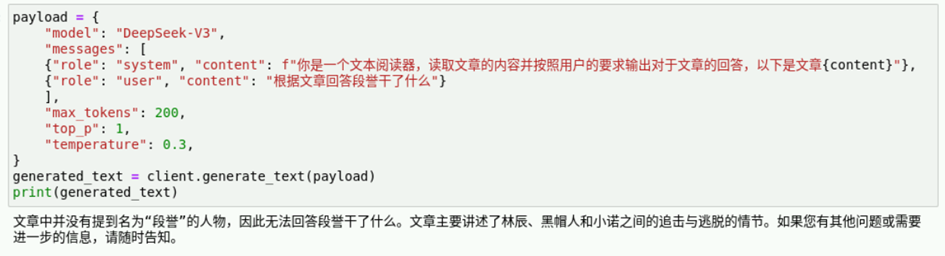
继续提问“根据文章回答:文章中有几个人物”测试模型输出,在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文章中有几个人物"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)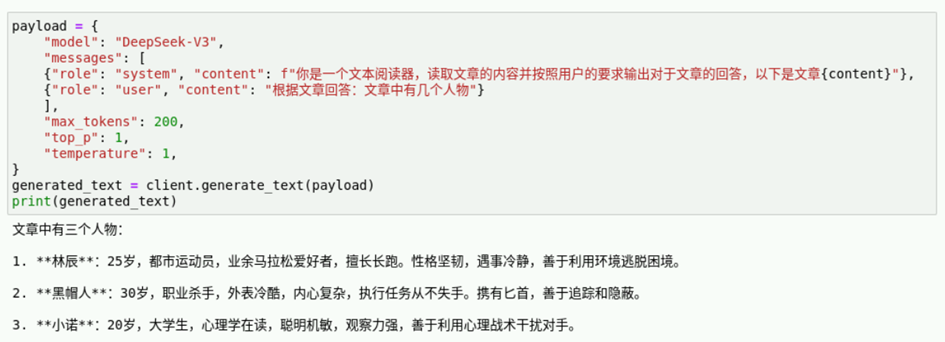
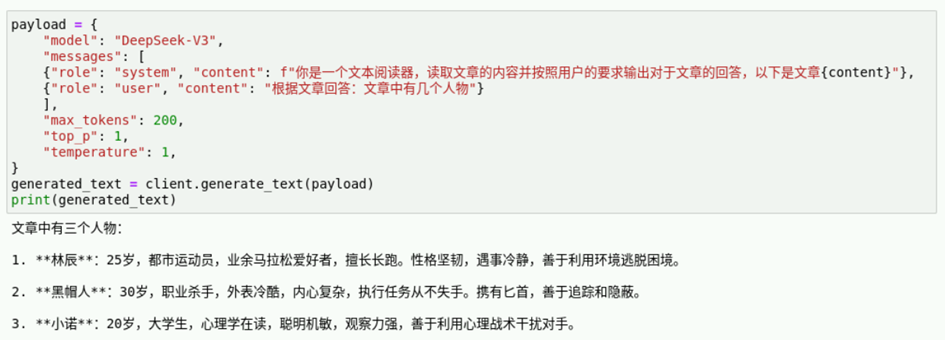
接下来我们使用一个小陷阱来测试模型输出的准确性,比如文章中是三个人物,但是我们提问“根据文章回答:文中的四个主角是什么关系” 测试模型输出,在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文中的四个主角是什么关系"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)参考运行结果如下,可以看见模型对提问的错误并没有指出,然而在我们实际使用的场景中,例如客服问答,是需要识别提问并回答的,因此,我们需要通过Prompt工程技巧规范模型的回答。
2.4 Prompt工程技术控制模型输出
下面我们将介绍如何使用样本提示(Example Prompting)、思维链提示(CoT)和链式提示(Chain Prompting)3种不同的技术来控制模型的输出。
2.4.1 样本提示
样本提示(Example Prompting)是通过提供少量输入-输出示例(即样本),引导模型模仿示例的格式或逻辑生成回答。核心特点是依赖具体的输入-输出对(如“问题→答案”),不强调推理过程。模型从示例中学习任务规则(如翻译格式、分类标准、文本风格),适用于格式固定的任务,需要快速对齐输出风格或者结构的场景。
例如先给出样本提示问题:
- 输入:“悲伤的 →反义词是什么?”
- 输出:“悲伤的反义词是快乐。”
- 输入:“大 → 小的反义词是什么?”
- 输出:“小的反义词是大。”
然后再输入:“高 →” 就会输出:“高的反义词是矮。”
在本案例中我们设定样本使用样本提示上下文“文章:a,b,c,d,e是五个人物,他们之间是亲属关系;提问:文章的6个人物,他们是什么关系;回答:文章中只有五个人物,他们是亲属关系”来进行输出内容的控制。在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,\
上下文:“文章:a,b,c,d,e是五个人物,他们之间是亲属关系;提问:文章的6个人物,他们是什么关系;回答:文章中只有五个人物,他们是亲属关系” \
以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文中的四个主角是什么关系"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
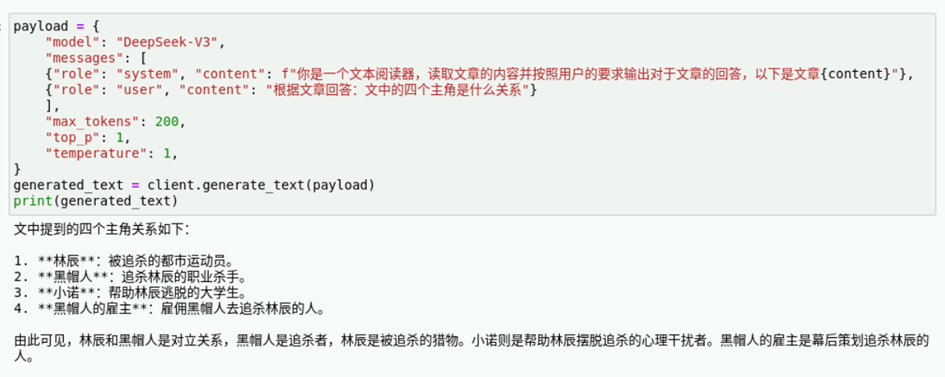
print(generated_text)结果如下,模型根据上下文提示回答了人物之间的关系,但是没有识别到问题的陷阱,进行主角人数纠正。
2.4.2 思维链提示
思维链提示(Chain of Thought,CoT)是一种引导语言模型通过分步推理解决问题的方法。它的核心思想是让模型像人类一样展示思考过程,将复杂问题拆解为多个逻辑步骤,输出一系列中间步骤,从而得出所需的答案。这种方法显著提升了模型在数学、逻辑和复杂文本任务中的表现。
在使用过程中可以通过添加引导词“请逐步思考”、“让我们一步步分析”来引导模型去思考,模拟人类认知形式,让推理过程更接近真实思维,提升答案的可靠性。
传统提问和思维链提示对比示例如下:
| 类别 | 传统提问 | 思维链提示 |
| 问题 | 为什么夏天柏油马路看起来像有水渍,走近却消失了? | 请逐步解释:夏天柏油马路上出现‘水渍’的物理原理是什么?走近后为何消失? |
| 模型回答 | 这是光的折射现象。 | 夏季高温使路面附近的空气温度梯度变化大; 光线穿过不同密度的空气层时发生折射; 折射导致光线路径弯曲,形成类似水面的镜面反射虚像; 当观察者靠近时,光线入射角改变,虚像消失。 |
在本案例中我们可以通过让大模型“逐步思考用户提出问题并逐一回答”来进行输出内容的控制,在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,\
你需要逐步思考用户提出问题并逐一回答 \
以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文中的四个主角是什么关系"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)参考运行结果如下,可以看见模型在进行人物关系推理时,进行了更多的思考。但是仍旧没有识别出实际文章中只有三个人物而提问中是“四个主角”这个陷阱,需要再进行提示词的引导。

2.4.3 链式提示
链式提示(Chain Prompting)的本质是任务分解,所以在进行链式提示之前,我们需要思考我们的任务应该怎么拆分。我们的目标是让模型能够先思考用户的提问和模型所理解的事实或者读取的文件之间的匹配程度。然后再就用户的提问进行回答,所以我们可以拆分成4个子任务。
子任务1:模型提取信息。
在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,\
以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文中有几个人物,他们是什么关系"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)
info = generated_text #提取的信息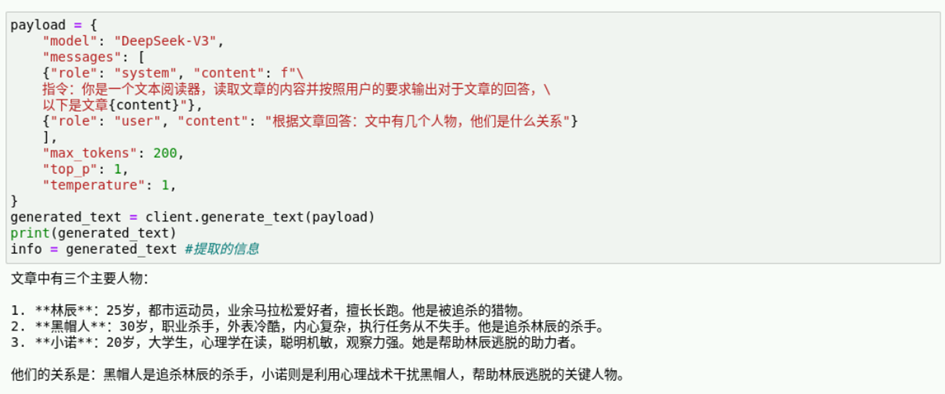
子任务2:根据模型获取的信息匹配用户的问题,找出用户问题中的错误。
在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:根据提问对比已知的信息,找出提问的错误,并输出错误的点”\
以下是已知的信息{info}"},
{"role": "user", "content": "提问的问题是:“文中的四个主角是什么关系”"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 0.3,
}
generated_text = client.generate_text(payload)
print(generated_text)
error = generated_text #提问的错误

子任务3:就用户的题问进行回答。
在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:你是一个文本阅读器,读取文章的内容并按照用户的要求输出对于文章的回答,\
以下是文章{content}"},
{"role": "user", "content": "根据文章回答:文中的四个主角是什么关系"}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)
answer = generated_text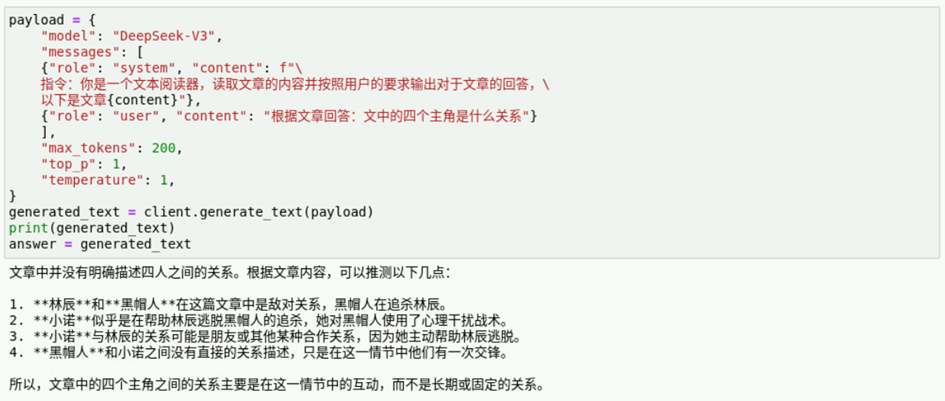
子任务4:根据错误信息,以及模型的回答整合最终回答。
在新的执行框中输入如下代码并运行。
payload = {
"model": "DeepSeek-V3",
"messages": [
{"role": "system", "content": f"\
指令:根据错误信息,并修改错误的回答,并按照输出格式化输出正确的回复 \
上下文:以下是错误信息{error}, \
以下是需要修改的错误的回答{answer} \
输出格式化:问题:\
正确的答案应该是:\
"},
{"role": "user", "content": ""}
],
"max_tokens": 200,
"top_p": 1,
"temperature": 1,
}
generated_text = client.generate_text(payload)
print(generated_text)

接来下我们串起这个流程,在新的执行框中输入如下代码并运行。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java