
一种 DSL to SQL 的技术实现
引言
随着 ChatGPT 给几乎所有技术都带来新冲击和新机会,让我们不禁思考,在 BI 场景下「用户直接使用自然语言完成数据查询」的可行性。
如果要完成这个需求,则一定需要一种中间表达串联自然语言和结果数据,对于这种中间表达大家的瞬间决策可能都会选择 SQL。在文章《Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs》中,作者团队观察了 500 个随机抽样的 Text -> SQL 错误案例,提供了四类错误的详细评估:
Wrong Schema Linking (41.6%) pertains to the scenario where ChatGPT can accurately comprehend the structure of the database, but erroneously associates it with inappropriate columns and tables.
Misunderstanding Database Content (40.8%) occurs when ChatGPT either fails to recall the correct database structure (e.g., rtype doesn’t belong to the satscores table) or generates fake schema items (e.g., lap_records is not appearing in the database).
Misunderstanding Knowledge Evidence (17.6%) refers to cases in which ChatGPT does not accurately interpret human-annotated evidence. An instance is that ChatGPT directly copies the formula DIVIDE(SUM(spent), COUNT(spent)) without considering SQL syntax.
The final groups of error cases are *Syntax Error* (3.0%) with a small portion, suggesting that the ChatGPT is well-performed zero-shot semantic parser. However, we observe that ChatGPT occasionally employs incorrect keywords (e.g., misusing the MySQL Year() function instead of an SQLite function STRFTIME() or exhibits decoding errors (e.g., SELECT7)).
由于 SQL 本身较为复杂且标准较多(一条 MySQL 的查询 SQL 放到 PostgreSQL 可能就会查询失败),ChatGPT 出现幻觉的确不是一个特别好解决的问题。因此本实现方案中我们采用了 Text -> DSL -> SQL -> Data 的实现路径,在 Text 和 SQL 之间架一层半结构化的 DSL 表达,其作用有:
- DSL 不绑定特定的 SQL 数据库方言,ChatGPT 直接按照 DSL 脚本的规则输出 DSL 即可,而无需关系底层数据库是 MySQL 还是 Impala。适配每种数据库方案的事情就可以和 ChatGPT 解耦,完全托付给 DSL 背后的相关逻辑即可。(Syntax Error)
- DSL 脚本与 SQL 相比可以更加的「柔软」。DSL 中声明 DIVIDE(SUM(spent), COUNT(spent)) 表达式可以被正确的转换为 SUM(spent) / COUNT(spent)而不是直接报错;判断值相当的操作声明 EQUAL 还是 EQUALS 也都是被允许的。基于 SQL 想要达成一样的效果就要困难很多。(**Misunderstanding Knowledge Evidence**)
- 使用 DSL 对于信息错误声明的情况也可以有更好的表现。比如声明了一个不存在表中的字段,DSL 可以直接以 Promot 的方式反馈给 ChatGPT,方便在没有用户参与的情况下,ChatGPT 直接给出一份正确的答案(之前给出的一次错误答案用户是无感知的)。(**Misunderstanding Database Content**)
除了上述优点外,我们选择在 Text 和 SQL 之间架一层半结构化的 DSL 表达更多的原因如下:
- SQL 过于灵活,服务端无法很好的控制客户端的行为,而如果控制不当的话可能导致数据安全问题。
- DSL 整体更偏结构化设计,相比于 SQL 而言,没有编程背景的用户更容易理解和使用。
- 数据分析的场景相对有限,因此可接受有限的 DSL 表达能力,不纠结于图灵完备性。
- 结合当前灯塔的产品矩阵,DSL 的存在可以改变功能实现环境,将部分功能逻辑从编译时切换到运行时,同时收敛「拼 SQL」的场景(DSL 既可以支持统一数据管家的片段 SQL 场景,还可以支持 DataTalk 的完整、独立 SQL 场景)。
综上,DSL 更贴合当下我们的需求场景。为了更好的表述,后面涉及到我们这里的 DSL,都使用 SimpliQL 代替。
概述
SimpliQL 是一种用于描述 SQL 数据库中 Dimension、Metric、Calculations 和 Data Relations 的语言,同时 MixQuery 可以直接使用 SimpliQL 构造特定的数据库 SQL,以实现数据查询。
SimpliQL 示例
如下 SimpliQL 脚本描述了一个「查询 2023 五月一日每个城市的 APP 在线总时长」的数据查询需求。
datasource:
name: demo_datasource
tableType: IMPALA
connId: demo_cluster
table:
name: demo_table
type: table
ref: t
metrics:
- name: 在线总时长
type: column
ref: a + b
operator: sum
dimensions:
- name: 城市
type: column
ref: c
filters:
- name: f1
type: column
ref: ds
operator: equals
valueType: literal
value: 20230501这里可以先简单的感受下其对应的 SQL 表达,后续我们会详细阐述 SimpliQL 脚本是如何一步一步构成如下 SQL 的。
select `c` as `城市`, sum(`a + b`) as `在线总时长`
from `t`
where `ds` = '20230501'
group by `c`SimpliQL 主要结构
Datasource & Table
Datasource 声明了一个连接数据库的方式。
熟悉灯塔数据平台的同学应该都知道,在使用 BI 平台之前一定先要在数据管家注册数据资源,而注册数据资源的第一步,就是配置一份数据连接(通过数据库 ip、port、账号密码等)。而 Datasource 中的 connId 所配置的内容,就是用户在配置数据连接时所生成的唯一 ID。
Table 则泛指一张数据表,亦可对应于数据管家中的数据资源。
在 Table 的声明模块中,使用 type 字段声明依赖的是一张表而不是一个视图;使用 ref 字段声明可以唯一定位一张表的标识。
Metric
用于声明查询的指标。
在 Metric 的声明模块中,使用 type 字段声明聚合计算依赖的是一个字段;使用 ref 字段声明字段的唯一标识,同时对于聚合计算所使用字段,还支持虚拟列,比如在计算总耗时类指标时,可能在底表没有直接存储耗时字段,而是需要通过 end_time - start_time 计算得到。
Operator 用于声明支持数据表字段的聚合计算(原子指标),如 sum、count、max 等,同时 operator 也支持配置成多个聚合计算的二次运算表达式(复合指标),比如在计算人均类指标时,其复合指标表达式为总值 / 人数。
Dimension
用于声明查询的分组维度,同时也支持虚拟列,其声明块的每个元素含义与 Metric 声明块相同。
Filter
用于声明数据的过滤条件,支持条件嵌套,其声明块的每个元素含义与 Metric 声明块相同。。
DSL to SQL 的技术实现
读到这里,大家应该已经了解了什么是 SimpliQL,以及为什么要使用 SimpliQL 来表达用户查询数据的意图。 现在来主要介绍通过 SimpliQL 构建不同引擎的 SQL 表达过程中我们所使用的主要技术。
DSL 处理结构
我们使用大体的 DSL 处理结构如下:通过「三层表达、两次转换」实现 DSL to SQL 的转换能力。
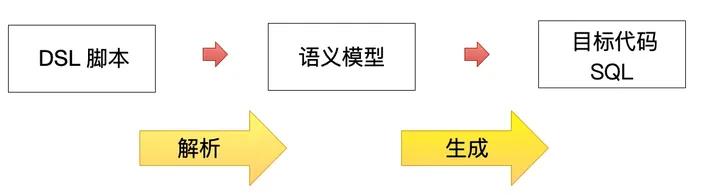
语义模型指的是 DSL 所描述主题的一种表示形式(如内存中的对象模型),是由 DSL 组装的库和框架。若以状态机为例,那么语义模型可能是由状态、时间、触发机制等类组成的对象模型了。
代码生成的目标就是生成符合各类数据库方言的 SQL,以用于数据库查询。
使用这种 DSL 处理架构有几个好处。最主要的好处是,我们可以保证 DSL、语义模型和代码生成三个核心模块的独立演进。
如果需要改变语义模型,可以不更改 DSL,而只需要在语义模型能够正常工作之后给 DSL 加上必要的构造;同理,如果需要尝试迭代新的 DSL 语法,那么只需要验证这些新的语法在语义模型中可以创建相同对象。
同样的,在这种层次剥离的设计中,我们还可以选择 DSL 与语义模型的薄厚,两个极端的例子分别是:
1、DSL 作为语义模型之上的一个薄层、一种处理抽象的简单声明方式,这里甚至可以把 DSL 当做是「用户界面」的另一种表现形式。
2、弱化语义模型,甚至是无视语义模型,比如手工编写输出文件来生成输出,并在文件中查询标注来生成可变的部分。
DSL 解析
接下来,我们来重点介绍一下 DSL 到语义模型的转换功能的实现机制,主要包含两个流程,首先是将 DSL 通过文法分析得到为一个一个的 Token,然后再将解析得到的每个 Token 组装成语义模型所希望的表示形式。
文法分析
我们 DSL 的解析目前是半结构化的解析:
1、使用 yaml 来描述一个查询最基本的要素: 维度,指标,过滤条件等。 2、使用自然语义和 sql 片段来描述复杂计算的逻辑。
其中复杂计算我们采用的文法分析的方式,
文法(Grammar)是语言学的一个重要分支,用于研究语言如何运作和组织的规则系统,它描述了一种自然语言中单词、短语和句子的构成方式和结构。
一条加法文法可能看起来是这样的:add = number '+' number,5 + 3 就是符合这个加法文法的一个具体的实例。文法分析的目的就是可以识别 5 + 3 ,并判断这是一条加法语句,参与加法运算的两个元素分别是 5 和 3。
复合指标的定义是基于原子指标的二次运算,因此在我们的 DSL 中,也会存在类似于如下定义,用于声明平均在线时长指标的定义。
metrics:
- name: 在线时长
type: column
ref: a + b
operator: sum
- name: 日活
type: column
ref: uid
operator: count
evict: true
- name: 平均在线时长
type: expression
ref: m1 / m2JavaCC 是一个代码生成器,它的作用就是生成在语法解析过程中非常重要的词法分析器和语法分析器。它主要通过模板文件(例如.jj 文件)来生成一些 Java 程序,我们正是利用其中的词法分析器来完成对上述复合指标表达式的词法解析的。
JJ 文件示例
我们通过如下的 jj 文件,定义了解析中的所有关键字,并在后续的编码中将「REFERENCE」关键字所关联的内容组装成了文法解析的目标对象,即抽象语法树 AST。
SKIP: { <[" ","\t","\r","\n"]> }
TOKEN [IGNORE_CASE]: {
<LPAREN: "(">
| <RPAREN: ")">
| <AND: "AND">
| <OR: "OR">
| <PLUS: "+">
| <MINUS: "-">
| <MULTIPLY: "*">
| <DIVIDE: "/">
}
TOKEN [IGNORE_CASE]: {
<REFERENCE: (~[" ", "\t", "\n", "\r", "(", ")", "+", "-", "*", "/"])+ >
}在使用词法解析器对复合指标计算m1 / m2表达式解析完成后,我们便可以获知复合指标表达式中的各类元素以及每个元素所对应的类型(操作符、分割符、计算单元等)。

同时,我们在词法解析的时候也考虑了嵌套的模式。比如我们考虑一个 where 谓词的表达式,如 'a and b or (c and d) or e'。 其中 c and d 就属于一个子表达式, 所以我们在设计 AST 的时候添加了一个子表达式的类型。
但是工作尚未完成,我们注意到在复合指标的定义中,表达式中的元素并不是原子指标的完整定义,而只是一个引用,也就是说,指标中的元素存在「在一个地方被定义,在另一个地方被引用」的情况,当元素被引用时,它所在的 AST 和它被定义的 AST 分支是不同的。如果语法树的表示只存在于调用栈中,那么这时命令的定义已经消失了。为了解决这个问题,我们为 DSL 中每一个元素都定义了某种形式的唯一标识符号,并在处理 DSL 时,我们把这些符号放在一个符号表中。符号表中存储了符号与底层对象之间的链接,而底层对象中保存了完整的信息。
至此,我们就完成了所有对 DSL 的文法分析工作。但是文法只定义了一门语言的语法,它并没有告诉我们它的语义,也就是表达式的含义。在不同的上下文中,5 + 3 可能等于 8,也可能等于 53,语法相同但是语义可能截然不同,而这就是语义模型的作用,接下来我们来介绍语义模型。
语义模型
在 DSL 处理架构中可以看到,语义模型向上需要承接 DSL 的表达,向下需要生成目标代码。在我们的场景下,所需要生成的目标代码就是可以在各式各样数据库和查询引擎中可执行的 SQL 了。
Calcite 是一个开源的基于 Java 平台的 SQL 解析器和查询优化器,其提供了一套通用的框架,可以将 SQL 语句转换为执行计划,并对查询进行优化后再输出 SQL,从而提高查询性能和效率。并且它天然的还支持了很多类型的数据源(MySQL、Hive 等)、也在一程度上抹平了部分 SQL 表达的差异性,这对于我们的场景,简直是解决问题的利器!
我们先简化下示例 SQL,先移除其关于过滤条件的声明部分,然后再辅以其在 Calcite 中的查询计划作为图示,介绍下 Calcite 中的关键概念以及这些关键概念是如何与 DSL 中的核心元素完成对应和转换的。
datasource:
name: demo_datasource
tableType: IMPALA
connId: demo_cluster
table:
name: demo_table
type: table
ref: t
metrics:
- name: 在线总时长
type: column
ref: a + b
operator: sum
dimensions:
- name: 城市
type: column
ref: c
TableScan
在 Calcite 中,TableScan 代表了数据源,其数据的物理组织形式可以是关系表、csv 文件、HTTP 接口。
TableScan 对应 DSL 脚本中的 datasource 和 table 两部分。在构造 TableScan 对象时,首先会使用 datasource 和 table 中的数据源连接、数据库、数据表唯一定位一张存储在数据库/查询引擎中的物理表,随后会将表内的所有列信息存储起来,用于做维度和指标计算,下图中的 a、b、c 就是 t 表中三个字段列名。
datasource:
name: demo_datasource
tableType: IMPALA
connId: demo_cluster
table:
name: demo_table
type: table
ref: tProject
Project 代表了一种投影操作,定义了产生新元组的表达式。
由于在维度和指标定义中分别使用了 c 列和 a+b 列,因此图中 TableScan 上层的 Project 定义了两个投影操作。
metrics:
- name: 在线总时长
type: column
ref: a + b
operator: sum
dimensions:
- name: 城市
type: column
ref: c其中,a + b 将会转换为如下的 Calcite 中的关系表达式对象,也就是说,+ 对应了 RexCall{+} 这个关系表达式对象,而 RexCall {+} 下面挂了 RexInputRef {a}和 RexInputRef {b} 这两个关系表达式对象。
图中 RexInputRef 中对应的 和
1 使用的是数据的字段索引而不是名称:代表;
1 代表 b。
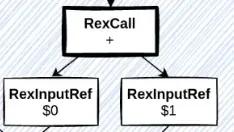
解释一下这里用到的两种关系表达式的类型:
RexInputRef,其代表对一个输入的引用。RexCall,其代表一个或多个输入的函数转换。
Aggregate
在看完了 TableScan 和第一次的 Project 运算之后,我们最后再来看一下 Aggregate 运算。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java