
详解JVM内存问题排查
一、前言
之后来到对客页面,意外的是在这里也会碰到不少客户打来的内存相关问题。大多数时候,客户也理解这个事情和阿里云无关,但是他收到了来自云监控或者ARMS的相关内存报警,接入了ARMS应用监控的客户也可以在ARMS上看到如Old GC暴涨,内存触发阈值等监控相关的指标。虽然有了监控,但是很多时候没有排查思路,希望阿里云这边给出具体的排查思路或者一起排查。本着对客户负责的态度我们也会一起协助排查,但是这种情况会比排查自己的代码更麻烦一些,首先对方的业务代码我们是不熟悉的,一般情况下我们也不会直接上手看对方代码,这个行为有一定风险。其次客户给的信息不会像我们自己排查问题一样很全,很多时候是没有事故出现时候的快照和日志的。在这样的场景下,一份系统的,全面的排查Guideline尤其重要。可以帮助我自己不被片面的信息和我自己的臆断带沟里去,消耗了客户的信任也浪费了宝贵的排查窗口。
(一) 本文目的
目的一:系统性整理排查思路,等下次遇到问题的时候可以有个全面的排查流程,不至于漏掉某些可能性误入歧途浪费时间。
目的二:分享出来也希望扫到的大佬们可以在评论区补充一些有用的案例,然后我可以学习一下补充到案例库里。
(二) 基本原则
由于本文的定位是Cookbook,基本原则是让整个流程能够系统化规范化的同时将一个比较复杂的问题拆分成几个简单易上手的环节,目标是让没有JVM问题排查经验的同学能够快速地定位问题并给出可行性建议。
所以本文会基于以下基本原则编写:
- 正文部分不会放具体概念或者知识性质的内容。JVM内存模型会放在扩展阅读部分;
- 正文部分会放排查思路和排查建议,涉及到变更或者命令行实操的部分会放在扩展阅读部分;
- 正文部分使用的排查工具会满足下列两项规则之一:阿里云Paas服务产品或者开箱即用。需要安装的tool或者agent相关材料会放在扩展阅读部分;
- 正文排查判断流程会按照step一步步的向下走。争取做到思路连贯;
- 步骤中需要逻辑判断或者深入分析的部分会使用GPT来帮助解答分析,实在没法简化的部分会放在扩展阅读部分;
(三) 限定范围
JDK8-JDK11 其他版本正文排查思路一致,但是扩展阅读部分的内容有差异。
二、正文
Step1 : 收到问题
Step 1.1 基本信息收集
首先JAVA内存使用率高并不全是内存问题。可能是新业务或者大促本身流量高导致内存打高。在判断内存问题之前需要先和明确以下几个基本情况:
1.目前的现象是什么:是内存居高不下,内存缓慢增加还是进程突然Dump掉?
2.现象发生的节点,有无变更,有无新业务上线,有无应用本身监控数据留痕。
Step 1.2 依赖上面信息作出基本判断:
业务无损情况:
- 业务增加导致的内存增加,往阿里云弹性能力方向引导;
- 业务未变,近期未有变更,内存增长是周期性,偶发性。基于现象有基本判断,后续可以围绕基本判断推进排查;
- 周期性增加:往定时任务方向排查;
- 偶发性增长:首先考虑的是在不影响业务情况下的现场复现,后续往这个方向引导;
- 缓慢持续性增长:都有可能,跳转Step2判断来源;
在了解情况过程中,如果客户没有进一步分析的监控手段,推荐阿里云ARMS监控内存和GC情况。
业务有损情况:
- 快速止损:业务有损情况下首先需要推荐快速止损方案;
- 切流下线,通过目前使用的服务发现组件(Nacos,Consul or Eureka) 将问题机器快速下线。如果判断是变更造成的需要灰度回滚;
- 机器重启或者手动触发FullGC(跳转扩展阅读->Jcmd)。快速回收内存,减少服务影响;
- 在变更前保留现场;
Step 1.3 保留现场:
无论是什么机器如果条件允许不建议直接重启或者回滚,可以先保留现场,需要保存如下内容,优先级依次降低。
1. heapdump文件
ATP帮助文档-生成Java转储文件[1]
#jmap命令保存整个Java堆(在你dump的时间不是事故发生点的时候尤其推荐)
jmap -dump:format=b,file=heap.bin <pid>
#jmap命令只保存Java堆中的存活对象, 包含live选项,会在堆转储前执行一次Full GC
jmap -dump:live,format=b,file=heap.bin <pid>
#jcmd命令保存整个Java堆,Jdk1.7后有效
jcmd <pid> GC.heap_dump filename=heap.bin
#在出现OutOfMemoryError的时候JVM自动生成(推荐)节点剩余内存不足heapdump会生成失败
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heap.bin
#编程的方式生成
使用HotSpotDiagnosticMXBean.dumpHeap()方法
#在出现Full GC前后JVM自动生成,本地快速调试可用
-XX:+HeapDumpBeforeFullGC或 -XX:+HeapDumpAfterFullGCPS: 如果客户侧应用接入ARMS,可以直接用控制界面的dump功能:
如何创建内存快照_应用实时监控服务(ARMS)-阿里云帮助中心[2]
2. 当前JVM的启动参数
ps -ef|grep java示例:结果类似下文
$ps -ef|grep java
admin 101775 1 4 2023 ? 13:32:54 /opt/taobao/java/bin/java -server -Xms9g -Xmx9g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:MaxDirectMemorySize=1g -XX:SurvivorRatio=10 -XX:SoftRefLRUPolicyMSPerMB=1000 -XX:+UnlockExperimentalVMOptions -Xss256k -XX:+UseG1GC -XX:MaxGCPauseMillis=150 -XX:G1HeapWastePercent=5 -XX:G1NewSizePercent=10 -XX:G1MaxNewSizePercent=30 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1MixedGCCountTarget=64 -XX:MaxHeapFreeRatio=15 -XX:MinHeapFreeRatio=5 -Dsun.rmi.dgc.server.gcInterval=2592000000 -Dsun.rmi.dgc.client.gcInterval=2592000000 -XX:ParallelGCThreads=4 -Xloggc:/home/admin/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs/java.hprof -Djava.awt.headless=true -Dsun.net.client.defaultConnectTimeout=3000 -Dsun.net.client.defaultReadTimeout=3000 -Dfile.encoding=UTF-8 -Dproject.name=primushubcenter -Dschedulerx.console.domain=vpc-schedulerx2.cn-hangzhou.aliyun-inc.com -Drocketmq.namesrv.domain=jmenv.cn-hangzhou.aliyun-inc.com -Drocketmq.namesrv.domain.subgroup=nsaddr -Daddress.server.domain=jmenv.cn-hangzhou.aliyun-inc.com -Dhsf.server.ip=10.1.0.149 -javaagent:/home/admin/primushubcenter/ArmsAgent/arms-bootstrap-1.7.0-SNAPSHOT.jar org.springframework.boot.loader.JarLauncher --server.port=7001 --management.port=7002 --management.info.build.mode=full --spring.profiles.active=production --logging.path=/home/admin/primushubcenter/logs --logging.file=/home/admin/primushubcenter/logs/application.log --startup.at=1702966471667ps: 得到的JVM参数可以直接让chatgpt给你说明。Prompt格式如下:
我希望你充当JVM调优专家。我将提供机器的规格和当前JVM参数,可能会包含其他输入。您的工作是逐条解释这些JVM参数,然后基于机器的规格和我其他的输入,判断当前JVM参数是否合理。如果有不合理的参数,请给出具体的修改建议和理由。
我的第一个请求是“机器规格12核 24G JVM参数如下:”
基于上述Prompt。Chatgpt的结果有一定的参考价值:
这段命令包含了很多JVM参数,下面一条一条来解析:
-server:JVM运行在server模式,这种模式下JIT编译器会进行更多的优化,但是启动和编译速度会慢一些。因为这是一个持久运行的服务,所以这个选项是正确的。
-Xms9g -Xmx9g:初始化堆内存和最大堆内存都设为9G,这种设置可以避免JVM因为频繁的扩张和收缩堆空间导致的性能开销。考虑到机器内存是24G,这个设定是合理的。
-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m:设置元空间的初始大小和最大大小均为512M。元空间用于存储类的元数据,对于大型应用,这个值可能需要增大。
-XX:MaxDirectMemorySize=1g:设定直接内存的最大值为1G。直接内存并不是Java Heap,而是在Java Heap之外的,且不受JVM垃圾收集影响的内存区域,主要用于NIO的缓冲。
-XX:SurvivorRatio=10:设置新生代中Eden区与Survivor区的大小比值。这个值决定了新生代中多少空间被用作Eden区和Survivor区。
-XX:SoftRefLRUPolicyMSPerMB=1000:设置软引用对象的空闲生存时间。每个软引用对象会有一个时间戳,JVM会根据这个时间戳和上次GC后的间隔时间来决定是否回收软引用对象。
-XX:+UnlockExperimentalVMOptions:解锁试验阶段的JVM选项,对于生产环境,应慎用此参数。
-Xss256k:设置每个线程的栈大小为256K,这个值需要根据程序的线程需求来设定。
-XX:+UseG1GC:使用G1垃圾收集器。
-XX:MaxGCPauseMillis=150:设置G1GC的最大停顿时间,单位是毫秒。
-XX:G1HeapWastePercent=5:设置G1GC在mixed GC之后,堆中可以浪费的最大空间百分比。
-XX:G1NewSizePercent=10 -XX:G1MaxNewSizePercent=30:设置新生代堆的最小大小和最大大小百分比。
-XX:InitiatingHeapOccupancyPercent=35:设置当堆占用率达到这个百分比后,就开启并发GC。
-XX:G1MixedGCCountTarget=64:设置混合GC的目标次数。
-XX:MaxHeapFreeRatio=15 -XX:MinHeapFreeRatio=5:设置堆空间空闲比例的上限和下限。
-Dsun.rmi.dgc.server.gcInterval=2592000000 -Dsun.rmi.dgc.client.gcInterval=2592000000:设置RMI系统的GC间隔。
-XX:ParallelGCThreads=4:设置并行GC时的线程数。这个值和具体的CPU核数有关,一般来说,这个值设置为和CPU核数相同是比较合适的。
-Xloggc:/home/admin/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs/java.hprof:这些参数是关于GC日志和堆转储的设置。
-Djava.awt.headless=true:运行在无头模式,适合服务器环境。
-Dsun.net.client.defaultConnectTimeout=3000 -Dsun.net.client.defaultReadTimeout=3000:设置默认的连接超时和读取超时时间。
-Dfile.encoding=UTF-8:设置文件编码为UTF-8。
在这些参数中,大部分的设定都是合理的。不过有一个参数可能需要调整,那就是-XX:ParallelGCThreads=4,因为你的机器有12核,所以这个参数可以设置为12,这样可以充分利用CPU资源进行垃圾收集。另外,元空间的大小也可能需要根据实际情况进行调整。如果你的应用有大量的类或者大量的动态生成类,可能需要增大元空间的大小。3. GC日志
Java GC日志需要在应用启动时设置GC日志打印相关的JVM参数来开启,以下是推荐的参数设置,仅供参考:
# Java8及以下
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<path>
# Java9及以上
-Xlog:gc*:<path>:time4. 内存栈
jstack <pid> > jstack.log #jstack生成,推荐
jcmd <pid> Thread.print > jstack.log #jcmd生成5. Linux日志(用于分析VM 层面 OOM情况)
如果你观察到现象的时候你的JVM进程已经消失了,有概率是被linux oom_killer kill掉了,可以通过以下命令获得相关日志:
sudo dmesg|grep -i kill|less
或者
grep /var/log/kern.log* -ie kill
6. JAVA日志(有具体的OOM信息最好)
很多时候JVM内存溢出是会打出日志信息。如果有比较明确的日志信息也可以帮助我们快速定位。
比如元空间溢出:java.lang.OutOfMemoryError: Metaspace;
直接内存溢出netty会报OutOfDirectMemoryError: failed to allocate capacity byte(s) of direct memory (used: usedMemory , max: DIRECT_MEMORY_LIMIT )
#/path/to/your/logfile 替换为 日志地址
grep "java.lang.OutOfMemoryError" /path/to/your/logfile
#如果日志文件是压缩文件(如.log.gz),你可以使用zgrep命令
zgrep "java.lang.OutOfMemoryError" /path/to/your/logfile.gz
#如果是多个文件的话在日志地址上增加通配符
grep "java.lang.OutOfMemoryError" /path/to/your/logs/*.logStep2 : 判断JVM内存问题来源
Step2.1 确认到底是哪个进程的内存问题
使用top命令或者ps aux或者分析系统日志确认是哪个进程最终导致的内存OOM。当Java进程被Linux kill的原因可能是别的进程占用过大内存,比如在生产机器中用vim打开过大的文件。导致其他进程被杀死。直观表现就是进程无故丢失。详情见 扩展阅读->OOM Killer。
确定是JVM问题后跳转到Step2.3
Step2.2 判断是否是JVM内存泄漏:内存占用缓慢增加一定是内存泄漏吗?
- 首先内存占用缓慢增加不一定是内存泄漏,如果是服务重启之后内存缓慢上涨,不一定是内存泄漏问题:
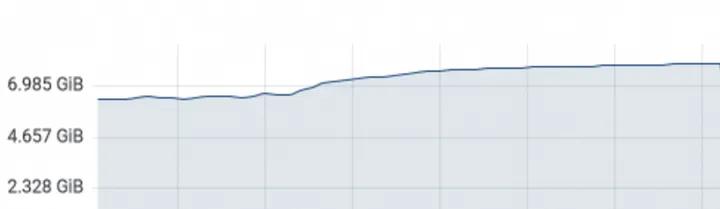
我之前的服务JVM内存一星期内涨了1.5G。当时排查JVM内存泄漏排查了好久,结果发现不是。。。是因为JVM只有在GC期间首次使用到堆内存的某个区域时,才会引起Linux实际分配相应的内存。这会导致内存使用量随着时间的推移逐渐增加。之前的情况就是是在JVM初始只使用了4.5G虚拟内存,而总共申请了7G的情况下,未使用的部分内存在首次被GC触及时才得到分配。在极端情况下,这种延迟分配可能导致GC耗时增加。
策略:后来加了-XX:+AlwaysPreTouch参数,它让JVM在启动时就访问所有堆内存区域,确保这些内存立即被分配。这不仅避免了内存使用量随时间增加的问题,还帮助稳定了内存使用,通过此策略,内存增长控制在2%以内,并降低了GC耗时。
缺点:尽管-XX:+AlwaysPreTouch参数减少了延迟分配导致的GC耗时问题,但也导致了更高的初始内存占用。另外,这个参数也可能延长JVM启动时间,特别是在申请了大量内存的情况下。如果应用需要快速启动,快速部署,这就不是很合适了。因此,需要在内存使用效率和稳定性之间找到平衡点。
- 其次docker占用内存上升并不代表JVM占用内存也同步上升,最好还是看JVM监控指标。
比如应用涉及生成报告或者文件。应用每次处理请求都会在临时文件下创建文件然后删除,随着请求量增加导致 slab 中 dentry 对象占用过多导致容器内存增加。
或者像这篇文章My Process Used Minimal Memory, and My Docker Memory Usage Exploded [3]里,应用频繁大量写日志,导致linux系统一直未将日志文件的缓存flush到磁盘导致;
PS:容器OOM的排查又是另外一个大主题。之后会单独讨论。
Step2.3 分析日志
在Step1 中我们有尽量保存下来相关的应用日志和系统日志,
分析应用日志是否有outofmemory等关键字,关键字和具体内存问题的映射参见扩展阅读->关联异常类型。
分析系统日志/var/log/messages或者dmesg观察outofmemory的情况、进程运行的记录;
PS:对于中型客户如果没有独立的业务应用日志的存储分析方案,推荐客户使用ARMS+SLS的方案将业务日志持久化并针对StackOverflowError或者OutOfMemory配置SLS告警,可以极大程度减少问题定位事件。详解官网最佳实践:
通过调用链路和日志分析sls定位业务异常_应用实时监控服务(ARMS)-阿里云帮助中心[4]
如何实现基于日志关键字的告警_日志服务(SLS)-阿里云帮助中心[5]
Step2.4 根据现象初步判断问题所在内存区域
这里开始可以引入阿里云ARMS监控辅助排查监控JVM内存。ARMS可以帮助监控JVM堆内内存的变化。如果在上一步保存了现场,也可以使用阿里云ATP分析工具用于分析堆内内存情况。
这里和后续都会使用阿里云官网上的内存图来辅助讲解:
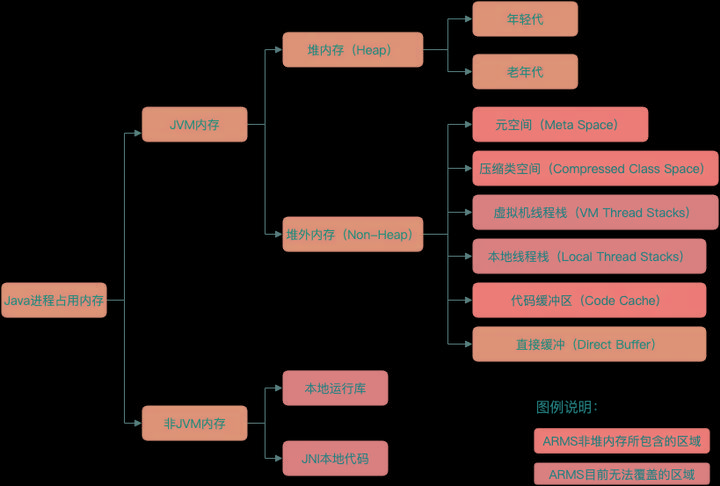
具体内存和每个内存关联的具体问题可以参见扩展阅读《JVM 内存》和《常见案例》。
这里就是比较简单的给出现象和问题的映射, 帮助快速定位问题。这里的现象收集自Step1.3的现场。
前提条件:内存问题的最值接基本上都是内存达到阈值,触发报警或者应用直接挂掉了。已经通过上面的Step确定了导致问题发生的原因是Java应用。这里主要使用ARMS
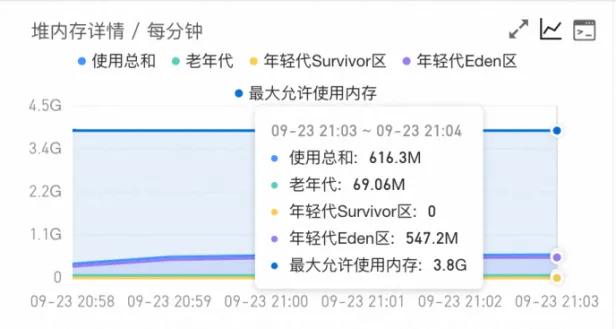
- ARMS堆监控堆内存一直缓慢上涨 -> 跳转Step3 堆内问题排查;
- ARMS堆监控堆内存保持不变,使用总和接近最大允许使用内存(同时伴随大量FulllGC) -> 跳转Step3 对内内存排查。
- JVM监控在启动后或者某个时间点开始,MetaSpace 的已使用大小在持续增长,同时每次 GC 也无法释放,调大 MetaSpace 空间也无法彻底解决。-> 跳转Step4 堆外问题排查。
- 内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。-> 跳转Step4 堆外问题排查。
Step3 : 堆内问题排查
这里给出具体的步骤和树状图。优先使用命令,具体工具因为线上环境限制无法使用的场景,可以使用命令从上到下排查。具体内容详解会链接到正文后面扩展阅读中:
- 工具
- ATP GC分析[6]:分析GC, 同类功能有EasyGC.
- ATP 堆分析[7]: 类似MAT的在线平台:内部工具grace产品化, 可以快速使用。
- MAT 堆分析:最推荐的堆内存分析工具,可以通过内存快照, 有一定的学习成本,推荐花点时间完整学一遍非常有用。ps: 扩展阅读-》常用第三方工具部分 会列出常用场景和OQL,帮助快速使用。
- 命令,从上到下排查,从整体到局部,从JVM到系统本身
- jstat -gcutil <pid> :获取JAVA堆,元空间,gc信息,详情参见扩展阅读示例
- jmap -heap <pid> :Java进程的堆内存详情,看在线情况
- jmap -histo <pid> :生成堆中的对象直方图:快速识别哪些类的实例占用了大量的堆内存
- arthas的memory命令 :查看堆和对外具体信息,详情参见扩展阅读部分Arthas
- pmap -x <pid> | sort -nrk3 | less :获取大内存块特别是堆,栈,代码段具体位置和布局
Step4 : 堆外问题排查
堆外内存排查比较复杂,我能力有限,没法写得非常简洁清楚。这里需要对JVM有些基本的了解,建议简单过一遍扩展阅读中的各个堆外内存部分,这里简单描述初步定位的方式和可能用到的命令。
元空间 :
异常现象:
在JVM启动后或者某一特定时间点,MetaSpace的使用量持续增加,并且每次的垃圾回收(GC)都无法释放这部分空间。即使增大MetaSpace的容量,也无法根本解决这个问题。
简要思路:定位具体类位置
元空间是存储类元数据的位置,元空间问题的排查方式就是去trace类加载,下面是相关命令:
查看类加载情况
#显示指定进程的类加载器相关的统计信息
Jmap -clstats <pid> :
#监视类加载器的行为,包括加载、卸载的类的数量以及相关的内存消耗。
Jstat -class <pid>
#统计在JVM的类加载中,每一个类的实例数量,并按照数量降序排列。
jcmd <PID> GC.class_stats|awk '{print$13}'|sed 's/\(.*\)\.\(.*\)/\1/g'|sort |uniq -c|sort -nrk1
#arthas的classloader命令玩法比较多,有一定学习成本
arthas的classloader命令追踪类加载,卸载情况:
在调试环境中添加VM参数(在生产环境请谨慎!!!)
-verbose:class 用于同时跟踪类的加载和卸载 -XX:+TraceClassLoading 单独跟踪类的加载 -XX:+TraceClassUnloading 单独跟踪类的卸载
简要思路:关注点,具体见扩展阅读-》案例部分
- 关注 fastjson, beanCopy, Orika, Groovy, 反射,CGLIB 动态代理
- 是否有设置-XX:MaxMetaspaceSize 元空间最大值
DirectMemory和JNI Memory
异常现象:
top发现JAVA实际占用的RES 甚至超过了 -Xmx 的大小,内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象
排查策略
判断堆外内存泄漏是否和direct memory强相关。
使用 NMT(NativeMemoryTracking[8]) 进行分析。在项目中添加 -XX:NativeMemoryTracking=detailJVM参数后重启项目(需要注意的是,打开 NMT 会带来 5%~10% 的性能损耗)。
使用命令jcmd pid VM.native_memory detail查看内存分布。重点观察 total 中的 committed,因为 jcmd 命令显示的内存包含堆内内存、Code 区域、通过Unsafe.allocateMemory和DirectByteBuffer申请的内存,但是不包含其他 Native Code(C 代码)申请的堆外内存。如果 total 中的 committed 和 top 中的 RES 相差不大,则应为主动申请的Direct Memory未释放造成的。
DirectMemory关注点(详见 扩展阅读-》案例部分)
-XX:MaxDirectMemorySize 配置
如果大量DirectMemory没有释放,关注-XX:DisableExplicitGC 配置
通过反射监控NIO 和 Netty 的计数器字段
使用Dio.netty.leakDetectionLevel的netty自带排查功能
JNI Memory关注点(详见 扩展阅读-》案例部分)
JNI Memory的内存是因为JVM内存调用了Native方法,即C、C++方法,所以需要使用C、C++的思路去解决。C和C++的问题排查也是非常复杂的值得用一个专题去介绍。这里只是简单的结合网上的案例提供两个比较粗糙的方案。
- 方向1:1.gpertools分析谁没有释放内存:定位C、C++的函数 2.确认C、C++的函数对应的Java 方法 3.jstack或arthas的stack命令:Java方法对应的调用栈;
- 方向2:1.pmap定位内存块的分布:查看哪些内存块的Rss、Swap占用大 2.dump出内存块,打印出内存数据:把内存中的数据,打印成字符串,分析是什么数据 方向2具体操作参见pmap指令部分[9]和扩展阅读-》案例部分;
栈问题
这里粗略讨论两种栈溢出报错:StackoverflowError和OOM:unable to create new native thread。两者都可以粗略归类为栈相关的内存问题,StackoverflowError是当前线程的 JVM 栈帧空间耗尽报错;unable to create new native thread一般为1.内存中耗尽无法为新线程分配空间;2.系统层面线程数超过了限制。再次强调,栈的内存报错最快的定位方式就是在有应用日志的情况下查看日志相关异常关键字相关上下文。
Stackoverflow :
问题定位:
- 程序直接抛出StackOverflowError异常:直接可以检查 Java 调用栈看是哪个方法触发了溢出。注意,JVM可能不会完全打印所有栈帧,因为栈帧输出数量默认限制为1024(XX:MaxJavaStackTraceDepth=1024)。若需完整栈信息,将此参数设为-1。
- 分析Crash日志:如果进程崩溃后留下了Crash日志,查看日志中"Current thread"的栈范围和RSP寄存器的值。如果RSP值超出了栈范围,说明是栈溢出导致崩溃。
- 利用核心转储(core dump)分析:如果没有Crash日志,你需要依赖核心转储文件。在程序运行前设置ulimit -c unlimited来允许核心转储。进程崩溃时会生成core.<pid>文件,使用jstack $JAVA_HOME/bin/java core.<pid>来分析栈信息。检查是否有异常长的调用链。注意,使用jstack提取信息可能受到serviceability agent(SA)的bug影响。
根因分析:具体参见云栖社区-StackOverFlowError 常见原因及解决方法[10]
总结一下:
| 引发 StackOverFlowError 原因 | 解决方法 |
| 无限递归循环调用(eg.类之间的循环依赖) | 修bug,使用异常堆栈追踪重复的代码行 |
| 执行了大量方法导致线程栈空间耗尽 | 通过 -Xss 参数增加线程栈内存空间,如 -Xss2m |
| 方法内声明了海量的局部变量 | 通过 -Xss 参数增加线程栈内存空间以容纳更多局部变量 |
| native 代码在栈上分配了较大内存,如 java.net.SocketInputStream.read0 | 检查和优化 native 代码,或通过 -Xss 参数为线程栈分配更多空间 |
OutOfMemoryError: unable to create new native thread
报错原因为1.内存中耗尽无法为新线程分配空间;2.系统层面线程数超过了限制 。解决方法无非是从应用和系统两个层面上“开源节流“。
- 应用层面上分析线程,判断是否创建了过多的线程,谁创建的这些线程。线程的变化趋势也可以通过ARMS的监控监控到,线程相关分析可以使用ATP-线程分析功能[11]。
- 线程数触限:系统层面上对线程数有相关限制,可以通过ulimit -u 查看,可以适当调大系统线程数。
- 内存耗尽:财大气粗就升配,没有必要就评估一下减少-xss(会有stackflowerror风险)
三、扩展阅读
(一) JVM 内存简述
JVM内存属于JAVA基础中的基础,大家都很了解,这里主要是整合基础的介绍并在这个基础上针对调优使用的JVM参数或者基于ARMS的使用问题进行整合。关于具体内部更详细的调用逻辑和解析,推荐阅读《全网最硬核 JVM 内存解析》[12]系列。下面会基于阿里云ARMS官网的图进行简要说明,这里要强调的是,针对堆内存,大部分的监控体系的认识是一致的,但是针对堆外内存,不同的监控体系有有一些差别。我们的介绍以ARMS为准:
1. 堆内存(Heap):
简介:
JVM 的堆空间分成2个区域:年轻代、老年代
年轻代又进一步细分成3个区域:Eden、Survivor From、Survivor To

关联异常类型:
OutOfMemoryError:如果在堆中没有内存完成实例的分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
相关参数:
-Xmn: 新生代的内存大小
-Xms: Heap的初始大小
-Xmx: Heap的最大大小
-XX:NewRatio:新老年代分配:默认情况下,年轻代与老年代比例为1:2。NewRatio默认值是2。如果NewRatio修改成3,那么年轻代与老年代比例就是1:3
-XX:SurvivorRatio:年轻代分配:默认情况下Eden、From、To的比例是8:1:1。SurvivorRatio默认值是8,如果SurvivorRatio修改成4,那么其比例就是4:1:1
-XX:MaxTenuringThreshold:参数设置新生代对象的最大存活次数,默认值为15。如果设为0,新生代对象直接进入老年代,提升效率。设置较大值,对象会在Survivor区复制多次,延长新生代存活时间并增加被回收概率。具体来说,对象在eden区经历MinorGC后存活则移入Survivor区,年龄加1,达阀值则移入老年代。
相关问题:
问题1 :ARMS监控为什么显示堆内存和我设置的不同?
需要注意的是:根据Java垃圾收集器的不同,ARMS展示的最大允许使用堆内存有可能会略小于用户设置的堆内存上限。例如在ParallelGC垃圾收集器中,设置-XX:+UseParallelGC -Xms4096m -Xmx4096m -XX:NewRatio=3参数,会产生下图的结果,其中最大允许使用内存为3.8 G。这是因为在这种情况下MemoryMXBean收集的数据并没有包含From Space和To Space区域,导致了细微的偏差。这里最大使用内存为3.8G,NewRatio为3,那么年轻代与老年代比例就是1:3。年轻代内部Eden、From、To的比例是8:1:1。所以不无法监控到的From Space和To Space区域为0.2G左右,导致最终监控结果为3.8G。
问题2 :Xmx(Heap的最大大小)设置多大合适?
对于一般应用,建议将XMX设置为物理内存的1/2至2/3,以充分利用内存。然而,对于需要大量使用Heap外内存的应用,如ElasticSearch、RocketMQ-broker、Kafka等,由于需要大量读写文件,操作系统需要大量的Page Cache来提高性能,因此建议JVM内存不要超过1/2,以预留足够的非Heap内存。
2. 堆外内存:元空间(MetaSpace):
简介:
用于存储类元数据(如类定义和方法定义)的内存区域。Metaspace 在 JDK 8 中取代了永久代(PermGen)。
MetaSpace 主要由 Klass Metaspace 和 NoKlass Metaspace 两大部分组成。
- Klass MetaSpace:就是用来存 Klass 的,就是 Class 文件在 JVM 里的运行时数据结构,这部分默认放在 压缩类空间 中,是一块连续的内存区域,紧接着 Heap。Compressed Class Pointer Space 不是必须有的,如果设置了 -XX:-UseCompressedClassPointers,或者 -Xmx 设置大于 32 G,就不会有这块内存,这种情况下 Klass 都会存在 NoKlass Metaspace 里。
- NoKlass MetaSpace: 专门来存 Klass 相关的其他的内容,比如 Method,ConstantPool 等,可以由多块不连续的内存组成。虽然叫做 NoKlass Metaspace,但是也其实可以存 Klass 的内容,上面已经提到了对应场景。
关联异常类型:
java.lang.OutOfMemoryError: Metaspace
关联异常现象:
在JVM启动后或者某一特定时间点,MetaSpace的使用量持续增加,并且每次的垃圾回收(GC)都无法释放这部分空间。即使增大MetaSpace的容量,也无法根本解决这个问题。
相关参数:
-XX:MetaspaceSize:初始空间大小,达到该值就会触发垃圾收集,根据释放的空间进行动态缩小或增大。在 JDK 8 中,默认值为 21 MB。当元空间使用量达到这个值时,JVM 将触发 Full GC(也会附带younggc) 来尝试回收不再需要的类元数据以及相关资源。
-XX:MaxMetaspaceSize:最大空间,默认是没有限制的,最大可利用空间是整个系统内存的可用空间。
-XX:MinMetaspaceFreeRatio:在GC之后,最小的Metaspace剩余空间容量的百分比,默认40%,小于此值增大元空间。
-XX:MaxMetaspaceFreeRatio:在GC之后,最大的Metaspace剩余空间容量的百分比,默认70%,大于此值缩小元空间。
相关问题:
问题1 :Metaspace和PermGen有什么区别?
1) 存储位置不同:永久代在物理上是堆的一部分,和新生代、老年代的地址是连续的,而元空间属于本地内存。2) 存储内容不同:原来的永久代划分中,永久代用来存放类的元数据信息、静态变量以及常量池等。现在类的元信息存储在元空间,静态变量和常量池等并入堆中,相当于原来的永久代中的数据,被元空间和堆内存给瓜分了。
由于MetaSpace 直接位于本地内存,默认大小只受物理机限制,直到用完物理机内存才抛出 OOM。所以在某些情况下直接升级 JDK8 可能就出现内存持续增长的情况,在这种情况下通过 top 命令会发现内存猛涨,远超 Xmx 设置的大小, 但通过 jmap 则发现正常。这里有一个非常经典的Fastjson问题,之前宁波某客户就碰到了。参见元空间案例:
问题2 :堆内存使用量不高,为何会发生一次FULL GC?
这很可能是因为应用的JVM参数里没有设置-XX:MetaspaceSize,或者-XX:MetaspaceSize设置的比较小。在 JDK 8 中,默认值为 21 MB。当元空间使用量达到这个值时,JVM 将触发 Full GC(也会附带younggc) 来尝试回收不再需要的类元数据以及相关资源。
问题3:如何查看元空间内的信息或者获取元空间的具体对象?
如上文所说元空间本质是《Java虚拟机规范》中方法区概念在JAVA8之后的具体实现方式。所以具体定位方式通用的有三种,一种是 dump 快照之后通过 MAT 观察 Classes 的 Duplicate Classes。第二种是在调试环境中添加-verbose:class 查看类加载情况。最后一种是通过直接分析GC日志得到。可以参考如下Jcmd命令:统计在JVM的类加载中,每一个类的实例数量,并按照数量降序排列。
jcmd <PID> GC.class_stats|awk '{print$13}'|sed 's/\(.*\)\.\(.*\)/\1/g'|sort |uniq -c|sort -nrk13. 堆外内存:直接缓存(Direct Buffer):
简介:
是Java NIO 框架引入的一种内存分配机制,允许在堆外分配内存以便更高效地执行 I/O 操作,通常用于NIO网络编程,JVM使用该内存作为缓冲区,提升I/O性能。NIO的Buffer提供一个可以直接访问系统物理内存的类——DirectBuffer,普通的ByteBuffer仍在JVM堆上分配内存,其最大内存受到最大堆内存的 限制。而DirectBffer直接分配在物理内存中,并不占用堆空间。
优点:
1)改善堆过大时垃圾回收效率,减少停顿。Full GC时会扫描堆内存,回收效率和堆大小成正比。Native的内 存,由OS负责管理和回收。
2)可以提供更快的I/O操作,并且可以避免内存复制的开销,因此在处理大量数据时非常高效。大量的I/O操作会增加直接缓冲区内存占用。
3)可突破JVM内存大小限制。
关联异常类型:
NIO 中是:OutOfMemoryError: Direct buffer memory。
Netty 中是:OutOfDirectMemoryError: failed to allocate capacity byte(s) of direct memory (used: usedMemory , max: DIRECT_MEMORY_LIMIT )
关联异常现象:
内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。添加(NativeMemoryTracking) 进行分析。在项目中添加 -XX:NativeMemoryTracking=detailJVM参数后重启项目(需要注意的是,打开 NMT 会带来 5%~10% 的性能损耗)。使用命令 jcmd pid VM.native_memory detail 查看内存分布。重点观察 total 中的 committed,因为 jcmd 命令显示的内存包含堆内内存、Code 区域、通过 Unsafe.allocateMemory 和 DirectByteBuffer 申请的内存,但是不包含其他 Native Code(C 代码)申请的堆外内存。
如果 total 中的 committed 和 top 中的 RES 相差不大,则应为主动申请的堆外内存未释放造成的,如果相差较大,则基本可以确定是 JNI 调用造成的。
相关参数:
-XX:MaxDirectMemorySize:未设置默认值等于Xmx。当DirectMemory超过MaxDirectMemorySize时,触发FULL GC(也会附带Young GC),堆内DirectByteBuffer等对象回收时,会触发对象的clean逻辑,释放该对象关联的DirectMemory,当gc后还是不够,就会OOM。
相关问题:
问题1 :哪些地方使用了Direct Memory?
目前像Netty等IO框架,都会大量使用NIO;而很多RPC框架都会使用Netty。所以直接内存的OOM在分布式系统中可能会比较常见。
问题2:Netty内存泄漏如何排查?
Netty使用虚引用跟踪每一个 ByteBuf,同时Netty自带了一个内存泄漏的JVM参数
jvm启动参数增加 -Dio.netty.leakDetectionLevel=[检测级别]
- disabled 完全关闭内存泄露检测
- simple 以约1%的抽样率检测是否泄露,默认级别
- advanced 抽样率同simple,但显示详细的泄露报告
- paranoid 抽样率为100%,显示报告信息同advanced
注意抽样率越高,Netty性能越低!
开启项目后再模拟请求:复现泄漏点。Netty输出如下具体日志信息,类似下列结构:
WARNING: 1 leak records were discarded because the leak record count is limited to 4. Use system property io.netty.leakDetection.maxRecords to increase the limit.
Recent access records: 5
#5:
io.netty.buffer.AdvancedLeakAwareCompositeByteBuf.readBytes(AdvancedLeakAwareCompositeByteBuf.java:476)
io.netty.buffer.AdvancedLeakAwareCompositeByteBuf.readBytes(AdvancedLeakAwareCompositeByteBuf.java:36)
com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.getClientMassageInfo(LongRotationServerHandler.java:169)
com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.handleHttpFrame(LongRotationServerHandler.java:121)
com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.channelRead(LongRotationServerHandler.java:80)
io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
io.netty.channel.ChannelInboundHandlerAdapter.channelRead(ChannelInboundHandlerAdapter.java:86)
......可以比较清晰的看到Trace. 具体可以看参考文档案例《长连接Netty服务内存泄漏,看我如何一步步捉“虫”解决》
4. JNI内存:
简介:
JNI (Java Native Interface) memory是指Java应用程序与本地代码交互时使用的内存。Java Native Interface (JNI) 是 Java 与本地(如 C 或 C++)代码进行交互的桥梁。
JNI方法
使用方式:在Java中使用native关键字定义方法,并在C/C++代码中实现相关的本地方法。
示例:
private native int inflateBytes(long addr, byte[] b, int off, int len);该native方法内部也会申请内存用以存储数据,这部分内存属于JNI内存的一部分。
内存分配过程如图:来自参考文档
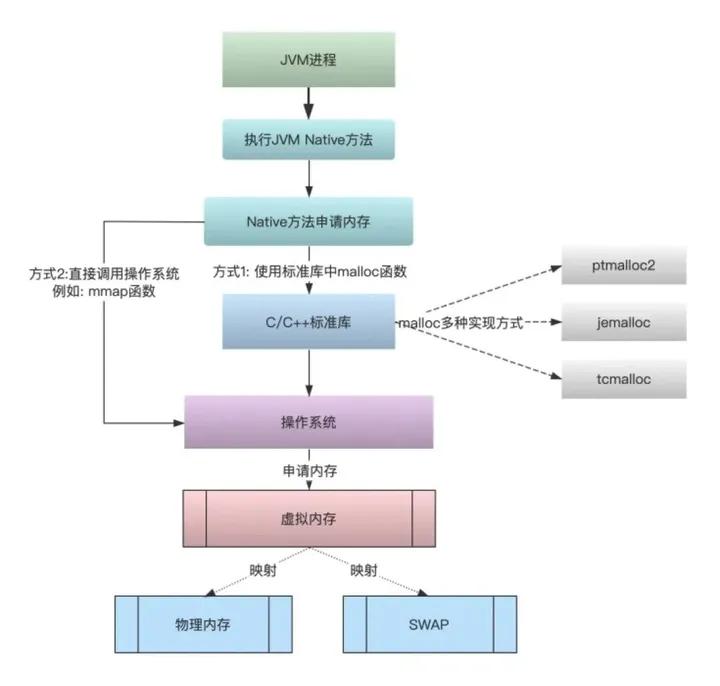
关联异常类型:
JNI内存泄露没有关联的异常类型
相关参数:
JNI Memory的内存是因为JVM内存调用了Native方法,即C、C++方法,所以需要使用C、C++的思路去解决。由于是调用本地的native方法,所以JVM层次没有特别限制这一情况的相关参数
相关问题:
问题1 :JNI问题的排查思路?
正如上文所说JNI Memory的内存是因为JVM内存调用了Native方法,即C、C++方法,所以需要使用C、C++的思路去解决。C和C++的问题排查也是非常复杂的值得用一个专题去介绍。这里只是简单的结合网上的案例提供两个比较粗糙的方案。
- 方向1:1.gpertools分析谁没有释放内存:定位C、C++的函数 2.确认C、C++的函数对应的Java 方法 3.jstack或arthas的stack命令:Java方法对应的调用栈
- 方向2:1.pmap定位内存块的分布:查看哪些内存块的Rss、Swap占用大 2.dump出内存块,打印出内存数据:把内存中的数据,打印成字符串,分析是什么数据 方向2具体操作参见pmap指令部分[13]和案例《一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问》
5. Stack(栈内存)[包括 本地线程栈(Native Stack) 和 虚拟机线程栈(VM Stack)]:
简介:
用于存储线程执行过程中的局部变量、方法调用、操作数栈等。栈内存由JVM自动管理,每个线程都有一个独立的栈。栈内存与堆内存相互独立,它们之间不共享数据。分为VM Stack(Java虚拟机栈)、Native Stack(本地方法栈)
- VM Stack(Java虚拟机栈) 用于存储线程执行Java方法时所需的信息。当一个方法执行完成后,其对应的栈帧会从栈中弹出,释放该方法所占用的内存空间。每个线程对应一个Java线程栈,大小由-Xss参数控制,默认是1M,当超过1M会报错StackOverFlowError。
- Native Stack(本地方法栈) 用于存储本地方法(通过Java Native Interface,JNI调用的方法)的信息。本地方法栈与Java虚拟机栈的主要区别在于,它是为本地方法提供内存空间,而不是Java方法。
关联异常类型:
两种异常:
StackOverFlowError :线程请求的栈深度>所允许的深度;
OutOfMemoryError:stack_trace_with_native_method 本地方法栈扩展时无法申请到足够的内存。
OutOfMemoryError: unable to create native thread:这个在创建太多的线程,超过系统配置的极限。如Linux默认允许单个进程可以创建的线程数是1024个。
相关参数:
-Xss 或者 -XX:ThreadStackSize :HotSpot虚拟机中并不区分虚拟机栈和本地方法栈,所以栈容量只能由-Xss参数来设定。-Xss 或者 -XX:ThreadStackSize 基本等价, 一般来说,-Xss 或者 -XX:ThreadStackSize 是用来设置每个线程的栈大小的,但是更严谨的说法是,它是设置每个线程栈最大使用的内存大小,并且实际可用的大小由于保护页的存在还要小于这个值。
相关问题:
问题1 :如何定位是否是栈溢出?
- 确认StackOverflowError异常:如果遇到StackOverflowError异常,这明显指示栈溢出。你可以检查 Java 调用栈看是哪个方法触发了溢出。注意,Java 虚拟机(JVM)可能不会完全打印所有栈帧,因为栈帧输出数量默认限制为1024(XX:MaxJavaStackTraceDepth=1024)。若需完整栈信息,将此参数设为-1。
- 分析Crash日志:如果进程崩溃后留下了Crash日志,查看日志中"Current thread"的栈范围和RSP寄存器的值。如果RSP值超出了栈范围,说明是栈溢出导致崩溃。
- 利用核心转储(core dump)分析:如果没有Crash日志,你需要依赖核心转储文件。在程序运行前设置ulimit -c unlimited来允许核心转储。进程崩溃时会生成core.<pid>文件,使用jstack $JAVA_HOME/bin/java core.<pid>来分析栈信息。检查是否有异常长的调用链。注意,使用jstack提取信息可能受到serviceability agent(SA)的bug影响。
(二) 常见案例
这里的案例会收集根因相同但是排查逻辑和思路不同的案例,用于我之后排查问题初步定位后可以快速Mapping。这里的例子多是常见组件或者常见代码的BUG或者系统本身的坑,目前收集的内容多以堆外内存为主。
各位大佬有碰到有趣的案例或者文章可以在评论区贴出!!!然后您有空的话总结一下关键词或者我之后学习一遍总结关键词,然后我补充在案例里面。
1. JNI Memory 溢出:
一、Linux使用默认ptmalloc2内存分配器在高并发分配内存时,存在较多内存碎片无法释放
关键词:Linux经典64MB问题,ptmalloc2,glibc,malloc
解决方法:
- 治标:调用malloc_trim手动释放内存
- 治本:更换ptmalloc2为jemalloc或者tcmalloc(两者各有优劣,慎重变更)
关联问题:GZip问题,stream流问题
关联文章:
【JVM案例篇】堆外内存(JNI Memory)泄漏(Linux经典64M内存块问题) [14]
一句话描述:文章描述了完整JNI 内存问题的定位和排查思路,推荐
一次 Java 进程 OOM 的排查分析(glibc 篇) [15]
一句话描述:相较于前文注重流程化排查,本文更深入原理。
二、在Java中流对象(FileInputStream)、网络连接对象(Socket)一般都关联了原生资源,对象未关闭导致native内存无法释放
关键词:Java.util.zip.Inflater, Gzip, hibernate
解决方法:定位到代码段,升级落后版本依赖,关闭Stream,难点主要在定位和排查。
关联文章:
一次大量 JVM Native 内存泄露的排查分析(64M 问题) [16]
一句话描述:hibernate源码中的流没有关闭导致泄漏,排查逻辑值得学习
一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问[17]
一句话描述:Gzip流未关闭问题,作者使用pmap快速定位到了问题代码,值得一提的是:kafka的consumer、provider端处理gzip压缩算法时,都是可能出现JNI Memory内存泄露问题。如果将kafka消息的压缩算法gzip改为其他算法,例如Snappy、LZ4,这些压缩算法可以规避掉JVM的gzip解、压缩使用JNI Memory的问题。
2. 元空间泄漏:
关键词:fastjson, beanCopy, Orika, Groovy, 反射,CGLIB 动态代理
如前文JVM内存部分元空间部分所描述的,元空间的问题原理比较复杂,但是问题定位比较简单,无论是使用阿里云ATP的GC分析日志,还是直接在线上的监控直接观察到元空间的异常变动。都可以快速定位到元空间问题。经常会出问题的几个点有 Orika 的 classMap、JSON 的 ASMSerializer、Groovy 动态加载类,bean copy等,基本都集中在反射、Javasisit 字节码增强、CGLIB 动态代理、OSGi 自定义类加载器等的技术点上。
题外话:这类问题比较容易发生的场景是老旧系统从java 1.7升级1.8的时候,没有设置MaxMetaspaceSize参数,导致元空间没有限制打爆了pod,所以才暴露出来问题。
关联文章:
一、FastJson 元空间泄漏相关文章,这类文章在内部和外部都出现过挺多次了,属于比较容易踩的一个坑了:
一次完整的JVM堆外内存泄漏故障排查记录| Java Debug 笔记 [18]
记录一次MetaSpace OOM问题排查历程[19]
二、Groovy 导致的元空间泄漏
大量类加载器创建导致诡异FullGC | HeapDump性能社区[20]
一句话总结:MAT使用的实践,值得一看。
三、 beanCopy导致的元空间泄漏
记一次Bean Copy导致Metaspace OOM [21]
又一个beanCopy引发的血案metaspace溢出_beanutil.copyproperties metaspace oomm[22]
为什么阿里代码规约要求避免使用 Apache BeanUtils 进行属性的拷贝 [23]
一句话总结:三篇实际内容相似,如果大量使用底层基于反射的apache的BeanUtils和spring的BeanUtils会创建大量的DelegatingClassLoader。导致元空间溢出。推荐使用cglib方式的beancopy
3. Direct Memory溢出:
关键词:Netty, 分布式,RPC
直接内存宕机问题。常见于NIO、Netty等相关组件和使用了这些组件的相关RPC框架。直接内存泄漏的判断不难,基本上会有如下步骤:
- top发现JAVA实际占用的RES 甚至超过了 -Xmx 的大小,内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象。
- 初步判断堆外内存泄漏是否和direct memory强相关。这里可以使用 NMT(NativeMemoryTracking)[24] 进行分析。在项目中添加 -XX:NativeMemoryTracking=detail JVM参数后重启项目(需要注意的是,打开 NMT 会带来 5%~10% 的性能损耗)。使用命令 jcmd pid VM.native_memory detail 查看内存分布。重点观察 total 中的 committed,因为 jcmd 命令显示的内存包含堆内内存、Code 区域、通过 Unsafe.allocateMemory 和 DirectByteBuffer 申请的内存,但是不包含其他 Native Code(C 代码)申请的堆外内存。如果 total 中的 committed 和 top 中的 RES 相差不大,则应为主动申请的Direct Memory未释放造成的。
判断是Direct Memory是比较容易的,锁定具体代码堆栈位置有一定的工作量:
Netty堆外内存泄露排查盛宴[25]
一句话总结:美团技术团队的文章,涉及到Idea debug的具体流程,通过反射监控Netty 中 io.netty.util.internal.PlatformDependent#DIRECT_MEMORY_COUNTER。有参考性
长连接Netty服务内存泄漏,看我如何一步步捉“虫”解决[26]
一句话总结:Netty泄漏,文章更新,使用Dio.netty.leakDetectionLevel的netty自带排查功能 JVM参数可以参考。
java 堆外内存监控_mob64ca12ddcacc的技术博客[27]
一句话总结:通过反射监控NIO 中的 java.nio.Bits#totalCapacity
4. 栈溢出
关键词:递归,调用栈过深
StackoverflowError 更多的涉及到具体框架的回调和循环调用逻辑, 包括bug或者漏洞。很多组件的github issue中都会提到。比如比较典型的log4j-over-slf4j.jar 和 slf4j-reload4j 在同一个classpath下会递归调用。
Detected both log4j-over-slf4j.jar AND slf4j-reload4j on the class path, preempting StackOverflowError.[28]
排查推荐云栖社区-StackOverFlowError 常见原因及解决方法 非常清晰![29]
Troubleshoot OutOfMemoryError: Unable to Create New Native Thread[30]
一句话总结:应该是全网最清晰的Unable to Create New Native Thread 的排查文章了,感觉看这篇就够了。
5. OOM-Killer
跳出JVM内存管理后,当实例全局内存或实例内cgroup的内存不足时,Linux 会选择内存占用最多,优先级最低或者最不重要的进程杀死。一般在容器里,主要的进程就是肯定是我们的 JVM ,一旦内存满,第一个杀的就是它,而且还是 kill -TERM (-9)信号,打你一个猝不及防。
- 如果 生产环境容器只有JVM一个进程在跑,JVM 内存参数配置合理,远低于容器内存限制,,还是出现了 OOM Killer 的话,那么恭喜你,大概率是有什么 Native 内存泄漏,请跳转上文排查 JNI Memory 溢出。
- 如果生产环境中有多个进程在跑,比如有JAVA进程,监控日志进程(Filebeat),定时调度脚本等,手动运维变更动作。。。那就需要具体看日志看到底是谁触发oom,oom时的内存分布是什么了。
推荐阅读阿里云官网的出现OOM Killer的原因与解决方案 [31]和 为什么应用运行时进程突然消失了[32]?
日志搜索命令一般为
grep -i 'killed process' /var/log/messages
或者
egrep "oom-killer|total-vm" /var/log/messages日志解读主要关注三段:谁触发了oom-killer;最后杀死了谁;当时进程的相关信息。
解读OOM killer机制输出的日志[33]
[20220707-022639][23457.059849] ptz_task invoked oom-killer: gfp_mask=0x24200ca(GFP_HIGHUSER_MOVABLE), nodemask=0, order=0, oom_score_adj=0
[20220707-022639][23457.079399] CPU: 0 PID: 732 Comm: ptz_task Not tainted 4.9.191 #4
[20220707-022639][23457.104264] Hardware name: sun8iw21
.......
[20220707-022639][23457.551958] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name
[20220707-022639][23457.577207] [ 632] 0 632 254 41 3 0 0 0 telnetd
[20220707-022639][23457.587485] [ 633] 0 633 232 43 3 0 0 0 adbd
[20220707-022639][23457.607393] [ 657] 0 657 585 72 4 0 0 0 wpa_supplicant
[20220707-022639][23457.628416] [ 660] 0 660 254 36 3 0 0 0 telnetd
[20220707-022639][23457.641304] [ 673] 0 673 244 48 3 0 0 0 sk_srv_syscall
[20220707-022639][23457.662083] [ 676] 0 676 17203 4349 35 0 0 0 skyapp
[20220707-022639][23457.682194] [ 677] 0 677 254 41 3 0 0 0 exe
[20220707-022639][23457.698911] [ 899] 0 899 1056 97 6 0 0 0 skmongoose
[20220707-022639][23457.712344] [ 900] 0 900 254 41 3 0 0 0 clearCached.sh
[20220707-022639][23457.733172] [ 921] 0 921 254 33 3 0 0 0 udhcpc
[20220707-022639][23457.752165] [ 1210] 0 1210 254 42 3 0 0 0 ash
[20220707-022639][23457.762516] [11670] 0 11670 254 41 3 0 0 0 sleep
[20220707-022639][23457.773158] [12021] 0 12021 228 24 3 0 0 0 sleep
[20220707-022639][23457.788033] [12023] 0 12023 244 48 3 0 0 0 sk_srv_syscall
[20220707-022639][23457.819352] Out of memory: Kill process 676 (skyapp) score 276 or sacrifice child
[20220707-022639][23457.838273] Killed process 676 (skyapp) total-vm:68812kB, anon-rss:16536kB, file-rss:820kB, shmem-rss:40kB
[20220707-022639][23457.882911] oom_reaper: reaped process 676 (skyapp), now anon-rss:0kB, file-rss:0kB, shmem-rss:40kB(三) 常用Linux指令
Top
【技术指南】每天一个命令:top工具命令[34]
第一行:输出系统任务队列信息
- 21:08:13:系统当前时间
- up 1 day:系统开机后到现在的总运行时间
- 3 user:当前登录用户数
- load average: 0.12, 0.08, 0.06:系统负载,系统运行队列的平均利用率,可认为是可运行进程平均数;三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二行:任务进程信息
- total:系统全部进程的数量
- running:运行状态的进程数量
- sleeping:睡眠状态的进程数量
- stoped:停止状态的进程数量
- zombie:僵尸进程数量
第三行:CPU信息
- us:用户空间占用CPU百分比
- sy:内核空间占用CPU百分比
- ni:已调整优先级的用户进程的CPU百分比
- id:空闲CPU百分比,越低说明CPU使用率越高
- wa:等待IO完成的CPU百分比
- hi:处理硬件中断的占用CPU百分比
- si:处理软中断占用CPU百分比
- st:虚拟机占用CPU百分比
第四行:物理内存信息
以下内存单位均为MB
- total:物理内存总量
- free:空闲内存总量
- used:使用中内存总量
- buw/cache:用于内核缓存的内存量
第五行:交换区内存信息
- total:交换区总量
- free:空闲交换区总量
- used:使用的交换区总量
- avail Mem:可用交换区总量
注:如果used不断在变化, 说明内核在不断进行内存和swap的数据交换,说明内存真的不够用了。
进行信息区
- top 输出界面的顶端,也显示了系统整体的内存使用情况,这些数据跟 free 类似。
- PID:进程号
- USER:运行进程的用户
- PR:优先级
- NI:nice值。负值表示高优先级,正值表示低优先级
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享 内存。
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及 程序的代码段等。
- S:进程状态 (R运行状态 S睡眠状态 D不可中断状态 T跟踪/停止 Z僵尸进程)
- %CPU:CPU 使用率
- %MEM:进程使用物理内存占系统总内存的百分比
- TIME+:上次启动后至今的总运行时间
- COMMAND:命令名or命令行
在查看 top 输出时,还要注意两点:
第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,可以发现每个进程的虚拟内存都比常驻内存大得多。
第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库, 也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
pmap
pmap(英文全拼:process memory map)命令用于查看进程的内存映射。
语法:
pmap [options] pid [...]选项:
-x, --extended :显示扩展格式。
-d, --device :显示设备格式。
-q, --quiet :不显示 header 和 footer 行。
-A, --range low,high :将给定范围内的结果限制为低地址和高地址范围。请注意,low 和 high 参数是用逗号分隔的单个字符串。
-X :显示比 -x 选项更多的详细信息。注意:格式根据 /proc/PID/smaps 更改。
-XX :显示内核提供的一切。
-p, --show-path :在映射列中显示文件的完整路径。
-c, --read-rc :读取默认配置。
-C, --read-rc-from file :从文件 file 中读取配置。
-n, --create-rc :创建新的默认配置。
-N, --create-rc-to file :创建新的配置,并保存到文件。
-h, --help :显示帮助信息并退出。
-V, --version :显示版本信息并退出。场景一:JNI内存排查:比较新增内存块内容:
linux进程启动时,有代码段、数据段、堆(Heap)、栈(Stack)及内存映射段,在运行过程中,应用程序调用malloc、mmap等C库函数来使用内存,C库函数内部则会视情况通过brk系统调用扩展堆或使用mmap系统调用创建新的内存映射段。所以排查的逻辑:
- 检查那些占用内存较大的内存段,如下
pmap -x 1 | sort -nrk3 | less- 检查一段时间后新增了哪些内存段,或哪些变大了,如下:在不同的时间点多次保存pmap命令的输出,然后通过文本对比工具查看两个时间点内存段分布的差异。
pmap -x 1 > pmap-`date +%F-%H-%M-%S`.log- icdiff 获取新增内存块
icdiff pmap-2023-07-27-09-46-36.log pmap-2023-07-28-09-29-55.log | less -SR- 查看变化的内存块内存储的字符串:
tail -c +$((0x00007face0000000+1)) /proc/$pid/mem|head -c $((11616*1024))|strings|less -S命令解释:
1、tail -c +$((0x00007face0000000+1)) /proc/$pid/mem
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java