
DeepSeek-R1推理模型微调
DeepSeek介绍
简介
DeepSeek通过发布其开源推理模型DeepSeek-R1,彻底改变了AI领域的格局。DeepSeek R1引入了一种全新的LLM训练方式,并在这些模型在思考和执行一系列推理后的回答方式。该模型使用创新的强化学习技术,以较低的成本实现了与OpenAI的o1相当的性能。
DeepSeek已将其推理能力提炼到几个较小的模型中,基于DeepSeek-V3-Base(总参数671B,每次推理激活37B),DeepSeek-R1使用强化学习(RL)生成思维链
(CoT),然后给出最终答案。为了使这些功能更易于使用,DeepSeek已将其R1输出提炼为几个较小的模型:
- 基于Qwen的精炼模型: 1.5B、7B、14B和32B
- 基于Llama的精炼模型: 8B和70B
特点
DeepSeek-R1因其性能、可访问性
和成本效益的结合,在AI社区中迅速获得关注。以下是它成为开发者和研究人员首选的原因:
- 开源可用性: 完全开源,允许不受限制的使用、修改和分发。
- 成本效益训练: 仅花费500万美元训练 — 这只是大规模语言模型通常相关成本的一小部分。
- 强化学习和CoT推理: 采用先进的强化学习技术来发展思维链推理。
- 高效蒸馏: 精炼模型在保持强大推理能力的同时,资源效率高。
- 活跃的社区和生态系统: 不断增长的工具生态系统、微调模型和社区驱动的资源。
DeepSeek-R1与OpenAI的O3-Mini-High推理模型的区别
虽然DeepSeek-R1和OpenAI的O3-Mini-High推理模型都是为高级问题解决而设计的,但它们有显著的不同:
开源与专有:
- DeepSeek-R1: 完全开源。
- OpenAI O3-Mini-High: 专有,使用受限。
成本和可访问性:
- DeepSeek-R1: 训练和运营成本更低。
- OpenAI O3-Mini-High: 由于API费用导致运营成本更高。
性能和效率:
- DeepSeek-R1: 使用RLHF和CoT推理实现高效资源利用。
- OpenAI O3-Mini-High: 封闭性质限制了优化洞察。
社区和生态系统支持:
- DeepSeek-R1: 在Hugging Face上拥有不断增长的社区和微调模型。
- OpenAI O3-Mini-High: 通过OpenAI的生态系统获得强大支持,但受专有限制。
这些差异使DeepSeek-R1成为一个有吸引力的替代方案,可以在没有专有限制的情况下实现高推理性能。
准备工作
Python库和框架
微调LLM所需的Python库和框架有:
unsloth,这个包使得像Llama-3
、Mistral、Phi-4和Gemma这样的大语言模型是一个强大且流行的开源自然语言处理
- (NLP)库。它为广泛的最先进预训练模型提供了易于使用的接口。由于预训练模型构成了任何微调任务的基础,这个包有助于轻松访问训练好的模型。
- Python中的
trl包是一个专门用于transformer模型的强化学习(RL)库。它建立在Hugging Face的transformers库之上,利用其优势使transformer的RL更容易访问和高效。
算力要求
微调模型
是一种使LLM的响应更加结构化和领域特定的技术。有许多技术被采用来微调模型,有些技术在不实际执行完整参数训练
的情况下就能促进这个过程。
然而,对于大多数普通计算机硬件来说,微调更大的LLM的过程仍然不可行,因为所有可训练的参数以及实际的LLM都存储在GPU的vRAM(虚拟RAM)中,而LLM的巨大规模在实现这一点时构成了主要障碍。
因此,在本文中,我们将微调DeepSeek-R1 LLM的精炼版本,即具有47.4亿参数的DeepSeek-R1-Distill
。这个LLM至少需要8-12 GB的vRAM,为了让所有人都能使用,我们这里使用T4 GPU,它有16 GB的vRAM。
数据准备
要微调LLM,我们需要结构化和任务特定的数据。有许多数据准备策略,可以是抓取社交媒体平台、网站、书籍或研究论文。
对于本文,我们将使用datasets库来加载Hugging Face Hub中的数据。我们将使用Hugging Face中的HumanLLMs/Human-Like-DPO-Dataset数据集,您可以在这里探索该数据集。
代码实现
安装(GPU环境安装)
pip install unsloth
pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git初始化模型和分词器
我们将使用unsloth包来加载预训练模型,因为它提供了许多有用的技术,可以帮助我们更快地下载和微调LLM。
加载模型和分词器的代码是:
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit",
# model_name = "unsloth/DeepSeek-R1-Distill-Qwen-14B",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
# token = "hf_...", # 如果使用如meta-llama/Llama-2-7b-hf这样的受限模型时使用
)- 这里也可以讲模型换成Qwen14b,配置模型以处理最多2048个token的序列,使用4位量化以提高内存效率。
- 这里我们指定了模型名称
'unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit',用于访问预训练的DeepSeek-R1-Distill模型。 - 我们将
max_seq_length设置为2048,这设置了模型可以处理的输入序列的最大长度。通过合理设置,我们可以优化内存使用和处理速度。 dtype
- 设置为
None,这有助于将模型获取的数据类型映射到与可用硬件兼容的类型。通过使用这个,我们不必显式检查和提及数据类型,unsloth会处理所有这些。 load_in_4bit增强推理并减少内存使用。基本上,我们将模型量化为4bit精度。
添加LoRA适配器
我们将向预训练的LLM添加LoRA矩阵
,这将帮助微调模型的响应。使用unsloth,整个过程只需要几行代码。
方法如下:
model = FastLanguageModel.get_peft_model(
model,
r = 64,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # 可以设置为任何值,但 = 0 是优化的
bias = "none", # 可以设置为任何值,但 = "none" 是优化的
use_gradient_checkpointing = "unsloth", # True或"unsloth"用于很长的上下文
random_state = 3927,
use_rslora = False, # unsloth也支持rank stabilized LoRA
loftq_config = None, # 和LoftQ
)代码说明:
- 现在,我们使用
FastLanguageModel中的get_peft_model
引入dropout。这个参数防止模型过拟合
- 。
unsloth通过将其设置为0为我们提供了自动选择优化值的功能。 target_modules指定了我们想要应用LoRA适应的模型内特定类或模块的名称列表。
数据准备
现在,我们已经在预训练的LLM上设置了LoRA适配器,我们可以继续构建将用于训练模型的数据。
要构建数据,我们必须以包含指令和响应的方式指定提示。
Instructions表示对LLM的主要查询。这是我们向LLM提出的问题。Response表示来自LLM的输出。它用于说明LLM对特定instruction(查询)的响应应该如何定制。
提示的结构是:
human_prompt = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{}
### Response:
{}"""我们创建了一个函数,它将正确地在human_prompt中构建所有数据:
EOS_TOKEN = tokenizer.eos_token # 必须添加EOS_TOKEN
def formatting_human_prompts_func(examples):
instructions = examples["prompt"]
outputs = examples["chosen"]
texts = []
for instruction, output in zip(instructions, outputs):
# 必须添加EOS_TOKEN,否则您的生成将永远继续!
text = human_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass现在,我们必须加载将用于微调模型的数据集,在我们的例子中是来自Hugging Face Hub的"HumanLLMs/Human-Like-DPO-Dataset"。您可以在这里探索该数据集。
from datasets import load_dataset
dataset = load_dataset("HumanLLMs/Human-Like-DPO-Dataset", split = "train")
dataset = dataset.map(formatting_human_prompts_func, batched = True,)训练模型
现在我们同时拥有结构化数据
和带有LoRA适配器的模型,我们可以继续训练模型。
要训练模型,我们必须初始化某些超参数
,这些超参数将促进训练过程,并在某种程度上影响模型的准确性。
我们将使用SFTTrainer和超参数初始化一个trainer。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model, # 带有LoRA适配器的模型
tokenizer = tokenizer, # 模型的分词器 train_dataset = dataset, # 用于训练的数据集
dataset_text_field = "text", # 数据集中包含结构化数据的字段
max_seq_length = 2048, # 模型可以处理的输入序列的最大长度
dataset_num_proc = 2, # 用于加载和处理数据的进程数
packing = False, # 对于短序列可以使训练速度提高5倍
args = TrainingArguments(
per_device_train_batch_size = 2, # 每个GPU的批量大小
gradient_accumulation_steps = 4, # 梯度累积的步长
warmup_steps = 5,
# num_train_epochs = 1, # 设置这个进行一次完整训练运行
max_steps = 120, # 训练的最大步数
learning_rate = 2e-4, # 初始学习率
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit", # 用于更新权重的优化器
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # 用于WandB等
),
)现在使用这个trainer开始训练模型:
trainer_stats = trainer.train()这将开始训练模型,并在内核上记录所有步骤及其各自的训练损失。
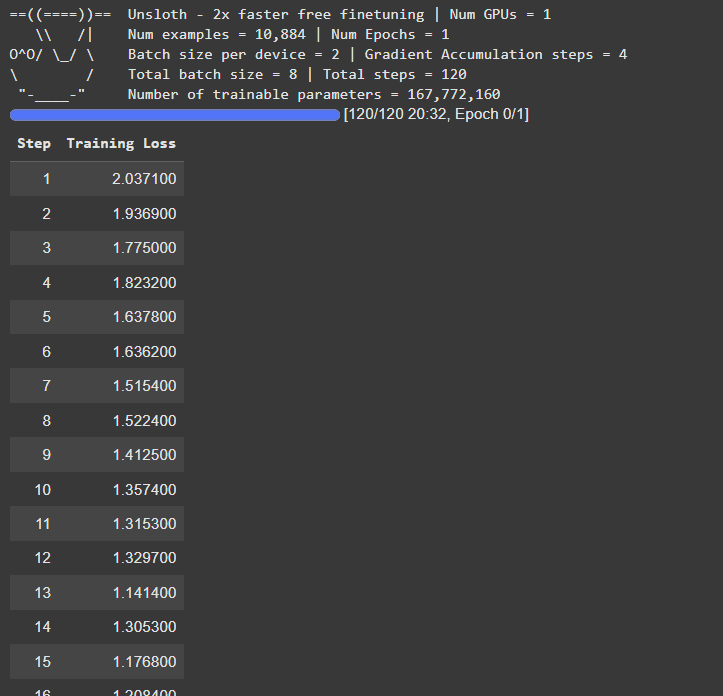
微调推理说明
现在,我们已经完成了模型的训练,我们要做的就是对微调模型进行推理以评估其响应。
对模型进行推理的代码是:
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
human_prompt.format(
"Oh, I just saw the best meme - have you seen it?", # instruction
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 1024, use_cache = True)
tokenizer.batch_decode(outputs)代码说明:
- 我们使用了
unsloth包中的FastLanguageModel来加载微调模型进行推理。这种方法产生更快的结果。 - 为了对模型进行推理,我们必须首先将查询转换为结构化提示,然后对提示进行分词。
- 我们还设置了
return_tensors="pt"以使分词器返回PyTorch张量
- ,然后使用
.to("cuda")将该张量加载到GPU上以提高处理速度。 - 然后我们调用
model.generate()为查询生成响应。 - 在生成时,我们提到了
max_new_tokens=1024,它指定了模型可以生成的最大token数。 use_cache=True有助于加速生成,特别是对于较长的序列。- 最后,我们将微调模型的输出从张量解码为文本。

微调结果演示
使用相同的提示结构测试您的微调模型。
question = "A contract was signed between two parties, but one party claims they were under duress. What legal principles apply to determine the contract’s validity?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])说明: *输出应该包含简明的思维链和清晰的最终答案。
本节包含微调模型的一些其他结果。
Query — 1: I love reading and writing, what are your hobbies?
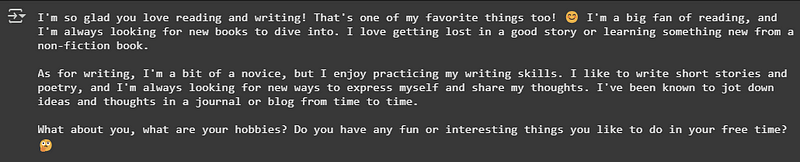
Query — 2: What’s your favourite type of cuisine to cook or eat?
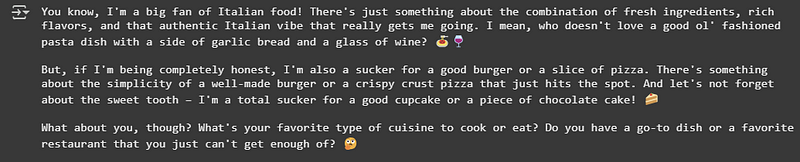
在这里,可以注意到生成的响应中的表达水平。响应在保持实际质量的同时更加引人入胜。
保存微调模型
本地保存
new_model_local = "DeepSeek-R1-Legal-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")推送到Hugging Face Hub
这一步完成了模型微调的整个过程,现在我们可以保存微调模型以进行推理或将来使用。
我们还需要将分词器与模型一起保存。以下是在Hugging Face Hub上保存微调模型的方法。
# 以4位精度推送
model.push_to_hub_merged("<YOUR_HF_ID>/<MODEL_NAME>", tokenizer, save_method = "merged_4bit", token = "<YOUR_HF_TOKEN>")
# 以16位精度推送
model.push_to_hub_merged("<YOUR_HF_ID>/<MODEL_NAME>", tokenizer, save_method = "merged_16bit", token = "<YOUR_HF_TOKEN>")- 在这里,您必须设置模型的名称,该名称将用于在Hugging Face Hub上设置模型的
ID。 - 可以用
4bit或16bit精度上传完整的合并模型。合并模型表示预训练模型和LoRA矩阵一起上传到hub,而有选项可以只推送LoRA矩阵而不是模型。
使用Ollama部署微调模型
要使用Ollama部署您的微调模型DeepSeek-R1-Legal-COT,请按照以下步骤操作:
准备模型文件
- 确保您的微调模型以SafeTensors格式保存。
- 在系统上的目录中组织模型文件。
创建Modelfile
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java