
MySQL全文索引源码剖析之Insert语句执行过程
1. 背景介绍
全文索引是信息检索领域的一种常用的技术手段,用于全文搜索问题,即根据单词,搜索包含该单词的文档,比如在浏览器中输入一个关键词,搜索引擎需要找到所有相关的文档,并且按相关性排好序。
全文索引的底层实现是基于倒排索引。所谓倒排索引,描述的是单词和文档的映射关系,表现形式为(单词,(单词所在的文档,单词在文档中的偏移)),下文的示例将会展示全文索引的组织方式:
mysql> CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200),
FULLTEXT idx (opening_line)
) ENGINE=InnoDB;
mysql> INSERT INTO opening_lines(opening_line,author,title) VALUES
('Call me Ishmael.','Herman Melville','Moby-Dick'),
('A screaming comes across the sky.','Thomas Pynchon','Gravity\'s Rainbow'),
('I am an invisible man.','Ralph Ellison','Invisible Man'),
('Where now? Who now? When now?','Samuel Beckett','The Unnamable');
mysql> SET GLOBAL innodb_ft_aux_table='test/opening_lines';
mysql> select * from information_schema.INNODB_FT_INDEX_TABLE;
+-----------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+-----------+--------------+-------------+-----------+--------+----------+
| across | 4 | 4 | 1 | 4 | 18 |
| call | 3 | 3 | 1 | 3 | 0 |
| comes | 4 | 4 | 1 | 4 | 12 |
| invisible | 5 | 5 | 1 | 5 | 8 |
| ishmael | 3 | 3 | 1 | 3 | 8 |
| man | 5 | 5 | 1 | 5 | 18 |
| now | 6 | 6 | 1 | 6 | 6 |
| now | 6 | 6 | 1 | 6 | 9 |
| now | 6 | 6 | 1 | 6 | 10 |
| screaming | 4 | 4 | 1 | 4 | 2 |
| sky | 4 | 4 | 1 | 4 | 29 |
+-----------+--------------+-------------+-----------+--------+----------+如上,创建了一个表,并在opening_line列上建立了全文索引。以插入'Call me Ishmael.'为例,'Call me Ishmael.'也即文档,其ID为3,在构建全文索引时,该文档会被分成3个单词'call', 'me', 'ishmael',由于'me'小于设定的ft_min_word_len(4)最小单词长度被丢弃,最后全文索引中只会记录'call'和'ishmael',其中'call'起始位置在文档中的第0个字符处,偏移为0,'ishmael'起始位置在文档中的第12个字符处,偏移即为12。
关于全文索引更详细的功能介绍可以参考MySQL 8.0 Reference Manual,本文将从源码层面,简要剖析Insert语句的执行过程。
2. 全文索引Cache
全文索引表中记录的是{单词,{文档ID,出现的位置}},即插入一个文档需要将其分词成多个{单词,{文档ID,出现的位置}}这样的结构,如果每次分词完就马上刷磁盘,其性能会非常差。
为了缓解该问题,Innodb引入了全文索引cache,其作用与Change Buffer类似。每次插入一个文档时,先将分词结果缓存到cache,等到cache满了再批量刷到磁盘,从而避免频繁地刷盘。Innodb定义了fts_cache_t的结构来管理cache,如下图所示:
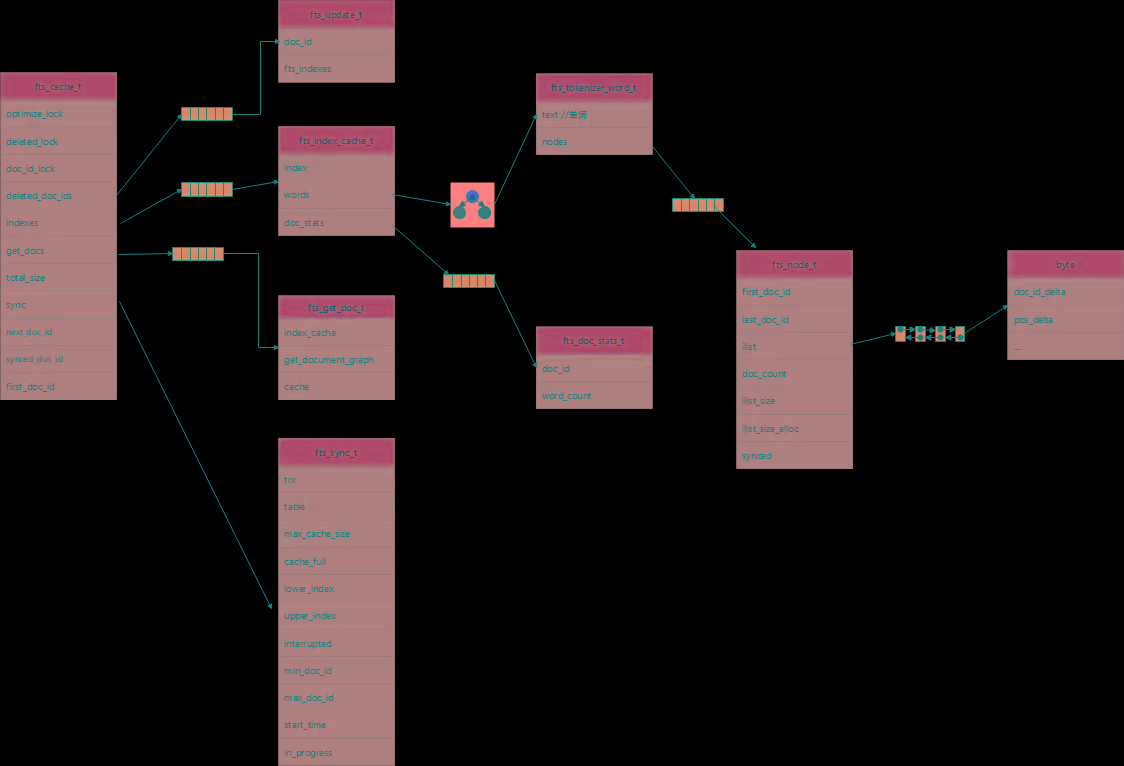
每张表维护一个cache,对于每个创建了全文索引的表都会在内存中创建一个fts_cache_t的对象。注意,fts_cache_t是表级别的cache, 若一个表创建了多个全文索引,内存中依旧是对应一个fts_cache_t对象。fts_cache_t的一些重要成员如下:
- optimize_lock、deleted_lock、doc_id_lock:互斥锁,与并发操作相关。
- deleted_doc_ids:vector类型,存储已删除的doc_id。
- indexes:vector类型,每个元素表示一个全文索引,每次创建全文索引时,都会往该数组中添加一个元素,每个索引的分词结果以红黑树结构存储,key为word, value就是doc_id及单词的偏移。
- total_size:cache已分配的全部内存,包含其子结构使用的内存。
3. Insert语句执行过程
以MySQL 8.0.22源码为例,Insert语句的执行主要分为三个阶段,分别为写入行记录阶段、事务提交阶段和刷脏阶段。
3.1 写入行记录阶段
写入行记录的主要工作流如下图所示:

如上图所示,这一阶段最主要是生成doc_id,并写入到Innodb的行记录中,并且将doc_id缓存,以供事务提交阶段根据doc_id获取文本内容,其函数调用栈如下:
ha_innobase::write_row
->row_insert_for_mysql
->row_insert_for_mysql_using_ins_graph
->row_mysql_convert_row_to_innobase
->fts_create_doc_id
->fts_get_next_doc_id
->fts_trx_add_op
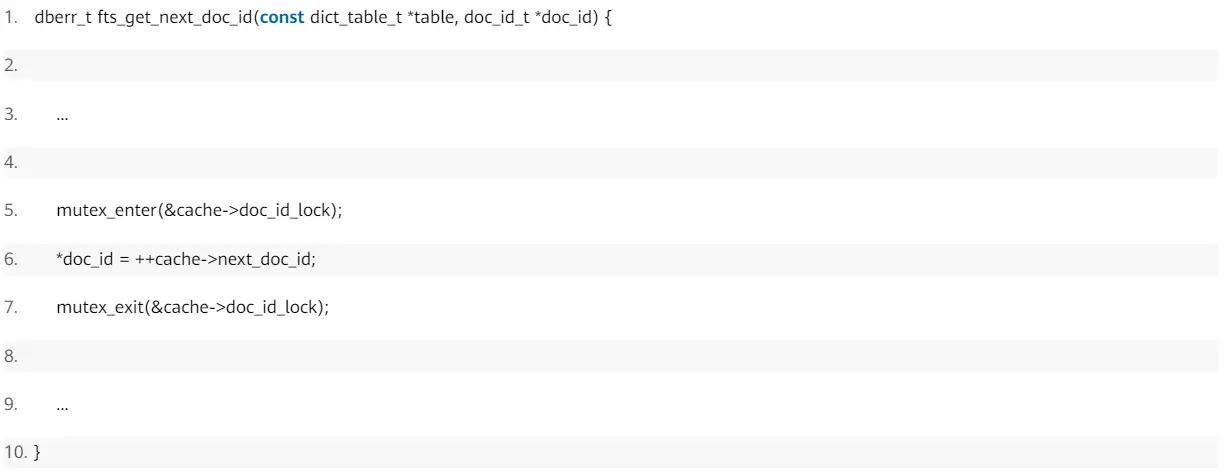
->fts_trx_table_add_opfts_get_next_doc_id与fts_trx_table_add_op是比较重要的两个函数,fts_get_next_doc_id是为了获取doc_id,innodb行记录中包含了一些隐藏列,比如row_id、trx_id等,若创建了全文索引,其行记录中也会增加一个隐藏字段FTS_DOC_ID,这个值在fts_get_next_doc_id中获取的,如下:
而fts_trx_add_op则是将对全文索引的操作添加到trx中,待事务提交时进一步处理。
3.2 事务提交阶段
事务提交阶段的主要工作流如下图所示:
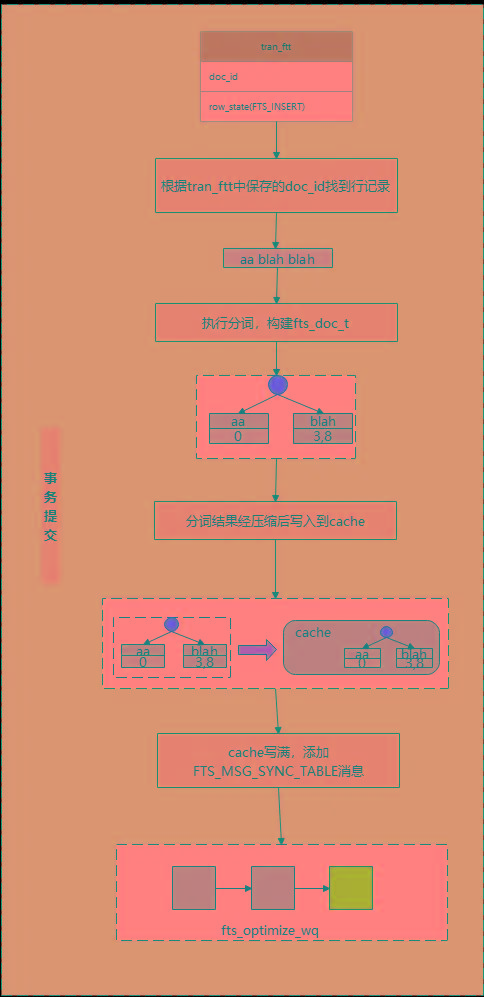
这一阶段是整个FTS 插入的最重要的一步,对文档进行分词,获取{单词,{文档ID,出现的位置}},插入到cache,这些都是在这一阶段完成的。其函数调用栈如下:
fts_commit_table
->fts_add
->fts_add_doc_by_id
->fts_cache_add_doc
// 根据doc_id获取文档,对文档分词
->fts_fetch_doc_from_rec
// 将分词结果添加到cache中
->fts_cache_add_doc
->fts_optimize_request_sync_table
// 创建FTS_MSG_SYNC_TABLE消息,通知刷脏线程刷脏
->fts_optimize_create_msg(FTS_MSG_SYNC_TABLE)其中,fts_add_doc_by_id是比较关键的一个函数,该函数主要完成了以下几件事:
1)根据doc_id找到行记录, 获取对应的文档;
2)对文档执行分词,获取{单词,(单词所在的文档,单词在文档中的偏移)}关联对,并添加到cache中;
3)判断cache->total_size是否达到阈值时,若达到阈值,则往刷脏线程的消息队列添加一个FTS_MSG_SYNC_TABLE消息, 通知该线程刷脏(fts_optimize_create_msg),具体代码如下:
为方便理解,我把代码的异常处理部分以及一些查找记录的通用部分省略了,并给出了简要注释:
static ulint fts_add_doc_by_id(fts_trx_table_t *ftt, doc_id_t doc_id)
{
/* 1. 根据docid在fts_doc_id_index索引中的查找记录 */
/* btr_pcur_open_with_no_init函数中会调用btr_cur_search_to_nth_level,btr_cur_search_to_nth_level
会执行b+树搜索记录的过程,先从根节点找到docid记录所在的叶子节点,再通过二分查找找到docid记录。*/
btr_pcur_open_with_no_init(fts_id_index, tuple, PAGE_CUR_LE,
BTR_SEARCH_LEAF, &pcur, 0, &mtr);
if (btr_pcur_get_low_match(&pcur) == 1) { /* 如果找到了docid记录 */
if (is_id_cluster) {
/** 1.1 如果fts_doc_id_index是聚集索引,则意味着已经找到行记录数据, 直接保存行记录 **/
doc_pcur = &pcur;
} else {
/** 1.2 如果fts_doc_id_index是辅助索引,则需要根据1.1找到的主键id在聚集索引上进一步搜 索行记录,找到后保存行记录**/ btr_pcur_open_with_no_init(clust_index, clust_ref, PAGE_CUR_LE,
BTR_SEARCH_LEAF, &clust_pcur, 0, &mtr);
doc_pcur = &clust_pcur;
} // 遍历cache->get_docs
for (ulint i = 0; i < num_idx; ++i) {
/***** 2. 对文档执行分词,获取{单词,(单词所在的文档,单词在文档中的偏移)}关联对,并添加到cache中 *****/
fts_doc_t doc;
fts_doc_init(&doc);
/** 2.1 根据doc_id获取行记录中该全文索引对应列的内容文档,解析文档,主要是为了构建 fts_doc_t结构体的tokens,tokens为一个红黑树结构,每个元素是一个 {单词,[该单词在文档中出现的位置]}的结构,解析结果存于doc中 **/
fts_fetch_doc_from_rec(ftt->fts_trx->trx, get_doc, clust_index,doc_pcur, offsets, &doc);
/** 2.2 将2.1步骤获得的{单词,[该单词在文档中出现的位置]}添加到index_cache中 **/
fts_cache_add_doc(table->fts->cache, get_doc->index_cache, doc_id, doc.tokens);
/***** 3. 判断cache->total_size是否达到阈值时。 若达到阈值,则往刷脏线程的消息队列添加一个FTS_MSG_SYNC_TABLE消息, 通知该线程刷脏 *****/
bool need_sync = false;
if ((cache->total_size - cache->total_size_before_sync >
fts_max_cache_size / 10 || fts_need_sync) &&!cache->sync->in_progress) {
/** 3.1 判断是达到阈值 **/
need_sync = true;
cache->total_size_before_sync = cache->total_size;
}
if (need_sync) {
/** 3.2 打包FTS_MSG_SYNC_TABLE消息挂载至fts_optimize_wq队列, 通知fts_optimize_thread线程刷脏,消息的内容为table id **/ fts_optimize_request_sync_table(table);
}
}
}
}本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java