
2种基于深度学习的场景文字检索算法
文字检索是从图像库中检索出包含特定字符串的图像,并且同时定位该字符串在图像中位置的过程(如图1所示),是场景文字理解中的重要科学问题,被应用于商品检索、图书馆书籍管理、网络图像安全审核等场景中,极大地提高了生产效率。此外,文字识别要求图像中的所有文本实例都被精准地检测和识别,不同于端到端的文字识别任务,文字检索任务更关注于搜寻用户所感兴趣的文本。
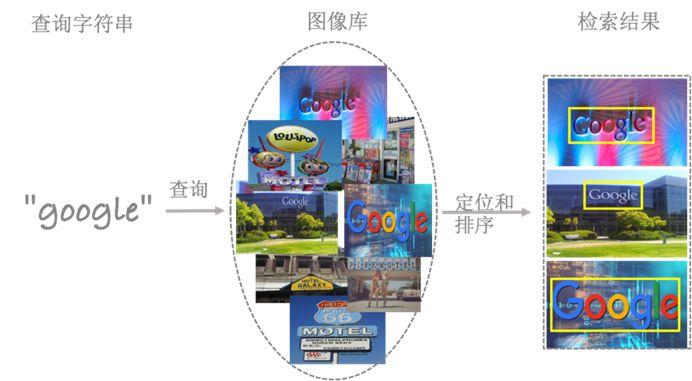
场景文字检索任务
和端到端文字识别任务一样,图像中的文本具有字体多变、字符排列方式不规则、字符序列长度不固定等难点。自然场景文字检索特有的挑战主要来自三个方面:
(1)不同的待检索字符串之间的差异非常微弱:和通用目标以及人脸不同,不同单词之间的差异性非常微弱,其差异性通常在于几个字符之间,因此如何区分高度相似的单词是文字检索的难点之一。如图2所示,待检索的单词“india”和“indian”只相差一个字符,而检索出的图像序列完全不同。
(2)同一待检索字符串在图像中的视觉差异大、字体变化大,比如艺术字体等。
(3)跨模态特征间的相似性度量:图像内的文本实例和访问字符串属于两种不同的模态,并且均为变长序列,度量跨模态序列特征间的相似性是难点之一。

场景文字检索任务的难点
前些年场景文字检索的方法[3][6][7]均是基于手工设计的特征,并且文本检测和距离度量是分开处理的。浅层的工设计的特征以及分步的文本检测与距离度量过程,使得网络模型在优化过程中无法达到全局最优。近几年,随着深度学习在计算机视觉各个领域的兴起,出现了一些基于深度学习的场景文本检索算法,能够将场景文本检测和距离度量过程整合到一个深度神经网络中。基于深度学习的文字检索算法可以大致分为:基于单词编码的方法[1]和基于相似性学习的方法[2]。
基于单词编码的方法的核心思想是将查询字符串转化为预定义的编码向量(如PHOC[3]),同时通过神经网络预测图像中包含的所有可能的单词的编码向量,最后通过计算查询字符串的编码向量和从图像中预测的编码向量间的距离来进行排序并检索, 计算公式如下:
其中表示度量两向量间距离的函数(如汉明距离,余弦距离等)。如图3所示,基于单词编码的方法的网络结构由单一的全卷积网络构成,该网络在特征图的每个位置上预测向量,其中表示文本实例的水平包围框,即(水平框中心点x轴坐标,水平框中心点y轴坐标,水平框的宽度,水平框的高度),表示该位置属于文本的置信度,代表该文本行所属的单词对应的PHOC向量。
在推理阶段,对于图像库中的每张图像,首先根据文本的置信度从图像中选取前个文本候选区域,然后计算查询字符串的编码向量和个文本候选区域间的距离,并将距离最小的作为该图像的得分。
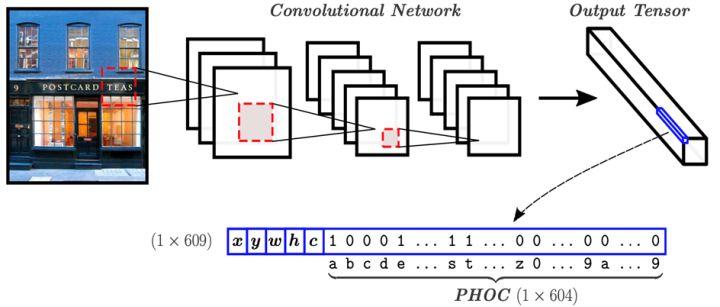
基于单词编码方法的流程图
基于相似性学习的方法的核心思想是直接度量图像中候选文本区域和查询字符串间的相似性,通过该相似性对图像进行排序并检索。如图4所示,网络由图像分支和文本分支构成。图像分支由检测模块和图像序列建模模块构成,其中检测模块使用的是单阶段检测器FCOS[4],其主要作用是产生大量的文本候选框。图像序列建模模块由双向循环神经网络构成,借助其内部的门机制对序列中每帧之间的相关性建模,获取序列特征的上下文信息。该模块以文本候选框内的特征作为输入,最终输出语义增强的文本特征。类似地,文本分支由词嵌入模块和文本序列建模模块构成。词嵌入模块以查询字符串作为输入,输出固定尺寸的特征向量。该模块由可学习的嵌入模块(类别数等于语种的字符类型数)和双线性插值构成,通过嵌入模块得到查询字符串中每个字符的特征,该变长字符序列特征(序列长度等于字符串字符个数)通过双线性插值算法插值为固定长度。接着,插值后的固定长度特征输入文本序列建模模块获取语义增强的特征。最后,将查询字符串包含于该图像的可能性定义为和之间的最大相似度,计算公式如下:
其中表示度量两向量间相似度的函数(如余弦相似度)。特别地,两向量间的相似度通过相应的单词对间的归一化的编辑距离[5]进行监督学习。另外,为了使得图像分支的特征优化得更好,将文本识别任务以多任务的方式引入到网络框架之中,来引导模型提取更好的序列特征。
在推理阶段,对于图像库中的每张图像,首先利用检测器FCOS从图像中选取前(数值为100)个文本候选区域,然后计算查询字符串的特征和个文本候选区域的特征的余弦相似度,并将相似度最大的作为该图像的得分。
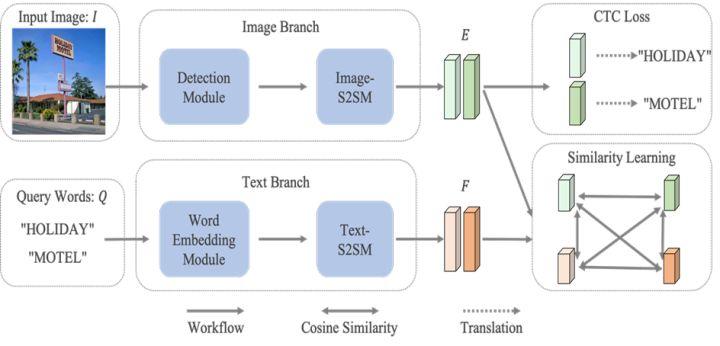
基于相似性学习方法的流程图
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java