
Java 实现分页列表缓存的3种方式
1 直接缓存分页列表结果
显而易见,这是最简单易懂的方式。
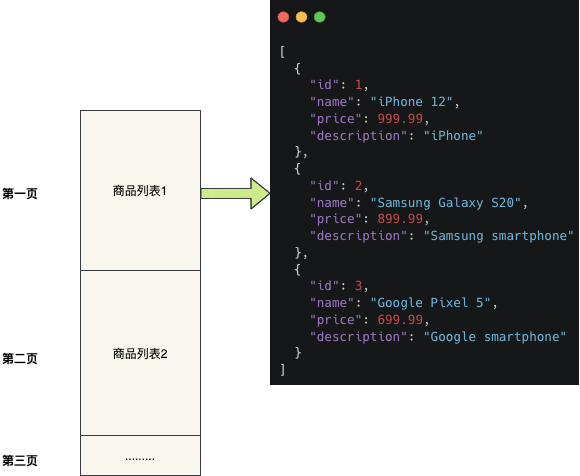
我们按照不同的分页条件来缓存分页结果 ,伪代码如下:
public List<Product> getPageList(String param,int page,int size) {
String key = "productList:page:" + page + ”size:“ + size +
"param:" + param ;
List<Product> dataList = cacheUtils.get(key);
if(dataList != null) {
return dataList;
}
dataList = queryFromDataBase(param,page,size);
if(dataList != null) {
cacheUtils.set(key , dataList , Constants.ExpireTime);
}
} 这种方案的优点是工程简单,性能也快,但是有一个非常明显的缺陷基因:列表缓存的颗粒度非常大。
假如列表中数据发生增删,为了保证数据的一致性,需要修改分页列表缓存。
有两种方式 :
1、依靠缓存过期来惰性的实现 ,但业务场景必须包容;
2、使用 Redis 的 keys 找到该业务的分页缓存,执行删除指令。 但 keys 命令对性能影响很大,会导致 Redis 很大的延迟 。
生产环境使用 keys 命令比较危险,发生事故的几率高,非常不推荐使用。
2 查询对象ID列表,再缓存每个对象条目
缓存分页结果虽然好用,但缓存的颗粒度太大,保证数据一致性比较麻烦。
所以我们的目标是更细粒度的控制缓存 。

我们查询出商品分页对象ID列表,然后为每一个商品对象创建缓存 , 通过商品ID和商品对象缓存聚合成列表返回给前端。
伪代码如下:

核心流程:
1、从数据库中查询分页 ID 列表
// 从数据库中查询分页商品 ID 列表
List<Long> productIdList = queryProductIdListFromDabaBase(
param,
page,
size);对应的 SQL 类似:
SELECT id FROM products
ORDER BY id
LIMIT (page - 1) * size , size 2、批量从缓存中获取商品对象
Map<Long, Product> cachedProductMap = cacheUtils.mget(productIdList);假如我们使用本地缓存,直接一条一条从本地缓存中聚合也极快。
假如我们使用分布式缓存,Redis 天然支持批量查询的命令 ,比如 mget ,hmget 。
3、组装没有命中的商品ID
List<Long> noHitIdList = new ArrayList<>(cachedProductMap.size());
for (Long productId : productIdList) {
if (!cachedProductMap.containsKey(productId)) {
noHitIdList.add(productId);
}
}因为缓存中可能因为过期或者其他原因导致缓存没有命中的情况,所以我们需要找到哪些商品没有在缓存里。
4、批量从数据库查询未命中的商品信息列表,重新加载到缓存
首先从数据库里批量查询出未命中的商品信息列表 ,请注意是批量。
List<Product> noHitProductList = batchQuery(noHitIdList);参数是未命中缓存的商品ID列表,组装成对应的 SQL,这样性能更快 :
SELECT * FROM products WHERE id IN
(1,
2,
3,
4);然后这些未命中的商品信息存储到缓存里 , 使用 Redis 的 mset 命令。
//将没有命中的商品加入到缓存里
Map<Long, Product> noHitProductMap =
noHitProductList.stream()
.collect(
Collectors.toMap(Product::getId, Function.identity())
);
cacheUtils.mset(noHitProductMap);
//将没有命中的商品加入到聚合map里
cachedProductMap.putAll(noHitProductMap);5、 遍历商品ID列表,组装对象列表
for (Long productId : productIdList) {
Product product = cachedProductMap.get(productId);
if (product != null) {
result.add(product);
}
}当前方案里,缓存都有命中的情况下,经过两次网络 IO ,第一次数据库查询 IO ,第二次 Redis 查询 IO , 性能都会比较好。
所有的操作都是批量操作,就算有缓存没有命中的情况,整体速度也较快。
”查询对象ID列表,再缓存每个对象条目“ 这个方案比较灵活,当我们查询对象ID列表,可以不限于数据库,还可以是搜索引擎,Redis 等等。
下图是开源中国的搜索流程:
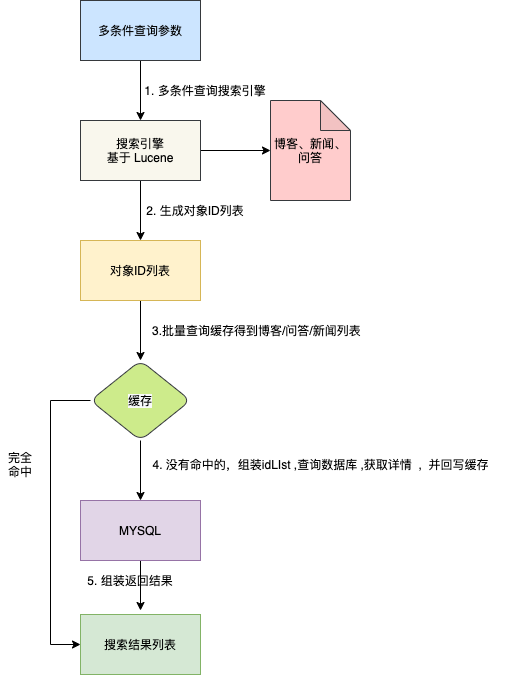
精髓在于:搜索的分页结果只包含业务对象 ID ,对象的详细资料需要从缓存 + MySQL 中获取。
3 缓存对象ID列表,同时缓存每个对象条目
笔者曾经重构过类似朋友圈的服务,进入班级页面 ,瀑布流的形式展示班级成员的所有动态。
我们使用推模式将每一条动态 ID 存储在 Redis ZSet 数据结构中 。Redis ZSet 是一种类型为有序集合的数据结构,它由多个有序的唯一的字符串元素组成,每个元素都关联着一个浮点数分值。
ZSet 使用的是 member -> score 结构 :
- member : 被排序的标识,也是默认的第二排序维度( score 相同时,Redis 以 member 的字典序排列)
- score : 被排序的分值,存储类型是 double
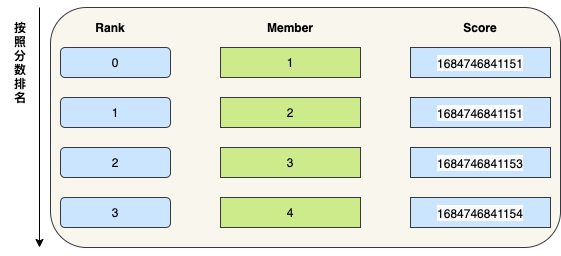
如上图所示:ZSet 存储动态 ID 列表 , member 的值是动态编号 , score 值是创建时间。
通过 ZSet 的 ZREVRANGE 命令就可以实现分页的效果。
ZREVRANGE 是 Redis 中用于有序集合(sorted set)的命令之一,它用于按照成员的分数从大到小返回有序集合中的指定范围的成员。

为了达到分页的效果,传递如下的分页参数 :
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java