
一文带你搞清楚Python的多线程和多进程
Python作为一种高级编程语言,提供了多种并发编程的方式,其中多线程与多进程是最常见的两种方式之一。在本文中,我们将探讨Python中多线程与多进程的概念、区别以及如何使用线程池与进程池来提高并发执行效率。
多线程与多进程的概念
多线程
多线程是指在同一进程内,多个线程并发执行。每个线程都拥有自己的执行栈和局部变量,但共享进程的全局变量、静态变量等资源。多线程适合用于I/O密集型任务,如网络请求、文件操作等,因为线程在等待I/O操作完成时可以释放GIL(全局解释器锁),允许其他线程执行。
多进程
多进程是指在操作系统中同时运行多个进程,每个进程都有自己独立的内存空间,相互之间不受影响。多进程适合用于CPU密集型任务,如计算密集型算法、图像处理等,因为多进程可以利用多核CPU并行执行任务,提高整体运算速度。
线程池与进程池的介绍
线程池
线程池是一种预先创建一定数量的线程并维护这些线程,以便在需要时重复使用它们的技术。线程池可以减少线程创建和销毁的开销,提高线程的重复利用率。在Python中,可以使用concurrent.futures.ThreadPoolExecutor来创建线程池。
进程池
进程池类似于线程池,不同之处在于进程池预先创建一定数量的进程并维护这些进程,以便在需要时重复使用它们。进程池可以利用多核CPU并行执行任务,提高整体运算速度。在Python中,可以使用concurrent.futures.ProcessPoolExecutor来创建进程池。
线程池与进程池的应用示例
下面是一个简单的示例,演示了如何使用线程池和进程池来执行一组任务。
import concurrent.futures
import time
def task(n):
print(f"Start task {n}")
time.sleep(2)
print(f"End task {n}")
return f"Task {n} result"
def main():
# 使用线程池
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(task, range(5))
for result in results:
print(result)
# 使用进程池
with concurrent.futures.ProcessPoolExecutor(max_workers=3) as executor:
results = executor.map(task, range(5))
for result in results:
print(result)
if __name__ == "__main__":
main()在上面的示例中,我们定义了一个task函数,模拟了一个耗时的任务。然后,我们使用ThreadPoolExecutor创建了一个线程池,并使用map方法将任务提交给线程池执行。同样地,我们也使用ProcessPoolExecutor创建了一个进程池,并使用map方法提交任务。最后,我们打印出每个任务的结果。
线程池与进程池的性能比较
虽然线程池与进程池都可以用来实现并发执行任务,但它们之间存在一些性能上的差异。
线程池的优势
- 轻量级: 线程比进程更轻量级,创建和销毁线程的开销比创建和销毁进程要小。
- 共享内存: 线程共享同一进程的内存空间,可以方便地共享数据。
- 低开销: 在切换线程时,线程只需保存和恢复栈和寄存器的状态,开销较低。
进程池的优势
- 真正的并行: 进程可以利用多核CPU真正并行执行任务,而线程受到GIL的限制,在多核CPU上无法真正并行执行。
- 稳定性: 进程之间相互独立,一个进程崩溃不会影响其他进程,提高了程序的稳定性。
- 资源隔离: 每个进程有自己独立的内存空间,可以避免多个线程之间的内存共享问题。
性能比较示例
下面是一个简单的性能比较示例,演示了线程池和进程池在执行CPU密集型任务时的性能差异。
import concurrent.futures
import time
def cpu_bound_task(n):
result = 0
for i in range(n):
result += i
return result
def main():
start_time = time.time()
# 使用线程池执行CPU密集型任务
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(cpu_bound_task, [1000000] * 3)
print("Time taken with ThreadPoolExecutor:", time.time() - start_time)
start_time = time.time()
# 使用进程池执行CPU密集型任务
with concurrent.futures.ProcessPoolExecutor(max_workers=3) as executor:
results = executor.map(cpu_bound_task, [1000000] * 3)
print("Time taken with ProcessPoolExecutor:", time.time() - start_time)
if __name__ == "__main__":
main()在上面的示例中,我们定义了一个cpu_bound_task函数,模拟了一个CPU密集型任务。然后,我们使用ThreadPoolExecutor和ProcessPoolExecutor分别创建线程池和进程池,并使用map方法提交任务。最后,我们比较了两种方式执行任务所花费的时间。
通过运行以上代码,你会发现使用进程池执行CPU密集型任务的时间通常会比使用线程池执行快,这是因为进程池可以利用多核CPU真正并行执行任务,而线程池受到GIL的限制,在多核CPU上无法真正并行执行。
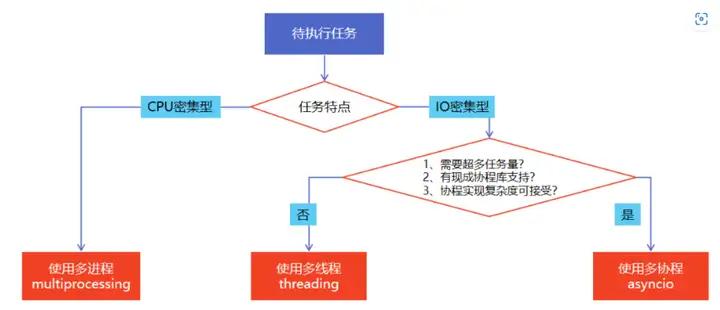
当考虑如何实现一个能够同时下载多个文件的程序时,线程池和进程池就成为了很有用的工具。让我们看看如何用线程池和进程池来实现这个功能。
首先,我们需要导入相应的库:
import concurrent.futures
import requests
import time然后,我们定义一个函数来下载文件:
def download_file(url):
filename = url.split("/")[-1]
print(f"Downloading {filename}")
response = requests.get(url)
with open(filename, "wb") as file:
file.write(response.content)
print(f"Downloaded {filename}")
return filename接下来,我们定义一个函数来下载多个文件,这里我们使用线程池和进程池来分别执行:
def download_files_with_thread_pool(urls):
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(download_file, urls)
print("Time taken with ThreadPoolExecutor:", time.time() - start_time)
def download_files_with_process_pool(urls):
start_time = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
results = executor.map(download_file, urls)
print("Time taken with ProcessPoolExecutor:", time.time() - start_time)最后,我们定义一个主函数来测试这两种方式的性能:
def main():
urls = [
"https://www.example.com/file1.txt",
"https://www.example.com/file2.txt",
"https://www.example.com/file3.txt",
# Add more URLs if needed
]
download_files_with_thread_pool(urls)
download_files_with_process_pool(urls)
if __name__ == "__main__":
main()通过运行以上代码,你可以比较使用线程池和进程池下载文件所花费的时间。通常情况下,当下载大量文件时,使用进程池的性能会更好,因为它可以利用多核CPU实现真正的并行下载。而使用线程池则更适合于I/O密集型任务,如网络请求,因为线程在等待I/O操作完成时可以释放GIL,允许其他线程执行。
这个例子展示了如何利用线程池和进程池来提高并发下载文件的效率,同时也强调了根据任务特点选择合适的并发编程方式的重要性。
并发编程中的注意事项
虽然线程池与进程池提供了方便的并发执行任务的方式,但在实际应用中还需要注意一些问题,以避免出现潜在的并发问题和性能瓶颈。
共享资源的同步
- 在多线程编程中,共享资源的访问需要进行同步,以避免竞争条件和数据不一致性问题。可以使用锁、信号量等同步机制来保护关键资源的访问。
- 在多进程编程中,由于进程之间相互独立,共享资源的同步相对简单,可以使用进程间通信(如管道、队列)来传递数据,避免数据竞争问题。
内存消耗与上下文切换
- 创建大量线程或进程可能会导致内存消耗增加,甚至引起内存泄漏问题。因此,在设计并发程序时需要注意资源的合理利用,避免创建过多的线程或进程。
- 上下文切换也会带来一定的开销,特别是在频繁切换的情况下。因此,在选择并发编程方式时,需要综合考虑任务的特点和系统资源的限制,以及上下文切换的开销。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java