
详解SQL操作的窗口函数
窗口函数是聚集函数的延伸,是更高级的SQL语言操作,主要用于AP场景下对数据进行一些分析、汇总、排序的功能。本文将从窗口函数的基本概念入手,介绍其常用SQL语法和主要的应用场景,同时会讲到在GaussDB(DWS)中使用窗口函数需要考虑的一些因素。
一. 窗口函数的作用
窗口函数(Window Function),又被叫做分析函数(Analytics Function),通常在需要对数据进行分组汇总计算时使用,因此与聚集函数有一定的相似性。但与聚集函数不同的是,聚集函数通过对数据进行分组,仅能够输出分组汇总结果,而原始数据则无法展现在结果中。而窗口函数则可以同时将原始数据和聚集分析结果同时显示出来。通过下例,大家可以体会一下区别。
给定表score(id, classid, score),每行表示学生id,所在班级id以及考试成绩,数据如下图所示:

如果我们想获取每个班的总分、平均分及学生数量,可以通过对classid进行聚集,查询语句为:
select classid, sum(score), avg(score), count(*) from score group by classid order by classid;结果如下:

通过这个结果,我们了解了班级1和2的基本信息,但是此时丢掉了学生信息,也不知道每个学生在班级中的排名如何。如果想查询这些信息,当然可以通过将聚集结果和原表进行Join得出,但显然更繁琐。而通过窗口函数的语句,我们可以轻而易举地将所需要的信息查询出来。
select classid, id, score,
sum(score) over(partition by classid),
avg(score) over(partition by classid),
count(*) over(partition by classid),
rank() over(partition by classid order by score desc)
from score
order by classid;结果如下:
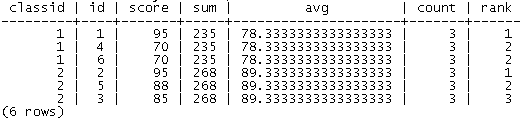
通过以上信息,我们可以很方便地进行进一步的查询,例如:查询每个班超过平均分的学生id,排名前5的学生id等。
可以看出,窗口函数其实是对查询,聚集等多个操作所做的一个组合操作,但相对于多个操作而言,使用窗口函数在完成功能的情况下,书写也更加简洁。同时,窗口函数还提供了更多的函数、更多的聚集方式以支持多样化的功能,而且支持分组中的排序功能。通过与聚集结果比较,可以方便地提取符合一定统计要求的记录信息。
二. 窗口函数的SQL语法介绍
窗口函数的功能这么强大,那支持的语法一定也非常复杂吧。别急,通过系统性地分析,你也可以快速掌握窗口函数语法的精髓!
单个窗口函数表达式的主要语法为:
SUM(SCORE) OVER (PARTITION BY CLASSID ORDER BY SCORE ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)该表达式主要由以下部分组成(下图为图解):
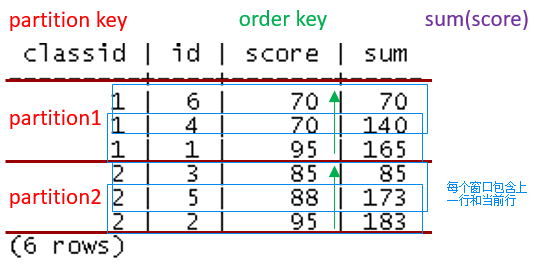
- 窗口函数表达式(紫色部分):指定该窗口函数进行计算的聚集函数,可以是SUM(), COUNT(), AVG(), MIN(), MAX()等聚集函数,可以通过以下语句在GaussDB(DWS)中查到:
SELECT proname FROM pg_proc WHERE proisagg = TRUE;也可以是其它专有的窗口函数,可以通过如下语句在GaussDB(DWS)系统表中查到:
SELECT proname FROM pg_proc WHERE proiswindow = TRUE;GaussDB(DWS)目前支持的专有窗口函数有15个:

下面将详细说明一下其中常用的窗口函数ROW_NUMBER(), RANK(), DENSE_RANK()的区别。首先通过如下查询的结果来对比。
SELECT id, classid, score,
ROW_NUMBER() OVER(ORDER BY score DESC),
RANK() OVER(ORDER BY score DESC),
DENSE_RANK() OVER(ORDER BY score DESC)
FROM score;
可以看出,三个函数都是用于进行行排序的,且参数个数为0。通过①可以看出ROW_NUMBER()和RANK()的区别:前者顾名思义,对行从1开始进行编号,无论数据是否重复,结果不重;而后者对于相同的数据,给出的排序结果是相同的。通过②可以看出RANK()和DENSE_RANK()的区别:前者在重复值后,编号和ROW_NUMBER()是相同的,虽然相同的数据编号相同,但仍然占用多个编号位置;而后者对于重复值只占用一个编号,重复后紧接着进行编号。
在实际应用着,前两个函数应用较多,ROW_NUMBER()主要用于行编号,用于分页展示等应用中;而RANK()主要用于对结果进行排序后展示。
- 窗口函数分区列(红色部分):表示根据哪一列进行分组计算,类似于聚集语句中的GROUP BY子句。该部分可以没有,类似于聚集语句,表示对所有语句划分同一组处理。
- 窗口函数排序列(绿色部分):表示数组划分到同一组后,在进行窗口函数计算前排序的顺序,可以指定多列,语法与ORDER BY类似。当聚集函数计算结果与顺序无关时,此子句可以省略。
- 窗口函数移动窗口选项(蓝色部分):该选项也称为Window Frame Option,默认可以省略,表示对每个分组内所有行进行聚集计算(无排序列时)或对每个分组内起始行到当前行进行聚集计算(有排序列时)。但指定该选项后,仅针对指定的窗口内的元组进行聚集计算。
对分组内所有行结果,当需要指定一个窗口时,我们需要指定开始的行和结束的行,则聚集函数将针对窗口之内的所有行的结果进行计算。因此,移动窗口选项的主要语法为:
RANGE|ROWS [BETWEEN] <rows_loc> [AND <rows_loc>]
或
RANGE|ROWS <rows_loc>第一种语法同时指定开始行和结束行,第二种语法仅指定开始行,结束行默认为当前行。
<rows_loc>用于指定某一行,支持以下五种用法:
- UNBOUNDED PRECEDING
表示该分组的第一行
- UNBOUNDED FOLLOWING
表示该分组的最后一行
- CURRENT ROW
表示当前行。
- <expression> PRECEDING
表示从当前行往前数<expression>数量的行,其中<expression>不能包含变量。RANGE选项禁用。
- <expression> FOLLOWING
表示从当前行往后数<expression>数量的行,其中<expression>不能包含变量。RANGE选项禁用。
例如:
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 以该分组所有元组为窗口
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 以该分组起始行到当前行为窗口
ROWS BETWEEN 10 PRECEDING AND 5 FOLLOWING 以该分组当前行前10行到后5行为窗口(不能超过起始行和结束行)
示例:下图左边表含有列x,计算的表达式值SUM(x) OVER(ROWS 2 PRECEDING AND 2 FOLLOWING)的值见右表所示,中间箭头上的数字表示起始和结束窗口的行号。例如:第1行的窗口为[1-2, 1+2]=[1, 3](不超过起始行);第4行的窗口为[4-2, 4+2]=[2, 6]。

了解完单个窗口函数表达式的语法,我们来看下在SQL语句中的使用规范。
1、单个查询中可以包含一个或多个窗口函数表达式。
2、窗口函数仅能出现在输出列中。如果需要使用窗口函数的值进行条件过滤,需要将窗口函数嵌套在子查询中,在外层使用窗口函数表达式的别名进行条件过滤。例如:
select classid, id, score
from
(select *, avg(score) over(partition by classid) as avg_score from score)
where score >= avg_score;3、窗口函数所在查询块中支持使用GROUP BY表达式进行分组去重,但要求窗口函数中的PARTITION BY子句中必须是GROUP BY表达式的子集,以保证窗口函数在GROUP BY列去重后的结果上进行窗口运算,同时ORDER BY子句的表达式也需要是GROUP BY表达式的子集,或聚集运算的聚集函数。例如:
select classid,
rank() over(partition by classid order by sum(score)) as avg_score
from score
group by classid, id;标准bench-mark TPC-DS中有多个语句使用到了窗口函数,以TPC-DS Q51为例:
WITH web_v1 as (
select
ws_item_sk item_sk, d_date,
sum(sum(ws_sales_price))
over (partition by ws_item_sk order by d_date rows between unbounded preceding and current row) cume_sales
from web_sales
,date_dim
where ws_sold_date_sk=d_date_sk
and d_month_seq between 1212 and 1212+11
and ws_item_sk is not NULL
group by ws_item_sk, d_date),
store_v1 as (
select
ss_item_sk item_sk, d_date,
sum(sum(ss_sales_price))
over (partition by ss_item_sk order by d_date rows between unbounded preceding and current row) cume_sales
from store_sales
,date_dim
where ss_sold_date_sk=d_date_sk
and d_month_seq between 1212 and 1212+11
and ss_item_sk is not NULL
group by ss_item_sk, d_date)
select *
from (select item_sk
,d_date
,web_sales
,store_sales
,max(web_sales)
over (partition by item_sk order by d_date rows between unbounded preceding and current row) web_cumulative
,max(store_sales)
over (partition by item_sk order by d_date rows between unbounded preceding and current row) store_cumulative
from (select case when web.item_sk is not null then web.item_sk else store.item_sk end item_sk
,case when web.d_date is not null then web.d_date else store.d_date end d_date
,web.cume_sales web_sales
,store.cume_sales store_sales
from web_v1 web full outer join store_v1 store on (web.item_sk = store.item_sk
and web.d_date = store.d_date)
)x )y
where web_cumulative > store_cumulative
order by item_sk
,d_date
limit 100;上面查询中使用了四个窗口函数,以CTE web_v1的定义为例:
select
ws_item_sk item_sk, d_date,
sum(sum(ws_sales_price))
over (partition by ws_item_sk order by d_date rows between unbounded preceding and current row) cume_sales
from web_sales
,date_dim
where ws_sold_date_sk=d_date_sk
and d_month_seq between 1212 and 1212+11
and ws_item_sk is not NULL
group by ws_item_sk, d_date;该语句块计算了在一定时间内,网上销售的货物的累计销售额。
该语句块在web_sales和date_dim表Join后,使用ws_item_sk, d_date列进行GROUP BY,计算sum(ws_sales_price),而后对聚集函数的结果进行窗口函数,对sum(ws_sales_price)再进行窗口函数的求和。窗口函数sum(sum(ws_sales_price)) over (partition by ws_item_sk order by d_date rows between unbounded preceding and current row)的含义是:以ws_item_sk为分组,以d_date为顺序,计算从开始截止到当天累计销售额。
三. Window子句
通过这个语句,细心的读者可以发现,窗口函数基本都是相同的格式partition by item_sk order by d_date rows between unbounded preceding and current row,存在冗余书写的问题。因此,SQL语句中支持使用window子句,类似于WITH子句定义公共的分组排序窗口,这样使用时仅引用对应的窗口名称即可。例如Q51的主语句可以写成:
select *
from (select item_sk
,d_date
,web_sales
,store_sales
,max(web_sales)
over (s rows between unbounded preceding and current row) web_cumulative
,max(store_sales)
over (s rows between unbounded preceding and current row) store_cumulative
from (select case when web.item_sk is not null then web.item_sk else store.item_sk end item_sk
,case when web.d_date is not null then web.d_date else store.d_date end d_date
,web.cume_sales web_sales
,store.cume_sales store_sales
from web_v1 web full outer join store_v1 store on (web.item_sk = store.item_sk
and web.d_date = store.d_date)
)x window s as (partition by item_sk order by d_date))y
where web_cumulative > store_cumulative
order by item_sk
,d_date
limit 100;在GaussDB(DWS)中使用window子句有以下需要注意的:
- window子句仅能在相同查询块语句中复用,跨查询块需要定义不同的window子句。
- window子句中仅能包含OVER之后的窗口子句。窗口子句可以包含:PARTITION BY子句、ORDER BY子句和移动窗口选项,而window不支持移动窗口选项。
- 窗口函数在复用window子句时,可以在window子句的基础上增加ORDER BY子句和移动窗口子句,类似于继承。
例如下面的例子:
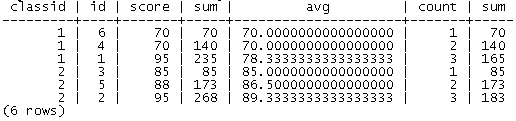
select classid, id, score,
sum(score) over(s),
avg(score) over(s),
count(*) over(s),
sum(score) over(s rows between 1 preceding and current row)
from score
window s as (partition by classid order by score, id desc)
order by classid;查询结果为:
四. GaussDB(DWS)使用窗口函数注意事项
- 与Teradata等主流数据库不同的是,GaussDB(DWS)中窗口函数的PARTITION BY后的表达式如果是数字,表示常量值,而不是输出列的序号,这点与GROUP BY的语法也有出入。例如:
select *, rank() over(partition by 1 order by id) as avg_score from score;此处会将所有数据分为一组。
- 由于窗口函数一般需要对数据进行排序之后进行窗口计算,因此在GaussDB(DWS)中使用Sort + WindowAgg算子来实现其功能。如果有多个不同的窗口子句,则每个窗口子句对应一对Sort + WindowAgg算子,示例语句及计划如下:
explain
select classid, id, score,
sum(score) over(s),
avg(score) over(s),
count(*) over(s),
sum(score) over(s rows between 1 preceding and current row)
from score
window s as (partition by classid order by score, id desc)
order by classid;
此查询中包含两类窗口子句,(partition by classid order by score, id desc)以及(partition by classid order by score, id desc rows between 1 preceding and current row),因此需要两对Sort + WindowAgg算子,见2-4号算子(为什么计划中仅出现了一个SORT?请读者思考)。由于按classid做partition,因此首先按其进行重分布,见5号算子。
- 对于分布式数据库GaussDB(DWS),数据需要在各DN执行以获得更好的性能。对于窗口函数,相同PARTITION BY的值的元组会在同一个DN上执行,因此对于缺少PARTITION BY子句,或PARTITION BY的值较少的场景,将无法完全发挥出分布式的效果。
(1) 当没有PARTITION BY子句时,Gauss(DWS)需要进行全局排序及窗口计算,因此需要先在各DN进行排序,然后将数据汇总到一个DN上进行合并排序及窗口计算,最终进行计算的DN将成为整个系统的瓶颈。这种场景需要尽量避免。(Teradata早期支持的MSUM等函数其语义即进行全局排序并局部求和,就属于这种情况。后由于窗口函数可实现同样的功能,MSUM仅作前向兼容对外提供。)此种场景示例语句及计划如下图所示:
SELECT * from (select id, classid, score, ROW_NUMBER() OVER(ORDER BY score DESC) rn from score) where rn <= 5;本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java