
谈谈 JAVA 19 有哪些新特性
2023年了,谈谈 JAVA 19 有哪些新特性。
一、JDK19最新更新
谈到Java最新技术,那么一定会谈到JAVA 19,这一小节,我们先来看下JAVA 19有哪些更新。

从openJDK看出,JAVA 19主要有以上截图中的特性,我们来一一了解一下。
1.1 记录模式 (预览)
如果不经常关注JDK更新的朋友肯定对记录模式很陌生,甚至都没听过,其实记录模式非常好用。官方的解释是这样的:“记录模式由一个类型、一个可能为空的记录组件模式列表(用于匹配相应的记录组件)和一个可选标识符组成,带有标识符的记录模式称为命名记录模式,变量称为记录模式变量。”
对于新手来说,不加以白话文的解释是看不懂的。我们直接上代码,用代码给大家作解释:
record Test(int a, int b) {}形如以上代码的就是记录模式。
record是一种新类型,本质上是一个final类,在修改所有属性的同时加final,会自动编译public get hashcode、equals、toString方法,这样减少了代码量。record在Java 14中被提出,在Java 15中进入预览阶段,并在Java 16中发布。
我们编写一个Drone类,定义sn、brand、name:
package com.wljslmz;
public record Drone(String sn, String brand, String name) {
}record的使用:
package com.wljslmz;
public class RecordTest {
public static void main(String[] args) {
Drone drone1 = new Drone("0a9f55785ebc4c52", "DJI", "M30无人机");
Drone drone2 = new Drone("7400f6c1c5644c6e", "DJI", "精灵4无人机");
System.out.println(drone1);
System.out.println(drone2);
}
}输出结果:
Drone[sn=0a9f55785ebc4c52, brand=DJI, name=M30无人机]
Drone[sn=field 7400f6c1c5644c6e, brand=DJI, name=精灵4无人机]在Java 19中,模式匹配被引入record中,这样的话就可以使用instanceof:
package com.wljslmz;
public class RecordTest {
public static void main(String[] args) {
Drone drone1 = new Drone("0a9f55785ebc4c52", "DJI", "M30无人机");
if(drone1 instanceof Drone droneType){
System.out.println(drone1.sn());
}
Drone drone2 = new Drone("7400f6c1c5644c6e", "DJI", "精灵4无人机");
if(drone2 instanceof Drone(String sn, String brand, String name)){
System.out.println("无人机2的序列号为:"+sn+",厂商为:"+brand+",名称为:"+name);
}
}
}输出结果:
0a9f55785ebc4c52
无人机2的序列号为:7400f6c1c5644c6e,厂商为:DJI,名称为:精灵4无人机1.2 虚拟线程(预览)
在讲虚拟线程前,给大家稍微普及一下线程的知识。
研究过Java虚拟机的朋友都知道,线程一直是Java并发编程中非常重要的一部分。Thread是Java中的并发单元,每个Thread线程都提供了一个栈来存储局部变量和方法调用,以及关于线程上下文的信息。Java线程和系统内核线程是一一对应的,Java线程是由系统内核线程调度的,所以到并发场景中,我们第一个想到的是增加线程数目去提高系统的性能。
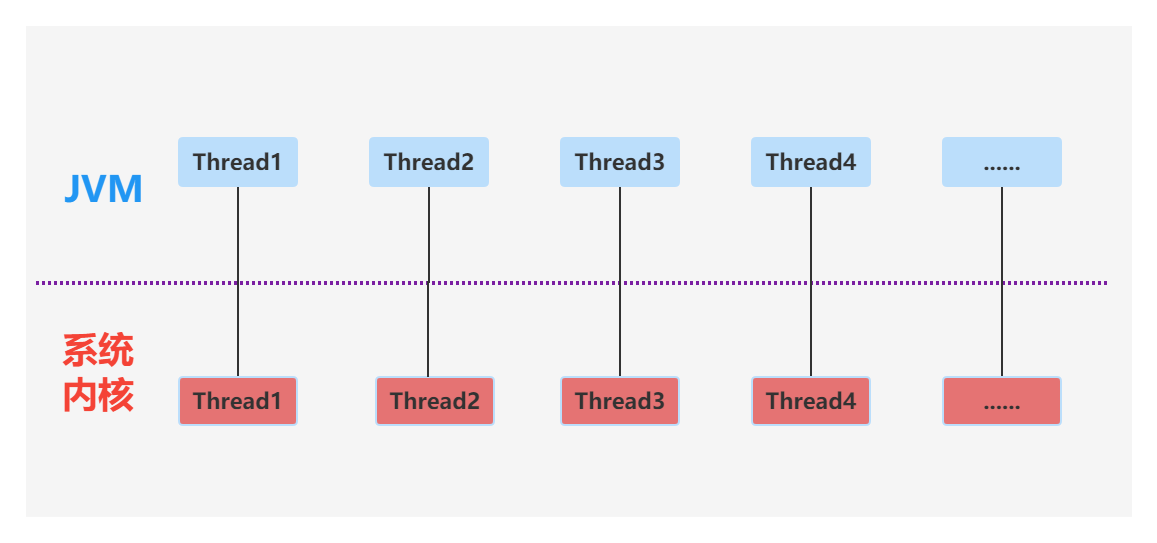
多线程模型能不能解决并发中绝大多数问题?
答案肯定是:能!但是可取吗?
小型的并发场景可取,但是并发数很大的场景就不可取了。线程的数目当然是越多,越能提高系统的性能,但是这个带来的直接后果就是成本增加,上面我们说过了,Java的线程是由系统内核直接调用的,那么也就意味着,多线程需要在物理上增加机器,试想一下,这种成本代价得多高?
那有人肯定说了,不是还有线程池吗?
不错,线程池确实能提高并发场景下系统的性能,但是,请注意,线程池只是帮助你如何更好的管理线程、利用线程,本身不会凭空给你创造出线程来,最终工作的还是底层的内核线程。而且线程池往往会受限于CPU、网络、内存等,所以从硬件的角度来看,并没有解决实际问题。
因此,Java19引入了虚拟线程。
我们来看下虚拟线程的模型是什么样的:
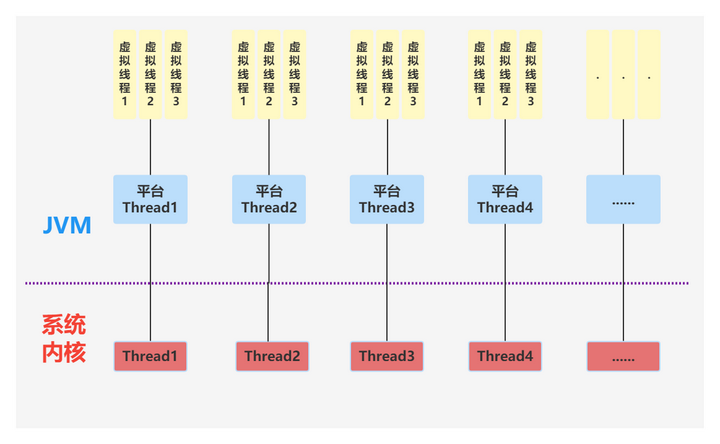
多线程模型中的线程在虚拟线程模型中被称为平台线程,一个平台线程对应多个虚拟线程,最终其实也是由内核线程去驱动。
在体验上虚拟线程与Threads没有区别,并且兼容之前的API,但相比而言它们占用的资源非常少,并且优化了硬件使用效率。
package com.wljslmz.demo;
import Java.util.concurrent.ExecutorService;
import Java.util.stream.IntStream;
import static Java.util.concurrent.Executors.*;
/**
* @author: wangrui
* @date: 2022/10/18 15:12
* @description: 虚拟线程测试
*/
public class VirtualThreadTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
try (ExecutorService executor = newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 1000000).forEach(index -> {
executor.submit(() -> {
Thread.sleep(1000);
return index;
});
});
System.out.println("执行消耗时间:" + (System.currentTimeMillis() - start) + "毫秒");
}
}
}执行结果:
执行消耗时间:8550毫秒代码中我们创建了100万个线程,每个线程睡眠1秒钟,完成这个操作最终只花了8秒多,假如我们使用的是普通线程去处理或者线程池去处理,那么这个速度能差异到多少呢?
我们稍微改动一下代码:
long start = System.currentTimeMillis();
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 1000000; i++) {
executor.submit(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
System.out.println("执行消耗时间:" + (System.currentTimeMillis() - start) + "毫秒");最后执行的时间:
执行消耗时间:13459毫秒差距是不是也不是很大,确实是的,因为虚拟线程只会增加程序的吞吐量,不会增加程序的处理速度。
1.3 Vector API
Vector API最初在Java 16中被引入,Java 19带来了它的第四次迭代。简单来说Vector API可以加速矢量计算,在数学计算领域非常有用。
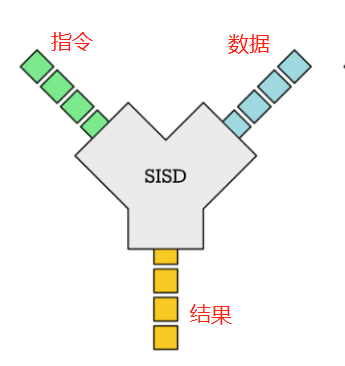
在传统计算中,数据的处理都是一个一个处理的,这种操作被称为“SISD”,即“单指令,单数据”:
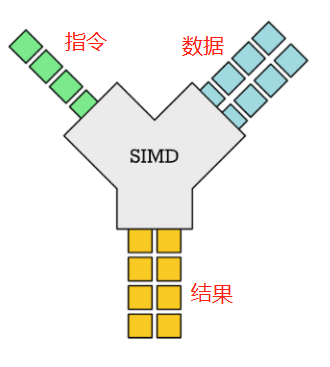
但是在Vector API中,数据的计算可以做到“单指令,多数据”,即“SIMD”:
这个代表什么意思呢?
比如我们对两组数据进行处理,普通处理的方式就是,遍历这些数组,然后逐个处理:
int[] array1 = {1, 2, 3, 4, 5};
int[] array2 = {6, 7, 8, 9, 10};
int[] array3 = new int[5];
for (int i = 0; i < 5; i++) {
array3[i] = array1[i] + array2[i];
}
System.out.println(Arrays.toString(array3));如上代码,我们定义了两个数组,现在我们想对相同下标的数进行相加,所以我们遍历了数组,一对一对进行处理,最终的结果就是:
[7, 9, 11, 13, 15]如果使用Vector API应该怎么写?
int[] array1 = {1, 2, 3, 4, 5};
int[] array2 = {6, 7, 8, 9, 10};
int[] array3 = new int[5];
VectorSpecies<Integer> intvector = IntVector.SPECIES_PREFERRED;
int[] intvectorBound = intvector.loopBound(5);
int i = 0;
for (; i < intvectorBound; i += intvector.length()) {
var array1Intvector = IntVector.fromArray(intvector, array1, i);
var array2Intvector = IntVector.fromArray(intvector, array2, i);
var array3Intvector = array1Intvector.add(array2Intvector);
array3Intvector.intoArray(array3, i);
}
for (; i < 5; i++) {
array3[i] = array1[i] + array2[i];
}
System.out.println(Arrays.toString(array3));这个代码看起来是比非Vector API复杂了,但是处理的思想完全不一样,普通处理方法是单个数据单个数据进行处理,而Vector API是多组数据处理,两者如果在大数据量计算的时候,其性能就可想而知了。
1.4 switch 模式匹配
模式匹配在Java 19中得到了相当大的更新,改进后的Switch模式匹配代码更简洁,逻辑更清晰。
在Java 19中,使用when 子句增强保护,在Java 17和Java 18中,Switch是这样使用的:
switch (t) {
case student s && s.age() > 18 -> System.out.println("学生成年");
case student s -> System.out.println("学生未成年");
default -> System.out.println("数据有误");
}那么在Java19中就是这样的:
switch (t) {
case student s when s.age() > 18 -> System.out.println("学生成年");
case student s -> System.out.println("学生未成年");
default -> System.out.println("数据有误");
}这种保护模式可比if else条件判断好用多了。
1.5 外部函数和内存API(预览)
访问堆外内存有几种方式:
- 使用ByteBuffer;
- 使用Unsafe;
- 使用JNI。
每种方式都有其优缺点,使用带ByteBuffer的直接缓冲区时,限制为2GB,这是int可以处理的范围,内存释放取决于GC。Unsafe 性能不错,但并不安全,访问释放的内存会导致JVM崩溃。使用JNI需要编写C代码,性能不好。
Java 19为Java程序引入一系列的 API,以便与Java运行时之外的代码和数据进行交互。API高效地执行外部函数(即JVM之外的代码)并安全地访问外部内存(不受JVM管理的内存),允许Java程序调用本地库和管理本地数据,从而使得程序拥有易用性、高性能、通用性、安全性等特点。
1.6 结构化并发
JDK 19引入了结构化并发,目前处于孵化阶段。
当我们在Java中创建一个新线程时,操作系统会进行系统调用,告诉它创建一个新的系统线程。我们都知道,创建系统线程的成本很高,因为调用会占用大量时间,并且每个线程都会占用一些内存,线程也共享相同的CPU,我们是不希望出现阻塞的情况。
这个时候可能就会想到使用异步编程来防止阻塞情况的发生,启动一个线程并告诉它在数据到达时要做什么。在数据可用之前,其他线程可以将CPU资源用于其任务。异步编程确实实现了其想要的效果,但是往往处理起来比较麻烦,那么结构化并发就可以简化并发编程中的种种麻烦事,使得编写和调试多线程代码变得更加容易。
结构化并发的原理就是使线程的生命周期与结构化编程中的代码块相同。如果在方法1中调用方法2 ,则必须先完成方法2,然后才能退出方法1,方法2的生命周期不能超过方法1的生命周期。
我们来画个图进行解释一下,看完你就懂了。
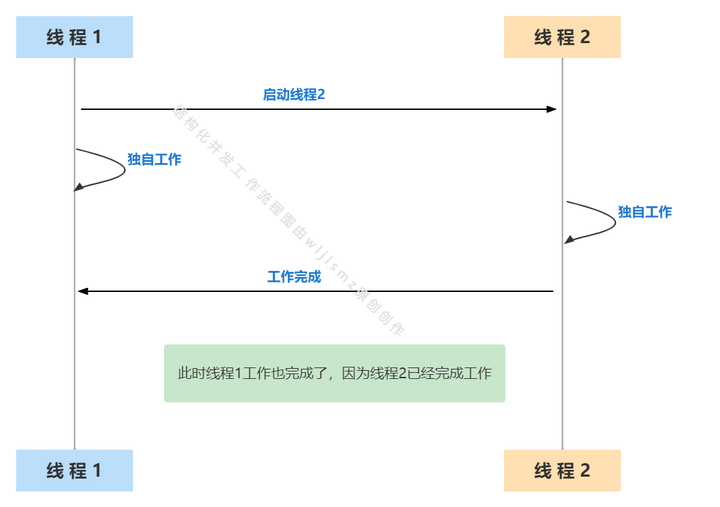
如图,线程1启动了一个线程,我们暂且叫它线程2,两者彼此分开工作,但在线程 1完成之前,它必须等待线程2完成其工作。
1.7 Linux/RISC-V移植
这个我们简单了解一下,其思想就是将JDK移植到开源Linux RISC-V架构。RISC-V标准是12年前由加州大学伯克利分校教授David Patterson和Krste Asanovi?发明的,开发人员可以自由更改RISC-V芯片的指令集架构与英特尔x86、Arm处理器的指令集架构。
估计这个解释,各位看官不认可或者直接不知所云,说的简单点,就是通过Linux/RISC-V移植,Java可以支持对硬件发送指令,这个就很厉害了,以前提到硬件,那么必然想到的语言就是C或者C++,但是目前Linux/RISC-V移植还不完善,我们期待有一天在硬件开发的领域中,Java能够有自己的一席之地!
二、热门技术
在第一章节,我们介绍了目前Java最新版本Java19中最新的功能,本章节,我们介绍一下2023年比较热门的Java技术。
2.1 微服务
微服务的火热其实已经持续很长时间了,传统服务一般是单体服务,但是随着业务的增加、架构的复杂,单体服务会使得本身服务变得非常臃肿,性能也会非常低。
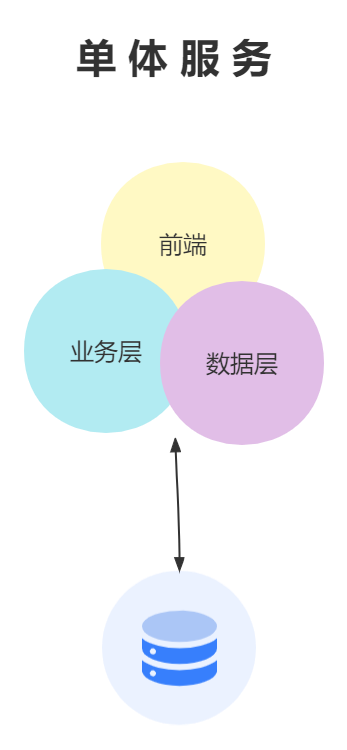
那么把服务拆分,不仅可以做到解耦合,还能在很大程度上提高系统的性能。
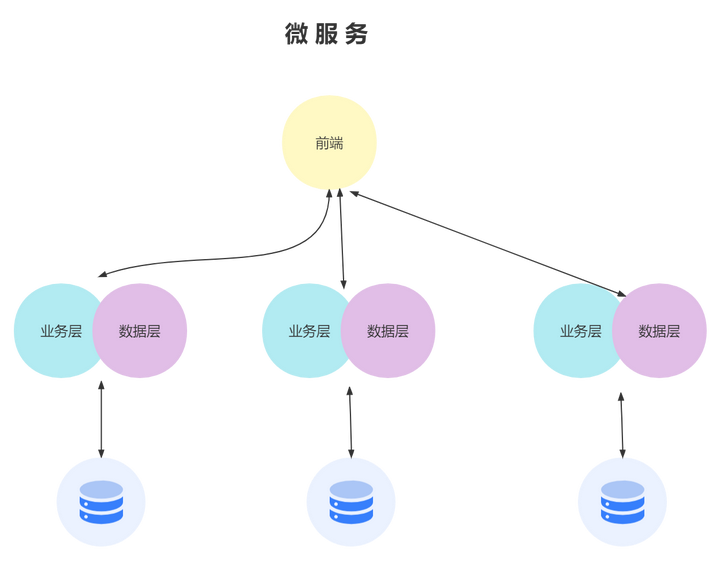
微服务的特点:
- 自治:微服务是自包含的,可以独立开发和部署,而不会影响其他服务。
- 专业化:每个微服务都针对一种特定功能而设计。
- 无状态:微服务不共享服务的状态,在某些情况下,如果需要维护状态,可以在数据库中进行维护。
在微服务中,Java相关的技术主要是Spring Boot + Spring Cloud,这也是 Java开发微服务的最佳选择,因为两者的体系非常成熟,而且社区活跃度也非常高。Spring Cloud 提供了许多开箱即用的特性,比如服务发现和负载均衡。
2.2 并发
并发编程一直是非常火热的技术,不仅仅在企业开发中出场率高,在面试中也是占据主要席位的,还有人说并发是区分普通开发人员和优秀程序员的标准,可见并发编程的重要性和难度。
在并发中,常见的技术主要有Thread、Runnable对象锁、同步、死锁、活锁、CyclicBarrier、CountDownLatch、Phaser和CompleteableFuture等。
2.3 NoSQL
数据库是Java开发中最基本的技术,就跟人的手脚一样,但是NoSQL不一样,它就像我们出行方式中的高铁、飞机一样,虽然说去某个地方也能走路过去,但是坐高铁、坐飞机,速度提升的不是一般的快。所以说NoSQL的应用是非常重要的,也是比较热门的技术。
出场率比较高的两个NoSQL有:
- Redis:即REmote Dictionary Server,由Salvatore Sanfilippo创立。它最初于2009年4月10日发布,是一种内存数据库,可用作数据库、缓存和消息代理。
- MongoDB:MongoDB由DoubleClick、ShopWiki和Gilt Groupe于2007年创立,是一个面向文档的数据库,使用动态模式来存储类似JSON的文档。
三、总结
2023即将过去四分之一,不知道你已经写了多少行代码,写代码的同时是否想过今年比较热门的技术有哪些?比较新的技术又有哪些?本文,笔者给大家着重介绍了Java最新版本Java19的新特性以及比较热门的微服务、并发、NoSQL,欢迎在评论区与我交流讨论。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java