
使用ChatGPT提升数据分析能力和效率
前言
比尔·盖茨说:“chatgpt像互联网发明一样重要,将会改变世界。”使用一段时间chatgpt后,可以发现chatgpt是能极大的提高工作效率的工具。在游戏运营中,数据分析和数据科学是非常重要的一环。
有了chatgpt,对于不会数据分析技能的运营同学,也可以进行常见的数据分析,作为工作效率的极大提升。对于会数据分析的运营同学和专职数据分析同学,可以使用chatgpt替代日常中数据分析开发工作,将重心更多的聚焦分析和业务工作。
本文就列举了4种常见的游戏运营中的数据分析场景,包括数据提取,数据分析,聚类,预测等,使用chatgpt辅助完成分析工作。
在使用chatGPT的过程中,我也会思考,有了chatgpt,好像我们的工作内容有一部分被取代了,是否说明我们的价值也相应被取代了呢?
我认为未来的时代,我们确实应该和chatgpt一样,持续进化。作为一个数据分析师或者游戏运营的价值,应该体现在:
- 更深的业务理解能力
- 更广的知识体系和知识运用能力(分析能力,算法能力,心理学,社会学,经济学)
- 数据敏感度和创造力
- 更熟练的chatgpt使用能力
提取数据
提取数据是非常常见的工作,这里介绍了如何使用chatgpt辅助生成提取数据sql代码。
准备工作
输入要用到的表和字段,这些信息可以询问数据同学。举个例子,这里用到三张数据表:
用户登录表eliot_db::yuanshen_userlogin,表是静态分区表,分区字段datadate,包括字段:userid,登录时间logdate 用户付费表eliot_db::yuanshen_userpay,表是静态分区表,分区字段datadate, 包括字段:userid,最近7天付费金额weekpaymoney 用户信息表eliot_db::yuanshen_userinfo,表是静态分区表,分区字段datadate, 包括字段:userid,年龄iage
输入chatgpt:

描述提取需求
我们想要提取最近30天活跃用户,包括每个用户的最近7天付费金额,和年龄信息。然后过滤18岁以下用户。可以这么输入chatgpt:

chatgpt输出的hive代码:
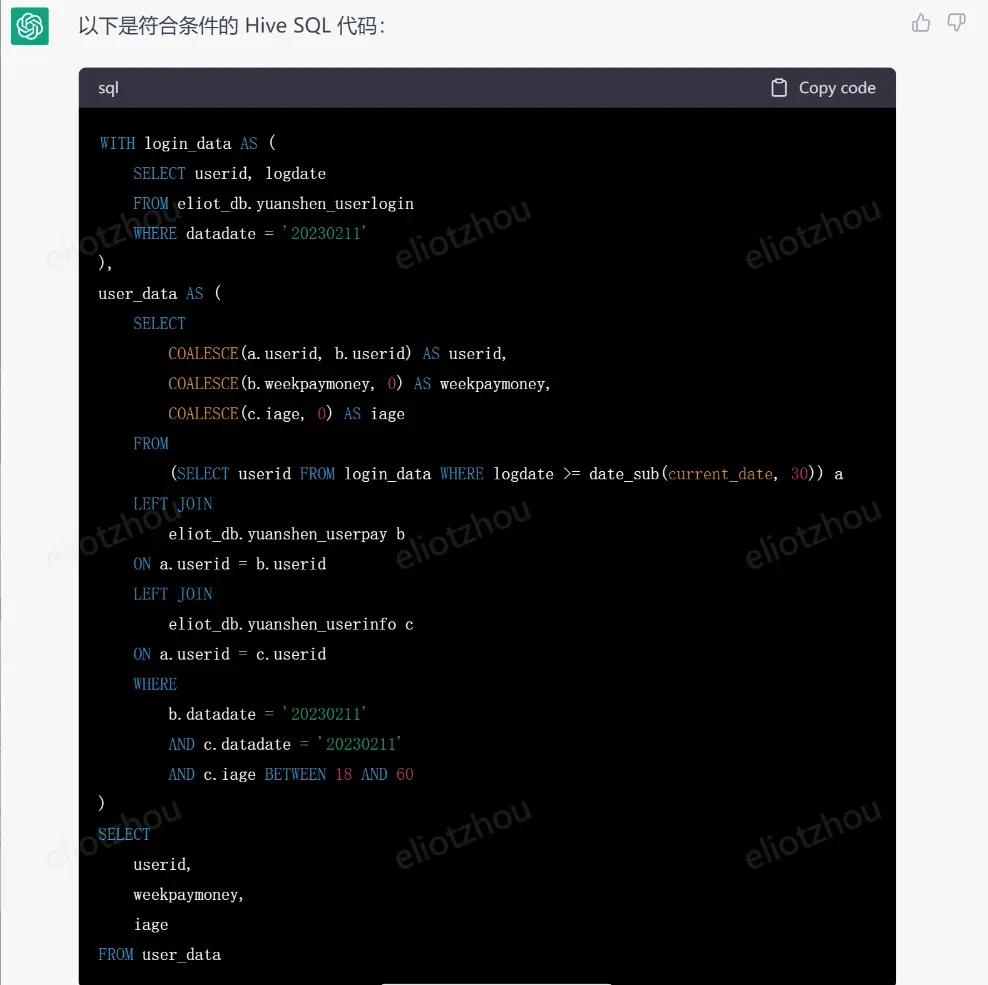
如果你具备一定的hive代码能力,检查下代码。以上chatgpt给出的代码完全没有问题。
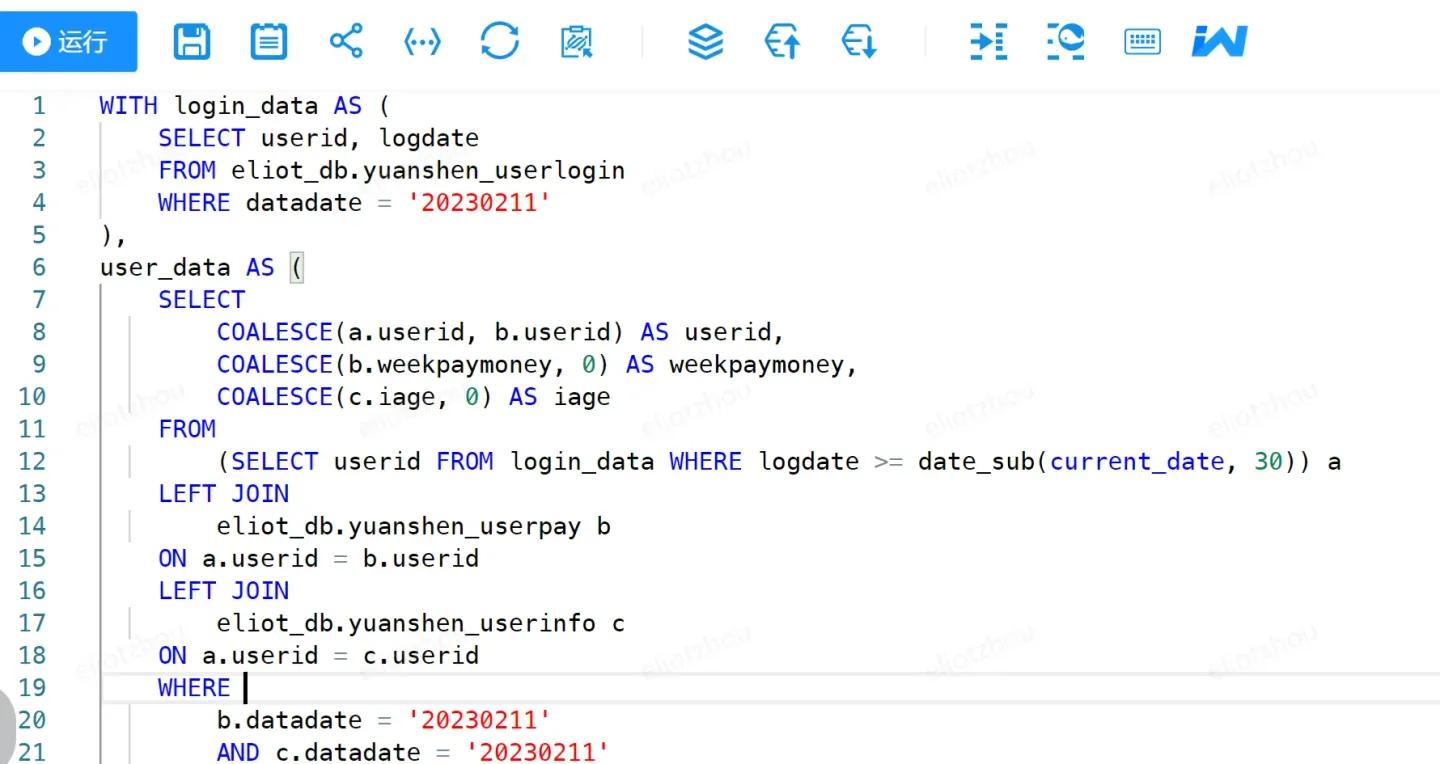
在idex中执行代码
将代码复制到idex中,执行代码,等待结果:
检查错误
有时候代码执行会报错,可以直接把错误信息让chatgpt查询

复制红字部分,输入给chatgpt

报错原因是因为表名或者库名不对,可以检查核对后,修改一下代码。
数据分析
数据分析也是比较常见的工作,包括游戏用户群的各项指标的分布和趋势等。同样的,我们可以让chatgpt生成分析代码。
用户付费能力分布
我们想要看特定用户付费金额分布情况,比如用户范围是最近30天活跃过的用户,年龄18~60岁。看最近7天付费金额分布情况,按每10元一个区间划分分布。
这里有一个需要明确的需求点要指明给chatgpt:如果我们取最近30天活跃过的用户,那么用户最近7天没有付费,不能把这部分过滤掉,将付费金额设置为0。
将需求输入给chatgpt:

chatgpt返回的hive代码:
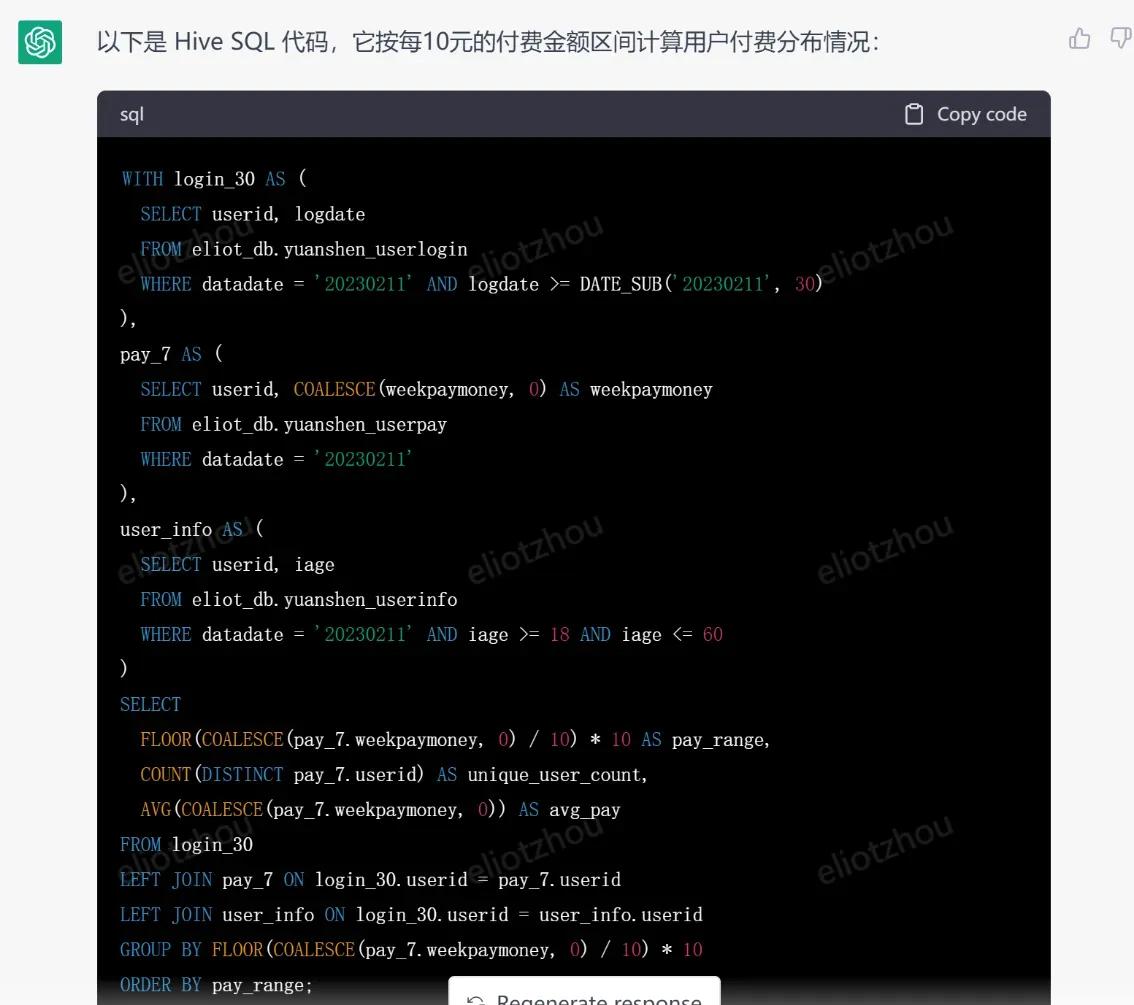
这个代码检查一下,也是完全没问题的,在idex执行就行。
得到结果后我们想检验下结果是否正确,可以将所有付费分布的用户数加和,得到我们定义的用户范围的用户数。
然后输入一个求用户数的代码需求给chatgpt:
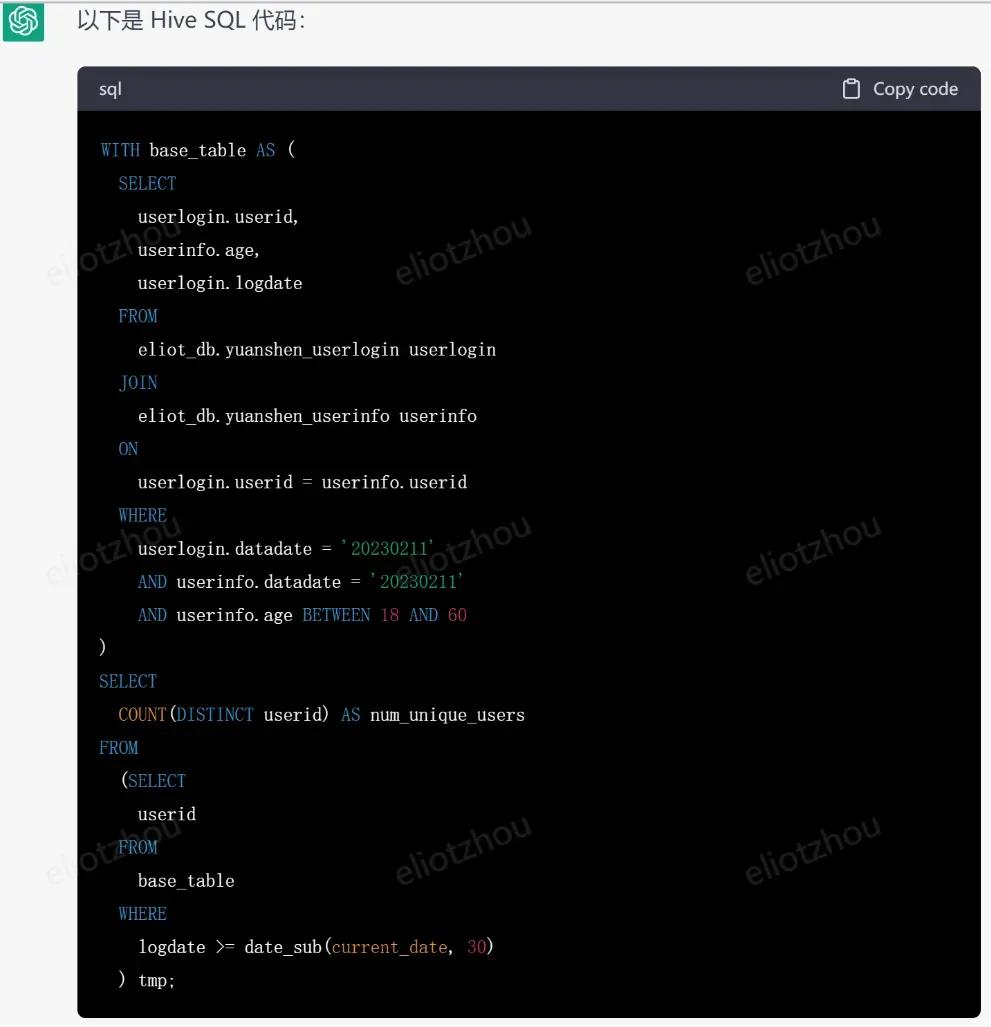
WeChatWorkScreenshot_849e9956-8ce9-4293-b004-ce8648550248
对比两个用户数,无误说明之前我们的需求结果应该没问题。
不同年龄段用户的付费能力分布情况
进一步,我们计算一个更复杂的分布问题,假如我们想看不同年龄段的用户的付费区间分布情况,我们继续输入需求:
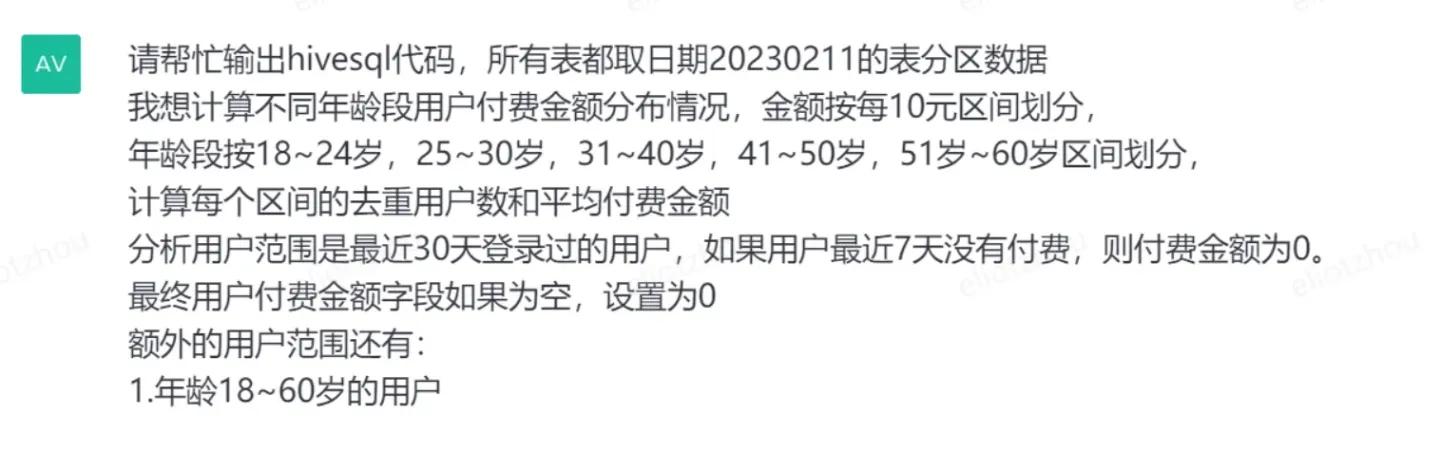
WeChatWorkScreenshot_868f8ee1-02e2-49d7-9b37-ccd956acfe73
chatgpt给出的hive代码:
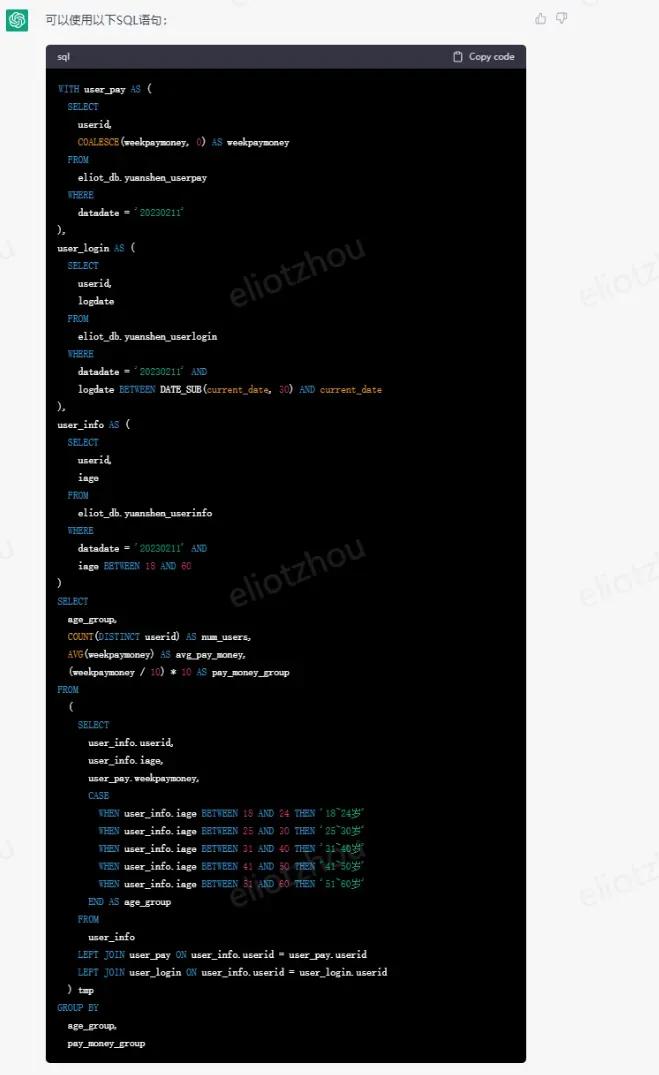
同样的在idex执行代码,然后核对检查下。
聚类
聚类是我们做游戏用户画像工作中常用的方法,比如用户玩法偏好,付费偏好等等。这里,我们用chatgpt辅助生成聚类代码。
聚类之前,需要准备好用户特征表,可以用之前列举的用户提取和分析方法,让chatgpt生成代码,跑出用户包文件。
举一个例子,我们想看原神用户玩法偏好画像,我们可以根据我们对游戏业务的理解能力,生成这样的一张用户特征表:
userid,主线剧情推进度zhuxian_rate,支线任务完成数renwu_num,深渊获得星数shenyuan_num,大地图探索度ditu_rate,七圣召唤比赛数zhaohuan_num。
生成聚类代码
输入需求:

chatgpt生成的代码:
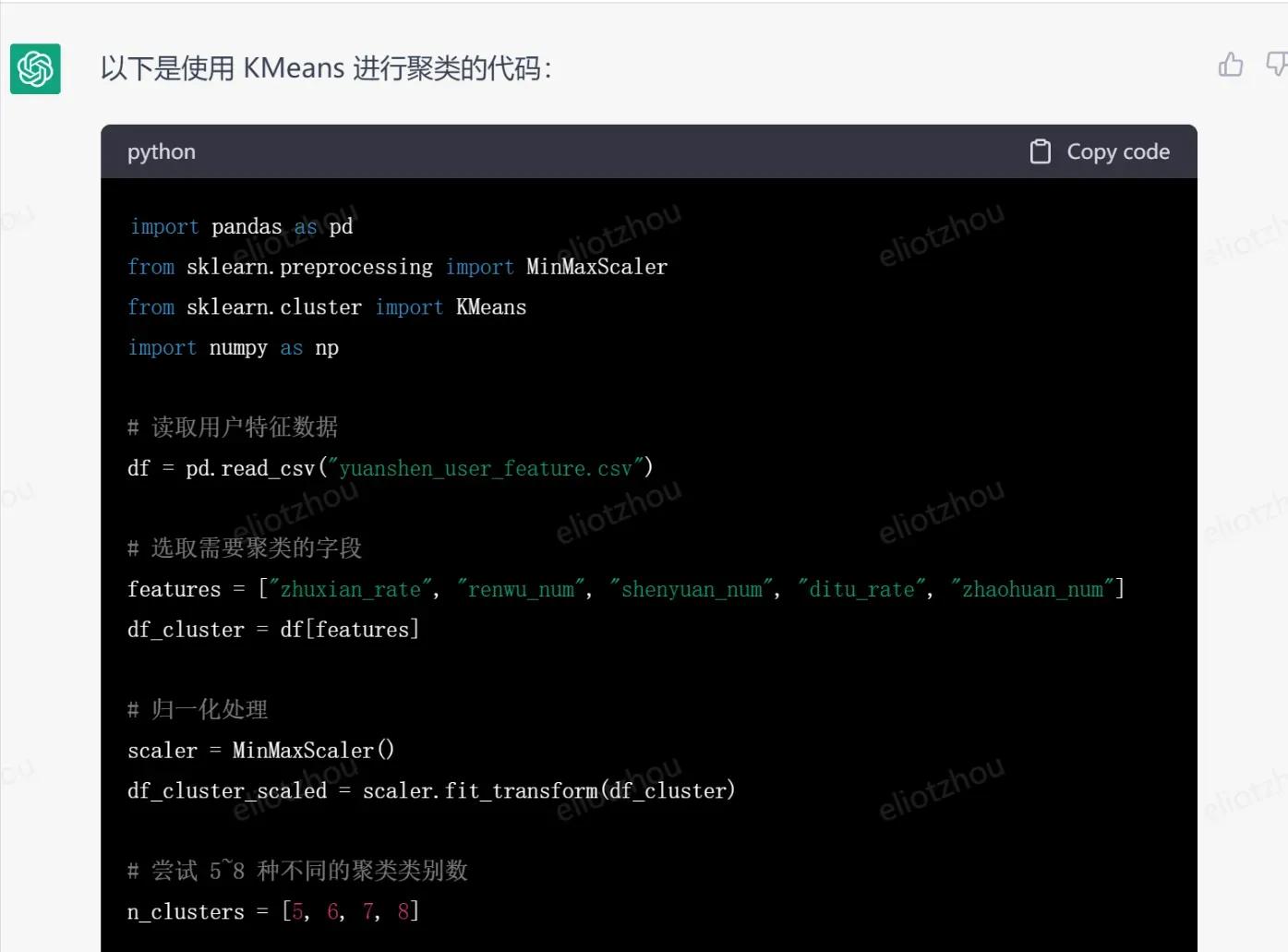
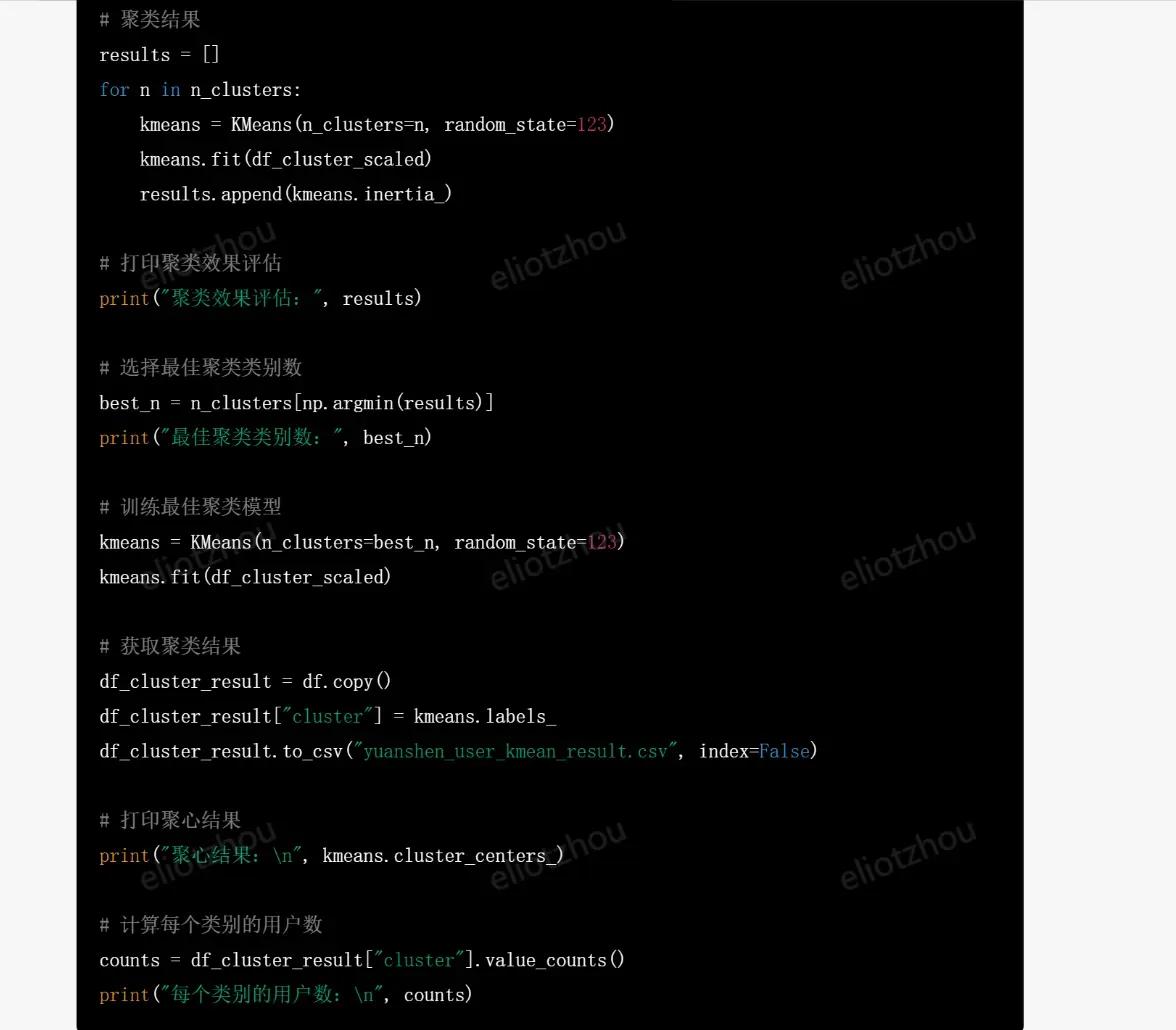
检查了代码,基本没有问题。
执行聚类代码
点开idex,打开jupyter:

选择python3.7新建一个启动页,重命名为yuanshen_kmeans.ipynb,将代码复制进去
然后将用户表文件放到目录中:
WeChatWorkScreenshot_449ecd96-b7ed-44e8-88aa-4a11f6189a37
最后点击执行,等待输出聚类结果。
解读结果
得到聚类结果后,我们会进一步分析用户画像,比如我们可以关联输出的聚类结果用户包,分析每个类别用户的其他特征指标情况等。
我们还需要分析每个类别用户的这些主要特征指标聚心结果,基于游戏业务理解,描述用户画像。
我一时兴起,将聚类结果输入给了chatgpt,请它帮忙描述下每类用户的画像。

它概括的居然还不错

WeChatWorkScreenshot_e2097d0d-e087-47b0-b6a9-04c6bc331ca6
预测
预测也是我们在游戏数据分析工作中经常会遇见的工作场景,包括道具销量预测,KPI指标预测,用户流失预测等等。
我们可以让chatgpt生成预测工作全过程的代码,帮忙我们快速得到预测结果。
举个例子,我们想预测原神1个月后上线的复刻胡桃和夜兰的池子流水收人,我们需要先准备两部分数据:
1.历史上线的角色池子收入数据yuanshen_juese_water_data.csv,和对应的每个池子的特征字段数据,比如:用户活跃数actusers,用户付费payusermoney,角色属性juese_feature_id,已拥有角色用户数have_juese_users等。
2.需要预测的池子的特征字段数据yuanshen_juese_water_predict.csv,用户活跃数,用户付费,角色属性,已拥有角色用户数等。
生成预测代码
输入需求

chatgpt给出的代码
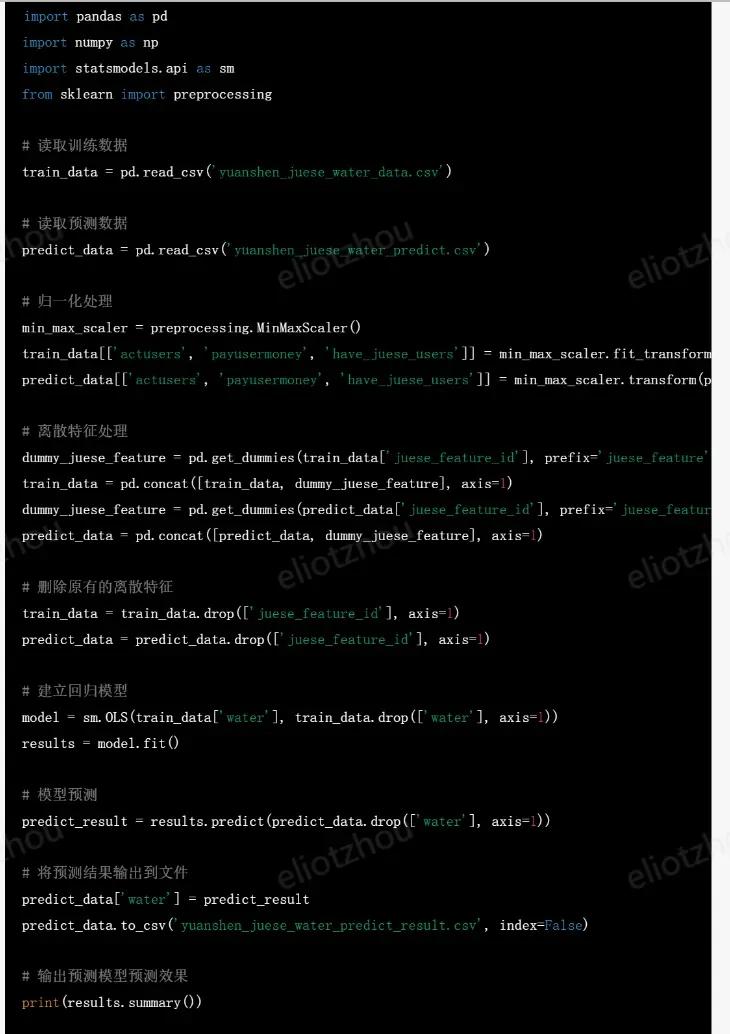
执行代码并评估效果
执行代码后,输出了预测结果,可以用于评估待上线的角色池子的流水水平。
当然,我们需要评估预测模型的准确度是否在我们的误差承受范围内,因此我们需要分析下模型效果。
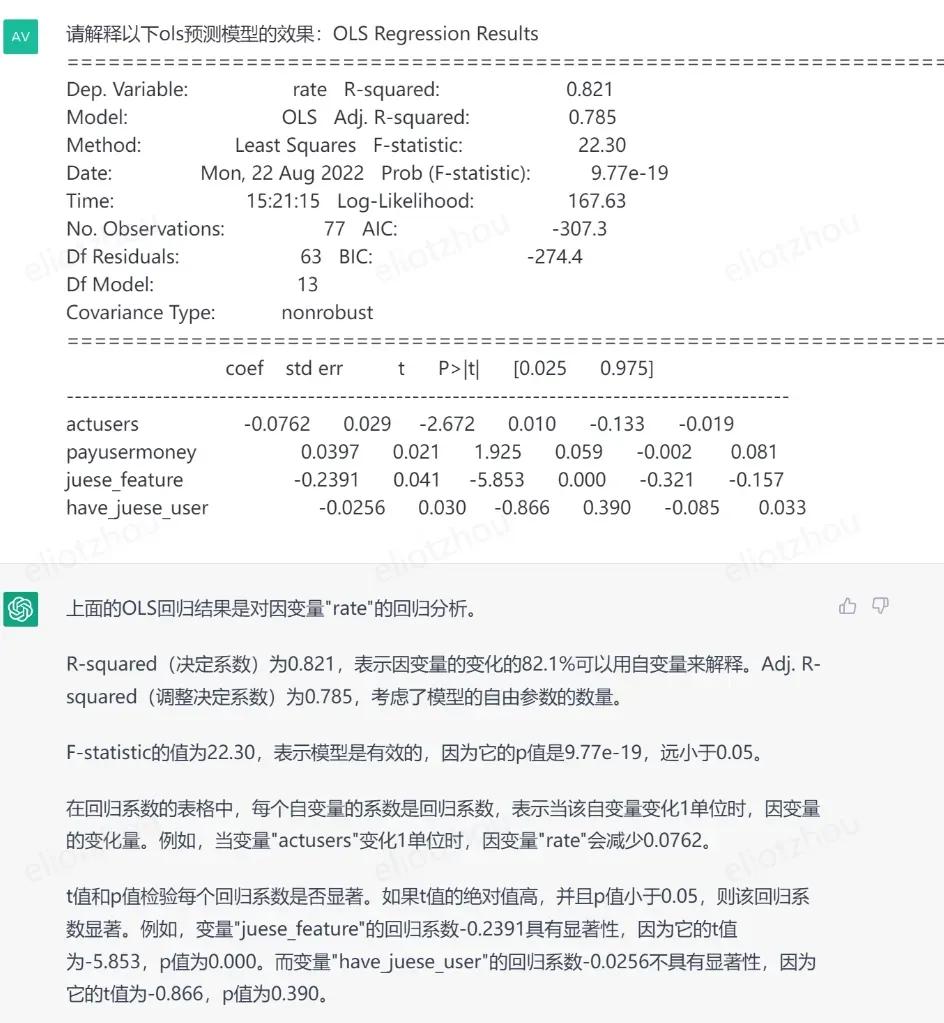
模型看上去是比较准确的,并且通过回归模型,我们可以发现,角色的属性信息,是比较能影响角色池子流水收人的。
因此,这个特征是在商业化探索上值得我们进一步分析的。
因果推断
更进一步,我们在工作中也会有一些因果推断的问题,比如分析某个策略或指标对用户留存,活跃的影响等等。
简单的因果推断问题,我们也可以让chatgpt快速生成代码。
举个例子,我们想分析钓鱼这种休闲玩法,是否能促进玩家的在线时长,我们需要先准备这样的数据:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java