
GPU学习笔记,详细整理了其工作原理、编程模型和架构设计
1. 引言
Why GPU?
为什么要使用GPU?很多同学的第一反应就是“快”,这当然没错。而一个更严谨的说法是,GPU兼顾了“通用性”与“高效性”,才使得其一步步成为高性能计算的首选。
针对计算性能,1974年Dennard等人提出了Dennard缩放比例定律(Dennard Scaling)。
Dennard 缩放比例定律 (Dennard Scaling) :当晶体管特征尺寸缩小时,其功率密度保持恒定。具体表现为电压随特征尺寸线性下降,电流密度保持稳定,使得单位面积的功耗与晶体管尺寸成比例关系。
一言以蔽之:晶体管越小越省电。
推导到芯片设计领域:晶体管缩小,芯片能塞入的晶体管更多,同时保持整体能耗稳定,推动计算机性能持续提升。在计算机发展的前四十年间,基于Dennard定律的晶体管微缩是提升性能的主要路径。但在2005-2007年间,随着晶体管进入纳米尺度,量子隧穿效应引发的漏电流呈指数增长,阈值电压难以继续降低,最终导致该定律失效。此时,工艺微缩带来的性能增益已无法抵消功耗的快速增长,著名的"功耗墙"问题开始显现。
单纯依靠缩小晶体管尺寸来提升性能的方法不再可行,部分工程师开始转向专用硬件,即专门为了某种或某几种计算设计的计算硬件,例如Google的TPU(Tensor Processing Unit,张量处理器),就是一款专为加速机器学习任务而设计的专用硬件。然而,专用计算硬件只能聚焦于某一类或者某几类特定的计算任务,在处理其他任务时则可能力不从心。
而GPU则是向通用性演进的典型代表。虽然其最初设计目标是为图形渲染加速,但高度并行的SIMT(单指令多线程)架构意外契合了通用计算的演进需求,无论是基于CUDA的深度学习训练,还是通过OpenCL加速的流体仿真,都能通过高度并行获得远超CPU的计算性能。
GPU的“快”
为什么快?
高计算并发:与CPU相比,GPU将更大比例的芯片面积分配给流处理器(如NVIDIA的CUDA核心),相应地减少控制逻辑(control logic)所占的面积,从而在高并行负载下获得更高的单位面积性能。
低内存延迟:内存访问导致的延迟也是影响性能的一大因素,GPU通过在其每个核心上运行大量线程的方式,来应对并掩盖因全局内存访问导致的延迟。这种设计使得GPU即使在面临较慢的内存访问时,也能维持高效的计算性能。具体来说,每个SIMT核心同时管理多组线程(多个warp,一个warp 32个线程),当某个warp因为等待内存数据而暂停时,GPU可以迅速切换到另一个warp继续执行。这种快速切换使得GPU能够在等待内存数据返回的同时,保持高利用率,从而有效地“隐藏”了内存访问延迟。
特化内存与计算架构:GPU通常配备高带宽的显存(如GDDR6或HBM),能够快速读取和写入数据。如NVIDIA A100使用HBM2e显存最高可达到1.6TB/s带宽,是普通DDR5内存(51.2GB/s)的31倍。计算架构方面,GPU集成专用计算单元实现硬件级加速,例如,NVIDIA的Tensor核心针对结构化稀疏计算做专门设计,在低精度损失的情况下,可以极大得提升计算性能。
有多快?
理论算力计算:GPU算力常以FLOPS(Floating-Point Operations Per Second,每秒浮点运算次数)来表示,通常数量级为T(万亿),也即是大家听到的TFLOPS。最常见的计算方式为CUDA核心计算法。
# CUDA核心计算法
算力(FLOPS)= CUDA核心数 × 加速频率 × 每核心单个周期浮点计算系数
# 以A100为例
A100的算力(FP32单精度)= 6912(6912个CUDA核心) × 1.41(1.41GHz频率) × 2(单周期2个浮点计算) = 19491.84 GFLOPS ≈ 19.5 TFLOPS实测性能评估: 通过计算只能得到纸面上的理论算力,如果同学们手上真的有GPU,那么实测性能评估则可以直接让你获取你的GPU的性能。此处为大家提供几种最常见的实测方式和思路。
首先推荐一个非常实用的工具 GPU-Z,它是一款免费工具,可提供计算机中显卡的详细参数信息,支持实时监控 GPU 负载、温度、显存使用情况等关键数据,是排查显卡性能问题或计算故障的实用诊断工具。GPU-Z是监控工具,而3DMark则是最流行的性能测试工具,通过模拟高负载游戏场景评估电脑图形处理能力(在steam平台即可购买,电脑上有GPU的同学不妨买来跑个分试试)。
最后再介绍一下GEMM
(General Matrix Multiplication,通用矩阵乘法),这是一种经典的并行计算领域的计算密集型应用,与跑分工具这样的封装好的峰值性能测试工具相比,GEMM的重点反而不是进行性能测试,而是不断调整优化逼近理论峰值的过程。GEMM通过执行时间 T 和总操作数(M×K与K×N的两矩阵相乘)计算实测算力:
算力 = 总操作数 / 执行时间 = A(M, K) × B(K, N)/ T = 2 × M × N × K / T如果实测算力低于GPU理论峰值算力,则表明可能存在低效内存访问、计算资源利用率低、未充分利用硬件加速单元等问题,这些问题均可通过逐步优化来解决,以逼近理论峰值,当然也有温度/功耗问题和显存带宽瓶颈等硬问题,但影响较小。对实际操作进行GPU编程有兴趣的同学可以选择深入了解GEMM,学习实现的比较好的GEMM库是如何优化以逼近理论峰值的,在这个过程中深入理解GPU计算和编程。
GPU架构概述
在这里作者要做一个简单的说明,现代的GPU架构,先不论不同厂家,仅NVIDIA一家就有数十年的架构迭代史,其中涉及的各种优化改进,限于篇幅,本文不可能一一介绍。但是,要想完整了解整个GPU架构的发展,作者认为可以分两步走:以NVIDIA为例,就是“从0到Fermi“,和”从Fermi到Blackwell“。Fermi架构是现代通用GPU架构的基石,其中许多核心设计思想传承至今,而此后直到作者撰文的2025年最新的Blackwell架构,都可以看做在基础上的一路迭代。本文介绍的重点为两步走里的第一步,即讲解现代通用GPU中的基石级的通用技术与设计,读者迈好第一步,就可以以此为基础广泛探索。
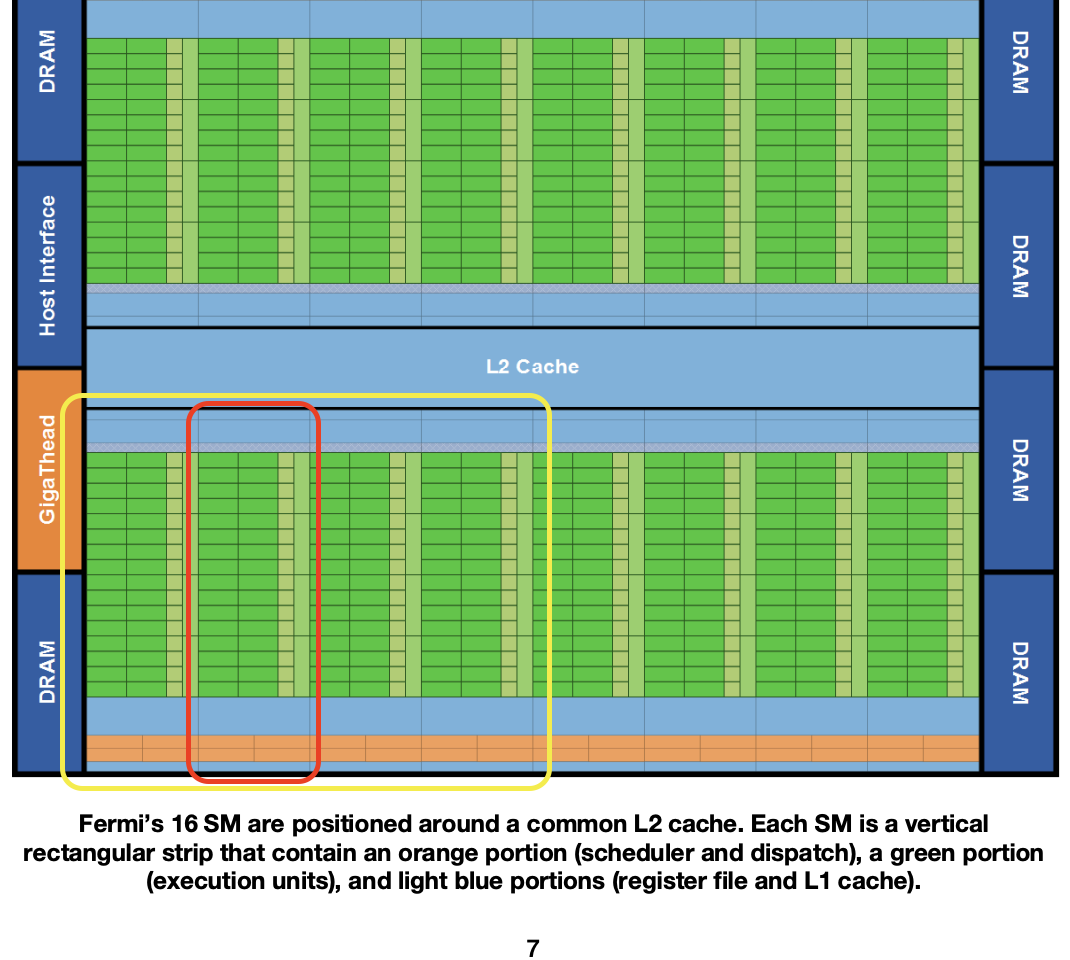
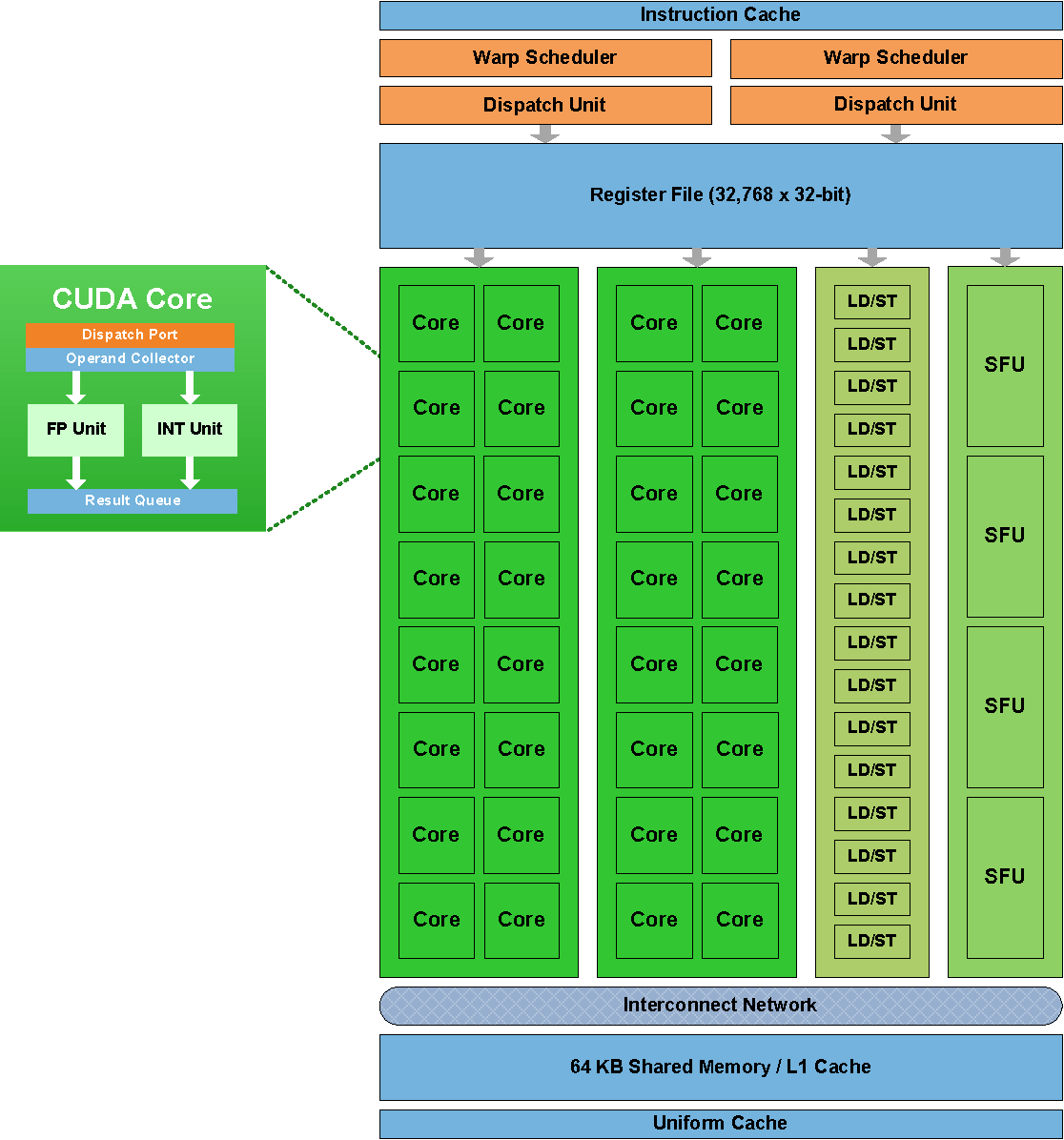
第一张图为Fermi架构图(来自Fermi架构白皮书),完整的Fermi架构GPU由4个GPC组成(黄色框),每个GPC有4个流式多处理器SM (Streaming Multiprocessor, 红色框),每个SM又有32个CUDA Core,此外还有L1、L2 Cache、共享内存、显存等组件。而每个SM、每个CUDA Core的结构则可见第二张图。这样看还是过于复杂,为了更清晰的从原理上了解通用GPU机构,本文将根据以下的简化通用GPU架构图讲解,介绍GPU架构使用的术语也将倾向于学术界常见的通用术语:
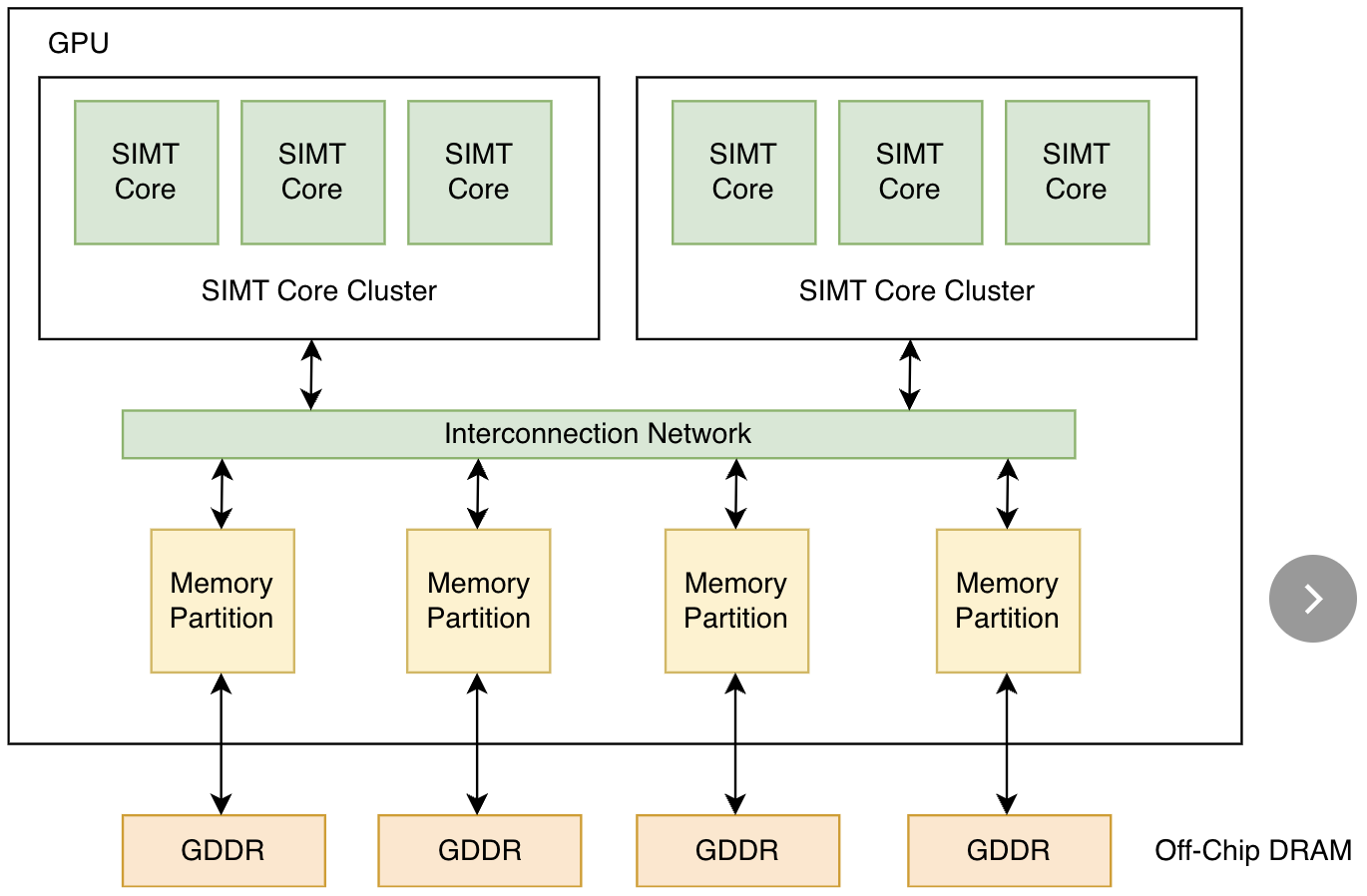
SIMT核心(SIMT Core)是GPU的核心计算单元,类似于CPU的多核集群,负责协调和管理大量线程的并行执行,对应NVIDIA 架构中的SM。SIMT(Single Instruction, Multiple Threads,单指令多线程),是GPU的核心执行模型,其本质是通过统一指令指挥多个线程并行处理不同数据。后文将做单独讲解。多个SIMT核心组成SIMT Core Cluster,对应NVIDIA的GPC,每个Cluster/GPC可以看做是一个可完整运作的mini GPU,而实际的GPU由多个GPC组成,也就是大家常说的“多核”。
在同一个SIMT核心内运行的线程可以通过共享内存(Shared Memory)来进行彼此通信同步,SIMT核心内还包含一级指令和数据缓存,用来减少与低级内存的交互次数从而提高性能。而SIMT Core Cluster之间通过Interconnection Network通信。
除SIMT核心外,另一重要部分是内存和内存管理,在图中即简化为Memory Partition和GDDR部分。Memory Partition部分管理显存的访问,跨SM的L2全局一致性缓存也位于此处。GDDR,即为大家常常提到的显存,其是位于GPU芯片外部的专用内存,用于存储图形数据等,相比于CPU的普通内存通常针对访问延迟和带宽进行优化。
2. GPU编程
本章将介绍如何编写程序使用GPU完成非图形类的计算,介绍重点在于揭示GPU的通用编程模式,以及程序执行的流程,并非专门的GPU编程教学。
程序如何执行?以SAXPY为例
SAXPY,即将向量X的元素乘以A,再加上向量Y。以下是用C语言实现的CPU计算SAXPY的代码:
// SAXPY函数实现
void saxpy(int n, float a, float *x, float *y) {
for (int i = 0; i < n; i++) {
y[i] = a * x[i] + y[i];
}
}
int main() {
float a = 2.0;
int n; // 向量长度
float *x; // 向量x
float *y; // 向量y
// 此处省略内存分配、元素赋值、长度指定
// ...
// 调用SAXPY函数
saxpy(n, a, x, y);
return 0;
}针对上述CPU计算代码,将代码改写为使用CUDA编写的在GPU上运行SAXPY:
__global__ void saxpy(int n, float a, float *x, float *y) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
y[i] = a * x[i] + y[i];
}
}
int main() {
float a = 2.0;
int n; // 向量长度
float *hx; // host向量x
float *hy; // host向量y
// 此处省略内存分配、元素赋值、长度指定
// GPU内存分配
int vector_size = n * sizeof(float); // 向量数据大小
float *dx; // device向量x
float *dy; // device向量y
cudaMalloc(&dx, vector_size);
cudaMalloc(&dy, vector_size);
// 将host向量内容拷贝到device向量
cudaMemcpy(dx, hx, vector_size, cudaMemcpyHostToDevice);
cudaMemcpy(dy, hy, vector_size, cudaMemcpyHostToDevice);
// 执行saxpy
int t = 256; // 每个thread block的线程数
int blocks_num = (n + t - 1) / t; // thread block数量
saxpy<<<blocks_num, t>>>(n, a, dx, dy);
// 将device向量y内容(计算结果)拷贝到host向量y
cudaMemcpy(hy, dy, vector_size, cudaMemcpyDeviceToHost);
// ... (剩余逻辑)
return 0;
}设备侧与主机侧
GPU编程的思维是将GPU当作CPU的协同外设使用,通常GPU自身无法独立运行,需要CPU指定任务,分配数据,驱动运行。第一行的__global__关键字,表示这段函数是内核函数(kernel,注意与Linux内核无关),是交给GPU执行的,而main函数则无此标识,由CPU执行。通常,将交GPU执行的代码部分称为设备(device)代码,而交给CPU执行的代码部分称为主机(host)代码。host与device是CUDA编程惯用的风格,CPU称为host侧,而GPU称为device侧。
main函数中的cudaMalloc、cudaMemcpy,是CPU操作GPU内存的操作,在分离式GPU架构(也就是独显)中,CPU分配内存用于GPU计算,再将数据传输到分配的内存空间,然后在GPU上启动内核函数。GPU执行的内核函数只能从分配的GPU内存空间读取数据。代码中的host向量对应CPU内存的数据,而device向量则代表GPU内存的数据。
值得一提的是,近年来统一内存(unified memory)在GPU的应用中逐渐流行,统一内存是指一种允许CPU和GPU共享同一段地址空间的内存架构,这种架构下可以实现CPU和GPU之间数据交换的自动化,开发者不需要手动管理数据在CPU到GPU之间的传输。
线程组织
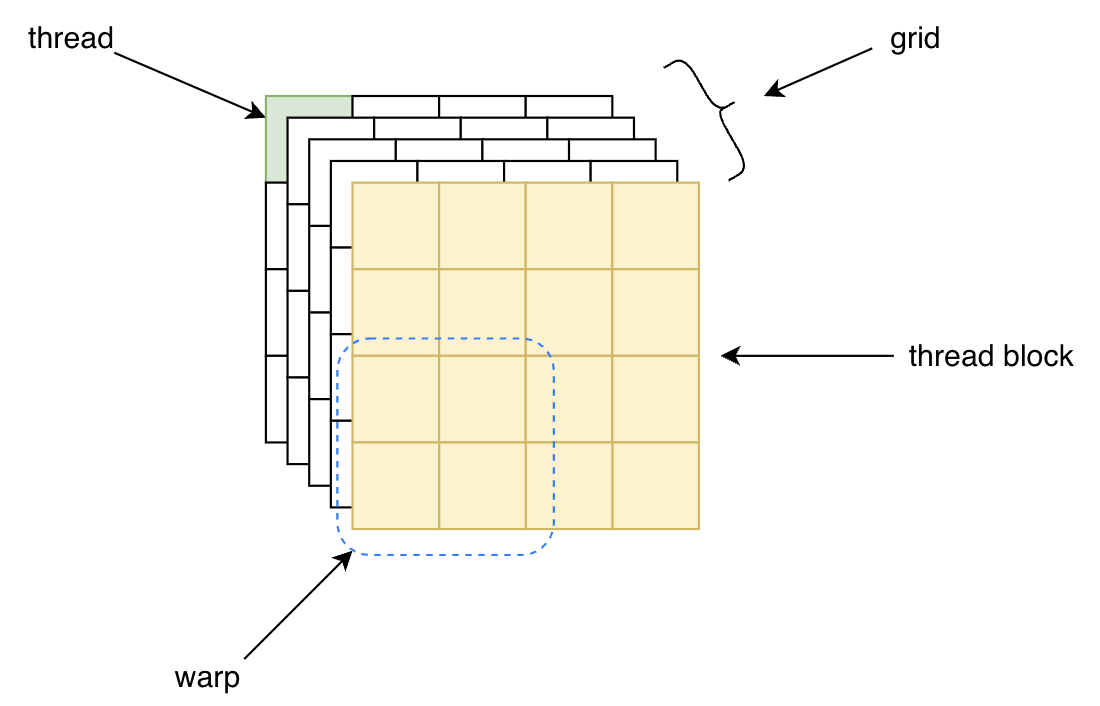
完成内存分配和数据拷贝后,CPU触发GPU执行saxpy内核函数。触发时同时指定了执行内核函数的线程的组织形式。在CUDA编程中,线程以thread,thread block,grid的层级结构进行组织,如上图所示:
● 线程(thread,绿色部分):最基本的执行单元。线程包含独立寄存器状态和独立程序计数器。
● 线程块(thread block,黄色部分):由多个线程组成的集合,支持一维、二维或三维结构。线程块内的线程可以通过共享内存进行通信,线程块之间无法通过共享内存通信,但可通过全局内存进行数据交互。
● Warp(蓝色线框):硬件底层概念,GPU实际运行时将32个线程组成一个warp,同一warp内的线程同步执行相同的指令。
● 线程块与warp的关系:warp是底层概念,NVIDIA的warp固定包含32个线程,warp是线程硬件调度的最小粒度。线程块是软件概念,线程块有多少个线程组成由代码指定。在运行时,硬件会将线程块中的线程32个为一组打包成多个warp进行调度,因此,线程块里的线程数最好为32的整数倍,以避免为拼凑完整warp而自动分配无效线程造成资源浪费。
● 网格(grid,总体):网格是所有线程块的集合,支持一维、二维或三维结构,覆盖整个计算任务的运行范围。
thread,thread block,grid,warp是NVIDIA的术语,而对于AMD,四者又有其独特的称呼,因为本文使用的例子为CUDA编程,GPU编程部分的讲解也将使用NVIDIA的术语体系,下表为术语对照表:
| NVIDIA(CUDA) | Grid | Thread Block | Warp | Thread |
|---|---|---|---|---|
| AMD(OpenGL) | NDRange | Work Group | Wavefront | Work Item |
区别于NVIDIA,AMD的一个wavefront由64个work item组成。线程块有时也被称为CTA(Co-operative Thread Array)。
代码执行saxpy部分:
// 执行saxpy
int t = 256; // 每个thread block的线程数
int blocks_num = (n + t - 1) / t; // thread block数量
saxpy<<<blocks_num, t>>>(n, a, dx, dy);此处指定线程块为一维的,一个每个线程块(thread block)有256个线程(thread)。又计算得到了线程块的数量block_num,指定网格(grid)也为一维,一个网格中有block_num个线程块。最后,用<<< >>>三个尖括号包含网格的线程块数、线程块的线程数,指定一个grid有block_num个线程块,一个线程块有256个线程。
线程块数量的计算
一个线程块由多少个线程组成可以指定,与此不同的是,线程块本身的数量则是由计算规模决定的,这段代码根据向量的长度计算了线程块的数量:
int blocks_num = (n + t - 1) / t; // thread block数量这样计算的目的是保证线程数量足够,即每一个计算单元都有一个线程负责计算。
例如,如果向量长度n=250,则block_num = (250 + 256 - 1) / 256 = 1,每个线程块有256个线程,那么要保证每个向量元素有一个线程负责计算,1个线程块就够了。又例如,如果向量长度n=257,则block_num = (257 + 256 - 1) / 256 = 2,需要两个线程块才能提供足够的线程,当然,本例子中的两个线程块足以提供512个线程,有很多线程实际上是闲置了。
总结上述计算方式,可以得到计算线程块数量时最常见的向上取整编程范式:
// B:线程块数,N:问题规模,T:线程块内线程数
B = (N + T - 1) / T指定线程执行内核函数指令
最后,我们来关注saxpy内核函数本身,main函数中分配的每个线程都会并发地执行这段代码:
__global__ void saxpy(int n, float a, float *x, float *y) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
y[i] = a * x[i] + y[i];
}
}此处为每个线程分配了一个其所属的向量元素,然后驱动线程分别完成计算。
首先计算i,i为线程的编号,blockIdx是block在grid上的坐标,blockDim则是block本身的尺寸,threadIdx为thread在block上的坐标。此前提到我们的grid、block都是一维的,因此只需要取其X维度,因此block的编号就直接取blockIdx.x,而一个block有blockDim.x个线程,线程编号为threadIdx.x。
假设当前线程是第二个线程块上的第10个线程,即第266个线程,则其index应为265:
i = blockIdx.x * blockDim.x + threadIdx.x = 1 * 256 + 9 = 265得到线程编号i后,第3行判断i是否落在[0,n]区间内,n为线程总数。如果为否,则该线程就是前面提到的多分配的闲置线程,不调度。而对于需要调度的线程,则根据自己的线程编号,读取源向量不同位置的元素,执行计算,并将结果写入结果向量的不同位置。这样,我们就为不同线程安排了独立的工作,让他们并发地完成工作。
多维线程组织结构
截止到这里我们提到的grid、thread_block都是一维的,实际可以支持一维、二维、三维,这里再举一个三维的例子:
// 主机端调用代码
void launch_kernel_3d() {
// 三维数据尺寸
int dimX = 64 int dimY = 32 int dimZ = 16;
// 定义三维线程块(Block)和网格(Grid)
dim3 blockSize(8, 4, 4); // 指定每个块包含8x4x4=128个线程
dim3 gridSize(
(dimX + blockSize.x - 1) / blockSize.x, // X方向块数
(dimY + blockSize.y - 1) / blockSize.y, // Y方向块数
(dimZ + blockSize.z - 1) / blockSize.z // Z方向块数
);
// 启动内核函数
kernel_3d<<<gridSize, blockSize>>>(d_data, dimX, dimY, dimZ);
}使用dim3(CUDA数据结构)来承载三维grid、thread block的尺寸。grid为三维,因此要计算X、Y、Z三个维度上thread_block的数量,仍套用前文提到的向上取整计算方法。而如果是三维的grid、block,其计算线程编号时就需要取X、Y、Z三个维度:
// 核函数定义(处理三维数据)
__global__ void kernel_3d(float* data, int dimX, int dimY, int dimZ) {
// 计算三维索引
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int z = blockIdx.z * blockDim.z + threadIdx.z;
if (x < dimX && y < dimY && z < dimZ) {
// 处理三维数据(例如:三维矩阵元素操作)
int idx = x + y * dimX + z * dimX * dimY; // 线程编号
data[idx] *= 2.0f; // 示例:每个元素翻倍
}
}SIMT
前文提到:SIMT(Single Instruction, Multiple Threads,单指令多线程),由NVIDIA提出,是现代通用GPU的核心执行模型,甚至可以说正是SIMT的出现,使得GPU从一种处理图形计算的专用硬件,进化为处理各类计算的通用处理器。SIMT的本质是通过统一指令指挥多个线程并行处理不同数据,结合上述例子,此处展开讲解。
SIMT本质上是一种并行计算的范式,要彻底理解SIMT,以及SIMT存在的意义,就必须从另一种更基础的并行计算的范式——SIMD讲起。因为SIMT是对SIMD进行“线程级抽象”得到的,或者说,SIMT是“基于Warp的SIMD”。
SIMD(Single Instruction Multiple Data,单指令多数据),即:在同一时刻向多个数据元素执行同样的一条指令。SIMD范式常见的一种实现是CPU的向量化运算,将N份数据存储在向量寄存器里,执行一条指令,同时作用于向量寄存器里的每个数据。可见SIMD,特别是向量化运算,是一种偏硬件底层的并行计算优化,而SIMT范式则是通过线程编程模型隐藏了底层SIMD的执行细节。
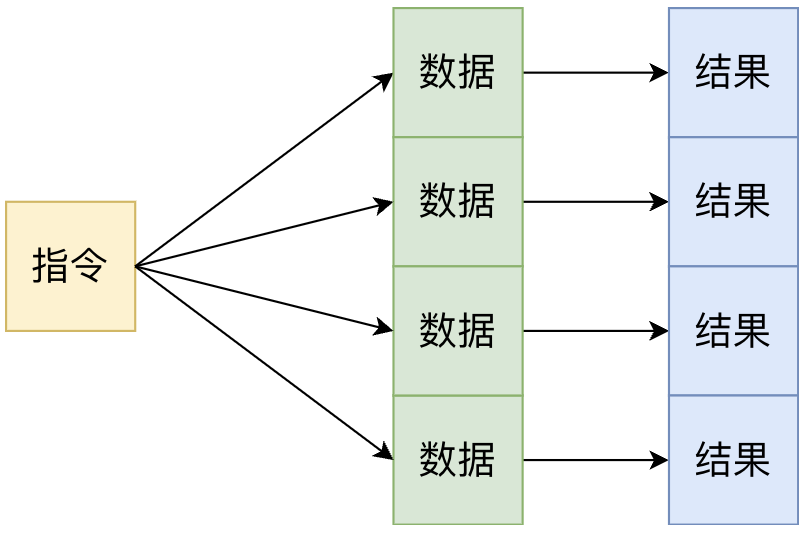
在向量化运算实现的SIMD,有N个这样流程并发执行:“指令+操作数→结果”,而SIMT的设计思想,则将“指令+操作数”抽象成了“线程”,线程可以看做是打包了指令和操作数的一个执行单元:线程包含独立寄存器状态(操作数)和程序计数器(指令)。在软件编程时,程序以线程为单位进行调度,编程者只需要关注安排多少线程执行哪些指令,而无需过多考虑底层细节。这使得编程模型更接近多线程CPU,降低开发者适配难度。
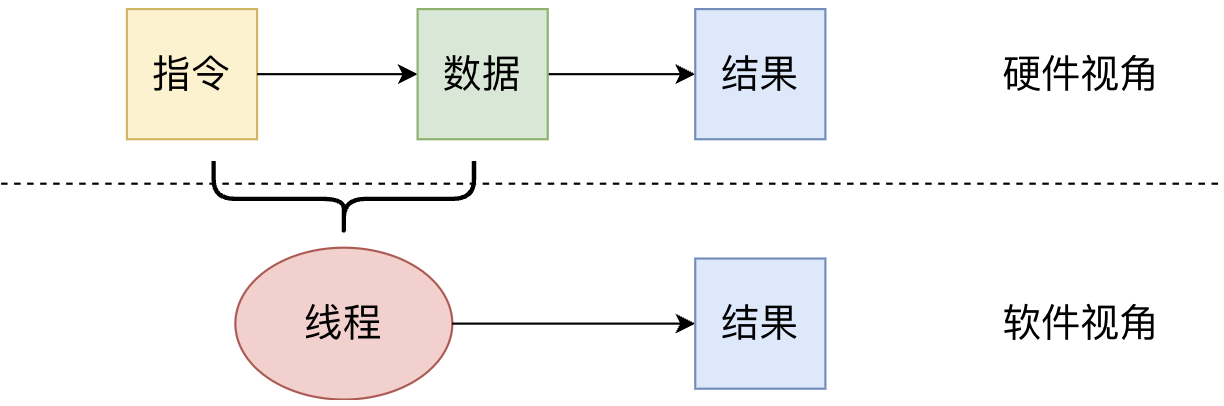
SAXPY例子中的内核函数,就是以SIMT模型进行编程的,安排所有线程执行相同的指令,但每个线程执行指令时的指令操作数均不同,这便是SIMT:
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
// 每个线程都执行这条指令,每个线程读取不同元素执行相同计算
y[i] = a * x[i] + y[i];
}而在各线程实际运行时,硬件层面便会回归SIMD范式。继续以SAXPY为例,实际执行时GPU硬件会将其组织为warp,warp中的每个线程基于唯一索引i,访问不同的内存位置,以不同的数据执行相同的指令,这便是SIMD:
// 一个Warp中每个线程的执行流程(线程0-31)
//【指令 + 操作数 = 结果】的SIMD范式
i = 0 → y[0] = a*x[0] + y[0]
i = 1 → y[1] = a*x[1] + y[1]
...
i = 31 → y[31]= a*x[31]+ y[31]传统的SIMD关注的是一条条指令本身的执行方式,而SIMT则将SIMD“包了一层”,底层实现SIMD,表面上提供线程级编程模型,让编程者很大程度上可以从串行的角度思考,而屏蔽了很多并行角度的执行细节。
这种编程便利最好的体现就是在出现分支(如if-else)时:Warp执行每个Branch Path,执行某个path时,不在那个path上的线程闲置不执行,线程活跃状态通过一个32位的bitmask标记,分支收敛时再对齐汇总到下一段指令等等。后文将对这一过程作详细讲解,而在这里读者只需要理解到,如果只有底层SIMD,那么这一切复杂流程都要编程者自己思考+编排,而在SIMT编程模型下编程者只需要编写分支代码,把这些编排交给硬件底层即可。
指令集与编译
刚才我们讲解了CUDA C语言编写的SAXPY,到这里,只是到了高级语言层面,众所周知,高级语言需要转换为机器码才能被机器执行,本节将简单介绍CUDA C/C++的程序的编译流程,以及CUDA的PTX、SASS指令集。
指令集:SASS、PTX
SASS(Streaming Assembly)是GPU的机器指令集,是实际在GPU上执行的指令。SASS指令集直接对应GPU架构(Maxwell、Pascal等),虽然不是严格的一一对应,但通常每个GPU架构有专属的SASS指令集,因此需要针对特定架构进行编译。
PTX(Parallel Thread Execution)是一种中间表示形式,位于高级GPU编程语言(如CUDA C/C++)和低级机器指令集(SASS)之间。PTX与GPU架构基本无耦合关系,它本质上是从SASS上抽象出来的一种更上层的软件编程模型,PTX的存在保证了代码的可移植性(同一份PTX分发到不同架构上转为对应SASS)与向后兼容性(可将PTX代码转为最新GPU架构对应的SASS)。
PTX是开发者可编程的最底层级,而SASS层则是完全闭源的,这也是NVIDIA的“护城河”之一。
编译流程
CUDA程序的编译由NVCC(NVIDIA CUDA Compiler)完成。

首先,NVCC完成预处理;随后分类代码为设备代码和主机代码,NVCC驱动传统的C/C++编译器主机代码的编译和汇编;对于设备代码,NVCC将其编译针对某架构的SASS,编译过程中涉及C --> PTX --> SASS的转化,但通常不显式表现出来,生成的PTX/SASS码也会被直接嵌入最终的可执行文件。

运行期,GPU会优先查找可执行文件中是否有适合当前架构的SASS,如有则直接执行。若无,则GPU驱动(driver)会使用JIT(Just-In-Time)编译手段,将PTX码编译为当前架构对应的SASS再执行(前提是可执行文件必须包含PTX)。
3. SIMT核心架构
前面两章,我们主要从总体概述和软件编程的角度了解了GPU。相信不少同学在校园课程中,曾学习过CPU的核心架构,我一直以为,在了解了底层硬件是如何运作之后,我们看待处理器/硬件的视角才会有本质上的转变,从一个用户(这是执行我代码的黑盒)转变为一个专业技术人员(这是中央处理器)。因此,我们将更进一步,从更偏硬件的视角进一步了解GPU架构。
软硬分界线
前文提到SIMT核心也就是NVIDIA的SM,也给出了来自Fermi白皮书的SM结构图。但是,线程以Warp为单位在SM上执行,具体如何执行,执行的流程是什么,每个组件发挥什么作用,单单从结构体是看不出来的,因此我们需要引入SM的指令流水线结构图来进行讲解:
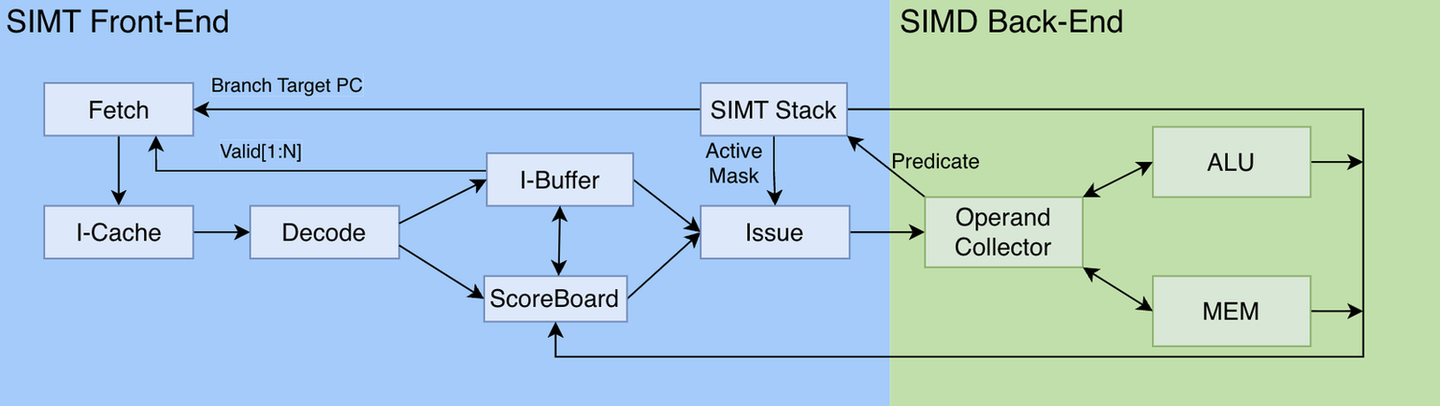
如图所示,SIMT核心流水线从运行的处理阶段可以分为SIMT前端和SIMD后端两个部分:
- SIMT前端:主要负责指令的获取、译码和发射、分支预测、以及线程的管理和调度。这部分设计的组件对应SM结构图中的蓝色、橙色部分(Warp Scheduler、Register File)。
- SIMD后端:主要负责完成计算。这部分设计的组件对应SM结构图中的绿色部分(Core)。
SIMT前端与SIMD后端的划分本质上是控制流与数据流的解耦,SIMT前端关注指令流/控制流,而SIMD后端关注单个指令执行/数据流。
SIMT前端在硬件运行时“落实”了程序对线程的调度:SIMT前端以warp为单位调度线程,其包含的指令缓存(I-Cache)、解码器和程序计数器PC组件集中管理线程的指令流,并使用SIMT堆栈等技术实现线程间的条件分支独立控制流。SIMD后端主要负责执行实际的计算任务。在SIMT前端确定了warp要执行的指令后,指令发射,SIMD后端负责高效地完成一条条指令。具体的数据计算单元ALU,以及存取计算数据的寄存器访问(Operand Collector)、寄存器文件(Register File)、内存读写(Memory)位于此处。
说到这里,这么多组件、组件之间有各种配合,不少同学估计已经要绕晕了。下面本文如果平铺直叙地直接深入一个个组件的细节,就会变得难以理解。因此,下面本文将采取一种“三步走”的讲解策略,先构建一个能执行计算任务的“最小系统”流水线,然后逐步向其中添加优化与功能,最终经过三步,构建出上图中完整的流水线架构。
第一步:最小可用系统
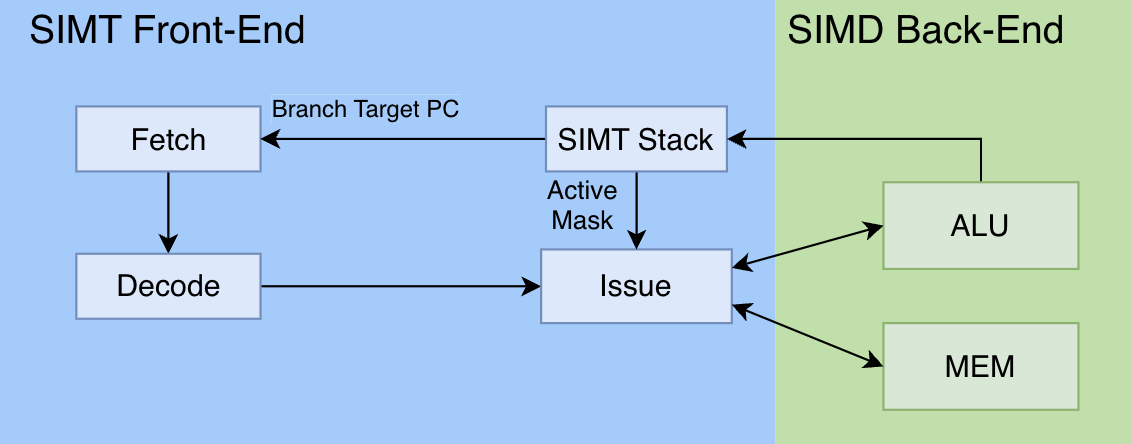
如上图,我们将SIMT内核的架构做了最大可能的简化,构成了一个“最简GPU”。这个最小可用系统由6部分构成,此6个组件相互配合,使得我们的最简GPU可以做到最简的指令执行功能:即顺序执行每一条指令,一条指令执行完再执行下一条:
- Fetch:取指令
- Decode:指令解码
- SIMT Stack:SIMT堆栈,管理线程束的分支执行状态,下文讲解
- Issue:指令发射
- ALU:算数逻辑单元,代表执行计算的组件
- MEM:存储器访问单元,代表对L1 Cache、共享内存等各层级内存访问的管理。
其中1、2、4、5、6部分是在CPU上久而有之的“老面孔”了,本文不多做解释。本节将重点介绍GPU独有的“新面孔”:SIMT堆栈。
分支发散:哪些线程执行哪条指令?
在GPU并行计算的发展历程中,SIMT堆栈是早期架构解决线程分支管理问题的核心机制。
现实中的计算任务常包含大量条件分支(if-else、循环等)。在遇到条件分支发散(Branch Divergence)当线程束内线程选择不同执行路径时,会产生线程发散(Thread Divergence):
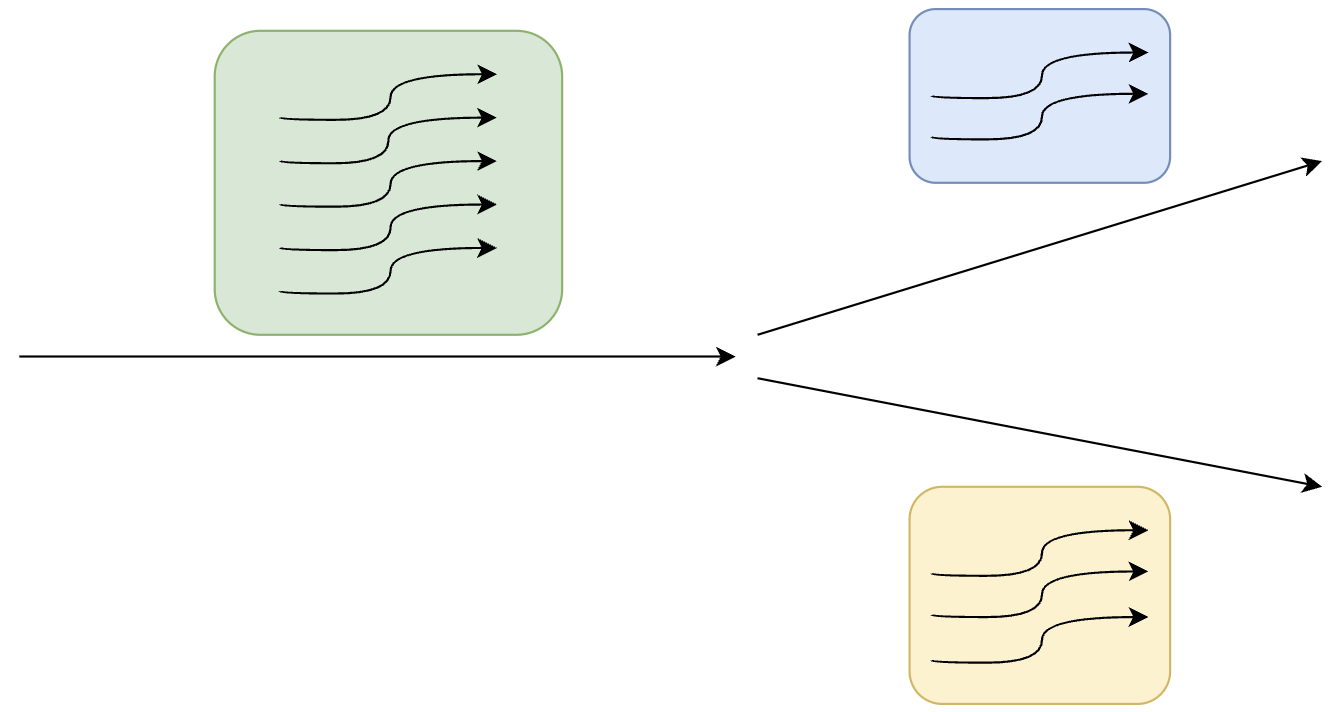
如上图,起初有5个线程执行相同的指令,直到分支发散处,根据SIMT的特性:多线程执行相同指令,但每个线程有自己独立的数据,假设此处是一个if-else,有不同数据的线程将得到不同的条件判断结果,2个线程进入if分支,3个线程进入else分支,进入不同分支的线程执行的指令流自然不同。
此处便出现了线程发散,即同一warp内的线程要执行不同指令,单由于线程以warp为最小单位调度,同一时钟周期内同一warp内的线程必须执行相同的指令,那么不同执行分支的线程就需要分开调度,例如一个时钟周期调度该warp执行if分支(if分支的线程活跃),下个时钟周期再调度该warp执行else分支的线程(else分支的线程活跃)。也就是说,以warp为单位调度不代表每次调度warp,其中全部32个线程都活跃,也可以只有部分线程活跃,其余线程闲置。
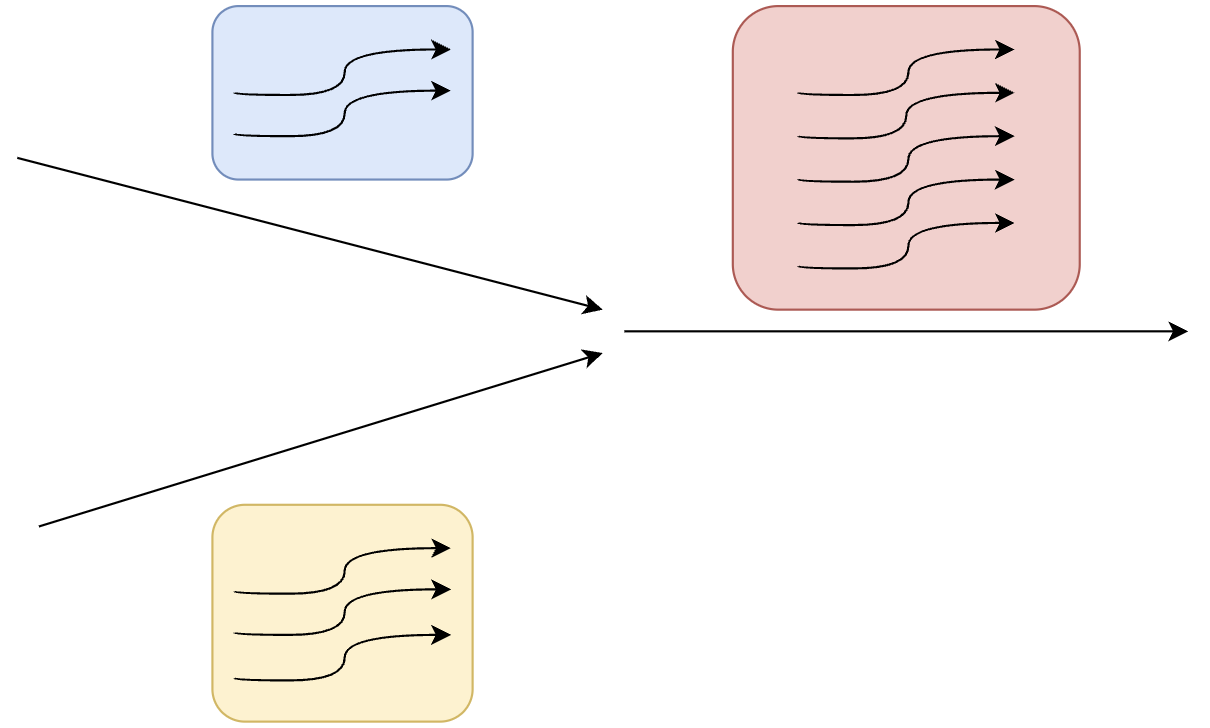
分支发散带来的复杂性不仅是线程指令流的发散,还有调度顺序。如上图,if-else分支发散后,分支聚合,5个线程执行红色部分,但依赖if和else分支线程的运行结果,那么就要求蓝色部分和黄色部分先执行完,再执行红色部分。
为解决分支发散时的线程调度,NVIDIA于2008年在Tesla架构中首次引入SIMT堆栈,并作为2010年Fermi架构的核心技术,其核心思想是:
- 路径跟踪:当线程束遇到分支时,通过堆栈记录所有可能执行路径的上下文(如程序计数器PC、活跃线程掩码)。
- 串行化执行:依次调度warp中每个分支路径上的线程,其他线程暂时闲置。
- 重新收敛:在所有路径执行完毕后,恢复完整warp的并行执行。
SIMT堆栈
为了介绍SIMT堆栈的工作原理,我们引入一个稍复杂一点的分支发散例子,如下图中的左图,是一个程序的分支流,其中有两层嵌套的if-else。而下方右图则用表格的形式展示了左图程序执行过程中SIMT堆栈的情况:表格最下行为栈顶,三行分别为聚合点PC、下条指令PC和活跃掩码(Active Mask)。
聚合点PC,即分支聚合点的指令指针,例如,对于B、F这一分支发散,其聚合点PC就是G。
下条指令PC,顾名思义,就是当前指令的下一条指令的PC,如A的下条指令PC为B。
活跃掩码(Active Mask),代表了哪些线程执行这条指令,本例子中假设有4个线程,而活跃掩码就有4位,每一位分别对应一个线程,这一位为0,则线程不执行这条指令,为1则执行,例如,指令B的活跃掩码为1110,代表前三个线程执行B,而第四个线程执行else分支的F(因此F的活跃掩码为0001)。
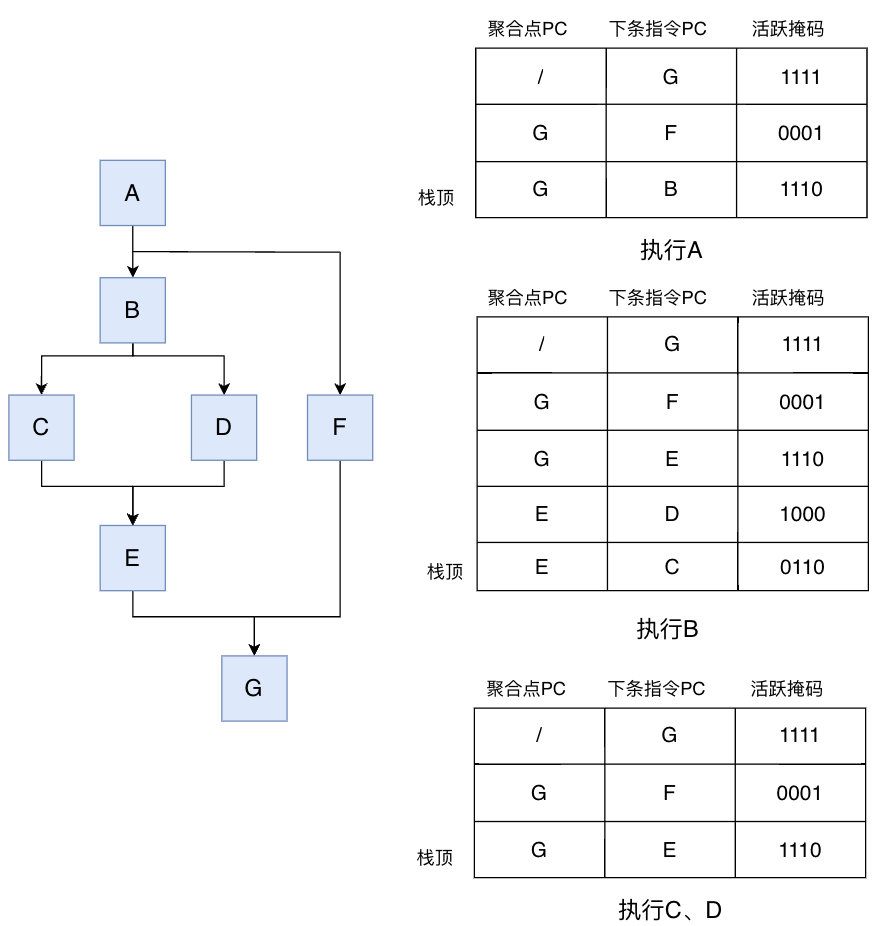
观察执行A、B、C、D时的SIMT堆栈,可以得到SIMT堆栈的运行方式:在遇到分支发散时,先将分支聚合点压入堆栈,随后压入各分支的指令,各分支指令执行完毕后,回到聚合点,执行聚合点的指令。
我们跟着例子走一遍:
- 执行指令A,发现有分支发散。此时先将分支聚合点G压栈,再将两分支F、B先后压栈。
- 执行栈顶的B,发现又有分支发散。此时先将聚合点E压栈,再将两分支D、C压栈。
- 执行栈顶的C、D,回到聚合点E。后续按弹栈顺序,再执行F、G,完成执行。
通过以上调度策略,保证了存在依赖时的正确性,例如,如果执行E依赖执行A、B、C、D的执行结果,SIMT栈刚好保证了E在ABCD后执行。
至于压入各分支时的压栈顺序,如压入C、D时的顺序,因为C、D二者之间不存在依赖关系,从正确性角度而言,CD或者DC顺序都可以,此时通常从性能角度出发,优先压入有更少线程执行的指令(线程少离栈顶远,线程多离栈顶近),从而保证有更多线程执行的指令先弹栈执行,这样做有助于尽量减少栈的层数,提高性能。
SIMT堆栈的问题
尽管SIMT堆栈在早期GPU架构中实现了分支管理能力,但其设计本质上面临多重硬件与效率瓶颈,难以适应现代计算任务(光线追踪、AI训练推理等)对复杂控制流的需求:
- 传统方案依赖固定深度的硬件堆栈,每个线程束需独立维护堆栈,导致寄存器占用率攀升。
- 堆栈通常只有4-8级最大深度,这就意味着如果程序控制流过于复杂,例如,在训练Transformer模型时,自注意力机制可能触发数十/上百层条件判断,远超堆栈容量。
- 每次分支发散时,硬件需执行压栈,并在路径切换时弹栈。例如,一个包含5层嵌套if-else的着色器,需至少10次堆栈操作(进入和退出各一次)。随着程序变得复杂,此类操作越来越多,会造成显著的流水线延迟。
- 最后,由于堆栈的严格后进先出(LIFO)特性要求分支路径必须按嵌套顺序执行,很容易造成负载失衡甚至死锁。例如,在光线追踪中,部分线程可能因等待材质纹理读取而停滞,而其他线程已完成计算,但受限于堆栈顺序无法提前推进。
独立线程调度
在Volta之前的架构(如Pascal、Fermi)中,在分支线程调度上,由SIMT完成调度,而Warp作为基本调度单元,所有线程共享统一的PC和活动掩码,当Warp内线程执行不同分支路径时,需按路径顺序串行执行。例如:线程0-3执行分支A的指令,线程4-31执行分支B的指令,则必须排队执行,一部分线程先执行分支A的指令,另一部分线程必须等待。
而从Volta架构开始,引入了独立线程调度(Independent Thread Scheduling)。每个线程拥有独立的程序计数器(PC)和执行状态寄存器,允许同一Warp内的线程在不同分支路径上并行执行指令流。但硬件层面仍以Warp为基本调度单元。
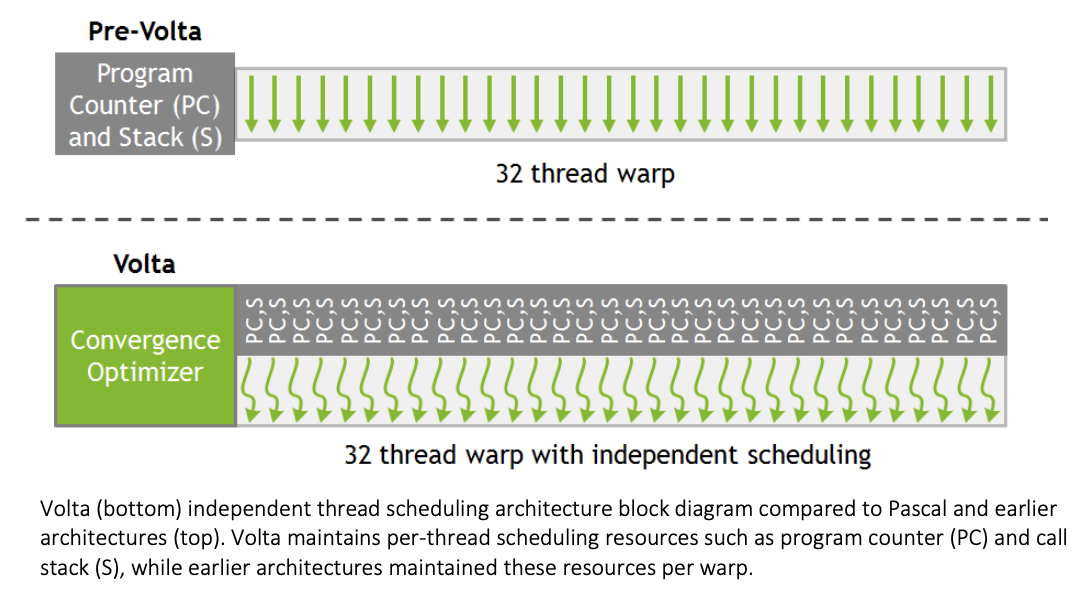
图出处:NVIDIA Volta架构白皮书
无堆栈分支收敛
同时,也是从Volta架构开始,随着独立线程调度的引入,传统SIMT堆栈被弃用,分支收敛机制也升级到了无堆栈分支重新收敛(Stackless Branch Reconvergence)机制,通过收敛屏障(Convergence Barriers)技术来低成本解决分支代码执行调度问题,独立线程调度为无堆栈分支重新收敛提供了硬件支持。
无堆栈收敛屏障机制的核心手段之一是屏障参与掩码(Barrier Participation Mask)与线程状态协同管理,其核心思想可以通过ADD和WAIT操作来展示:
- ADD(屏障初始化):当Warp执行到分支发散处前,通过专用ADD指令,活跃线程将其标识位注册到指定收敛屏障的32位掩码中,标记参与该屏障的线程组。
- WAIT(屏障同步):在预设的收敛点(如分支汇合处),硬件插入WAIT指令。到达此处的子线程组将线程状态标记为“阻塞”,并更新屏障状态寄存器。当所有参与线程均抵达屏障后,调度器才重新激活完整线程束。
为了便于理解,下面用一个图表示一个简单的的ADD,WAIT的例子:
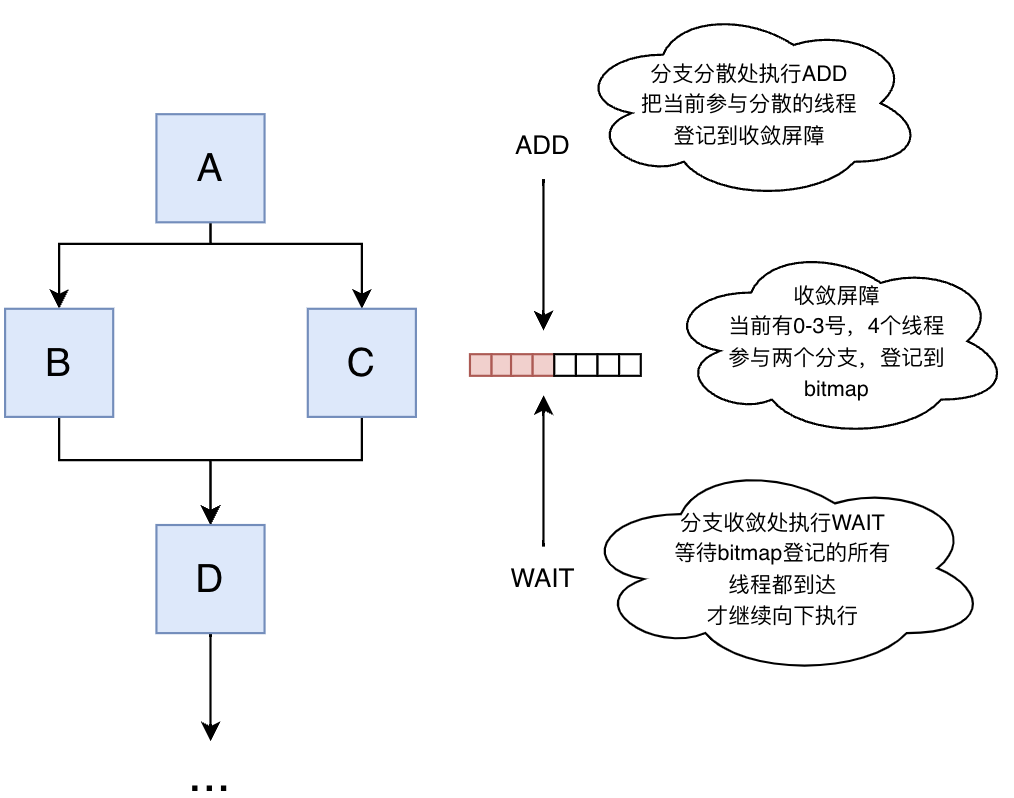
另外,通过新增的syncwarp()函数,开发者也可手动指定分支后的同步点,强制线程在特定位置重新收敛。
相比于SIMT堆栈,收敛屏障只需要使用仅需位掩码和状态寄存器,对于一个Warp(32个线程),一个屏障只需要32bit(每个bit对应一个线程),操作成本和硬件资源占用均极低,且不会再有堆栈深度限制,可以支持任意深度的条件分支嵌套。这一设计使得现代GPU(如NVIDIA Volta+架构)在复杂控制流场景下仍能保持高吞吐量,成为实时光追、AI推理等应用的关键支撑。
第二步:动态指令调度以提高并发
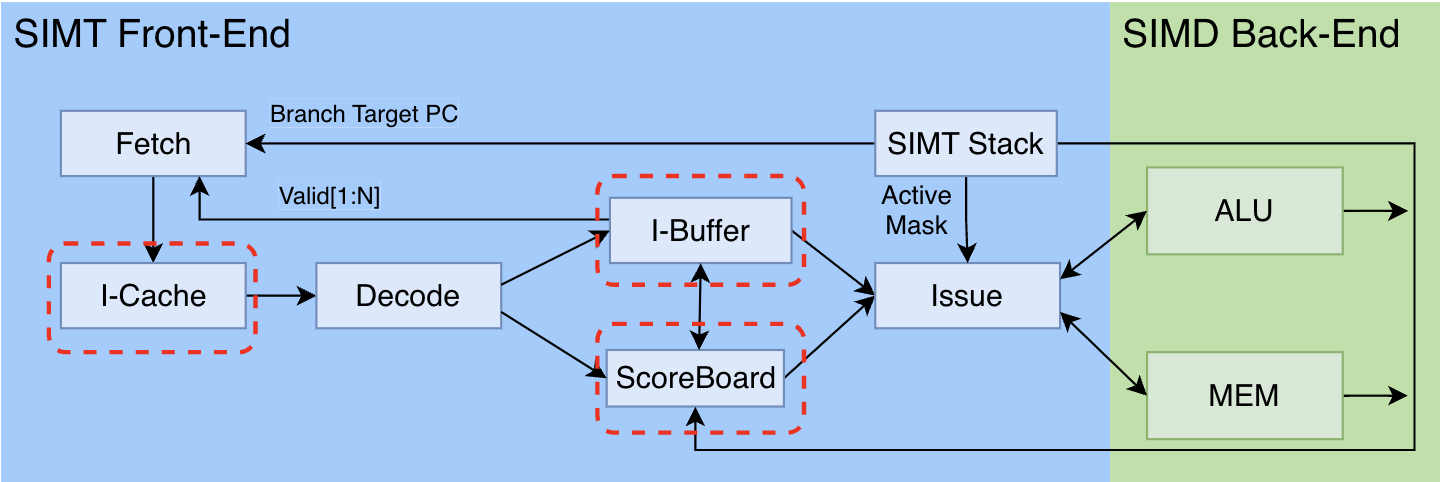
在第一步构建的最小可用系统中,采用的是“一条指令执行完再执行下一条”的最简执行策略。前文提到过,GPU为了隐藏内存访问的延迟,需要在内存访问指令为执行完前,先分配warp去执行其他指令。这里的策略其实就是动态指令调度,根据指令依赖关系和执行单元可用性,动态决定指令发射顺序。
但此处有一个重要条件,就是先分配执行的这个其他指令,不能依赖于未完成指令的结果,否则无法执行。因此,需要先判断指令之间是否存在依赖关系,才能选择出不依赖未完成指令的指令进行执行。为了分析指令之间的依赖关系,以支持乱序执行,第二步为我们的系统增加了I-Cache、I-Buffer和ScoreBoard三个组件,并且ALU和MEM又多了一个指向ScoreBoard的“回写”操作。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java