
提升 Java 字符串编码解码性能的技巧
1 常见字符串编码
常见的字符串编码有:
- LATIN1 只能保存ASCII字符,又称ISO-8859-1。
- UTF-8 变长字节编码,一个字符需要使用1个、2个或者3个byte表示。由于中文通常需要3个字节表示,中文场景UTF-8编码通常需要更多的空间,替代的方案是GBK/GB2312/GB18030。
- UTF-16 2个字节,一个字符需要使用2个byte表示,又称UCS-2 (2-byte Universal Character Set)。根据大小端的区分,UTF-16有两种形式,UTF-16BE和UTF-16LE,缺省UTF-16指UTF-16BE。Java语言中的char是UTF-16LE编码。
- GB18030 变长字节编码,一个字符需要使用1个、2个或者3个byte表示。类似UTF8,中文只需要2个字符,表示中文更省字节大小,缺点是在国际上不通用。
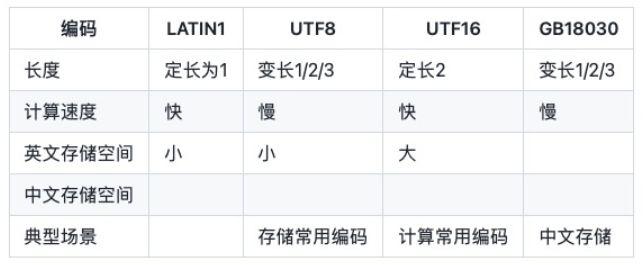
为了计算方便,内存中字符串通常使用等宽字符,Java语言中char和.NET中的char都是使用UTF-16。早期Windows-NT只支持UTF-16。
2 编码转换性能
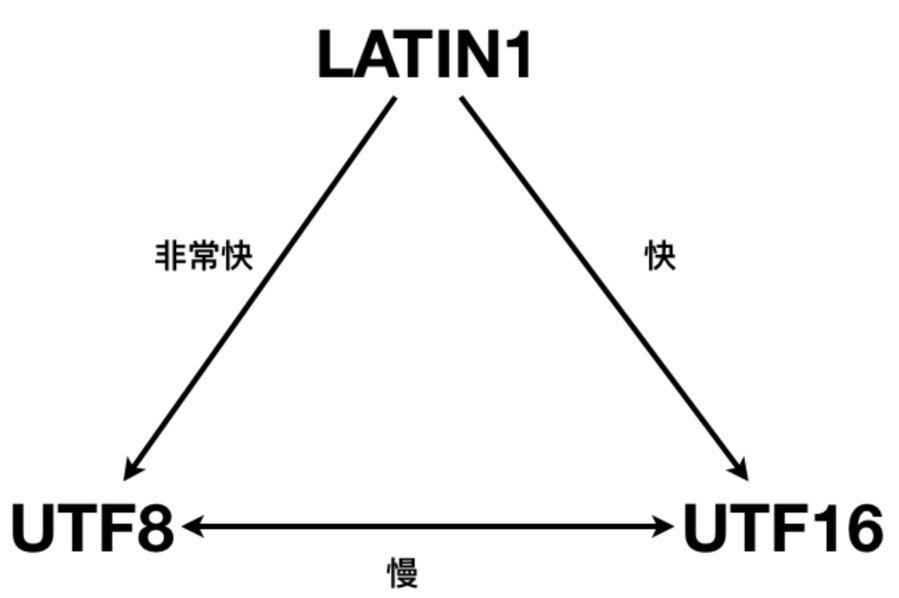
UTF-16和UTF-8之间转换比较复杂,通常性能较差。
如下是一个将UTF-16转换为UTF-8编码的实现,可以看出算法比较复杂,所以性能较差,这个操作也无法使用vector API做优化。
static int encodeUTF8(char[] utf16, int off, int len, byte[] dest, int dp) {
int sl = off + len, last_offset = sl - 1;
while (off < sl) {
char c = utf16[off++];
if (c < 0x80) {
// Have at most seven bits
dest[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 dest, 11 bits
dest[dp++] = (byte) (0xc0 | (c >> 6));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < '\uE000') {
int uc;
if (c < '\uDC00') {
if (off > last_offset) {
dest[dp++] = (byte) '?';
return dp;
}
char d = utf16[off];
if (d >= '\uDC00' && d < '\uE000') {
uc = (c << 10) + d + 0xfca02400;
} else {
throw new RuntimeException("encodeUTF8 error", new MalformedInputException(1));
}
} else {
uc = c;
}
dest[dp++] = (byte) (0xf0 | ((uc >> 18)));
dest[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dest[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (uc & 0x3f));
off++; // 2 utf16
} else {
// 3 dest, 16 bits
dest[dp++] = (byte) (0xe0 | ((c >> 12)));
dest[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}相关代码地址[1] 。
由于Java中char是UTF-16LE编码,如果需要将char[]转换为UTF-16LE编码的byte[]时,可以使用sun.misc.Unsafe#copyMemory方法快速拷贝。比如:
static int writeUtf16LE(char[] chars, int off, int len, byte[] dest, final int dp) {
UNSAFE.copyMemory(chars
, CHAR_ARRAY_BASE_OFFSET + off * 2
, dest
, BYTE_ARRAY_BASE_OFFSET + dp
, len * 2
);
dp += len * 2;
return dp;
}3 Java String的编码
不同版本的JDK String的实现不一样,从而导致有不同的性能表现。char是UTF-16编码,但String在JDK 9之后内部可以有LATIN1编码。
3.1. JDK 6之前的String实现
static class String {
final char[] value;
final int offset;
final int count;
}在Java 6之前,String.subString方法产生的String对象和原来String对象共用一个char[] value,这会导致subString方法返回的String的char[]被引用而无法被GC回收。于是使得很多库都会针对JDK 6及以下版本避免使用subString方法。
3.2. JDK 7/8的String实现
static class String {
final char[] value;
}JDK 7之后,字符串去掉了offset和count字段,value.length就是原来的count。这避免了subString引用大char[]的问题,优化也更容易,从而JDK7/8中的String操作性能比Java 6有较大提升。
3.3. JDK 9/10/11的实现
static class String {
final byte code;
final byte[] value;
static final byte LATIN1 = 0;
static final byte UTF16 = 1;
}JDK 9之后,value类型从char[]变成byte[],增加了一个字段code,如果字符全部是ASCII字符,使用value使用LATIN编码;如果存在任何一个非ASCII字符,则用UTF16编码。这种混合编码的方式,使得英文场景占更少的内存。缺点是导致Java 9的String API性能可能不如JDK 8,特别是传入char[]构造字符串,会被做压缩为latin编码的byte[],有些场景会下降10%。
4 快速构造字符串的方法
为了实现字符串是不可变特性,构造字符串的时候,会有拷贝的过程,如果要提升构造字符串的开销,就要避免这样的拷贝。
比如如下是JDK8的String的一个构造函数的实现
public final class String {
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
}在JDK8中,有一个构造函数是不做拷贝的,但这个方法不是public,需要用一个技巧实现MethodHandles.Lookup & LambdaMetafactory绑定反射来调用,文章后面有介绍这个技巧的代码。
public final class String {
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
}快速构造字符的方法有三种:
- 使用MethodHandles.Lookup & LambdaMetafactory绑定反射
- 使用JavaLangAccess的相关方法
- 使用Unsafe直接构造
这三种方法,1和2性能差不多,3比1和2略慢,但都比直接new字符串要快得多。JDK8使用JMH测试的数据如下:
Benchmark Mode Cnt Score Error Units
StringCreateBenchmark.invoke thrpt 5 784869.350 ± 1936.754 ops/ms
StringCreateBenchmark.langAccess thrpt 5 784029.186 ± 2734.300 ops/ms
StringCreateBenchmark.unsafe thrpt 5 761176.319 ± 11914.549 ops/ms
StringCreateBenchmark.newString thrpt 5 140883.533 ± 2217.773 ops/ms在JDK 9之后,对全部是ASCII字符的场景,直接构造能达到更好的效果。
4.1 基于MethodHandles.Lookup & LambdaMetafactory绑定反射的快速构造字符串的方法。
相关代码地址[2]。
4.1.1 JDK8快速构造字符串
public static BiFunction< char[], Boolean, String> getStringCreatorJDK8() throws Throwable {
Constructor< MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class);
constructor.setAccessible(true);
MethodHandles lookup = constructor.newInstance(
String.class
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findConstructor(
String.class, MethodType.methodType(void.class, char[].class, boolean.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "apply"
, MethodType.methodType(BiFunction.class)
, handle.type().generic()
, handle
, handle.type()
);
return (BiFunction) callSite.getTarget().invokeExact();
}4.1.2 JDK 11快速构造字符串的方法
public static ToIntFunction< String> getStringCode11() throws Throwable {
Constructor< MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class);
constructor.setAccessible(true);
MethodHandles.Lookup lookup = constructor.newInstance(
String.class
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findVirtual(
String.class, "coder", MethodType.methodType(byte.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "applyAsInt"
, MethodType.methodType(ToIntFunction.class)
, MethodType.methodType(int.class, Object.class)
, handle
, handle.type()
);
return (ToIntFunction< String>) callSite.getTarget().invokeExact();
}
if (JDKUtils.JVM_VERSION == 11) {
Function< byte[], String> stringCreator = JDKUtils.getStringCreatorJDK11();
byte[] bytes = new byte[]{'a', 'b', 'c'};
String apply = stringCreator.apply(bytes);
assertEquals("abc", apply);
}4.1.3 JDK 17快速构造字符串的方法
在JDK 17中,MethodHandles.Lookup使用Reflection.registerFieldsToFilter对lookupClass和allowedModes做了保护,网上搜索到的通过修改allowedModes的办法是不可用的。
在JDK 17中,要通过配置JVM启动参数才能使用MethodHandlers。如下:
--add-opens java.base/java.lang.invoke=ALL-UNNAMED
public static BiFunction< byte[], Charset, String> getStringCreatorJDK17() throws Throwable {
Constructor< MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, Class.class, int.class);
constructor.setAccessible(true);
MethodHandles.Lookup lookup = constructor.newInstance(
String.class
, null
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findStatic(
String.class, "newStringNoRepl1", MethodType.methodType(String.class, byte[].class, Charset.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "apply"
, MethodType.methodType(BiFunction.class)
, handle.type().generic()
, handle
, handle.type()
);
return (BiFunction< byte[], Charset, String>) callSite.getTarget().invokeExact();
}
if (JDKUtils.JVM_VERSION == 17) {
BiFunction< byte[], Charset, String> stringCreator = JDKUtils.getStringCreatorJDK17();
byte[] bytes = new byte[]{'a', 'b', 'c'};
String apply = stringCreator.apply(bytes, StandardCharsets.US_ASCII);
assertEquals("abc", apply);
}4.2 基于JavaLangAccess快速构造
通过SharedSecrets提供的JavaLangAccess,也可以不拷贝构造字符串,但是这个比较麻烦,JDK 8/11/17的API都不一样,对一套代码兼容不同的JDK版本不方便,不建议使用。
JavaLangAccess javaLangAccess = SharedSecrets.getJavaLangAccess();
javaLangAccess.newStringNoRepl(b, StandardCharsets.US_ASCII);4.3 基于Unsafe实现快速构造字符串
public static final Unsafe UNSAFE;
static {
Unsafe unsafe = null;
try {
Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeField.setAccessible(true);
unsafe = (Unsafe) theUnsafeField.get(null);
} catch (Throwable ignored) {}
UNSAFE = unsafe;
}
////////////////////////////////////////////
Object str = UNSAFE.allocateInstance(String.class);
UNSAFE.putObject(str, valueOffset, chars);注意:在JDK 9之后,实现是不同,比如:
Object str = UNSAFE.allocateInstance(String.class);
UNSAFE.putByte(str, coderOffset, (byte) 0);
UNSAFE.putObject(str, valueOffset, (byte[]) bytes);4.4 快速构建字符串的技巧应用:
如下的方法格式化日期为字符串,性能就会非常好。
public String formatYYYYMMDD(Calendar calendar) throws Throwable {
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH) + 1;
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH);
byte y0 = (byte) (year / 1000 + '0');
byte y1 = (byte) ((year / 100) % 10 + '0');
byte y2 = (byte) ((year / 10) % 10 + '0');
byte y3 = (byte) (year % 10 + '0');
byte m0 = (byte) (month / 10 + '0');
byte m1 = (byte) (month % 10 + '0');
byte d0 = (byte) (dayOfMonth / 10 + '0');
byte d1 = (byte) (dayOfMonth % 10 + '0');
if (JDKUtils.JVM_VERSION >= 9) {
byte[] bytes = new byte[] {y0, y1, y2, y3, m0, m1, d0, d1};
if (JDKUtils.JVM_VERSION == 17) {
return JDKUtils.getStringCreatorJDK17().apply(bytes, StandardCharsets.US_ASCII);
}
if (JDKUtils.JVM_VERSION <= 11) {
return JDKUtils.getStringCreatorJDK11().apply(bytes);
}
return new String(bytes, StandardCharsets.US_ASCII);
}
char[] chars = new char[]{
(char) y0,
(char) y1,
(char) y2,
(char) y3,
(char) m0,
(char) m1,
(char) d0,
(char) d1
};
if (JDKUtils.JVM_VERSION == 8) {
return JDKUtils.getStringCreatorJDK8().apply(chars, true);
}
return new String(chars);
}5 快速遍历字符串的办法
无论JDK什么版本,String.charAt都是一个较大的开销,JIT的优化效果并不好,无法消除参数index范围检测的开销,不如直接操作String里面的value数组。
public final class String {
private final char value[];
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
}在JDK 9之后的版本,charAt开销更大
public final class String {
private final byte[] value;
private final byte coder;
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}
}5.1 获取String.value的方法
获取String.value的方法有如下:
- 使用Field反射
- 使用Unsafe
Unsafe和Field反射在JDK 8 JMH的比较数据如下:
Benchmark Mode Cnt Score Error Units
StringGetValueBenchmark.reflect thrpt 5 438374.685 ± 1032.028 ops/ms
StringGetValueBenchmark.unsafe thrpt 5 1302654.150 ± 59169.706 ops/ms5.1.1 使用反射获取String.value
static Field valueField;
static {
try {
valueField = String.class.getDeclaredField("value");
valueField.setAccessible(true);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
char[] chars = (char[]) valueField.get(str);5.1.2 使用Unsafe获取String.value
static long valueFieldOffset;
static {
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UNSAFE.objectFieldOffset(valueField);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
char[] chars = (char[]) UNSAFE.getObject(str, valueFieldOffset);
static long valueFieldOffset;
static long coderFieldOffset;
static {
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UNSAFE.objectFieldOffset(valueField);
Field coderField = String.class.getDeclaredField("coder");
coderFieldOffset = UNSAFE.objectFieldOffset(coderField);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
byte coder = UNSAFE.getObject(str, coderFieldOffset);
byte[] bytes = (byte[]) UNSAFE.getObject(str, valueFieldOffset);6 更快的encodeUTF8方法
当能直接获取到String.value时,就可以直接对其做encodeUTF8操作,会比String.getBytes(StandardCharsets.UTF_8)性能好很多。
6.1 JDK8高性能encodeUTF8的方法
public static int encodeUTF8(char[] src, int offset, int len, byte[] dst, int dp) {
int sl = offset + len;
int dlASCII = dp + Math.min(len, dst.length);
// ASCII only optimized loop
while (dp < dlASCII && src[offset] < '\u0080') {
dst[dp++] = (byte) src[offset++];
}
while (offset < sl) {
char c = src[offset++];
if (c < 0x80) {
// Have at most seven bits
dst[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 bytes, 11 bits
dst[dp++] = (byte) (0xc0 | (c >> 6));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < ('\uDFFF' + 1)) { //Character.isSurrogate(c) but 1.7
final int uc;
int ip = offset - 1;
if (c >= '\uD800' && c < ('\uDBFF' + 1)) { // Character.isHighSurrogate(c)
if (sl - ip < 2) {
uc = -1;
} else {
char d = src[ip + 1];
// d >= '\uDC00' && d < ('\uDFFF' + 1)
if (d >= '\uDC00' && d < ('\uDFFF' + 1)) { // Character.isLowSurrogate(d)
uc = ((c << 10) + d) + (0x010000 - ('\uD800' << 10) - '\uDC00'); // Character.toCodePoint(c, d)
} else {
dst[dp++] = (byte) '?';
continue;
}
}
} else {
//
if (c >= '\uDC00' && c < ('\uDFFF' + 1)) { // Character.isLowSurrogate(c)
dst[dp++] = (byte) '?';
continue;
} else {
uc = c;
}
}
if (uc < 0) {
dst[dp++] = (byte) '?';
} else {
dst[dp++] = (byte) (0xf0 | ((uc >> 18)));
dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (uc & 0x3f));
offset++; // 2 chars
}
} else {
// 3 bytes, 16 bits
dst[dp++] = (byte) (0xe0 | ((c >> 12)));
dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}使用encodeUTF8方法举例
char[] chars = UNSAFE.getObject(str, valueFieldOffset);
// ensureCapacity(chars.length * 3)
byte[] bytes = ...; //
int bytesLength = IOUtils.encodeUTF8(chars, 0, chars.length, bytes, bytesOffset);这样encodeUTF8操作,不会有多余的arrayCopy操作,性能会得到提升。
6.1.1 性能测试比较
测试代码
public class EncodeUTF8Benchmark {
static String STR = "01234567890ABCDEFGHIJKLMNOPQRSTUVWZYZabcdefghijklmnopqrstuvwzyz一二三四五六七八九十";
static byte[] out;
static long valueFieldOffset;
static {
out = new byte[STR.length() * 3];
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UnsafeUtils.UNSAFE.objectFieldOffset(valueField);
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
@Benchmark
public void unsafeEncodeUTF8() throws Exception {
char[] chars = (char[]) UnsafeUtils.UNSAFE.getObject(STR, valueFieldOffset);
int len = IOUtils.encodeUTF8(chars, 0, chars.length, out, 0);
}
@Benchmark
public void getBytesUTF8() throws Exception {
byte[] bytes = STR.getBytes(StandardCharsets.UTF_8);
System.arraycopy(bytes, 0, out, 0, bytes.length);
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(EncodeUTF8Benchmark.class.getName())
.mode(Mode.Throughput)
.timeUnit(TimeUnit.MILLISECONDS)
.forks(1)
.build();
new Runner(options).run();
}
}测试结果
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java