
如何充分发挥 SQL 能力?
一、前言
1.1 初衷
如何高效地使用 MaxCompute(ODPS)SQL ,将基础 SQL 语法运用到极致。
在大数据如此流行的今天,不只是专业的数据人员,需要经常地跟 SQL 打交道,即使是产品、运营等非技术同学,也会或多或少地使用到 SQL ,如何高效地发挥 SQL 的能力,继而发挥数据的能力,变得尤为重要。
MaxCompute(ODPS)SQL 发展到今天已经颇为成熟,作为一种 SQL 方言,其 SQL 语法支持完备,具有非常丰富的内置函数,支持开窗函数、用户自定义函数、用户自定义类型等诸多高级特性,可以高效地应用在各种数据处理场景。
如何充分发挥 SQL 能力,是本篇文章的主题。本文尝试独辟蹊径,强调通过灵活的、发散性的数据处理思维,就可以用最基础的语法,解决复杂的数据场景。
1.2 适合人群
不论是初学者还是资深人员,本篇文章或许都能有所帮助,不过更适合中级、高级读者阅读。
本篇文章重点介绍数据处理思维,并没有涉及到过多高阶的语法,同时为了避免主题发散,文中涉及的函数、语法特性等,不会花费篇幅进行专门的介绍,读者可以按自身情况自行了解。
1.3 内容结构
本篇文章将围绕数列生成、区间变换、排列组合、连续判别等主题进行介绍,并附以案例进行实际运用讲解。每个主题之间有轻微的前后依赖关系,依次阅读更佳。
1.4 提示信息
本篇文章涉及的 SQL 语句只使用到了 MaxCompute(ODPS)SQL 基础语法特性,理论上所有 SQL 均可以在当前最新版本中运行,同时特意注明,运行环境、兼容性等问题不在本篇文章关注范围内。
二、数列
数列是最常见的数据形式之一,实际数据开发场景中遇到的基本都是有限数列。本节将从最简单的递增数列开始,找出一般方法并推广到更泛化的场景。
2.1 常见数列
2.1.1 一个简单的递增数列
首先引出一个简单的递增整数数列场景:
- 从数值 0 开始;
- 之后的每个数值递增 1 ;
- 至数值 3 结束;
如何生成满足以上三个条件的数列?即 [0,1,2,3] 。
实际上,生成该数列的方式有多种,此处介绍其中一种简单且通用的方案。
-- SQL - 1
select
t.pos as a_n
from (
select posexplode(split(space(3), space(1), false))
) t;
通过上述 SQL 片段可得知,生成一个递增序列只需要三个步骤:
1)生成一个长度合适的数组,数组中的元素不需要具有实际含义;
2)通过 UDTF 函数 posexplode 对数组中的每个元素生成索引下标;
3)取出每个元素的索引下标。以上三个步骤可以推广至更一般的数列场景:等差数列、等比数列。下文将以此为基础,直接给出最终实现模板。
2.1.2 等差数列
SQL 实现:
-- SQL - 2
select
a + t.pos * d as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;2.1.3 等比数列

SQL 实现:
-- SQL - 3
select
a * pow(q, t.pos) as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;提示:亦可直接使用 MaxCompute(ODPS)系统函数 sequence 快速生成数列。
-- SQL - 4
select sequence(1, 3, 1);
-- result
[1, 2, 3]2.2 应用场景举例
2.2.1 还原任意维度组合下的维度列簇名称
在多维分析场景下,可能会用到高阶聚合函数,如 cube 、 rollup 、 grouping sets 等,可以针对不同维度组合下的数据进行聚合统计。
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 5
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;现针对省份 province , 城市 city, 设备类型 device_type 三个维度列,通过grouping sets聚合统计得到了不同维度组合下的用户访问量。问:1)如何知道一条统计结果是根据哪些维度列聚合出来的?
2)想要输出 聚合的维度列的名称,用于下游的报表展示等场景,又该如何处理?
解决思路
可以借助 MaxCompute(ODPS)提供的 GROUPING__ID 来解决,核心方法是对 GROUPING__ID 进行逆向实现。
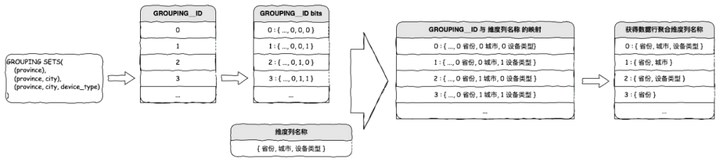
一、准备好所有的 GROUPING__ID 。

| GROUPING__ID | bits |
| 0 | { ..., 0, 0, 0 } |
| 1 | { ..., 0, 0, 1 } |
| 2 | { ..., 0, 1, 0 } |
| 3 | { ..., 0, 1, 1 } |
| ... | ... |
| 2n2n | ... |

二、准备好所有维度名称。
{ dim_name_1, dim_name_2, ..., dim_name_n }三、将 GROUPING__ID 映射到维度列名称。
对于 GROUPING__ID 递增数列中的每个数值,将该数值的 2 进制每个比特位与维度名称序列的下标进行映射,输出所有对应比特位 0 的维度名称。例如:
GROUPING__ID:3 => { 0, 1, 1 }
维度名称序列:{ 省份, 城市, 设备类型 }
映射:{ 0:省份, 1:城市, 1:设备类型 }
GROUPING__ID 为 3 的数据行聚合维度即为:省份SQL 实现
-- SQL - 6
with group_dimension as (
select -- 每种分组对应的维度字段
gb.group_id, concat_ws(",", collect_list(case when gb.placeholder_bit = 0 then dim_col.val else null end)) as dimension_name
from (
select groups.pos as group_id, pe.*
from (
select posexplode(split(space(cast(pow(2, 3) as int) - 1), space(1), false))
) groups -- 所有分组
lateral view posexplode(regexp_extract_all(lpad(conv(groups.pos,10,2), 3, "0"), '(0|1)')) pe as placeholder_idx, placeholder_bit -- 每个分组的bit信息
) gb
left join ( -- 所有维度字段
select posexplode(split("省份,城市,设备类型", ','))
) dim_col on gb.placeholder_idx = dim_col.pos
group by gb.group_id
)
select
group_dimension.dimension_name,
province, city, device_type,
visit_count
from (
select
grouping_id(province, city, device_type) as group_id,
province, city, device_type,
count(1) as visit_count
from visit_log b
group by province, city, device_type
GROUPING SETS(
(province),
(province, city),
(province, city, device_type)
)
) t
join group_dimension on t.group_id = group_dimension.group_id
order by group_dimension.dimension_name;| dimension_name | province | city | device_type | visit_count |
| 省份 | 湖北 | NULL | NULL | 3 |
| 省份 | 湖南 | NULL | NULL | 2 |
| 省份 | 四川 | NULL | NULL | 1 |
| 省份,城市 | 湖北 | 武汉 | NULL | 2 |
| 省份,城市 | 湖南 | 长沙 | NULL | 1 |
| 省份,城市 | 湖南 | 邵阳 | NULL | 1 |
| 省份,城市 | 湖北 | 孝感 | NULL | 1 |
| 省份,城市 | 四川 | 成都 | NULL | 1 |
| 省份,城市,设备类型 | 湖北 | 孝感 | Mac | 1 |
| 省份,城市,设备类型 | 湖南 | 长沙 | IOS | 1 |
| 省份,城市,设备类型 | 湖南 | 邵阳 | Android | 1 |
| 省份,城市,设备类型 | 四川 | 成都 | Windows | 1 |
| 省份,城市,设备类型 | 湖北 | 武汉 | Android | 1 |
| 省份,城市,设备类型 | 湖北 | 武汉 | IOS | 1 |
三、区间
区间相较数列具有不同的数据特征,不过在实际应用中,数列与区间的处理具有较多相通性。本节将介绍一些常见的区间场景,并抽象出通用的解决方案。
3.1 常见区间操作
3.1.1 区间分割

SQL 实现:
-- SQL - 7
select
a + t.pos * d as sub_interval_start, -- 子区间起始值
a + (t.pos + 1) * d as sub_interval_end -- 子区间结束值
from (
select posexplode(split(space(n - 1), space(1), false))
) t;3.1.2 区间交叉
已知两个日期区间存在交叉 ['2024-01-01', '2024-01-03'] 、 ['2024-01-02', '2024-01-04']。问:
1)如何合并两个日期区间,并返回合并后的新区间?
2)如何知道哪些日期是交叉日期,并返回该日期交叉次数?
解决上述问题的方法有多种,此处介绍其中一种简单且通用的方案。核心思路是结合数列生成、区间分割方法,先将日期区间分解为最小处理单元,即多个日期组成的数列,然后再基于日期粒度做统计。具体步骤如下:
1)获取每个日期区间包含的天数;2)按日期区间包含的天数,将日期区间拆分为相应数量的递增日期序列;
3)通过日期序列统计合并后的区间,交叉次数。
SQL 实现:
-- SQL - 8
with dummy_table as (
select stack(
2,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期计数
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的单个日期
date_add(date_start, pos) as date_item,
-- 拆解后的单个日期出现的次数
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t;| date_start_merged | date_end_merged | overlap_date |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
增加点儿难度!
如果有多个日期区间,且区间之间交叉状态未知,上述问题又该如何求解。即:
1)如何合并多个日期区间,并返回合并后的多个新区间?
2)如何知道哪些日期是交叉日期,并返回该日期交叉次数?
SQL 实现:
-- SQL - 9
with dummy_table as (
select stack(
5,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04',
'2024-01-06', '2024-01-08',
'2024-01-08', '2024-01-08',
'2024-01-07', '2024-01-10'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期计数
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的单个日期
date_add(date_start, pos) as date_item,
-- 拆解后的单个日期出现的次数
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt,
-- 对于拆解后的单个日期,重组为新区间的标记
date_add(date_add(date_start, pos), 1 - dense_rank() over (order by date_add(date_start, pos))) as cont
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
group by cont;| date_start_merged | date_end_merged | overlap_date |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
| 2024-01-06 | 2024-01-10 | ["2024-01-07:2","2024-01-08:3"] |
3.2 应用场景举例
3.2.1 按任意时段统计数据
场景描述
现有用户还款计划表 user_repayment ,该表内的一条数据,表示用户在指定日期区间内 [date_start, date_end] ,每天还款 repayment 元。
-- SQL - 10
with user_repayment as (
select stack(
3,
'101', '2024-01-01', '2024-01-15', 10,
'102', '2024-01-05', '2024-01-20', 20,
'103', '2024-01-10', '2024-01-25', 30
)
-- 字段:用户,开始日期,结束日期,每日还款金额
as (user_id, date_start, date_end, repayment)
)
select * from user_repayment;如何统计任意时段内(如:2024-01-15至2024-01-16)每天所有用户的应还款总额?
解决思路
核心思路是将日期区间转换为日期序列,再按日期序列进行汇总统计。
SQL 实现
-- SQL - 11
select
date_item as day,
sum(repayment) as total_repayment
from (
select
date_add(date_start, pos) as date_item,
repayment
from user_repayment
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
where date_item >= '2024-01-15' and date_item <= '2024-01-16'
group by date_item
order by date_item;| day | total_repayment |
| 2024-01-15 | 60 |
| 2024-01-16 | 50 |
四、排列组合
排列组合是针对离散数据常用的数据组织方法,本节将分别介绍排列、组合的实现方法,并结合实例着重介绍通过组合对数据的处理。
4.1 常见排列组合操作
4.1.1 排列
已知字符序列 [ 'A', 'B', 'C' ] ,每次从该序列中可重复地选取出 2 个字符,如何获取到所有的排列?
借助多重 lateral view 即可解决,整体实现比较简单。
-- SQL - 12
select
concat(val1, val2) as perm
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2;| perm |
| AA |
| AB |
| AC |
| BA |
| BB |
| BC |
| CA |
| CB |
| CC |
4.1.2 组合
已知字符序列 [ 'A', 'B', 'C' ] ,每次从该序列中可重复地选取出 2 个字符,如何获取到所有的组合?
借助多重 lateral view 即可解决,整体实现比较简单。
-- SQL - 13
select
concat(least(val1, val2), greatest(val1, val2)) as comb
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2
group by least(val1, val2), greatest(val1, val2);| comb |
| AA |
| AB |
| AC |
| BB |
| BC |
| CC |
提示:亦可直接使用 MaxCompute(ODPS)系统函数 combinations 快速生成组合。
-- SQL - 14
select combinations(array('foo', 'bar', 'boo'),2);
-- result
[['foo', 'bar'], ['foo', 'boo']['bar', 'boo']]4.2 应用场景举例
4.2.1 分组对比统计
场景描述
现有投放策略转化表,该表内的一条数据,表示一天内某投放策略带来的订单量。
-- SQL - 15
with strategy_order as (
select stack(
3,
'2024-01-01', 'Strategy A', 10,
'2024-01-01', 'Strategy B', 20,
'2024-01-01', 'Strategy C', 30
)
-- 字段:日期,投放策略,单量
as (dt, strategy, order_cnt)
)
select * from strategy_order;如何按投放策略建立两两对比组,按组对比展示不同策略转化单量情况?
| 对比组 | 投放策略 | 转化单量 |
| Strategy A-Strategy B | Strategy A | xxx |
| Strategy A-Strategy B | Strategy B | xxx |
解决思路
核心思路是从所有投放策略列表中不重复地取出 2 个策略,生成所有的组合结果,然后关联 strategy_order 表分组统计结果。
SQL 实现
-- SQL - 16
select /*+ mapjoin(combs) */
combs.strategy_comb,
so.strategy,
so.order_cnt
from strategy_order so
join ( -- 生成所有对比组
select
concat(least(val1, val2), '-', greatest(val1, val2)) as strategy_comb,
least(val1, val2) as strategy_1, greatest(val1, val2) as strategy_2
from (
select collect_set(strategy) as strategies
from strategy_order
) dummy
lateral view explode(strategies) t1 as val1
lateral view explode(strategies) t2 as val2
where val1 <> val2
group by least(val1, val2), greatest(val1, val2)
) combs on 1 = 1
where so.strategy in (combs.strategy_1, combs.strategy_2)
order by combs.strategy_comb, so.strategy;| 对比组 | 投放策略 | 转化单量 |
| Strategy A-Strategy B | Strategy A | 10 |
| Strategy A-Strategy B | Strategy B | 20 |
| Strategy A-Strategy C | Strategy A | 10 |
| Strategy A-Strategy C | Strategy C | 30 |
| Strategy B-Strategy C | Strategy B | 20 |
| Strategy B-Strategy C | Strategy C | 30 |
五、连续
本节主要介绍连续性问题,重点描述了常见连续活跃场景。对于静态类型的连续活跃、动态类型的连续活跃,分别阐述了不同的实现方案。
5.1 普通连续活跃统计
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 17
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;如何获取连续访问大于或等于 2 天的用户?
上述问题在分析连续性时,获取连续性的结果以超过固定阈值为准,此处归类为 连续活跃大于 N 天阈值的普通连续活跃场景统计。
SQL 实现
基于相邻日期差实现( lag / lead 版)
整体实现比较简单。
-- SQL - 18
select user_id
from (
select
*,
lag(dt, 2 - 1) over (partition by user_id order by dt) as lag_dt
from (select dt, user_id from visit_log group by dt, user_id) t0
) t1
where datediff(dt, lag_dt) + 1 = 2
group by user_id;| user_id |
| 101 |
| 102 |
基于相邻日期差实现(排序版)
整体实现比较简单。
-- SQL - 19
select user_id
from (
select *,
dense_rank() over (partition by user_id order by dt) as dr
from visit_log
) t1
where datediff(dt, date_add(dt, 1 - dr)) + 1 = 2
group by user_id;| user_id |
| 101 |
| 102 |
基于连续活跃天数实现
可以视作 基于相邻日期差实现(排序版) 的衍生版本,该实现能获取到更多信息,如连续活跃天数。
-- SQL - 20
select user_id
from (
select
*,
-- 连续活跃天数
count(distinct dt)
over (partition by user_id, cont) as cont_days
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
) t2
where cont_days >= 2
group by user_id;| user_id |
| 101 |
| 102 |
基于连续活跃区间实现
可以视作 基于相邻日期差实现(排序版) 的衍生版本,该实现能获取到更多信息,如连续活跃区间。
-- SQL - 21
select user_id
from (
select
user_id, cont,
-- 连续活跃区间
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
) t2
where datediff(cont_date_end, cont_date_start) + 1 >= 2
group by user_id;| user_id |
| 101 |
| 102 |
5.2 动态连续活跃统计
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 22
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;如何获取最长的 2 个连续活跃用户,输出用户、最长连续活跃天数、最长连续活跃日期区间?
上述问题在分析连续性时,获取连续性的结果不是且无法与固定的阈值作比较,而是各自以最长连续活跃作为动态阈值,此处归类为 动态连续活跃场景统计。
SQL 实现
基于 普通连续活跃场景统计 的思路进行扩展即可,此处直接给出最终 SQL :
-- SQL - 23
select
user_id,
-- 最长连续活跃天数
datediff(max(dt), min(dt)) + 1 as cont_days,
-- 最长连续活跃日期区间
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
order by cont_days desc
limit 2;本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java