
详解iptables规则
iptables规则
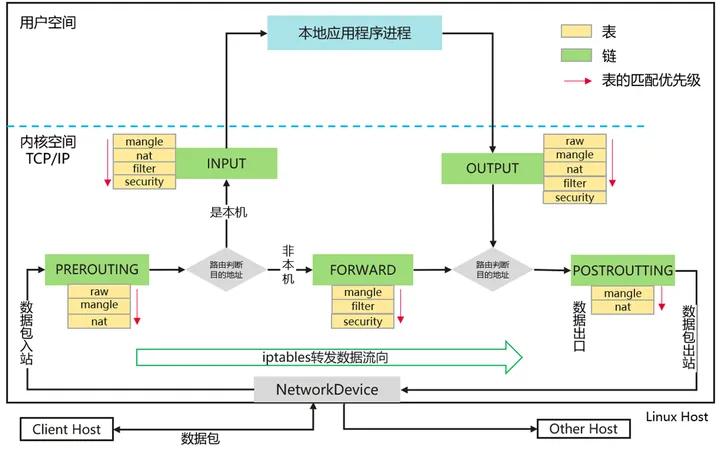
下图为数据包到达linux主机网卡后,内核如何处理数据包的大致流程
什么是规则
规则是管理员对数据包制定的一种触发机制,即当数据包达到某种条件,就执行指定的动作。
条件:可以是数据包源地址、目的地址、协议等
动作:可以是拒绝、接受、丢弃等;详细介绍见下表
| 动作 | 说明 |
|---|---|
| ACCEPT | 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链(nat:postrouting) |
| REJECT | 拦阻该封包,并传送封包通知对方,可以传送的封包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是 tcp-reset(这个封包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接 中断过滤程序。 |
| DROP | 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。 |
| MASQUERADE | 改写封包来源 IP 为防火墙 NIC IP,可以指定 port 对应的范围,进行完此处理动作后,直接跳往下一个规则炼(mangle:postrouting)。这个功能与 SNAT 略有不同,当进行 IP 伪装时,不需指定要伪装成哪个 IP,IP 会从网卡直接读取,当使用拨接连线时,IP 通常是由 ISP 公司的 DHCP 服务器指派的,这个时候 MASQUERADE 特别有用。 |
| SNAT | 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则炼(mangle:postrouting)。 |
| DNAT | 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规则炼(filter:input 或 filter:forward)。 |
| MARK | 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。 |
| RETURN | 结束在目前规则炼中的过滤程序,返回主规则炼继续过滤,如果把自订规则炼看成是一个子程序,那么这个动作,就相当于提早结束子程序并返回到主程序中。 |
使用iptables命令写入规则示例:
iptables -t filter -A INPUT -i eth0 -p tcp -s 192.168.1.0/24 -m multiport --dports 443,80 -j ACCEPT
#-t:操作那个表
#-A:在表末追加规则;-I为表首插入规则、-D为删除规则
#INPUT:链名称;该规则在那条链上生效
#-j:数据包处理动作;比如接受、拒绝等整条命令解释:允许经过本机网卡eth0,访问协议是TCP,源地址是192.168.1.0/24 段的数据包访问本地端口是80和443的服务
什么是表
表主要用来存放具体的防火墙规则,而规则具有功能性,比如修改数据包源/目的ip、拒绝来自某个网段的数据包访问本机等;所以我们可以对规则进行分类,不同的功能存入不同的表
- raw表:主要用于决定数据包是否被状态跟踪机制处理
- mangle表:主要用于拆解报文修改数据包的 IP 头信息
- nat表:主要用于修改数据包的源地址和目的地址、端口号等信息(实现网络地址转换,如SNAT、DNAT、MASQUERADE、REDIRECT)。
- filter表:主要用于对过滤流入和流出的数据包,根据具体的规则决定是否放行该数据包
- security 表:最不常用的表,用在 SELinux 上;用于强制访问控制(MAC)网络规则,由Linux安全模块(如SELinux)实现
其中nat表和filter表最常用
什么是链
上文提到表主要存放具体的规则,但是规则什么时候生效呢?比如客户端访问VIP,数据包到达本机后必须先用DNAT(网络地址转换)将vip转换成实际的后端实例ip,然后才能路由判断,因为后端实例可能有多个且分布在不同主机,直接用vip进行路由判断肯定是不行的。所以规则有生效时机,根据生效时机可以分为:
- PREROUTING:在数据包到达防火墙时,进行路由判断之前执行的规则
- INPUT:路由判断之后确定数据包流入本机,应用其规则
- FORWARD:路由判断之后确定数据包要转发给其他主机,应用其规则;linux主机需要开启ip_forward功能才支持转发,在/etc/sysctl.conf文件中配置参数net.ipv4.ip_forward=1
- OUTPUT:本机应用向外发出数据包时,应用其规则
- POSTROUTING:在数据包离开防火墙时进行路由判断之后执行的规则
在每条链中,规则按照从上到下的顺序进行匹配,当一个数据包与某个规则匹配成功后,就会按照该规则的动作进行处理,并且后续的规则将不再被考虑。
表、链、规则三者的关系是什么
表是区分相同链的上下顺序,规则在每条链中的上下顺序确定规则执行顺序:
- 如果规则来自不同表,通过表的优先级确定链的优先级: 比如完整的PREROUTING链中有来自raw表、mangle表、nat标的PREROUTING链规则,通过表优先级 (raw>mangle>nat>filter>security) 区分优先级。所以一个报文发送到某台虚拟机后,被虚拟机网卡接收,会进入的虚拟机网络协议栈处理,先经过PREROUTING链处理,具体来说先走raw表的PREROUTING规则、再走mangle表、最后在走nat表PREROUTING规则。
- 如果规则来自同一个表,则按规则插入表的顺序自上而下。
数据报文进/出节点经过哪些规则
- 对于客户端来说,发送报文过程
先进入OUTPUT链处理(raw、mangle、nat、filter、security表对应的PREROUTING规则依次匹配),如果没有被拦截则根据路由选择出网口,再进入POSTROUTING链处理(mangle、nat表对应的POSTROUTING规则依次匹配),最后从网卡出去 - 对于服务端来说,发送报文过程
先进入PREROUTING链处理(raw、mangle、nat表对应的PREROUTING规则依次匹配),根据路由判断数据报文发给本机,报文进入INPUT链处理(mangle、nat、filter、security表对应的INPUT规则依次匹配),如果没有被拦截则报文被应用程序处理 - 对于转发场景,发送报文过程
先进入PREROUTING链处理(raw、mangle、nat表对应的PREROUTING规则依次匹配),根据路由判断数据报文不是发给本机,报文进入FORWARD链处理(mangle、filter、security表对应的FORWARD规则依次匹配),如果没有被拦截则进入POSTROUTING链处理(mangle、nat表对应的POSTROUTING规则依次匹配),最后从网卡出去
*补充:转发场景需要Linux开启转发功能,否则数据报文进入FORWARD链直接丢弃;临时开启执行命令sysctl net.ipv4.ip_forward=1或者echo "1" >/proc/sys/net/ipv4/ip_forward;永久生效需要修改/etc/sysctl.conf,增加内容net.ipv4.ip_forward = 1保存,再执行命令:sysctl -p
NAT(网络地址转换)介绍
NAT应用最广的场景就是解决局域网内设备访问互联网的问题。
SNAT(源地址转换) 主要用于修改数据包的源IP和源端口,一般在nat表的PREROUTING链中增加规则:局域网内所有设备要上外网,如果每个设备都分配一个公网ip成本太大,可以在路由器出口分配一个公网ip,局域网内的设备访问外网时统一走路由器出口,路由器此时需要做两件事:
- 数据包从出口出去之前,将数据包的源地址和源端口改成公网ip和随机端口
- 同时将转换关系记录保存,响应数据包返回时根据记录转发给局域网内的设备
SNAT示例:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java