
一文为你深度解析LLaMA2模型架构
一、前言
随着人工智能技术的不断发展,自然语言处理(NLP)领域也取得了巨大的进步。在这个领域中,LLaMA展示了令人瞩目的性能。今天我们就来学习LLaMA2模型,我们根据 昇思MindSpore技术公开课·大模型专题(第二期)第六讲_云视界live_直播_云社区_华为云 (huaweicloud.com) 视频内容进行了学习整理,输出如下内容,欢迎大家前来指正。
二、LLaMA 介绍
1. LLaMA 简介
LLaMA 由 Meta AI 公司2022年发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,整个训练数据集在 token 化之后大约包含 1.4T 的 token。LLaMA 的性能非常优异:具有 130 亿参数Llama 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B,LLaMA 模型参数如下:
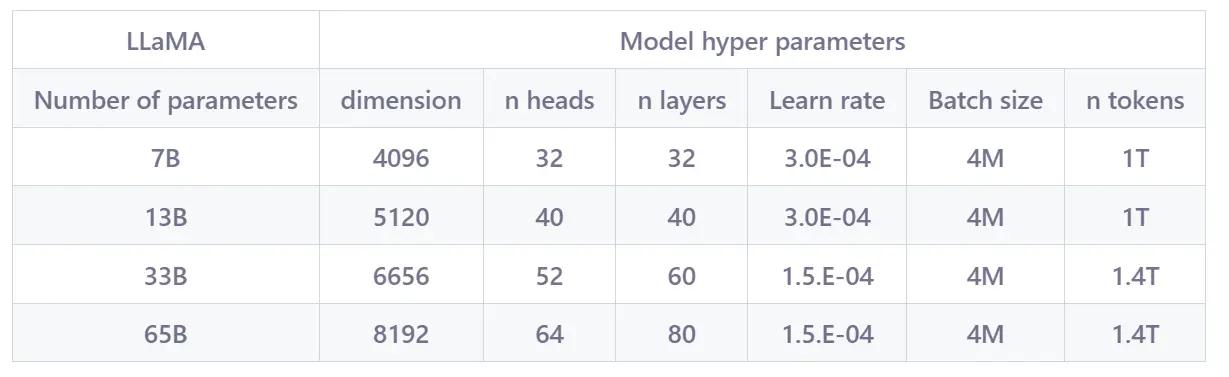
2. LLaMA 1 与 LLaMA 2 对比
LLaMA2是Meta最新开源的大型语言模型,其训练数据集达到了2万亿token,显著扩大了处理词汇的范围。此外,LLaMA2对上下文的理解长度也从原来的LLaMA模型的2048个token扩大到了4096个token,使得这个模型能够理解并生成更长的文本。LLaMA2包含7B、13B和70B三种规模的模型,它们在各种语言模型基准测试集上都展示了优异的性能。值得一提的是,LLaMA2模型不仅适用于语言研究,也可用于商业应用。总的来说,LLaMA2是目前开源的大型语言模型(LLM)中表现最出色的一种。

相比于 LLaMA 1 ,LLaMA 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2预训练模型是在2 万亿的 token上训练的,精调 Chat 模型是在100 万人类标记数据上训练的,具体对比分析如下:
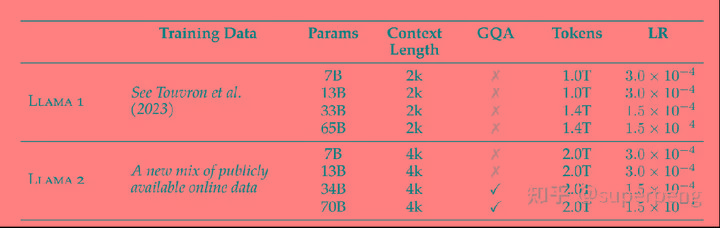
1)总token数量增加了40%:LLaMA 2训练使用了2 万亿个token的数据,这在性能和成本之间提供了良好的平衡,通过对最真实的来源进行过采样,以增加知识并减少幻觉。
2)加倍上下文长度:LLaMA 2 支持更长的上下文窗口,使模型能够处理更多信息,这对于支持聊天应用中的更长历史记录、各种摘要任务和理解更长文档特别有用。
3)Grouped-query attention (GQA):LLaMA 2支持GQA,允许在多头注意力(MHA)模型中共享键和值投影,从而减少与缓存相关的内存成本。通过使用 GQA,更大的模型可以在优化内存使用的同时保持性能。
三、LLaMA2核心介绍
1. 与Transformers架构的区别
Transformer模型是一种基于自注意力机制的神经网络模型,旨在处理序列数据,特别是在自然语言处理领域得到了广泛应用。Transformer模型的核心是自注意力机制(Self-Attention Mechanism),它允许模型关注序列中每个元素之间的关系。这种机制通过计算注意力权重来为序列中的每个位置分配权重,然后将加权的位置向量作为输出。模型结构上,Transformer由一个编码器堆栈和一个解码器堆栈组成,它们都由多个编码器和解码器组成。编码器主要由多头自注意力(Multi-Head Self-Attention)和前馈神经网络组成,而解码器在此基础上加入了编码器-解码器注意力模块。Transformer与LLaMA 的模型结构对比如下:
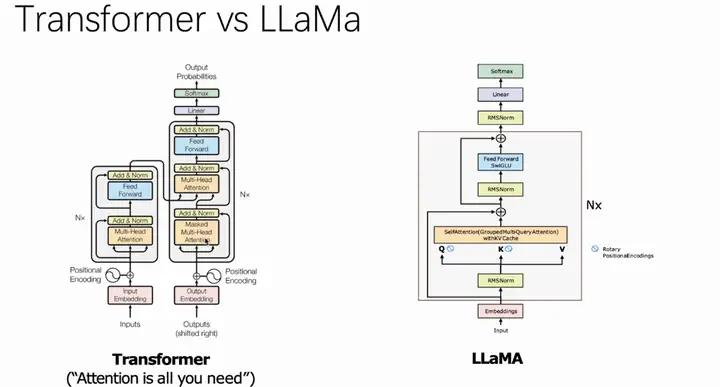
从Transformer的结构图中我们可以看出,Transformer主要分为编码器(encoder)和解码器(decoder)两部分。相较之下,LLaMA仅使用了Transformer的解码器部分,采取了一个仅解码器(decoder-only)的结构。这种结构现在被大多数生成型的语言模型所采用。在结构上,与Transformer模型相比,LLaMA2的主要变化是将其中的层标准化(LayerNorm)替换为了均方根标准化(RMSNorm),多头注意力(Multi-Head Attention)换成了分组查询注意力(GQA,在LLaMA中则是多查询注意力MQA),并将位置编码(Positional Encoding)替换为了旋转嵌入(Rotary Position Embedding,RoPE)。下面我们分别介绍RMS Normalization均方根标准化 ,Group Multi Query Attention分组查询注意力机制,SwiGLU Activation Function激活函数。
2. RMS Normalization 均方根标准化
LLaMA 2为了提高训练的稳定性,对每个transformer层的输入进行归一化,而不是输出进行归一化。同时,使用 RMS Norm 归一化函数。RMS Norm 的全称为Root Mean Square layer normalization,RMS Norm计算公式如下:
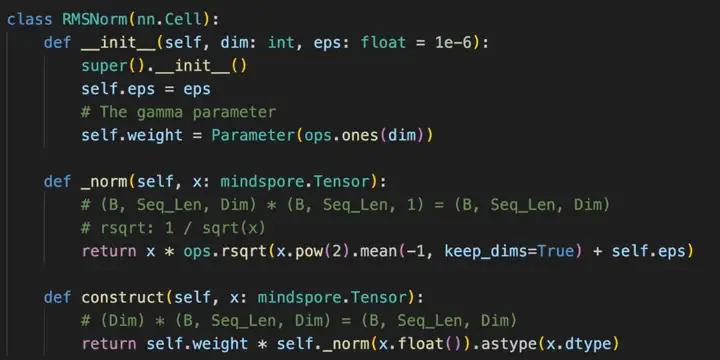
Layer Normalization(层归一化)和RMSNormalization(均方根归一化)都是神经网络中用于稳定训练过程的归一化技术。它们都旨在对神经网络中的激活进行规范化处理,以减少训练过程中的内部协变量偏移(Internal Covariate Shift)问题。尽管它们的目标相似,但在实现和应用上存在一些差异。与Layer Norm 相比,RMS Norm的主要区别在于去掉了减去均值的部分,它可以使得网络的训练更加稳定,加快收敛速度,并在一定程度上改善网络的泛化能力。具体来说,每一层的标准化操作都会调整该层输入数据的均值和方差,使其保持在一个稳定的数值范围内。RMS Norm 的作者认为这种模式在简化了Layer Norm 的计算,可以在减少约 7%∼64% 的计算时间。
3. Group Multi Query Attention 分组查询注意力
在各种多头注意力机制比较中,原始的多头注意力机制(MHA,Multi-Head Attention)使得QKV三部分具有相等数量的“头”,并且它们之间是一一对应的。每一次计算注意力时,各个头部的QKV独立执行自己的计算,最后将所有头部的结果加在一起作为输出。标准的MHA就是这样一个模型,其中Q、K、V分别对应了h个Query、Key和Value矩阵:
相对于MHA,多查询注意力(MQA,Multi-Query Attention)则略有不同。MQA保持了原来的Query头数,但是只为K和V各设置了一个头,即所有的Query头部都共享同一个K和V组合,因此得名为“多查询”。据实验发现,这种机制通常可以提高30%-40%的吞吐量,对性能的影响相对较小。MQA是一种多查询注意力的变体,被广泛用于自回归的解码。与MHA不同,MQA让所有的头部在K和V之间实现共享,每个头部只保留一份Query参数,从而大大降低了K和V矩阵的参数量。
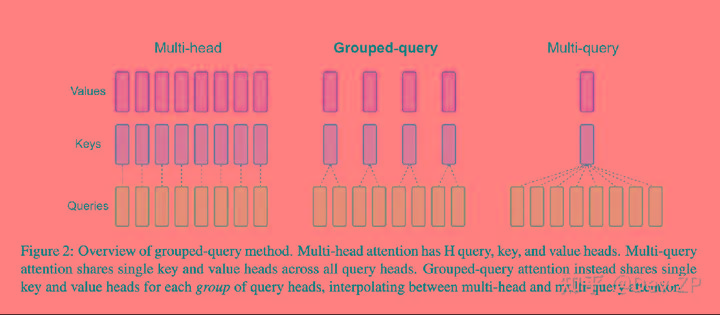
分组查询注意力(GQA,Grouped-Query Attention)综合了MHA和MQA,既避免了过多的性能损失,又能够利用MQA的推理加速。在GQA中,Query部分进行分组,每个组共享一组KV。GQA把查询头分成G组,每个组内部的头部共享一个相同的K和V组合。当G设为1,即GQA-1,则所有Query都共享同一组K和V,这时的GQA等效于MQA;而当G等于头的数量,即GQA-H,那么这时的GQA等效于MHA,具体差异及整体结构见下图:
4. SwiGLU Activation Function激活函数
SwiGLU 激活函数是Shazeer 在文献中提出,并在PaLM等模中进行了广泛应用,并且取得了不错的效果,相较于ReLU 函数在大部分评测中都有不少提升。在LLaMA 中全连接层使用带有SwiGLU 激活函数的FFN(Position-wise Feed-Forward Network)的计算公式如下:
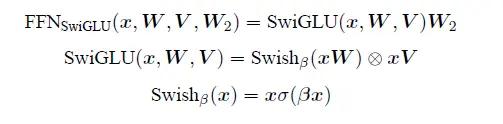
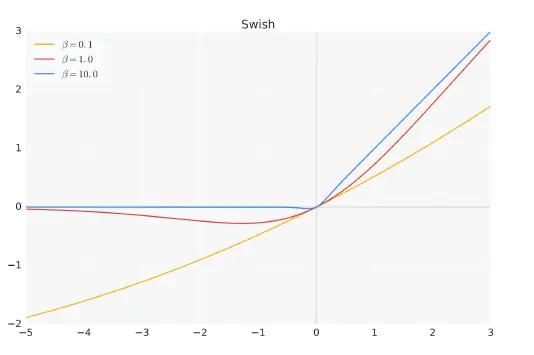
σ(x) 是Sigmoid 函数,Swish 激活函数在参数β 不同取值下的形状,可以看到当β 趋近于0 时,Swish 函数趋近于线性函数y = x,当β 趋近于无穷大时,Swish 函数趋近于ReLU 函数,β 取值为1 时,Swish 函数是光滑且非单调。在HuggingFace 的Transformer 库中Swish1 函数使用silu 函数 代替,见下图Swish 激活函数在参数β 不同取值下的形状:
关于激活函数的作用,种类,以及使用场景,由于篇幅限制,这里不做过多介绍,可自行百度。
四、与国内大模型对比
1. 模型参数
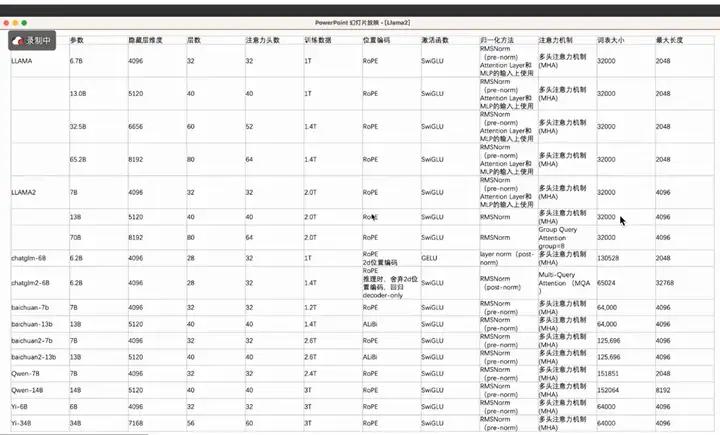
下面我们整理了LLaMA 系列,ChatGLM系列,BaiChuan系列,Qwen系列以及Yi系列等众多模型的数据,我们从训练数据,位置编码,激活函数,归一化方法以及注意力机制这几个维度分别对几个模型进行分析。
1)训练数据
LLaMA 7B和13B使用了1T的训练数据,LLAMA2对应使用了2T的数据,在训练数据上增加了一倍;ChatGLM 6B使用了1T的数据,ChatGLM2 6B使用了1.4T的数据,增加了40%;BaiChuan-7B使用了1.2T的数据,BaiChuan2-7B使用了2.6T的数据,训练数据增加了120%。看的出来,BaiChuan2在6B这个参数量级使用的训练数据是最多的,当然模型的表现也是有目共睹的。
2)位置编码
LLaMA,LLaMA2,ChatGLM,Qwen,Yi模型都是使用了RoPE位置编码,BaiChuan 13B模型使用的是ALiBi编码,BaiChuan 7B使用的是RoPE编码,百川大模型维护了俩套代码,,RoPE是主流位置编码。
3)激活函数
LLAMA,LLAMA2,Qwen,Baichuan,Yi模型都使用的是SwiGLU激活函数,ChatGLM1使用的是GELU激活函数,ChatGLM2使用了SwiGLU激活函数,SwiGLU是目前使用最广泛的激活函数。
4)归一化方法
LLaMA,LLaMA2,Qwen,Baichuan,Yi模型使用的归一化方位为RMS Norm, ChatGLM1使用的是Layer Norm,ChatGLM2使用了RMS Norm,大家默认都是用RMS Norm 归一化方法。
5)注意力机制
LLaMA,LLaMA2 7B,LLAMA2 13B,Qwen,ChatGLM-6B,BaiChuan,Yi模型使用的事MHA(多头注意力机制),LLaMA2 70B和ChatGLM2-6B 使用的是GQA(分组查询注意力机制)。
2. 模型测评
在众多国内开源模型之中,百川智能发布的Baichuan-7B、清华大学和智谱AI发布的ChatGLM2-6B、上海人工智能实验室发布的InternLM-7B等优秀模型广受业界关注。下表列出了这几个7B量级模型在几个有代表性评测集上的表现:
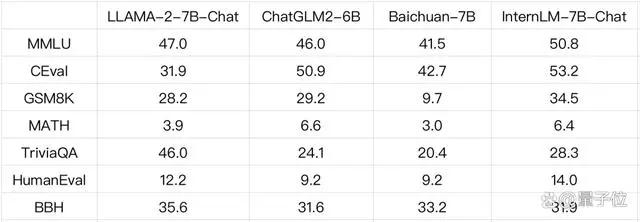
LLaMA-2在知识能力上有明显优势。但在学科、语言、推理和理解能力上,InternLM和ChatGLM2都已经超越了LLaMA-2,而且InternLM的领先优势十分明显。
五、问题解答
问题1:模型的上下文的记忆处理技术有哪些?
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java