
详解TextBrewer
TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包,
融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的知识蒸馏框架,用于以较低的性能损失压缩神经网络模型的大小,提升模型的推理速度,减少内存占用。
1.简介
TextBrewer 为NLP中的知识蒸馏任务设计,融合了多种知识蒸馏技术,提供方便快捷的知识蒸馏框架。
主要特点:
- 模型无关:适用于多种模型结构(主要面向Transfomer结构)
- 方便灵活:可自由组合多种蒸馏方法;可方便增加自定义损失等模块
- 非侵入式:无需对教师与学生模型本身结构进行修改
- 支持典型的NLP任务:文本分类、阅读理解、序列标注等
TextBrewer目前支持的知识蒸馏技术有:
- 软标签与硬标签混合训练
- 动态损失权重调整与蒸馏温度调整
- 多种蒸馏损失函数: hidden states MSE, attention-based loss, neuron selectivity transfer, …
- 任意构建中间层特征匹配方案
- 多教师知识蒸馏
- …
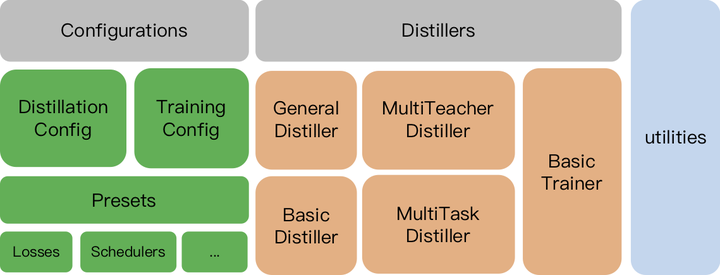
TextBrewer的主要功能与模块分为3块:
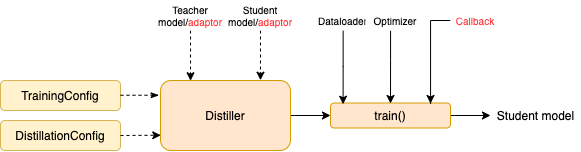
- Distillers:进行蒸馏的核心部件,不同的distiller提供不同的蒸馏模式。目前包含GeneralDistiller, MultiTeacherDistiller, MultiTaskDistiller等
- Configurations and Presets:训练与蒸馏方法的配置,并提供预定义的蒸馏策略以及多种知识蒸馏损失函数
- Utilities:模型参数分析显示等辅助工具
用户需要准备:
- 已训练好的教师模型, 待蒸馏的学生模型
- 训练数据与必要的实验配置, 即可开始蒸馏
在多个典型NLP任务上,TextBrewer都能取得较好的压缩效果。相关实验见蒸馏效果。
2.TextBrewer结构
2.1 安装要求
- Python >= 3.6
- PyTorch >= 1.1.0
- TensorboardX or Tensorboard
- NumPy
- tqdm
- Transformers >= 2.0 (可选, Transformer相关示例需要用到)
- Apex == 0.1.0 (可选,用于混合精度训练)
- 从PyPI自动下载安装包安装:
pip install textbrewer- 从源码文件夹安装:
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer2.2工作流程
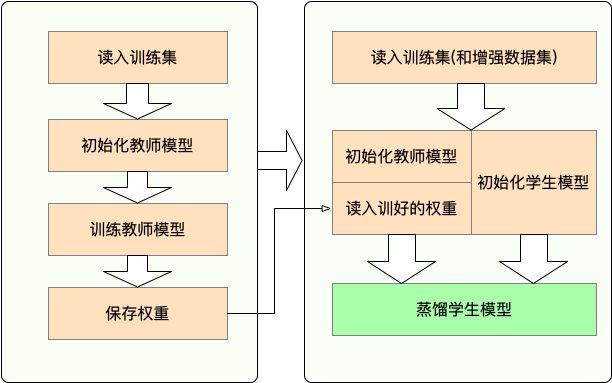
- Stage 1 : 蒸馏之前的准备工作:
- 训练教师模型
- 定义与初始化学生模型(随机初始化,或载入预训练权重)
- 构造蒸馏用数据集的dataloader,训练学生模型用的optimizer和learning rate scheduler
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java