
详解 MySQL Query Cache 使用与实现
一、背景介绍
查询缓存(Query cache,简称QC)是一种数据库优化技术,用于存储查询结果,以便在相同查询再次执行时能够快速返回结果,而无需重新执行查询。MySQL也有QC对应实现,但因其实现存在并发性能差、缓存命中率低等问题,该特性在MySQL 5.7.20标记为不推荐使用,在MySQL 8.0.3里被删除。
QC对于特定场景可以显著提升性能,TaurusDB保留QC并对其并发性能进行了优化。本文基于MySQL 8.0.2代码对QC的使用与实现进行分享,介绍TaurusDB如何进行优化。
二、Query Cache使用
在使用QC特性后,MySQL服务端会缓存符合条件(见文末链接)的查询与查询结果。
接收查询后,不会立刻解析和执行,而是优先从QC中检索结果返回。
QC是全局的,不同session可以共享QC功能,更详细介绍参考文末官网链接。
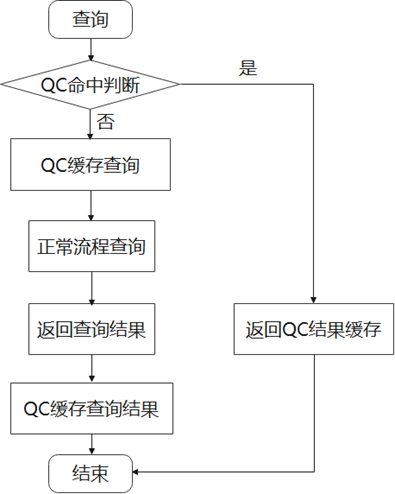
图1 QC缓存、命中流程图
- QC相关系统参数
相关参数都包含query_cache关键字,用如下SQL查询。
mysql> show variables like '%query_cache%';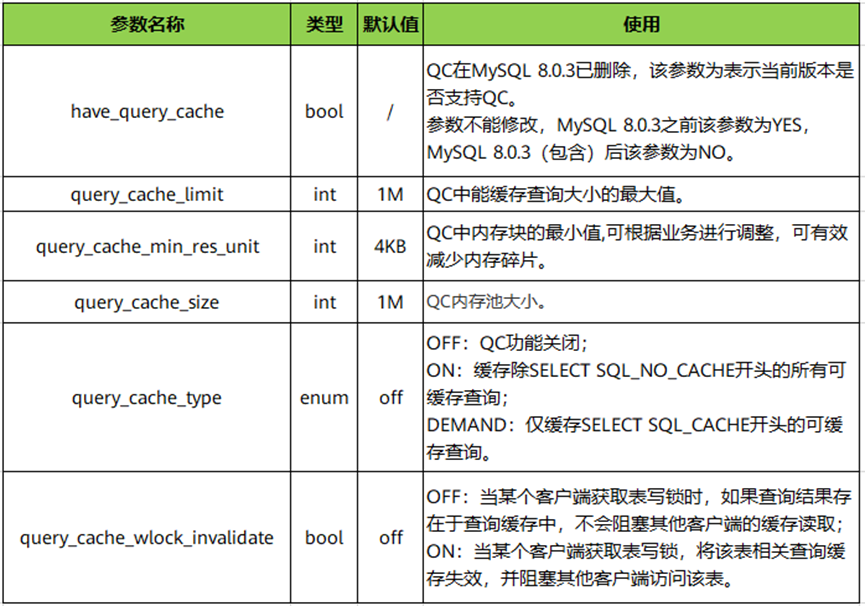
表1 QC系统参数说明
QC功能开启前提query_cache_type!=off且query_cache_size!=0,具体参数使用见官网说明。
- QC相关统计参数
相关参数都包含Qcache关键字,用如下SQL查询。
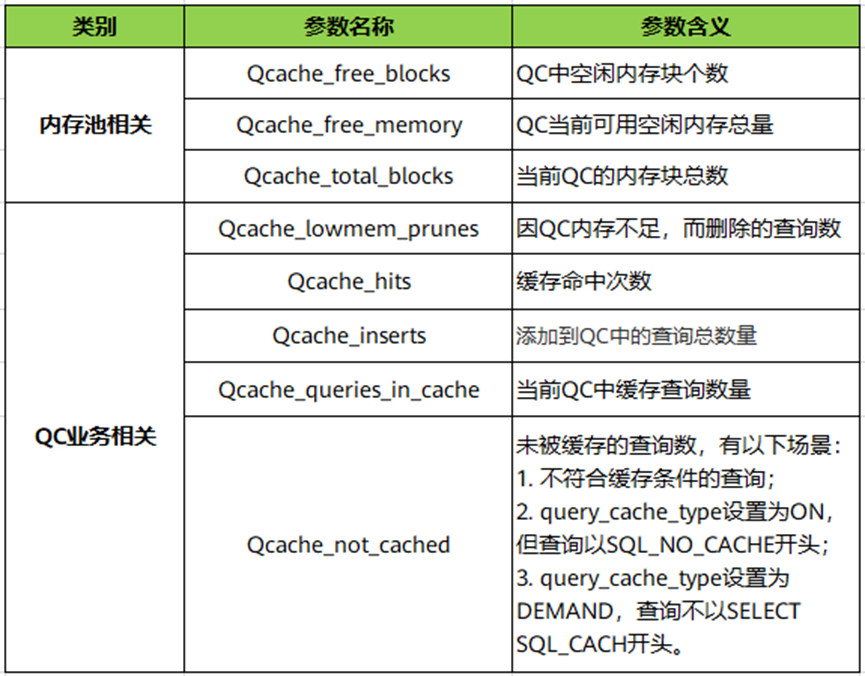
表2 QC统计参数说明
QC底层是一个内存池,所以包含内存池状态参数。上述参数反应当前QC的使用状态,以供使用者调整优化。如:
(1)Qcache_hits/(Qcache_hits+Qcache_inserts)可视作缓存命中率,过低说明QC功能对当前业务作用不大,可考虑关闭QC。
(2)Qcache_free_block/Qcache_total_block可视作缓存碎片率,过高可使用flush query cache进行碎片整理或根据业务适当减小query_cache_min_res_unit。
三、源码分析
先对QC业务常见场景进行概览,分为以下三种:
第一种,缓存查询,将查询结果存储到 QC 中。
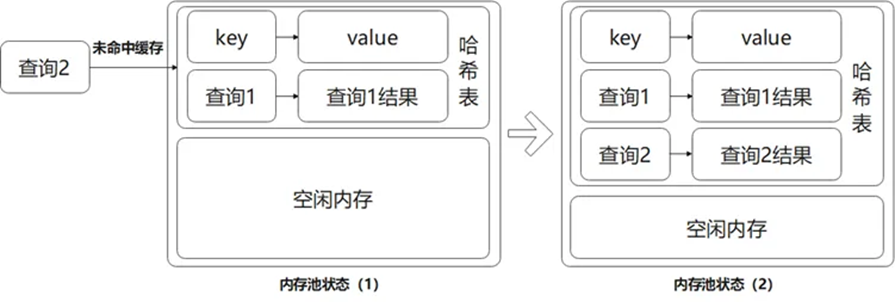
图2 内存池状态(1)
第二种,查询命中,从 QC 中直接返回查询结果。
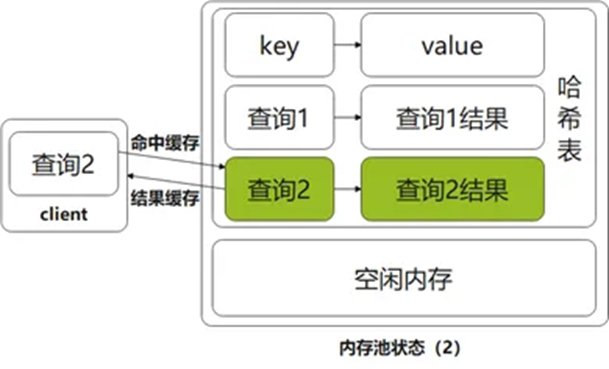
图3 内存池状态(2)
第三种,查询失效。发生影响缓存结果正确性的操作时(如相关表DDL、DML),对应缓存失效。
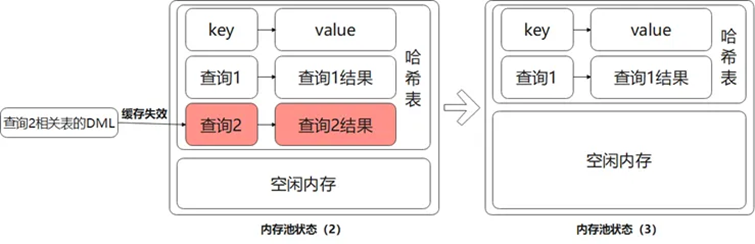
图4 内存池状态(3)
QC的业务实现和内存池有着密切的关系。为了更好理解QC实现,后文将从内存池设计和QC业务实现两方面进行介绍。需要注意,两者在代码层面不是割离的,都在一个全局对象Query_cache中实现。在设计层面,内存池的方案选择也会受到QC业务影响。
内存池设计
内存池的实现,会先申请一整块连续内存,但在处理申请、释放内存的请求后,整块内存逐渐会被分割为多个内存块(block)。根据内存块是否正在使用,可分为空闲内存块(free block)与非空闲内存块(used block)。
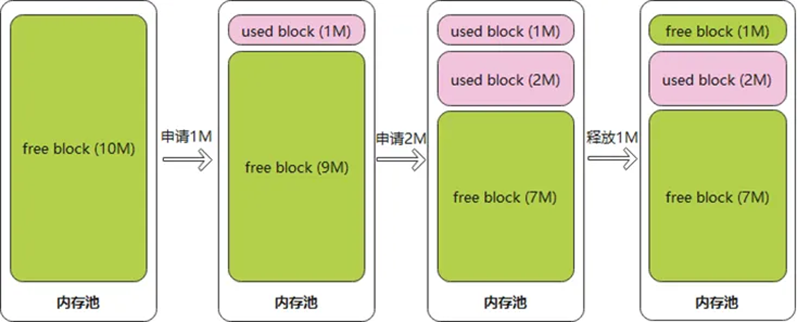
图5 内存池变化图
通过图5可以发现,内存池核心接口是内存的申请与释放,并且在内存池使用过程中会出现内存碎片化问题。
那么申请内存时,如何找到内存池中不小于所需大小的空闲块?如何知道各内存块的大小和空闲状态?如果有多个合适的空闲块,如何选择?如果选中的空闲块比申请的大,多余的空间(内部碎片)怎么处理?释放内存时,又该如何处理释放的内存块?
下面将分析QC如何解决上述问题,同时缓解内存的碎片化。
问题一:空闲内存块管理
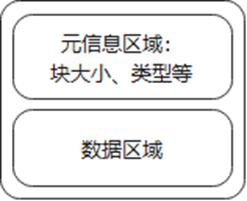
图6 内存块抽象图
如图6所示,QC内存池将内存块大小、类型等元信息存储在块头部。用数组(bins)根据块大小对空闲内存块进行管理。
class Query_cache {
Query_cache_memory_bin *bins;
};
// 一个bin元素维护一条空闲内存块链表,链表有如下特征(设当前数组下标为i):
// 1、链表管理块大小范围在bins[i].size ~ bins[i-1].size之间;
// 2、链表中空闲内存块从小到大有序;
// 3、链表为双向链表,并且头尾相连。
struct Query_cache_memory_bin {
Query_cache_block *free_blocks; // 空闲内存块链表
ulong size; // 链表管理块大小范围下限,最小为512B
uint number; // 当前链表长度
};数组长度与成员赋值根据内存池大小经过内部算法确定,算法有如下特征:
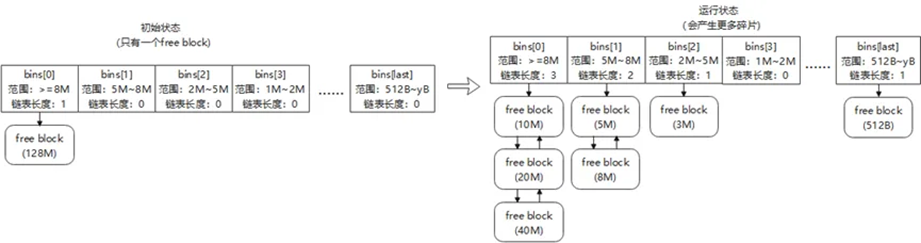
图7 free block管理
(1)数组成员下标越小管理的空闲内存块大小越大。如图7左边所示,bins[0]管理空闲内存块大小大于bin[1]管理的。
(2)数组成员下标越大管理的空闲内存块大小范围越小。如图7左边所示,bins[1]管理空闲内存块是5-8M,范围是3M,而bins[3]管理空闲内存块是1-2M,范围是1M)。
考虑到小对象往往会分配更频繁,越可能是性能瓶颈,所以算法会生成更多bin元素对小内存块进行更加细致的管理。
设当前内存池大小为128M,经过一段时间运行后,如图7右边所示(链表首尾相连,图中未画)。
问题二:空闲内存块选择
若申请大小为6M,当前有多个内存块符合申请大小。如图8所示,通常有如下选择策略:
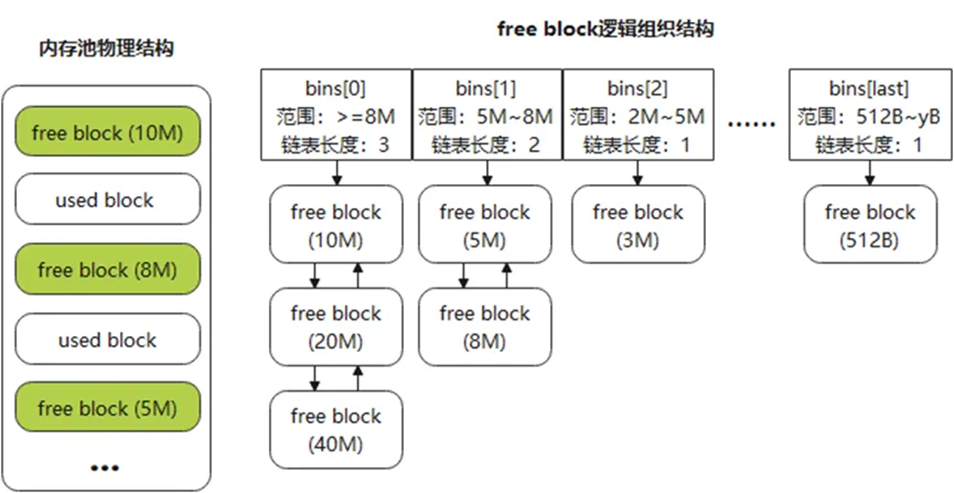
图8 内存池物理、逻辑结构
第一种策略,first fit。
在物理上进行遍历,返回第一个不小于申请大小free block(10M)。此策略寻找空闲内存块时间比较短,但块大小可能超出6M较多,易造成内存碎片。
第二种策略,best fit。
best fit返回最小不小于申请大小free block,可利用bins数组查找:
(1)根据申请大小找到对应的bin元素(6M对应bins[1])。
(2)遍历bin中free block链表,因链表有序,返回第一个不小于申请大小的块(8M)。
初看best fit是一个不错的方案,但如果free block链表长度过长,时间会线性增加。因此,QC在best fit基础上进行优化,将第二步的链表遍历修改为:从链表头向后(从小到大)遍历最多5次,若找到符合要求内存块返回,否则从链表尾向前(从大到小)遍历最多5次,返回这五个内存块中最小符合要求的内存块。
问题三:内部碎片处理
若申请8M内存块,但写入数据只有6M,则会出现了2M的内部碎片,如图9所示。若不处理,将影响内存利用率。
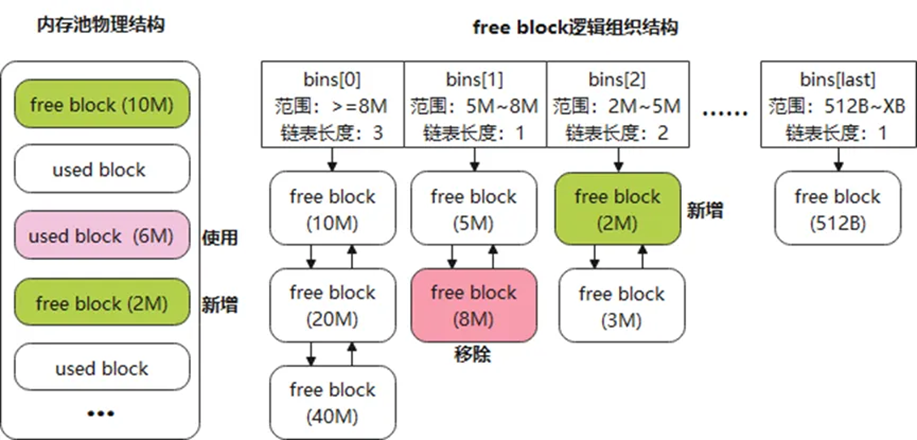
图9 内部碎片处理
QC的处理方式:如果内部碎片不大于512B不进行处理,否则将内部碎片从内存块中分离,视作新增的free block纳入bins中管理。
问题四:处理释放的内存
内存释放除了需要重置内存块后纳入对应bin管理,还需合并相邻的空闲内存块,以减少内存碎片。
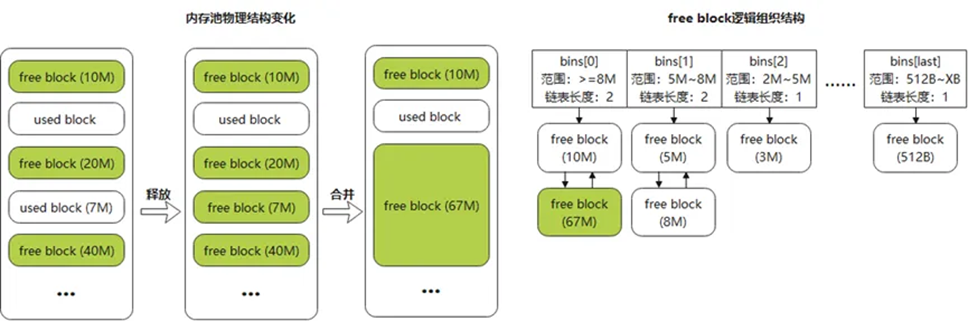
图10 内存释放处理
如图10中所示,若释放内存块大小为7M,物理相邻内存块也是空闲,从左到右即为内存池的变化过程。
QC业务设计
关键数据结构
关键数据结构就是前文常提的抽象概念内存块,对应代码中的Query_cache_block。
struct Query_cache_block {
block_type type; // 块类型,主要可分为query\table\result block
ulong length, used; // 块大小、块已使用大小
Query_cache_block *pnext,*pprev, // 块物理前后指针
*next,*prev; // 块逻辑前后指针,不同块类型有不同使用方式
int n_tables; // 块中Query_cache_block_table数组个数
// 获取第n个Query_cache_block_table
inline Query_cache_block_table *table(TABLE_COUNTER_TYPE n);
inline uchar* data(); // 获取块的data起始地址
inline Query_cache_query *query(); // 将data以query block方式解析
inline Query_cache_table *table();// 将data以table block方式解析
inline Query_cache_result *result();// 将data以result block方式解析
};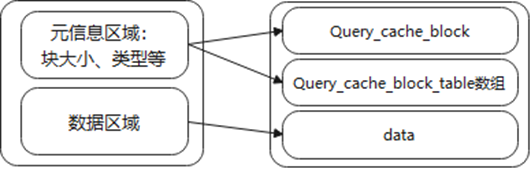
图11 block内存结构
图11中,元信息中Query_cache_block_table数组,作用是维护block之间关联关系,具体用法后文分析。
根据data存储内容不同,block主要被分为三种类型query,table,result block。
我们用一个简单SQL的执行作为例子,如查询:select * from t1 join t2 where t1.a = t2.a,来探究一个查询在内存池中对应哪些block。
- query block
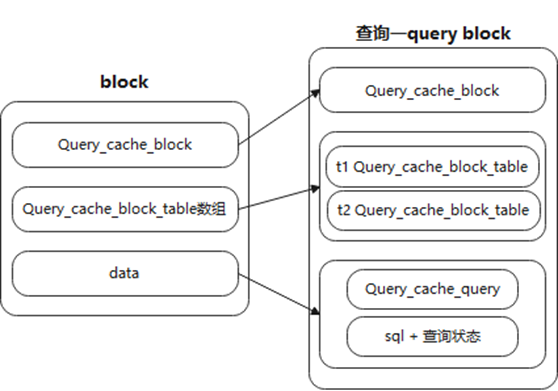
图12 query block结构图
图12中,一个查询对应一个query block,data记录查询SQL与查询状态(影响输出参数)。
query block中有t1、t2的Query_cache_block_table链表节点,与t1、t2的table block关联(table block中解释关联作用)。
Query_cache_query记录元信息,如查询对应的result block指针。
- table block
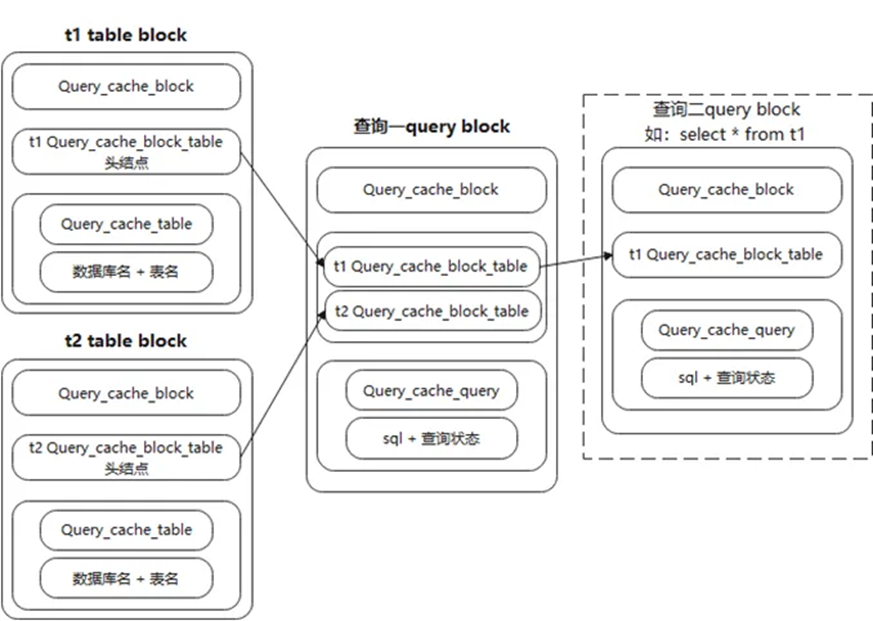
图13 table,query block关系图
图13中,一张表对应一个table block,data记录数据库名和表名。
table block有Query_cache_block_table链表头节点与相关的query block相连,方便后续通过库表名找到相关query block。
- result block
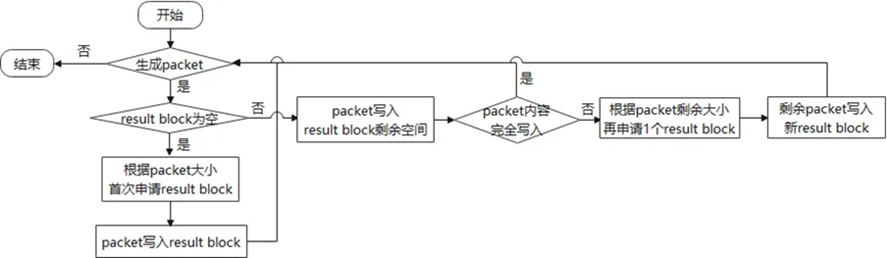
图14 查询结果写入流程图
图14中,result block的data记录MySQL返回客户端的packet内容.
因为packet的发送可能分为多次,所以result block在初次申请内存时,无法确定最终大小,这会导致一个查询可能对应的多个result block的情况,同一个查询的result block之间使用指针维护一个链表。
当查询一对应2个result block时,table,query,result block之间对应的关系图如图15所示。
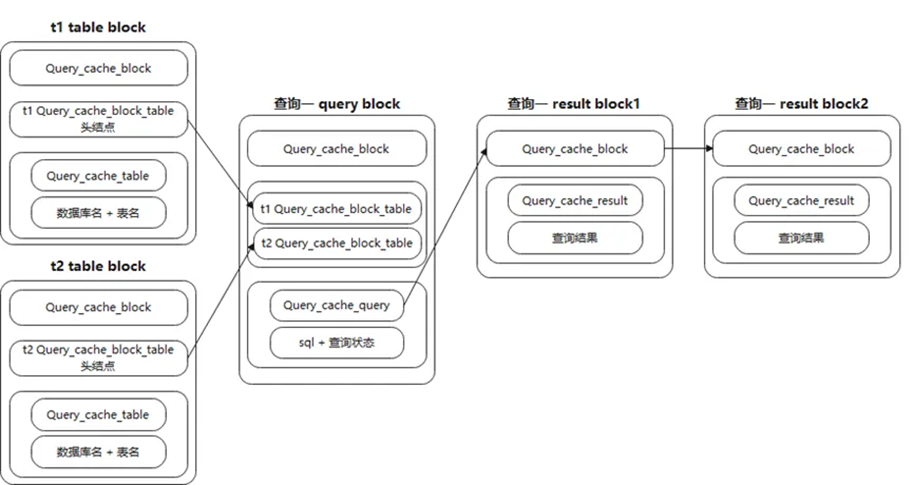
图15 table,query,result block关系图
QC场景场景实现
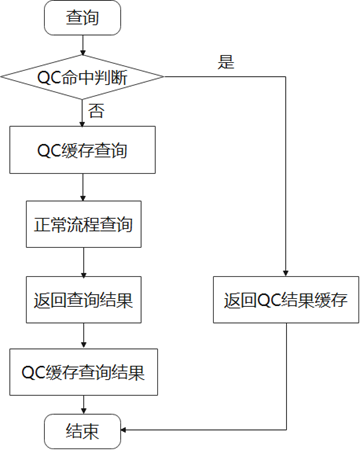
图16 QC流程图
- 缓存查询实现
对应图16中,若QC未命中分支,主要有2个步骤:
步骤一,QC存储查询内容。
通过调用Query_cache::store_query,创建query,table block,并维护对应的哈希表和链表。
步骤二,QC存储查询结果。
通过调用query_cache_insert,基于MySQL向客户端返回的packet内容生成result block,可参考查询结果写入流程图(图14)。
- 缓存命中实现
对应图16中,若QC命中分支,主要有1个步骤,即QC命中判断:在解析前调用Query_cache::send_result_to_client,使用query block哈希表来判断查询是否命中。若命中则直接调用函数net_write_packet,对客户端发送缓存结果。
- 缓存失效实现
缓存失效场景,相关表发生ddl、dml、内存池不足导致缓存失效等。参考图15(table,,query,result block关系图),dml的缓存失效流程如下:
(1)通过库表名在table block的哈希表中找到table block;
(2) 通过table block中Query_cache_block_table链表头找到与此表相关query block;
(3)根据query block的result block指针,找到对应的result block;
(4)对上述block进行释放。
其他设计
- 内存池整理命令
QC提供了命令FLUSH QUERY CACHE
,可手动触发内存池空间整理。分为两个步骤:
第一,pack cache,将free block移动到内存池底部。
第二,join result,将属于同一查询的多个result block(result1.1,result1.2)进行合并,此操作将导致内存碎片重新出现,需再进行一次pack cache。
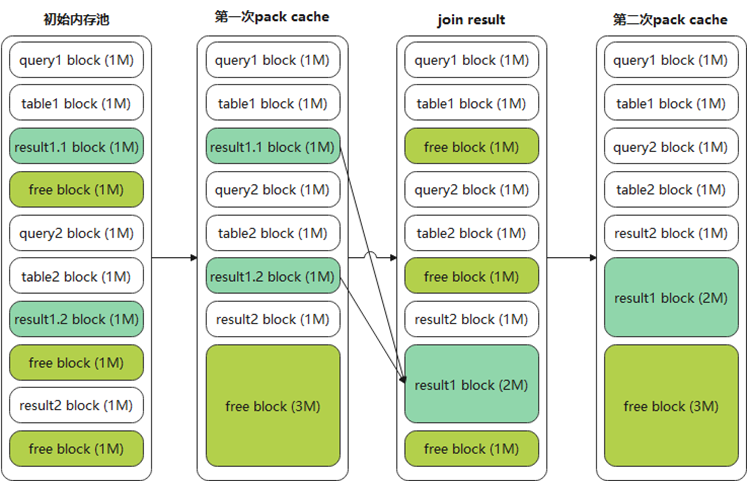
图17 内存池空间整理
如图17所示,整理后内存池只有1个free block,也对result block进行了整合。
- 并发处理
为了应对MySQL的并发查询,QC内存池需设计并发策略来保证QC业务的正确性。
QC锁
要求所有对内存池的操作(插入、删除、查询)需提前持有QC锁。其实质是将并发操作序列化,以保证正确性;
查询结果写入持锁优化
根据图14(查询结果写入流程图),对查询结果写入的持锁范围进行了优化——不需全程持锁,在进行result block写入时持锁即可。
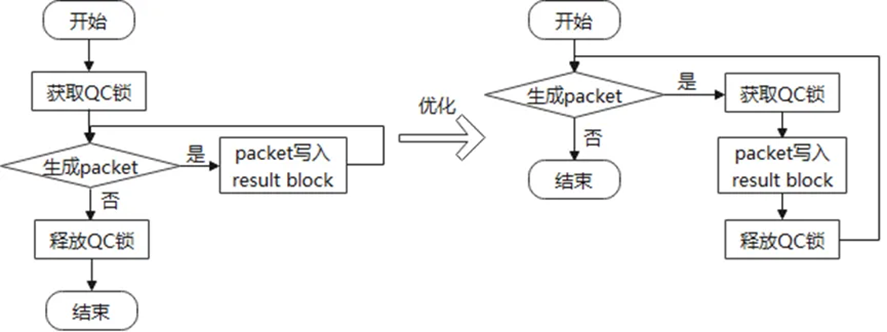
图18 写入流程优化
写入流程不需全程持锁,只需对内存池真正操作的 Query_cache::insert函数中持锁即可。但此优化引入一个新问题:如果同时有两个会话进行相同的查询,可能会导致两个线程对查询结果共同写入的情况,造成缓存结果错误。
此优化引入一个新问题:同时有两个会话进行相同查询,造成两个线程对同一查询结果同时写入的情况,造成缓存结果错误。
解决方案:
在query block中新增成员变量writer,创建query block时,writer记录线程号,后续result block只能由该线程写入。这样就可以确保每个查询结果,只能由一个线程写入,从而避免缓存结果的错误。
- 事务场景
1)多语句事务:
单语句事务和多语句事务中,相同查询对应不同的缓存。
-- 查询1进行缓存
select * from t1;
begin;
-- 查询2进行缓存
select * from t1;2)行锁写锁:
表有行写锁时,不会进行缓存。
begin;
insert into t1 values(1);
-- 不会缓存
select * from t1;3)RC场景:
DML、DDL操作会对相关查询缓存失效,所以,QC中查询缓存都是最新提交的结果,符合读已提交的定义,RC可以正常使用QC特性。
4)RR场景:
为了适配RR隔离级别,在表元数据中新增变量(query_cache_inv_id)记录对表的最新操作的事务ID(trx_id)。如果RR事务.trx_id< query_cache_inv_id,则说明该表有当前RR事务看不到的新操作,故该表QC缓存不适用此事务。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java