
SpringBoot实现TB级文件分片上传架构实践
业务背景
在AI模型生产平台中,文件存储场景包含图片、模型文件(.pt/.h5)、训练数据、用户数据集(CSV/ZIP)、标注数据集(COCO格式)等多样化类型。其中模型文件平均大小达20-50GB,原始数据集经压缩后普遍超过100GB。传统单文件上传方案存在以下痛点:
- HTTP超时导致上传失败率高达35%
- 网络波动造成重复传输浪费带宽
- 服务端内存溢出风险(单文件加载消耗2GB+内存)
- 断点续传能力缺失影响用户体验
基于此,我们开发了支持TB级文件处理的分片上传服务,实现99.99%的上传成功率与自动容错能力。
挑战
- 分片稳定性:网络闪断导致分片丢失
- 合并原子性:千级分片合并时文件顺序错乱
- 资源消耗:海量分片元数据存储压力
- 异步补偿:合并后处理流程的异常回滚
- 性能瓶颈:高并发场景下的磁盘IO竞争
架构设计
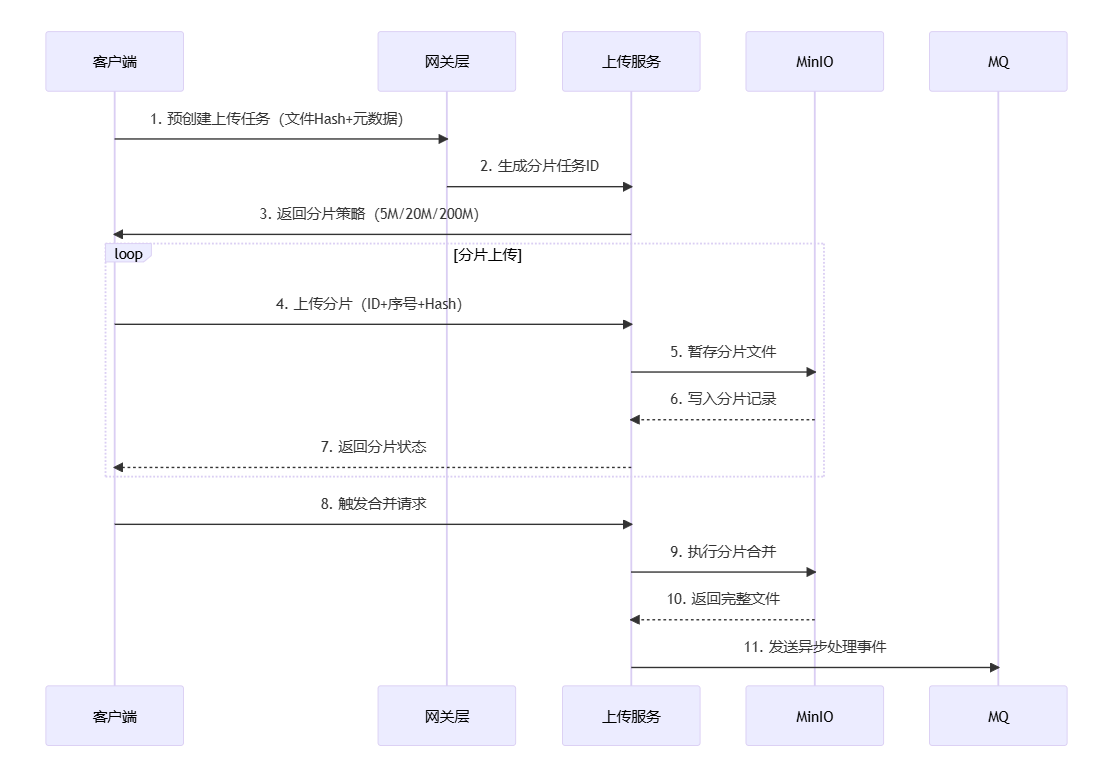
大文件分片上传技术流程
- 客户端初始化
- 发起预创建请求,携带文件元数据(文件大小、HASH值)
- 等待分片上传服务的控制器返回分片策略(分片大小5M/20M/200M)
- 上传服务预处理
- 生成全局唯一上传任务ID
- 根据文件大小动态分片(计算总片数及每片偏移量)
- 返回分片清单给客户端
- 分片上传阶段
- 客户端并行上传分片至上传服务
- 上传服务校验分片完整性(HASH校验)
- 分片临时存储至上传服务器的temp的目录下
- 每片成功即更新分片状态记录
- 进度监控循环
- 客户端轮询分片上传状态(间隔建议2-5秒)
- 服务端响应各分片上传状态(成功/失败/待传)
- 失败分片触发客户端重传机制
- 合并触发阶段
- 客户端验证全部分片成功后发起合并请求
- 请求包含分片顺序索引及校验参数
- 服务端合并处理
- 按索引顺序拼接分片文件
- 二次校验整体文件HASH值
- 生成最终文件存储路径
- 清理临时分片存储空间
- 结果返回与通知
- 返回文件访问URL给客户端
- 更新文件元数据至数据库
- 异步事件驱动
- MinIO
- 触发存储事件到消息队列(MQ)
- 消息包含分片路径、存储桶等元信息
- 消费端监听MQ准备后续处理
- 异步触发后续处理流程(如转码、OCR等)
关键技术特征
- 断点续传:基于分片状态记录实现
- 并行传输:支持多分片并发上传
- 秒传优化:HASH校验实现重复文件跳过
- 弹性分片:根据网络质量动态调整分片大小
- 事务补偿:失败分片自动重试机制
关键技术实现
智能分片策略
- 根据实时带宽检测自动切换分片模式:
- 5M分片(弱网:<10Mbps)
- 20M分片(普通网络:10-100Mbps)
- 200M分片(专线/高速网络:>100Mbps)
def dynamic_chunk_size(bandwidth):
if bandwidth < 10: return 5*1024*1024
elif 10 <= bandwidth < 100: return 20*1024*1024
else: return 200*1024*1024 前端处理分片
// 前端切割文件
const sliceFile = async (file) => {
const chunkSize = file.size > 1024 * 1024 * 1024 ? 200 * 1024 * 1024 : 5 * 1024 * 1024;
let offset = 0;
while (offset < file.size) {
const chunk = file.slice(offset, offset + chunkSize);
chunks.push({
index: Math.floor(offset / chunkSize),
hash: await calculateMD5(chunk)
});
offset += chunkSize;
}
};分片任务管理
关键数据结构设计:
CREATE TABLE upload_task (
task_id VARCHAR(64) PRIMARY KEY COMMENT '任务唯一标识(UUIDv4)',
file_hash CHAR(40) NOT NULL COMMENT '文件SHA1指纹(全大写HEX字符串)',
total_chunks INT NOT NULL COMMENT '总分片数量(1-65535)',
completed_chunks LONGTEXT NOT NULL COMMENT '已上传分片序号数组(JSON数组格式,如[1,2,3])',
status ENUM('PENDING','UPLOADING','MERGING','COMPLETED') NOT NULL DEFAULT 'PENDING' COMMENT '任务状态:待处理/上传中/合并中/已完成',
created_at DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '任务创建时间(带毫秒)',
updated_at DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最后更新时间',
expire_time DATETIME COMMENT '任务过期时间(默认创建后7天自动清理)',
retry_count TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '合并失败重试次数(0-255)',
storage_path VARCHAR(512) COMMENT '最终存储路径(合并完成后更新)',
INDEX idx_file_hash (file_hash) USING BTREE COMMENT '文件哈希索引',
INDEX idx_status (status) USING BTREE COMMENT '状态索引',
INDEX idx_expire (expire_time) USING BTREE COMMENT '过期时间索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
COMMENT='文件分片任务元数据表'-- 查询待合并任务 有分片上传完成时执行
SELECT * FROM upload_task
WHERE status = 'UPLOADING' and task_id = #{taskId}
AND JSON_LENGTH(completed_chunks) = total_chunks
AND created_at >= DATE_SUB(NOW(), INTERVAL 2 HOUR);分片上传接口
@PostMapping("/upload-chunk")
public ResponseEntity<?> uploadChunk(
@RequestParam String fileHash,
@RequestParam int chunkNumber,
@RequestParam MultipartFile chunk) {
// 验证分片是否已存在(幂等设计)
if (storageService.isChunkExists(fileHash, chunkNumber)) {
return ResponseEntity.ok().build();
}
// 存储分片到MinIO临时目录
String path = String.format("/temp/%s/%d", fileHash, chunkNumber);
storageService.upload(path, chunk.getInputStream());
// 更新任务进度
taskService.updateChunkStatus(fileHash, chunkNumber);
return ResponseEntity.ok().build();
}文件合并优化实现
public void mergeFile(String fileHash) throws IOException {
List<String> chunkPaths = getSortedChunkPaths(fileHash);
ForkJoinPool customPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors());
customPool.submit(() ->
IntStream.range(0, chunkPaths.size()).parallel().forEach(i -> {
String chunkPath = chunkPaths.get(i);
long position = offsets.get(i);
try (FileChannel source = FileChannel.open(Paths.get(chunkPath), StandardOpenOption.READ);
FileChannel dest = FileChannel.open(finalPath, StandardOpenOption.WRITE)) {
source.transferTo(0, source.size(), dest.position(position));
} catch (IOException e) {
throw new RuntimeException(e);
}
})
).get();
// 生成最终文件的MD5校验码
String mergedHash = DigestUtils.md5Hex(Files.newInputStream(finalPath));
if (!mergedHash.equals(fileHash)) {
throw new RuntimeException("File integrity check failed!");
}
}性能优化
分片计算负载过高
- 哈希计算:MD5/SHA256等哈希算法频繁计算(尤其是Web端未使用WebAssembly加速)
// 未优化的浏览器端哈希计算(可能阻塞主线程)
async function calculateHash(chunk) {
return crypto.subtle.digest('SHA-256', chunk);
}- 分片切割逻辑:同步切割大文件导致主线程阻塞
- 异步计算:将哈希/加密操作卸载到Web Worker或独立线程
- 硬件加速:使用WebAssembly优化浏览器端计算
并行传输架构
- 客户端多线程并发上传(建议4-8线程)
- 服务端采用分片路由策略:
- 哈希分片ID % 服务器节点数 实现负载均衡
- 跨AZ存储分片保障容灾
稳定性增强
- 分片预检:上传前校验分片MD5值
- 断点续传:客户端记录已上传分片序号
流水线压缩传输
- 客户端分片级压缩(Zstandard算法
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java