
十倍提升JS代码运行效率的技巧
一、V8 compiler pipeline
js 代码从源码到执行 —— v8 编译器管线:
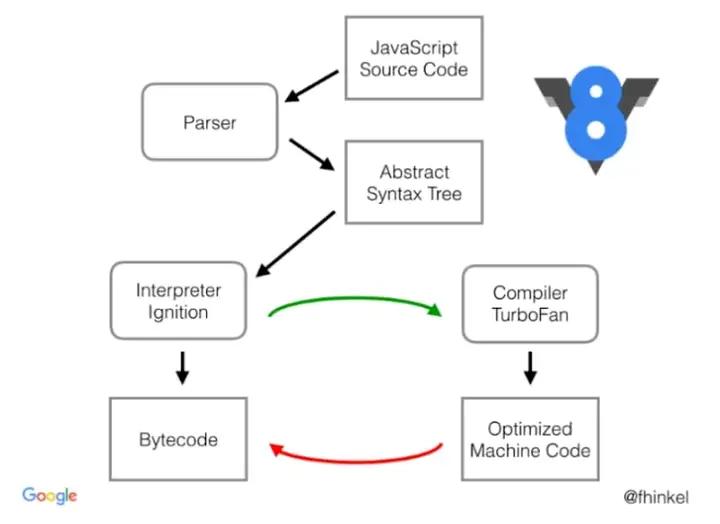
parser 将源码编译为 AST,并在 AST 基础上编译为「字节码 bytecode」
ignition 是 v8 的字节码解释器,可以运行字节码,并在运行过程中持续收集「feedback」即绿线,给到 turbofan 做最终的机器码编译优化。
而由于 js 是相当动态的语言,编译出来的「机器指令」未必能正确,因此其运行过程中有可能要回滚到 ignition 解释器来运行,这些问题通过「红线」反馈给 ignition 解释器,这个过程叫做「反优化」。
—— 更具体来说:
1. Parser (Source => Token => AST)
将源码一段线性 buffer string 解析为 Token 流,最后依据 Token 流生成 AST 树状构造,这是所有语言都会有的过程。
2. 绿线与 feedback
运行过程中产生并持续收集的反馈信息,比如多次调用 add(1, 2) 就会产生「add 函数的两个参数 “大概率” 是整数」的反馈,v8 会收集这类信息,并在后续 TurboFan codegen 的时候根据这些反馈来做假设,并依据这些假设做深度优化,后文将从汇编的角度讨论这个细节。
3. 红线与反优化 deoptimize
前面提到 「add 函数的两个参数 “大概率” 是整数」 的假设,当假设被打破的时候会触发所谓的「deoptimize」反优化,比如你在运行了很久的 add(number, number) 上突然来一个 add("123", "abc") 那么此时就会降级重新回到 ignition bytecode 执行。
4. Iginition 和 TurboFan
前者生成 byte code,后者根据执行过程中收集的 feedback 来生成深度优化的 machine code
二、V8 核心组件:Ignition 与字节码 / TurboFan 与机器码
1. 代码的执行层次: 从源码到字节码再到机器码其实就是不断编译的过程
世界上能执行代码的地方有很多,数轴上的两个极端: 左边是抽象程度最高的人脑,右边是抽象程度最低的 CPU:

上图中三个实体以不同的角度理解下面这样的代码,从源码到字节码再到机器码其实就是不断编译为另外一个语言的过程
const a = 3 + 4;a) 人脑的理解
计算 3+4 存储到 js 变量 const a 中
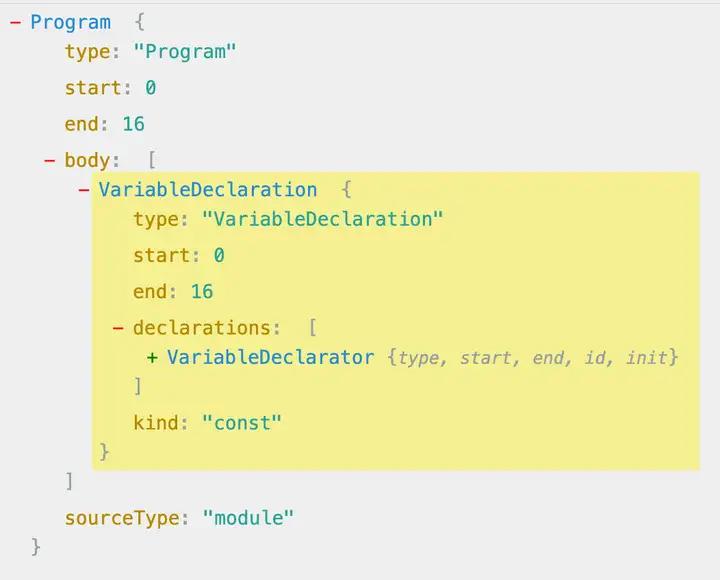
b) V8 parser 的理解
将代码解析为 AST 树(一种 JSON 结构)
c) V8 iginition 的理解
iginition 会将代码理解编译为 bytecode :
...
LdaSmi [3] // 加载字面量 3 到栈顶
Star0 // 将栈顶 3 pop 到寄存器 r0
Add r0, [4] // 计算 r0 + 4
...d) V8 TurboFan 的理解
TurboFan 会将代码理解为汇编:
...
mov ax 3 # 将 3 赋值到寄存器 ax
add ax 4 # 计算 ax = ax + 4
...2. 本质上来说 bytecode 和 x86 汇编是一样的
本质上来说 v8 bytecode 和 x86 汇编是一样的,只是世界上没有裸机能跑出 v8 所理解的 bytecode 而已,机器码为什么快是因为 CPU 能在硬件层面上裸跑汇编,因此速度特别快。
总之为了充分表达 js 动态特性以及方便优化为 CPU 能直接裸跑的汇编,v8 引入了 bytecode 这个层次,它比 AST 更接近物理机,因为它没有层次嵌套,是一种基于寄存器的指令集。
3. 编译时机: JIT / AOT
JIT 指的是边运行边优化为机器码的编译技术,其中的代表有 jvm / lua jit / v8,这类优化技术会在运行过程中持续收集执行信息并优化程序性能。 AOT 指的是传统的编译行为,在静态类型语言(如 C、C++、Rust)和某些动态类型语言(如 Go、Swift)中得到了广泛应用,由于能提前看到完整代码,编译器/语言运行时可以在编译阶段进行充分的优化,从而提高程序的性能。
由于 JIT 语言并不能提前分析代码并优化执行,因此 JIT 语言的「编译期」很薄,而「运行时」相当厚实,诸多编译优化都是在代码运行的过程中实现的。
4. Ignition 与字节码
ignition 负责解释执行 V8 引入的中间层次字节码,上接人脑里的 js 规范,下承底层 CPU 机器指令
5. TurboFan 与机器码
TurboFan 可以将字节码编译为最快的机器码,让裸机直接运行,达到最快的执行速度。
三、V8 内置 runtime 指令 --allow-natives-syntax
利用这个参数开启 v8 注入的 runtime call,帮助分析和调试 v8
# node 下开启
$ node --allow-natives-syntax
# chrome 下开启
$ open -a Chromium --args --js-flags="--allow-natives-syntax"
下面是一些常用指令说明。
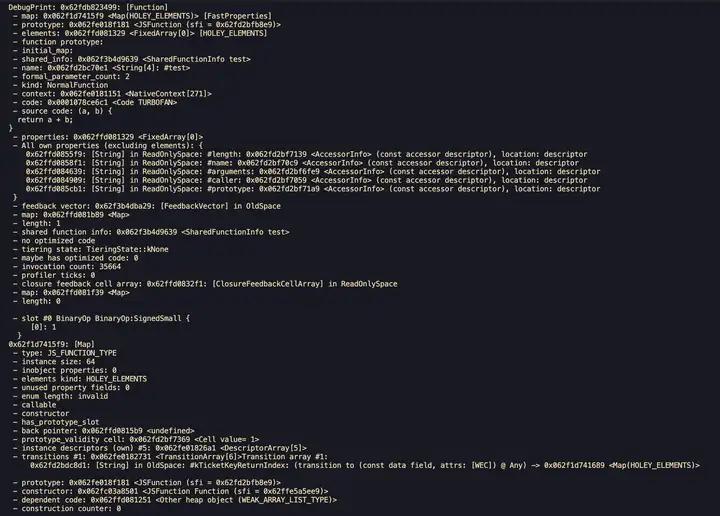
1. %DebugPrint(something);
可以打印对象在 v8 的内部信息,比如打印一个函数:
2. %OptimizeFunctionOnNextCall(fn);
告诉 v8 下次调用主动触发优化函数 fn
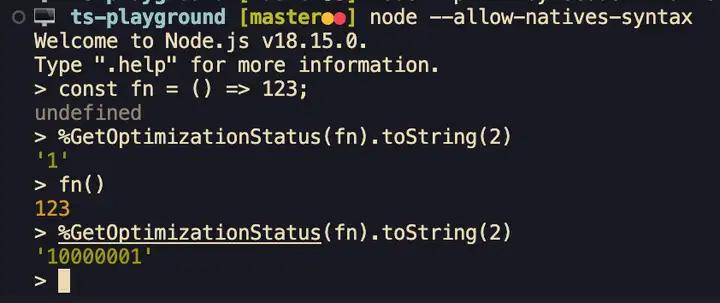
3. %GetOptimizationStatus(fn);
获取函数当前的优化 status,后文会详细介绍:
对应的是 V8 源码里的这个枚举:
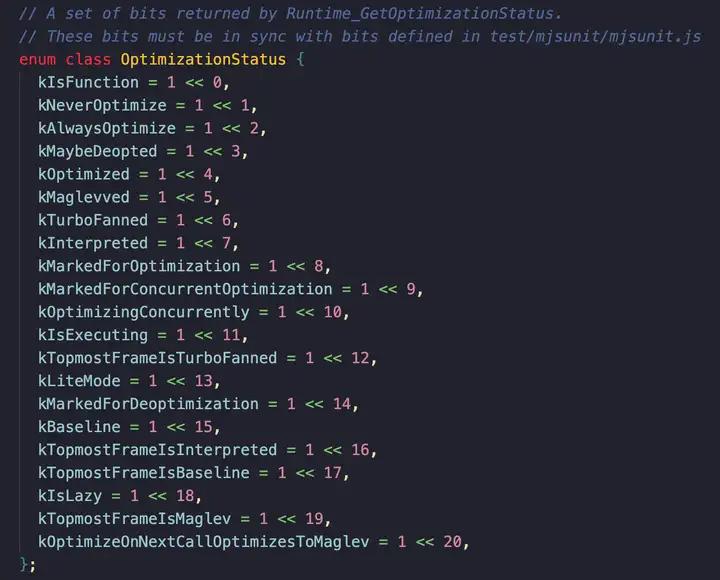
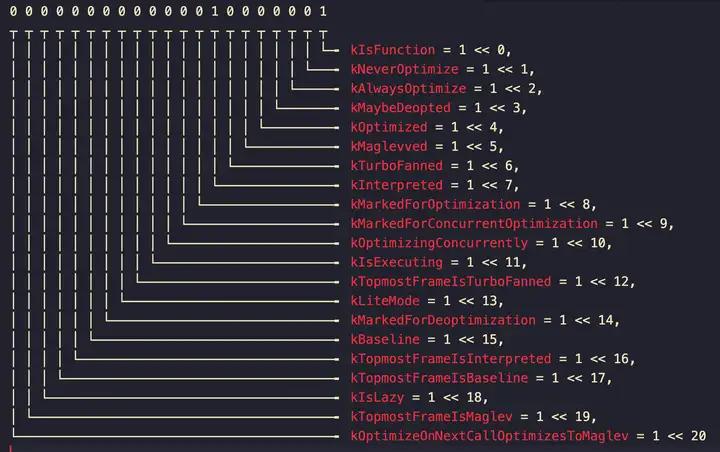
从开发视角来看,一个函数最佳的 status 应该是 00000000000001010001 (81) 即:
4. %HasFastProperties(obj);
%HasFastProperties 可以用来打印对象是否是 Fast Properties 模式
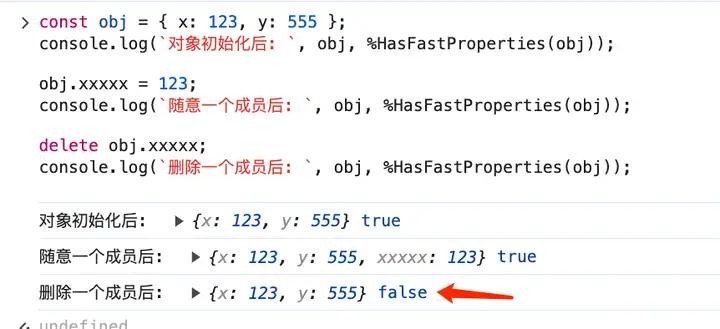
后文会介绍这个 Fast Properties 和与之对立的 Slow Properties。
四、V8 Tagged Pointer
首先 Tagged Pointer 是 C/C++ 里常用的优化技术,不只在 V8 里有用,具体来说就是依据 pointer 自身的数值的某些位来决定 pointer 的行为,也就是说这类指针的特点是「其指针数值上的某些位有特殊含义」。
比如在 v8 里,js 堆指针和 SMI 小整数类型(small intergers)是通过 Tagged Pointer 来表达和引用的,区别就在于最低一位是不是 0 来决定其指针类型:
对象指针(32 位):
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxx1SMI 小整数(32 位)其中 xxx 部分为数值部分:
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxx0用 C 表达就是这样:
#include <stdio.h>
void printTaggedPointer(void * p) {
// 强转一下, 关注 p 本身的数值
unsigned int tp = ((unsigned int) p);
if ((tp & 0b1) == 0b0) {
printf("p 是 SMI, 数值大小为 0x%x \n", tp >> 1);
return;
}
printf("p 是堆对象指针, Object<0x%x> \n", tp);
// printObject(*p); // 假设有个方法可以打印堆对象
}
int main() {
printTaggedPointer(0x1234 << 1); // smi
printTaggedPointer(17); // object
return 0;
}运行效果:
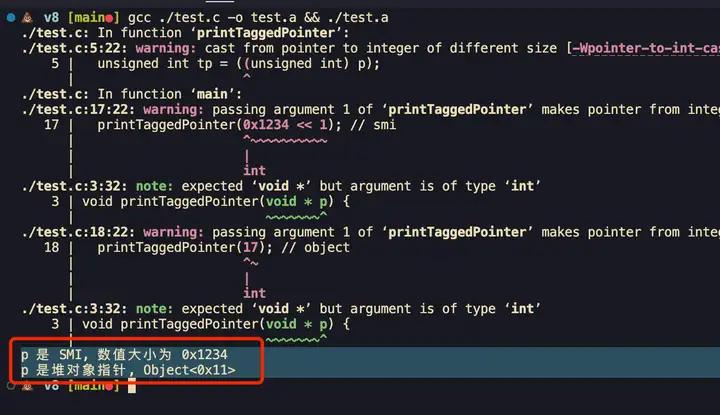
备注:
void *是 C 的any,强转比较多,请忽略 warning;- 从这也可以看到超过
2^31的整数或者浮点数就不能用 SMI 了,此时会装箱为特殊的 HeapObject 放进堆里 ); - 你可以通过
%DebugPrint({})和%DebugPrint(123)来看看其指针数值是不是整数,然后你会发现所有对象的指针数值都是奇数 Tagged Pointer ( 实际上 heap 内的都是奇数 heapdump 里也能看到这个细节 )。
五、V8 基于 assumption 的 JIT 机器码优化
我们先来看这个例子,一个 add(x,y) 函数,如果运行期间出现了多种类型的传参,那么会导致代码变慢:
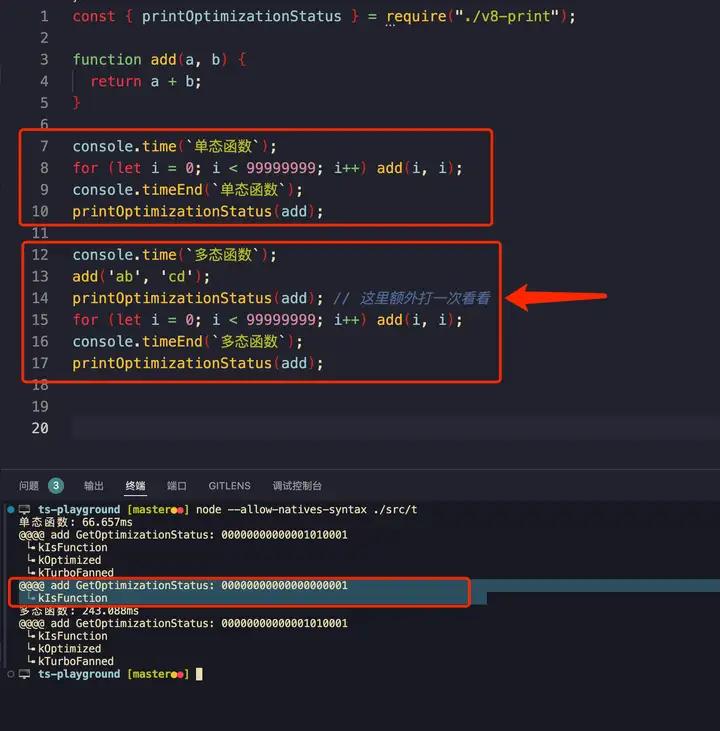
我们可以看到,L15 速度慢了非常多,比一开始的 66ms 慢了几倍。
原因:
- 一开始只会传数字的时候,V8 会假设这是数字加法,可以极致优化。(66 毫秒可以跑完)
- L13 传入其他参数,上述假设会被推翻,此时打印一次优化状态可以看看出现了
反优化,在 L13 执行的时候实际走的是 iginition 解释器去跑的。 - 执行 L15 for 循环走了足够多次后,V8 收集到足够的
feedback后会重新建立假设来做优化,不过这次的假设是「入参可能是 number 也可能是 string」—— 这意味着调用的时候要多判断入参类型是 string 还是 number 从而导致了最终的性能劣化 (一模一样的代码要 243 毫秒才跑完,慢了有三倍吧)。
1. assumption 被打破的时候不会 crash / 硬件错误 / 段错误吗?
比如一开始传的是 number,走到了优化过的代码,里面走的是汇编指令 add; 当传入 string 或者 其他什么合法的 JSValue 后,编译为汇编的 add 函数的执行真的没问题吗? —— 不会有问题,因为 TurboFan 在编译后的「机器码」里会带上很多 checkpoint,其实这些 checkpoint 就是在做类型检查 type guard,如果类型对不上立刻就会终止这次调用并执行「反优化」让 ignition 走字节码解释执行。
上述说法可能会比较含糊,我们可以具体看看打出来的汇编是咋样的,可以通过以下方式打印出优化后的 x86 汇编(m1 芯片的苹果电脑应该是 arm 指令)。
$ node --print-opt-code --allow-natives-syntax --trace-opt --trace-deopt ./a.js如下图所示,这个 test 函数实现是将第一个入参加上 0x1234 并返回,而这个核心逻辑对应 L37 那行汇编,而其他的部分除了 v8 自身的「调用约定」外,其他的就是 checkpoint 检查类型,以及一些 debug 断点了:
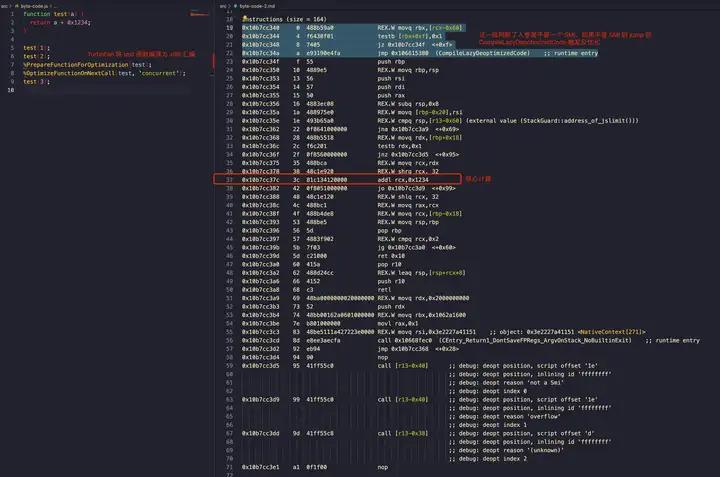
从前面的 Tagged Pointer 的相关讨论可知,L19 ~ L22 其实就是在判断入参是不是 SMI,具体来说是 [rbx+0xf] 与 0x1 做按位与操作([rbx+0xf] 是通过栈传递的参数,是 v8 里 js 的调用约定)如果结果是 0 则跳转 0x10b7cc34f 即后续的正常流程,否则走到 CompileLazyDeoptimizedCode 走反优化流程用字节码解释器去执行了,我这里大概写了一个反汇编伪码对照:
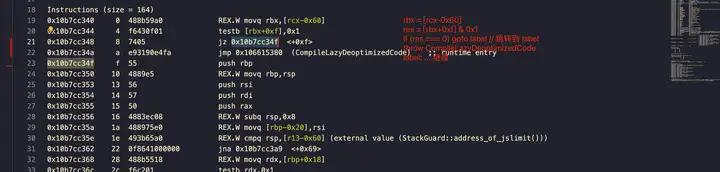
另外我们也可以看到,核心逻辑对应到汇编也就一行,剩余的指令要么是 checkpoint 要么是 v8/js 的调用约定,在这么多冗余指令的情况下执行性能依然很快,可见汇编的执行效率比起 line-by-line 的解释器要高得多了。
2. 哪里可以打印所谓 feedback ?
通过 %DebugPrint 可以看到
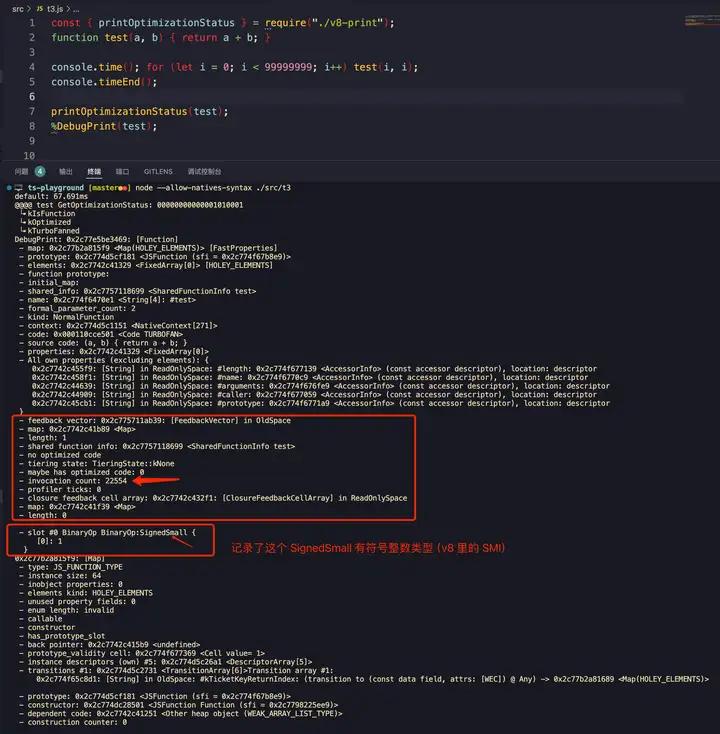
当打破这个 assumption 后,会变成 Any:
3. 多态 return 会导致优化效果打折吗?
不会
4. feedback slot 里的 MonoPoly|Mega|morphic 是?
- Monomorphic 单态:指参数的类型只有一种,不会变
- Polymorphic 多态:指参数的类型有多种 (比较短的 union type)
- Megamorphic 巨态:指参数的类型非常复杂 (非常长的 union type)
根据前面提到的 checkpoint,上面三个 mono 的 checkpoint 最少,而最后的 mega 将会非常多,优化性能最差,或者 V8 干脆就不会对这类函数做更深度的机器码优化了(比如后文会提到的 ICs)
5. TurboFan 过程本身耗时怎么样?
从 JS AST / bytecode 编译到机器码也需要开销,毫秒级。
6. 反优化太多次怎么办?
根据这篇文章 V8 function optimization - Blog by Kemal Erdem 如果某个函数「反优化」超过 5 次后,v8 以后就不再会对这个函数做优化了,不过我无法复现他说的这个情况,可能是老版本的 v8 的表现,node16 不会这样,不管怎样只要 run 了足够多次都turbofanned,只是如果「曾经传的参数类型太 union typed」会导致优化效果出现非常大的折损。
7. 什么时候会启动 TutboFan ?
前面我们已经知道了「运行足够多次」会触发优化,而这只是其中一种情况,具体可以参考 v8 里 ShouldOptimize 的实现,里面有详细定义何时启动优化:
作为开发视角来看:
- L371 已经优化过的代码不会再优化;
- L375 这段逻辑决定是否启用 maglev (具体见备注);
- L386 通过参数主动禁用/或者省电模式等这类不会优化 ( 比如 node --v8-options="--turbo_filter=xxxxx" );
- L394 运行足够多次才会优化 (还有个配置项 efficiency_mode_delay_turbofan 配置延迟多久启动 turbofan);
- L402 太长的函数不会优化。
备注:maglev 是去年 chrome v8 团队搞的新特性 —— 编译层次优化,总的来说就是根据 feedback 对机器码的编译层次做精细控制来达到更好的优化效果,下图是 v8 团队发布的 benchmark 对比:
具体可参考 v8.dev/blog/maglev
8. 编译后的代码会占内存吗?
会的,而且有时候这部分内存占用非常多,这也是 Chrome 经常被调侃为内存杀手的重要原因之一,以 qq.com 为例,具体对应是 heapdump 里的 (compiled code) 包含了编译后的代码内存占用:
六、 V8 对象模型
本节开始是本文的重点部分,因为只有了解 V8 对象的内存构造,才能真正理解 V8 诸多优化的理由。
1. C 语言的 struct 是怎么实现「点读」的 ?
在正式进入之前,我们先看看 C 里面 struct 的「点读」是怎么做的。
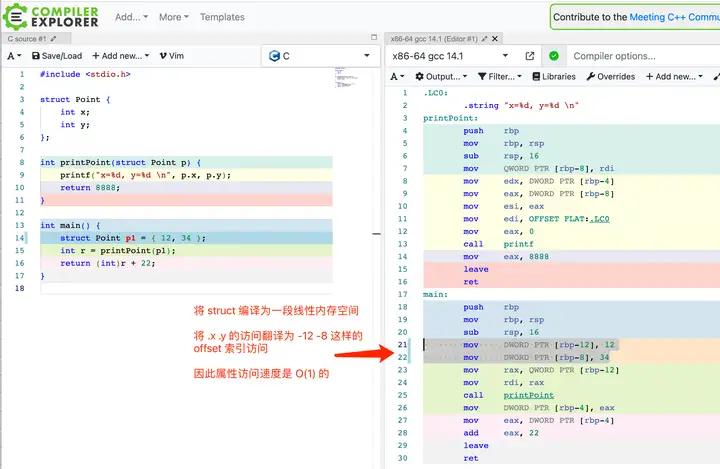
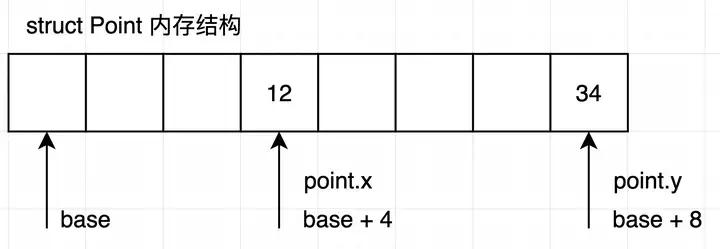
C 会将 struct 理解为一段连续的线性 buffer 结构,并在上面根据字段的类型来划分好从下标的哪里到哪里是哪个字段(对齐),因此在编译 point.x 的时候会改成 base+4 的方式进行属性访问,如下图所示,时间复杂度是 O(1) 的:
也因此 C 里面没提供从字段 key 名的方式去取 struct value 的方法,也就是不支持 point['x'] 这样,需要你自己写 getter 才能实现类似操作。
这类根据 string value 来从对象取值的技术通常在现代编程语言里都是自带了的,通常称为反射,可以在运行时访问源码信息。
但在 JS 里,对象是动态的,可以有任意多的 key-values,而且这些 kv 键值对还可能在运行时期间动态发生变化,比如我可以随时 p.xxx =123 又或者 delete p.xxx 去删掉它,这意味着一个 object 的 “shapes” 及其「内存结构」是无法被静态分析出来的,而且这种内存结构必然不是「定长固定」的,是需要动态 malloc 变长的。
假设现在是 2008 年,你是 google 的工程师,正在 chrome v8 项目组开发,你会怎样设计 JS 的对象的内存结构?
const obj = { x: 3, y: 5 }
// obj 的内存结构可以设计成怎样?一眼丁真,开搞:
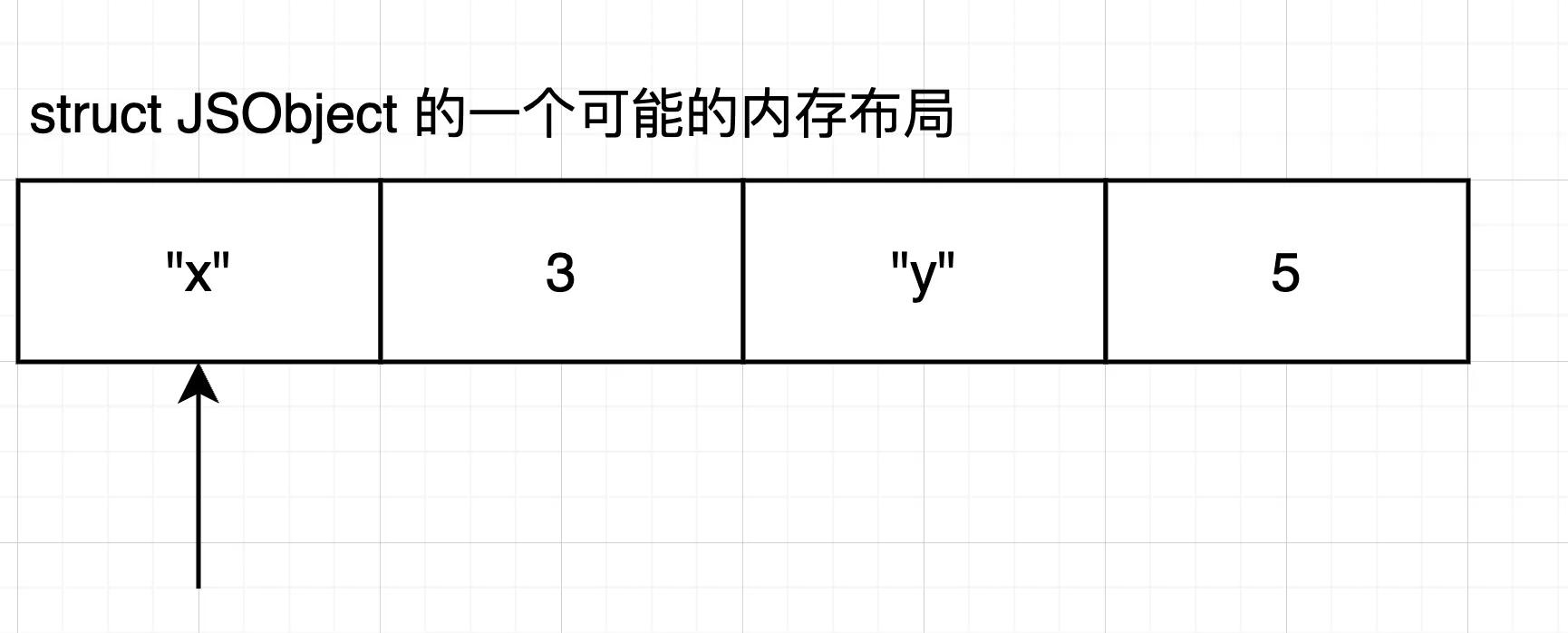
一个 key 定义加一个值,然后将这个结构数组化就可以表达对象的 kv 结构,增加属性就在后面继续扩增,查找算法则是从头查到尾,时间复杂度为 O(n)
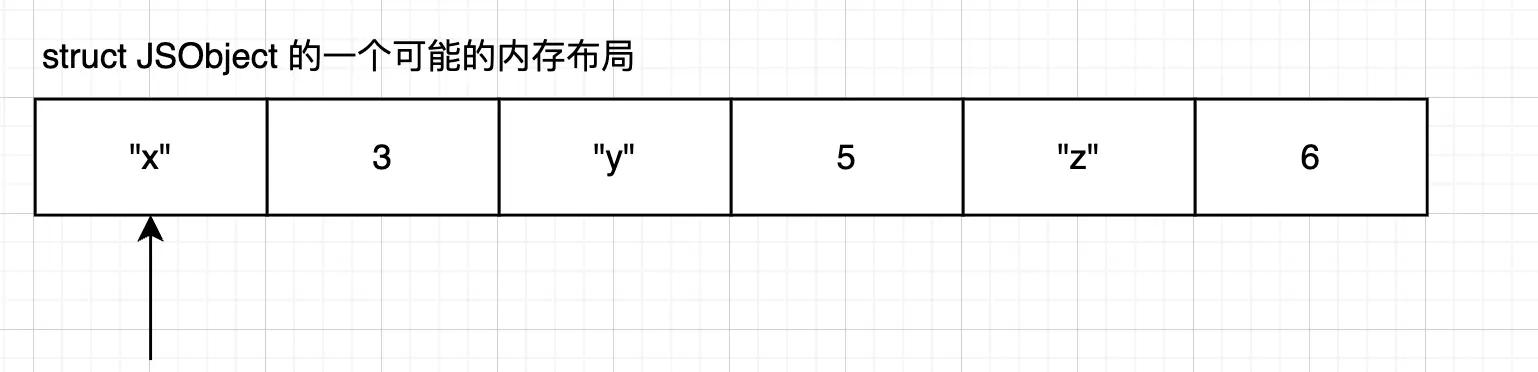
但是如果按这个设计,下面两个 obj 就会有重复的 key 定义内存消耗了:
const obj1 = { x: 11, y: 22 } // "x" 11 "y" 22
const obj1 = { x: 33, y: 44 } // "x" 33 "y" 44
// 会重复 "x" 和 "y"好了就上面这样简单弄一下就搞出了好多问题了。从下面开始正式进入,V8 是如何描述对象,参见下文。
2. JSObject 与 named-properties & indexed-elements
在 js 标准里 Array 是一类特殊的 Object,但出于性能考虑 V8 底层针对对象和数组的处理是不同的:
- 所谓 indexed-elements 指的是数组元素(以数字下标作为 key)存储于
*elements,是一段线性内存空间,可以直接用下标直接访问,查找速度非常快; - 而其他的普通成员所谓 named-properties 则存储于
*properties查找速度比较慢,需要遍历对比。
如下图所示,JSObject:
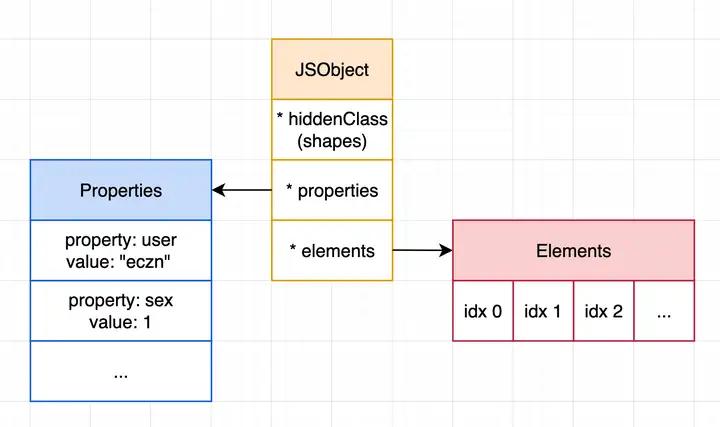
在 V8 里:
- Array-indexed 的属性存储在
*elements里,查找速度快;Named Properties 则存储在*properties里,查找速度慢; - Properties/Elements 这两个结构可以是数组,但有时候也会变成字典(比如稀疏数组场景,线性内存空间就不够性能了);
- 每个 JSObject 都有一个 *hiddenClass,用于保存对象的 Shapes。
嗯?对象的 Shapes?那是什么?
3. 对象的 Shapes
所谓对象的 shapes,其实就是对象上有什么 key,前面提到过 V8 的优化需要在运行时不断收集 feedback,比如当执行下面这段代码的时候,引擎就可以知道「obj 有两个 key,一个是 a 一个是 b」:
const obj = {}
obj.a = 123;
obj.b = 124;
doSomething(obj);V8 通过 Hidden Class 结构来记录 JSObject 在运行时的时候有哪些 key,也就是记录对象的 shapes,由于 JSObject 是动态的,后续也可以随意设置 http://obj.xxx = 123,也就是对象的 shapes 会变,也因此对象持有的 Hidden Class 会随着特定代码的运行而变化
Hidden Class 是比较学术的说法,在 V8 源码里的「工程命名」是 Map,在微软 Edge Chakra (edge) 里叫做 Types,在 JavaScriptCore (WebKit Safari) 里叫做 Structure,在 SpiderMonkey (FireFox) 里叫做 Shapes .... 总之各个主流引擎都有实现追踪「对象 shapes 变化」
后文可能会混淆上面几个用语,它们都是指 Hidden Class,用来描述对象的 shapes。
4. Hidden Class DescriptorArrays 与 in-object properties
前面提到除了 *properties 和 *elements 可以用来存储对象成员之外,JSObject 还提供了所谓 in-object properties 的方式来存储对象成员,也就是将对象成员保存在「JSObject 结构体」上,并配合 Hidden Class 进行键值描述:
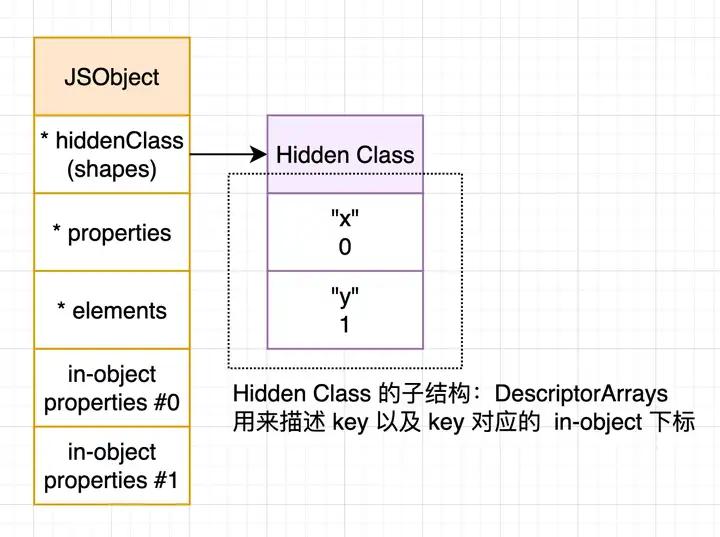
上图里 Hidden Class 里底下有个叫做 DescriptorArrays 的子结构,这个结构会记录对象成员 key 以及其对应存储的 in-object 下标,也就是上面的紫框。
或许你会问:
- 为什么要这样,这样做能帮助提升性能么?别急,后文会扣回来。
- 什么时候用
in-object什么时候用*properties存储,两者做的是同一件事,不会冲突吗?别急,后文会提。
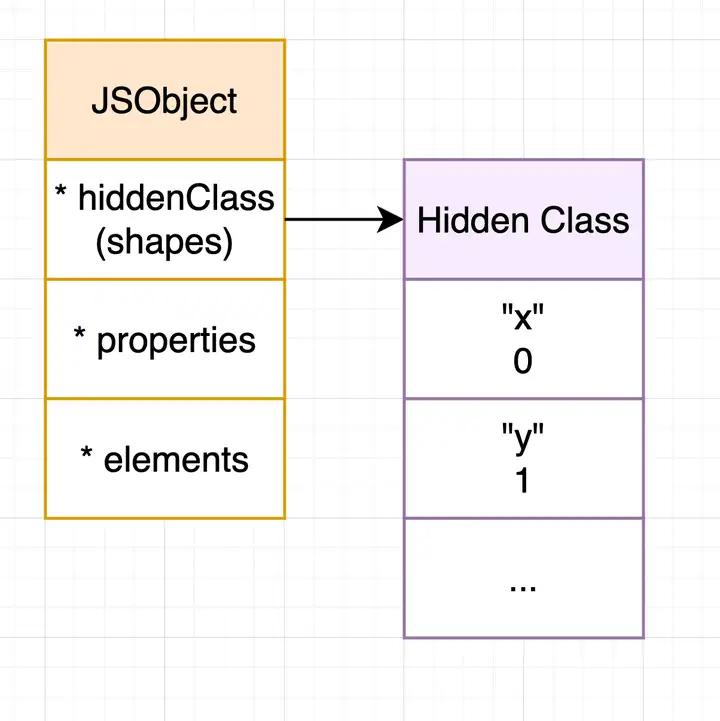
5. 变化中的 Hidden Class
如果 Hidden Class 是静态的,那么这图就足够描述 Hidden Class 了:
但是对象的 shapes 会变,也因此对象持有的 Hidden Class 会随着特定代码的运行而变化,V8 使用了 Transition Chain,一种基于链表构造的方式来描述「变化中的 Hidden Class」:
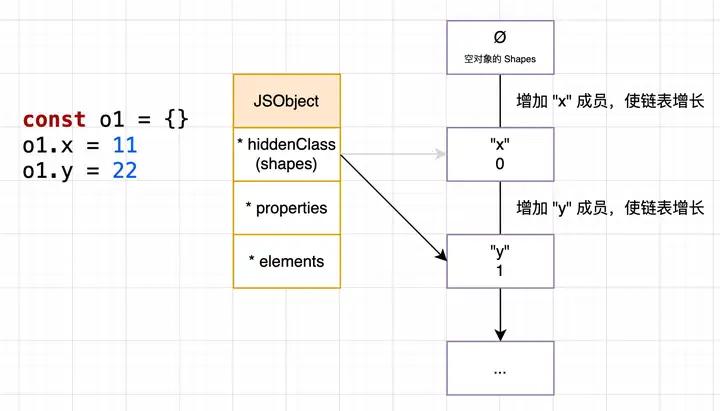
备注:为了方便讨论,后文可能不会将 Hidden Class 画成链表,而是画成一起并且省略空对象的 shapes,另外 Hidden Class Node 上还有其他字段,相对不那么重要,就忽略了
由于链表的特性,显然可以比较容易地让具有相同 shapes 的对象能复用同一个 Hidden Class ,比如下面这个 case,o1 o2 均复用了地址为 0xABCD 的 Hidden Class 节点:
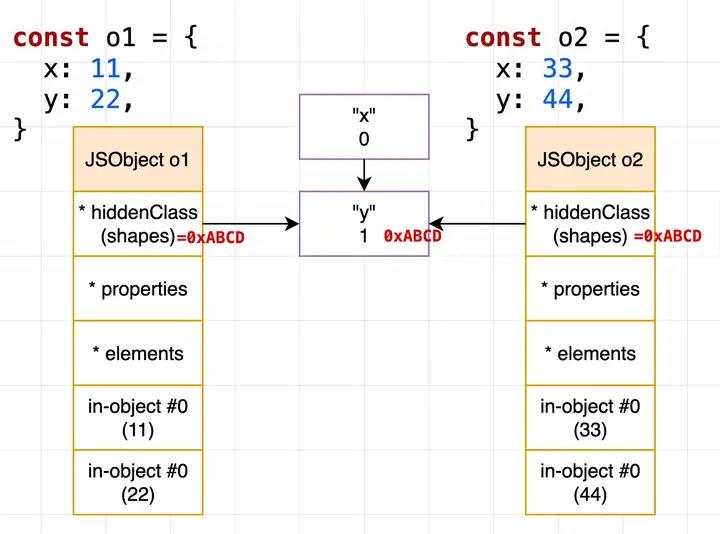
当出现不同走向的时候,此时会单独开一个 branch 来描述这种情况,此时 o1 和 o2 就不再一样了:
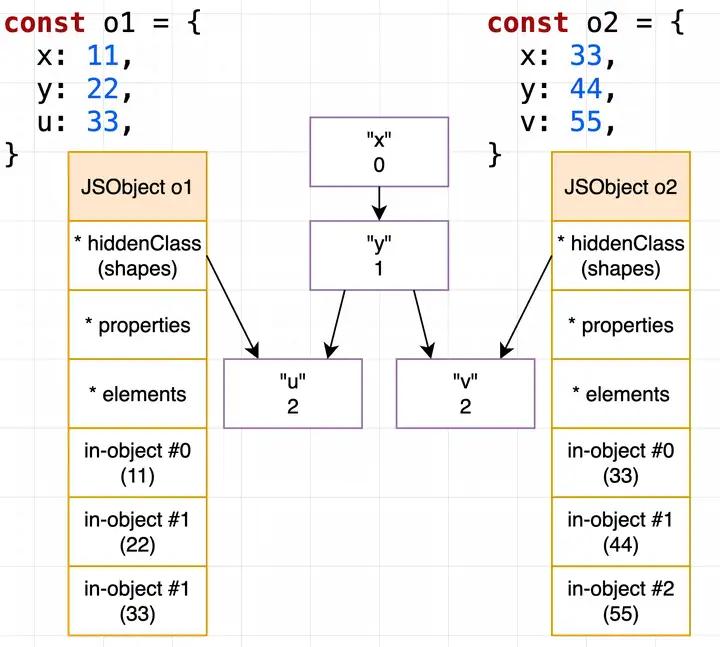
6. V8 对象模型总结
从前文的讨论,可以得到的结论:
- V8 使用 JSObject 来描述对象,上面有若干个字段(除了上面那些还有 prototype 原型链那些,相对不那么重要,就没画出);
- V8 还使用 Tagged Pointer 来描述对象指针(前文有提);
- named properties 成员存储在 *properties 里,可以为数组,也可以为字典
- named properties 也可以存储在
in-object properties里,可以动态增长; - 数字下标成员存储在
*elements里,可以为数组,也可以为字典(稀疏数组场景)。
悬而未决的问题:
1.何时用 in-object properties 何时用 *properties ?
2.为什么看起来 Hidden Class 这套机制下属性查找依然是 O(n) 的操作?追踪对象的 shapes 意义在哪?
请带着这两个问题到下一章 Inline Caches 继续阅读。
七、 Inline Caches (ICs) 优化原理
引入 Hidden Class 后,为了读取某个成员,那不还得查一次 Hidden Class 拿到 in-object 的下标,这个过程不还是 O(n) 吗?
是的,如果事先不知道 JSObject 的 shapes 的情况下去读取成员确实是 O(n) 的,但前面我已经提过了:
V8 的诸多优化是基于 assumption 的,那么在已知 obj 的 Shapes 的情况下,你会怎么优化下面这个 distance 函数?

如如此优化就可以将「通过遍历 *properties访问成员的 O(n)过程」直接优化为「直接按下标偏移直接读取 in-object 的 O(1) 过程」了,这种优化手段就叫做 Inline Caches (ICs),有点类似 C 语言的 struct 将字段点读编译为偏移访问,只不过这个过程是 JIT 的,不是 C 那样 AOT 静态编译确定的,是 V8 在函数执行多次收集了足够多的 feedback 后实现的。
你可能还会问:在调用优化后的 distance2 的时候具体要怎么确定传入的 p1 p2 的 shapes 是否有变化?还记得前面那个 0xABCD 吗?没错,编译后的汇编 checkpoint 就是直接判断传入对象的 hidden classs 指针数值是不是 *0xABCD*,如果不是就触发「反优化」兜底解释器模式运行即可。
—— 下面这个实例将手把手介绍 ICs 的真实场景以及汇编细节
1. 汇编实例:为什么静态的比动态的要好 ?
从前面 Inline Cache 的讨论中可以得知,必须要确定了访问的 key 才能做 ICs 优化,因此写代码的过程中,如有可能请尽量避免下面这样通过 key string 动态查找对象属性:
function test(obj: any, key: string) {
return obj[key];
}如果能明确知道 key 的具体值,此时建议写为:
function test(obj: any, key: 'a' | 'b') {
if (key === 'a') return obj.a;
if (key === 'b') return obj.b;
}即使确实不得不动态查询,但是你知道某个子 case 占了 99% 的调用次数,此时也可以这样优化:
function test(obj, key: 'a' | 'b') {
// 为 'a' 的调用次数占了 99% 可以这样提前优化
if (key === 'a') return obj.a;
return obj[key];
}静态和动态两种写法风格可能会有几倍甚至上百倍的差距,如果业务里有大几百万次的调用 test,优化后能省不少毫秒,比如下面这个「简化的服务发现」例子有近百倍的差距:
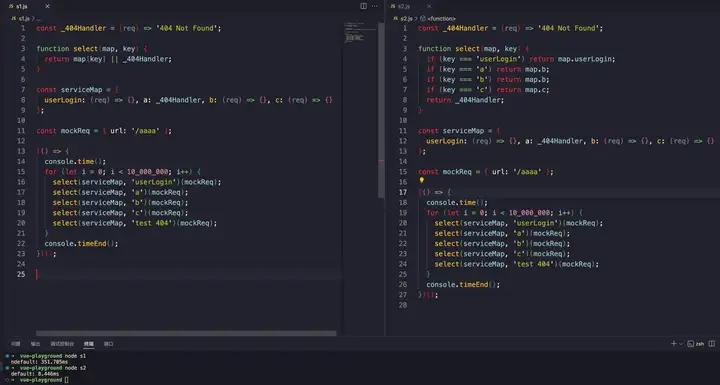
原因是 s2.js 里那些属性访问都被 ICs 技术优化成 O(1) 访问了,速度很快 —— 为了探究内部的 ICs 相关汇编逻辑,尝试输出 serviecMap 的 Hidden Class (V8 里 hidden class 别名是 Map) 以及汇编源码:
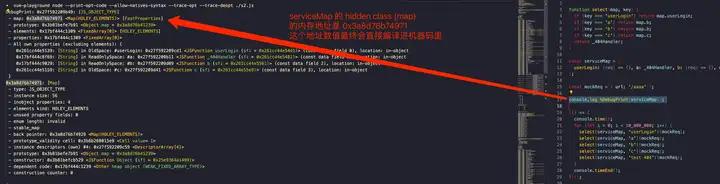
首先 %DebugPrint 出 serviceMap 的 Hidden Class 的物理地址,可以看到是 0x3a8d76b74971 然后看后续编译优化的 arm machine code 是怎么利用这个地址实现 ICs 技术优化的:(笔者这会的电脑是 mac m1 因此是 arm 汇编,不是 x86 汇编)。
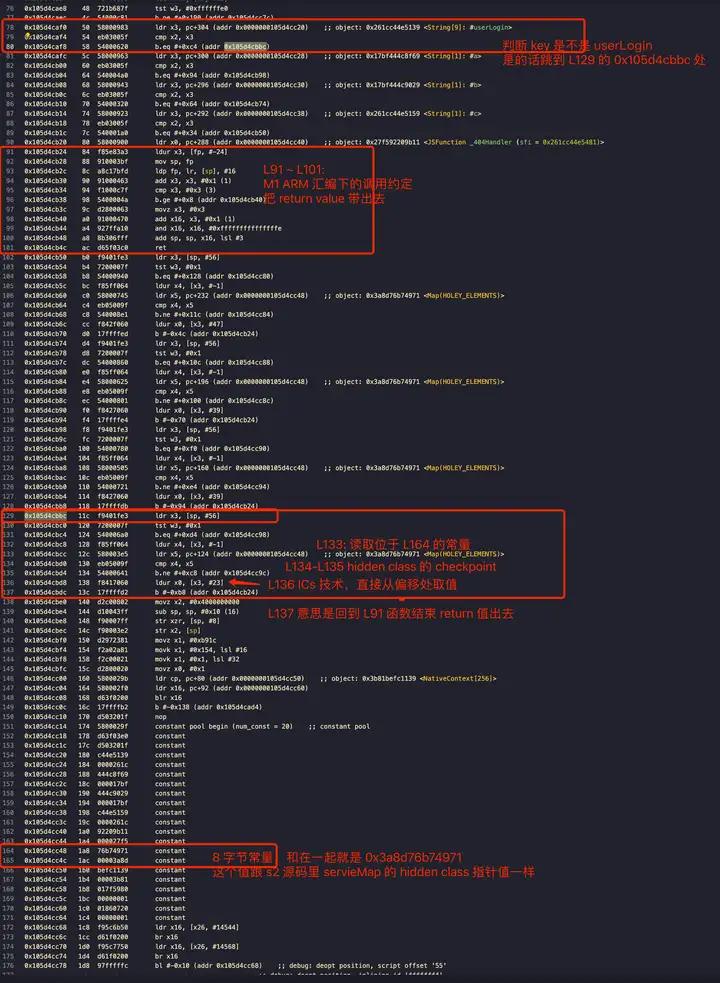
可以看到,ICs 优化后汇编的 checkpoint 其实就是将 Hidden Map 的指针物理地址直接 Inline 到汇编里了,通过判等的方式来验证假设,然后就可以直接将属性访问优化为 O(1) 的 in-object properties 访问了,这也是这个技术为什么叫做 Inline Cahce (ICs) 了。
(这几乎是 V8 里效果最好的优化了,也因此部分 benchmark 里 nodejs 对象可能比 Java 对象还快,因为 Java 里有可能滥用反射导致对象性能非常差)。
2. Fast Properties 和 Slow Properties
如果知道 ICs 技术内涵的话,理解 Fast Properties 和 Slow Properties (或者称字典模式) 就不会有困难了。
下图描述了 JSObject 的主要构造:当把对象成员存储到 in-object properties 的时候,此时称对象是 Fast Properties 模式,这意味着对象访问 V8 会在合适的时候将其 Inline Cache 到优化后的汇编里; 反之,当成员存储到 *properties 的时候,此时称为 Slow Properties,此时就不会对这类对象做 inline cache 优化了,此时对象访问性能最差(因为要遍历 *properties 字典,通常慢几十到几百倍,取决于对象成员数量)。

我们可以用 %HasFastProperties 来打印对象是否是 Fast Properties 模式,如下图所示:
delete 会将对象转为 slow properties 模式,为什么呢?因为 delete 带来的问题可太多了,缓存技术最怕的就是 delete,如图所示:
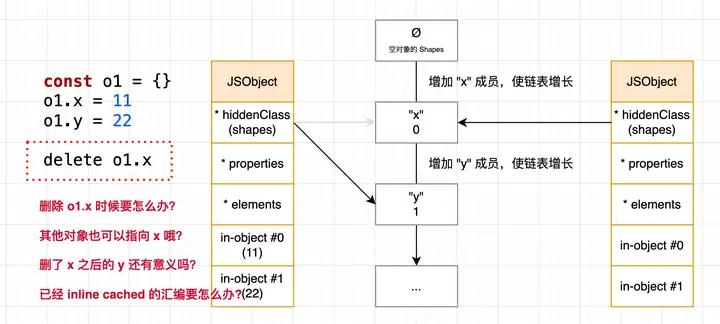
我拍脑子就能想到上面四个问题,要完整的确保 delete 的安全性可太难了,因此维护 delete 后的 hidden class 非常麻烦,V8 采取的方式是直接将 in-object 释放掉,然后将对象属性都复制存储到 *properties 里了,以后这个对象就不再开启 ICs 优化了,此时这种退化后的对象就称为 slow properties (或者称字典模式)。
3. 利用 Hidden Class 来查找内存溢出 (heapdump)
Hidden Class 是比较学术的名字,在 V8 里对应的「工程命名」是 Map,可以在 heapdump 里看到:
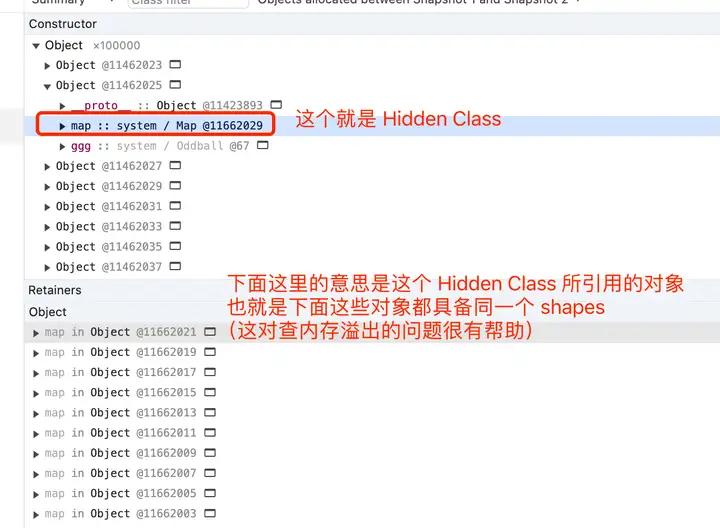
利用查找 Hidden Class 的方式可以快速定位大批量相同 shapes 的对象哦,很方便查找内存溢出问题。
八、V8 其他优化
1. inline 展开
跟 C++ 里的 inline 关键字一样,将函数直接提前展开,少一次调用栈和函数作用域开销。

2. 逃逸分析
基于 Sea Of Nodes 的 PL 理论进行优化,分析对象生命周期,如果对象是一次性的,那么就可以做编译替换提升性能,比如下图里对象 o 只用到了 a,那么就可以优化成右边那样,减少对象内存分配并提升寻址速度:

3. 提前为空对象申请 in-object 内存空间
通过打 heapdump 的方式可以发现下面第二行的空对象的 shallow size 是 28 字节,而后一个是 16 字节:
window.arr = []; // 打一次 heapdump
arr.push({}); // 打一次 heapdump
arr.push({ ggg: undefined });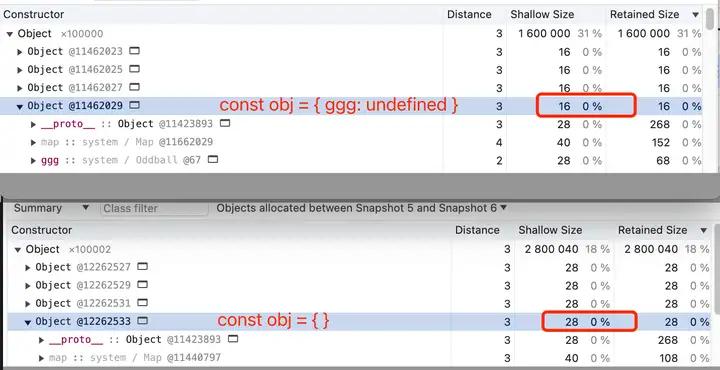
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java