
浅析数据对大语言模型的影响
由于大语言模型的训练需要巨大的计算资源,通常不可能多次迭代大语言模型预训练。千亿级参数量的大语言模型每次预训练的计算需要花费数百万元人民币。因此,在训练大语言模型之前,构建一个准备充分的预训练语料库尤为重要。
本篇文章中,将从数据规模、数量质量以及数据多样性三个方面分析数据对大语言模型的性能的影响。需要特别的说明的是,由于在千亿参数规模的大语言模型上进行实验的成本非常高,很多结论是在100 亿甚至是10 亿规模的语言模型上进行的实验,其结果并不能完整的反映数据对大语言模型的影响。此外,一些观点仍处于猜想阶段,需要进一步验证。需要各位读者甄别判断。
1.数据规模影响
随着大语言模型参数规模的增加,为了有效地训练模型,需要收集足够数量的高质量数据,在文献 针对模型参数规模、训练数据量以及总计算量与模型效果之间关系的研究之前,大部分大语言模型训练所采用的训练数据量相较于LLaMA 等最新的大语言模型模型都少很多。
表1给出了模型参数量和预训练数据量对比。在Chinchilla 模型提出之前,大部分的大语言模型都在着重提升模型的参数量,但是所使用的训练语料数量都在3000 亿词元左右,LAMDA 模型所使用的训练语料数量甚至仅有1680 亿。虽然Chinchilla 模型参数量仅有LAMDA 模型一半大小,但是训练语料的词元数量却达到了1.4 万亿词元,是LaMDA 模型训练语料的8 倍多。
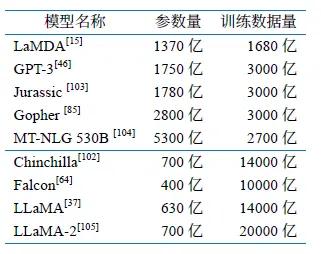
表1模型参数量与训练语料数量对比
DeepMind 的研究人员在文献 中给出了他们通过训练参数范围从7000 万到160 亿,训练词元数量从5 亿到5000 亿不等的400 多个语言模型所得到分析结果。研究发现,如果模型训练要达到计算最优(Compute-optimal),模型大小和训练词元数量应该等比例缩放,即模型大小加倍则训练词元数量也应该加倍。为了验证该分析结果,他们使用与Gopher 语言模型训练相同的计算资源,根据上述理论预测了Chinchilla 语言模型的最优参数量与词元数量组合。最终确定Chinchilla语言模型为700 亿参数,使用了1.4 万亿词元进行训练。通过实验发现,Chinchilla 在很多下游评估任务中都显著地优于Gopher(280B)、GPT-3(175B)、Jurassic-1(178B)以及Megatron-Turing NLG(530B)。
图1.1 给出了在同等计算量情况下,训练损失随参数量的变化情况。针对9 种不同的训练参数量设置,使用不同词元数量的训练语料,训练不同大小的模型参数量,使得最终训练所需浮点运算数达到预定目标。对于每种训练量预定目标,图中左侧绘制了平滑后的训练损失与参数量之间的关系。从左图中可以看到,训练损失值存在明显的低谷,这意味着对于给定训练计算量目标,存在一个最佳模型参数量和训练语料数量配置。利用这些训练损失低谷的位置,还可以预测更大的模型的最佳模型参数量大小和训练词元数量,如图3.5中间和右侧所示。图中绿色线表示使用Gopher训练计算量所预测的最佳模型参数量和训练数据词元数量。还可以使用幂律(Power Law)对计算量限制、损失最优模型参数量大小以及训练词元数之间的关系进行建模。C 表示总计算量、Nopt表示模型最优参数量、Dopt 表示最优训练词元数量,他们之间的关系符合一下关系:
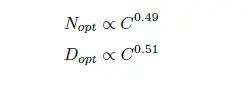
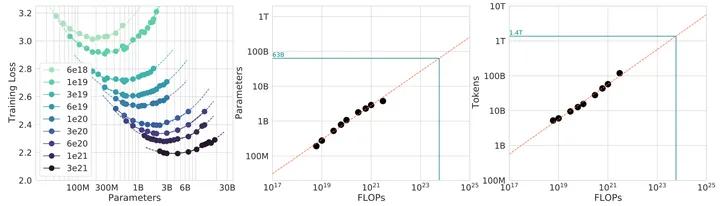
图1.1 在同等计算量情况下,训练损失随参数量的变化情况
LLaMA 模型在训练时采用了与文献相符的训练策略。研究发现,70 亿参数的语言模型在训练超过1 万亿个词元(1T Tokens)后,性能仍在持续增长。因此,Meta 的研究人员在LLaMA2模型训练中,进一步增大了训练数据量,训练数据量达到了2 万亿词元。文献给出了不同参数量模型在训练期间,随着训练数据量的增加,模型在问答和常识推理任务上的效果演变过程,如图2.1所示。研究人员分别在TriviaQA、HellaSwag、NaturalQuestions、SIQA、WinoGrande以及PIQA 等6 个数据集上进行了测试。可以看到,随着训练数据量的不断提升,模型在分属两类任务的6 个数据集上的性能都在稳步提高。通过使用更多的数据和更长的训练时间,较小的模型也可以实现良好的性能。
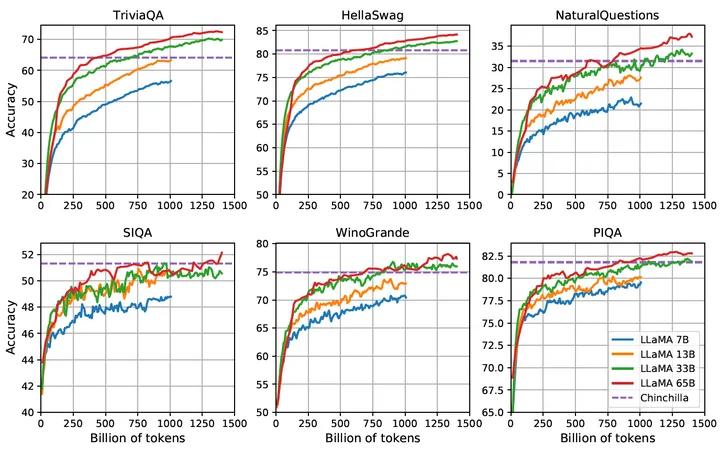
图1.2 LLaMA 模型训练期间在问答和常识推理任务上效果演变
文献对不同任务类型所依赖的语言模型训练数量进行了分析。针对分类探查(ClassifierProbing)、信息论探查(Info-theoretic Probing)、无监督相对可接受性判断(Unsupervised Relative Acceptability Judgment)以及应用于自然语言理解任务的微调(Fine-tuning on NLU Tasks)等四类任务,基于不同量级预训练数据的RoBERTa模型在上述不同类型任务上的效果进行了实验验证和分析。分别针对预训练了1M、10M、100M 和1B 个单词的RoBERTa 模型进行了能力分析。研究发现,模型只需要约10M 到100M 个单词的训练,就可以可靠地获得语法和语义特征。但是需要更多的数据量训练才能获得足够的常识知识和其他技能,并在典型下游自然语言理解任务中取得较好的结果。
2 数据质量影响
数据质量通常被认为是影响大语言模型训练效果的关键因素之一,包含大量重复的低质量数据甚至导致训练过程不稳定,造成模型训练不收敛。现有的研究表明训练数据的构建时间、包含噪音或有害信息情况以及数据重复率等因素,都对语言模型性能存在较大影响。截止到2023 年9 月的研究都得出了相同的结论,即语言模型在经过清洗的高质量数据上训练数据可以得到更高的性能。
文献介绍了Gopher 语言模型在训练时针对文本质量进行的相关实验。如图2.1所示,具有140 亿参数的模型在OpenWebText、C4 以及不同版本的MassiveWeb 数据集上训练得到的模型效果对比。他们分别测试了利用不同数据训练得到的模型在Wikitext103 单词预测、Curation Corpus摘要以及LAMBADA 书籍级别的单词预测三个下游任务上的表现。图中Y 轴表示不同任务上的损失,数值越低表示性能越好。从结果可以看到,使用经过过滤和去重后的MassiveWeb 数据训练得到的语言模型在三个任务上都远好于使用未经处理的数据训练得到的模型。使用经过处理的MassiveWeb 数据训练得到的语言模型在下游任务上的表现也远好于使用OpenWebText 和C4 数据集训练得到的结果。
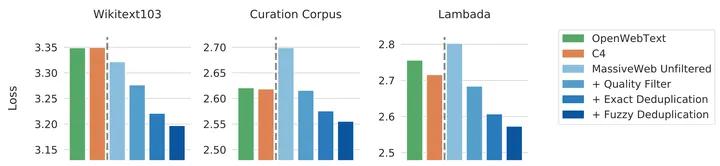
图2.1 Gopher 语言模型使用不同数据质量训练效果分析
GLaM 语言模型构建时,同样也对训练数据质量的影响的进行了分析。该项分析同样使用包含17 亿参数的模型,针对下游少样本任务性能进行了分析。使用相同超参数,对通过原始数据集和经过质量筛选后的数据训练得到的模型效果进行了对比,实验结果如图2.2所示。可以看到,使用高质量数据训练的模型在自然语言生成和自然语言理解任务上表现更好。特别是,高质量数据对自然语言生成任务上的影响大于在自然语言理解任务。这可能是因为自然语言生成任务通常需要生成高质量的语言,过滤预训练语料库对于语言模型的生成能力至关重要。文献[86] 的研究强调了预训练数据的质量在下游任务的性能中也扮演着关键角色。
Google Research 的研究人员针对数据构建时间、文本质量、是否包含有害信息开展了系统研究。使用具有不同时间、毒性和质量以及领域组成的数据,训练了28 个15 亿参数的仅解码器结构语言模型。研究结果表明,语言模型训练数据的时间、内容过滤方法以及数据源对下游模型行为具有显著影响。
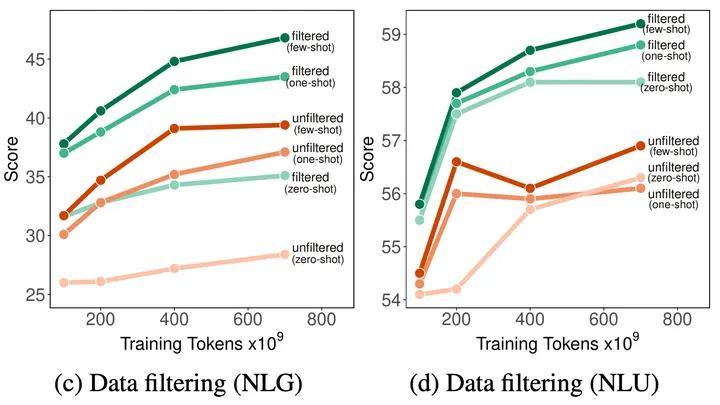
图2.2 GLaM 语言模型使用不同数据质量训练效果分析
针对数据时效性对于模型效果的影响问题,研究人员们在C4 语料集的2013、2016、2019 和2022 等不同版本上训练了四个自回归语言模型。对于每个版本,从Common Crawl 数据上删除了截止年份之后爬取的所有数据。使用新闻、Twitter 和科学领域的评估任务来衡量时间错位的影响。
这些评估任务的训练集和测试集按年份划分,分别在每个按年份划分的数据集上微调模型,然后在所有年份划分的测试集上进行评估。图2.3给出了使用4 个不同版本的数据集所训练得到的模型在5 个不同任务上的评测结果。热力图颜色(Heatmap Colors)根据每一列进行归一化得到。从图中可以看到,训练数据和测试数据的时间错配会在一定程度上影响模型的效果。
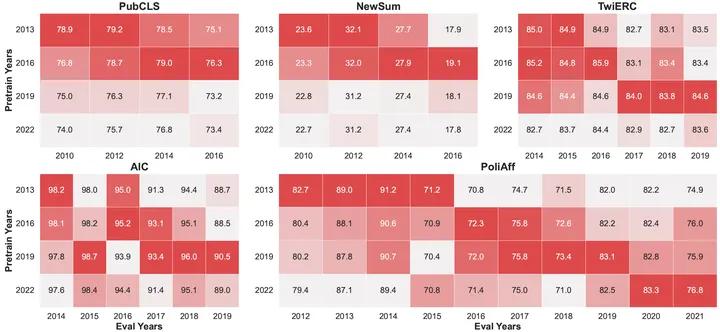
图2.3 训练数据和测试数据之间的时间错位情况下性能分析
Anthropic 的研究人员针对数据集中的重复问题开展了系统研究。为了研究数据重复对大语言模型的影响,研究人员构建了特定的数据集,其中大部分数据是唯一的,但是只有一小部分数据被重复多次,并使用这个数据集训练了一组模型。研究发现了一个强烈的双峰下降现象,即重复数据可能会导致训练损失在中间阶段增加。例如,通过将0.1% 的数据重复100 次,即使其余90% 的训练数据保持不变,一个800M 参数的模型的性能也可能降低到与400M 参数的模型相同。此外,研究人员还设计了一个简单的复制评估,即将哈利·波特(Harry Potter)的文字复制11 次,计算模型在第一段上的损失。在仅有3% 的重复数据的情况下,训练过程中性能最差的轮次仅能达到参数量为1/3 的模型的结果。
文献 中对大语言模型的记忆能力进行分析,根据训练样例在训练数据中出现的次数,显示了记忆率的变化情况,如图2.4所示。可以看到,在训练中只见过一次的样例,Palm 模型的记忆率为0.75%,而见过500 次以上的样例的记忆率超过40%。这也在一定程度上说明重复数据对于语言模型建模具有重要影响。这也可能进一步影响使用上下文学习的大语言模型的泛化能力。由于Palm 方法仅使用了文档级别过滤,因此片段级别(100 个以上Token)可能出现非常高的重复次数。
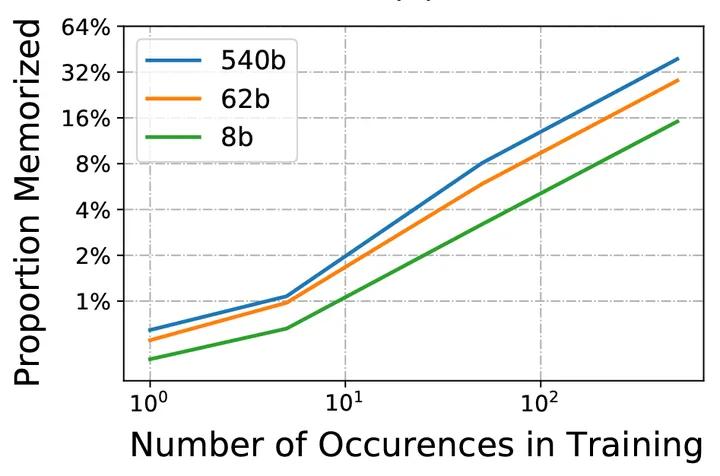
图2.4 大语言模型记忆能力评
3.数据多样性影响
来自不同领域、使用不同语言、应用于不同场景的训练数据具有不同的语言特征,包含不同语义知识。通过使用不同来源的数据进行训练,大语言模型可以获得广泛的知识。表3.2给出了LLaMA模型训练所使用数据集合。可以看到LLaMA 模型训练混合了大量不同来源数据,包括网页、代码、论文、图书、百科等。针对不同的文本质量,LLaMA 模型训练针对不同质量和重要性的数据集设定了不同的采样概率,表中给出了不同数据集在完成1.4 万亿词元训练时,每个数据集的采样轮数。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java