
Flink 新版 Connector 的实现
前言
Flink 可以说已经是流计算领域的事实标准,其开源社区发展迅速,提出了很多改进计划(Flink Improvement Proposals,简称 FLIP [1])并不断迭代,几乎每个新的版本在功能、性能和使用便捷性上都有所提高。Flink 提供了丰富的数据连接器(connecotr)来连接各种数据源,内置了 kafka [2]、jdbc [3]、hive [4]、hbase [5]、elasticsearch [6]、file system [7] 等常见的 connector,此外 Flink 还提供了灵活的机制方便开发者开发新的 connector。对于 source connector 的开发,有基于传统的 SourceFunction [8] 的方式和基于 Flink 改进计划 FLIP-27 [9] 的 Source [10] 新架构的方式。本文首先介绍基于 SourceFunction 方式的不足,接着介绍 Source 新架构以及其设计上的深层思考,然后基于 Flink 1.13 ,以从零开发一个简单的 FileSource connector 为例,介绍开发 source connector 的基本要素,尽量做到理论与实践相结合加深大家的理解。
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。流计算 Oceanus 提供了便捷的控制台环境,方便用户编写 SQL 分析语句、ETL 作业或者上传运行自定义 JAR 包,支持作业运维管理。
Source 旧架构
在 Flink 1.12 之前,开发一个 source connector 通过实现 SourceFunction [8] 接口来完成,官方给出的通用的实现模式如下。当 source 开始发送数据时,run 方法被调用,其参数 SourceContext 用于发送数据。run 方法是一个无限循环,通过一个标识 isRunning 来跳出循环结束 source。批模式和流模式通常需要不同的处理逻辑,例如示例的批模式通过一个计数器来结束批数据。此外,还需要通过 checkpoint 锁来保证状态更新和数据发送的原子性。值得一提的是,Flink 在 SourceFunction 之上抽象出了 InputFormatSourceFunction,开发者只需要实现 InputFormat,批模式 source connector(如 HBase)通常基于 InputFormat 实现,当然 InputFormat 也可以用于流模式,在一定程度上体现了批流融合的思想,但整体上来看至少在接口层面上流批并没有完全一致。
public class ExampleCountSource implements SourceFunction<Long>, CheckpointedFunction {
private long count = 0L;
private volatile boolean isRunning = true;
private transient ListState<Long> checkpointedCount;
public void run(SourceContext<T> ctx) {
while (isRunning && count < 1000) {
// this synchronized block ensures that state checkpointing,
// internal state updates and emission of elements are an atomic operation
synchronized (ctx.getCheckpointLock()) {
ctx.collect(count);
count++;
}
}
}
public void cancel() {
isRunning = false;
}
public void initializeState(FunctionInitializationContext context) {
this.checkpointedCount = context
.getOperatorStateStore()
.getListState(new ListStateDescriptor<>("count", Long.class));
if (context.isRestored()) {
for (Long count : this.checkpointedCount.get()) {
this.count += count;
}
}
}
public void snapshotState(FunctionSnapshotContext context) {
this.checkpointedCount.clear();
this.checkpointedCount.add(count);
}
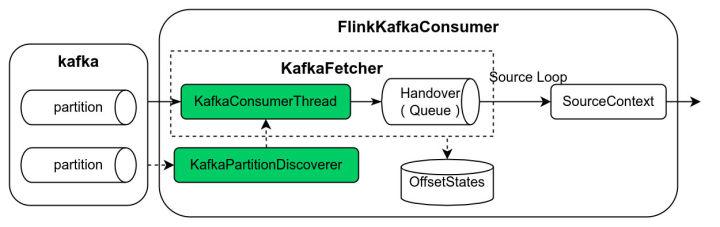
}在基于 SourceFunction 的开发模式下,以 Kafka Source 为例,见下图,FlinkKafkaConsumer 为 SourceFunction 的实现类,该类中集中了 kafka partition 发现逻辑(KafkaPartitionDiscoverer)、数据读取逻辑(KafkaFetcher)、基于阻塞队列实现的生产者消费者模型(KafkaConsumerThread -> Handover -> SourceContext)等等。
我们可以发现,这种开发模式存在如下不足:
- 首先对于批模式和流模式需要不同的处理逻辑,不符合批流融合的业界趋势。
- 数据分片(例如 kafka partition、file source 的文件 split)和实际数据读取逻辑混合在 SourceFunction 中,导致复杂的实现。
- 数据分片在接口中并不明确,这使得很难以独立于 source 的方式实现某些功能,例如事件时间对齐(event-time alignment)、分区 watermarks(per-partition watermarks)、动态数据分片分配、工作窃取(work stealing)。
- 没有更好的方式来优化 Checkpoint 锁,在锁争用下,一些线程(例如 checkpoint 线程)可能无法获得锁。
- 没有通用的构建模式,每个源都需要实现自行实现复杂的线程模型,这使得开发和测试一个新的 source 变得困难,也提高了开发者对现有 source 的作出贡献的门槛。
有鉴于此,Flink 社区提出了 FLIP-27 [9] 的改进计划,并在 Flink 1.12 实现了基础框架,在 Flink 1.13 中 kafka、hive 和 file source 已移植到新架构,开源社区的 Flink CDC connector 2.0 [11] 也基于新架构实现。
Source 新架构
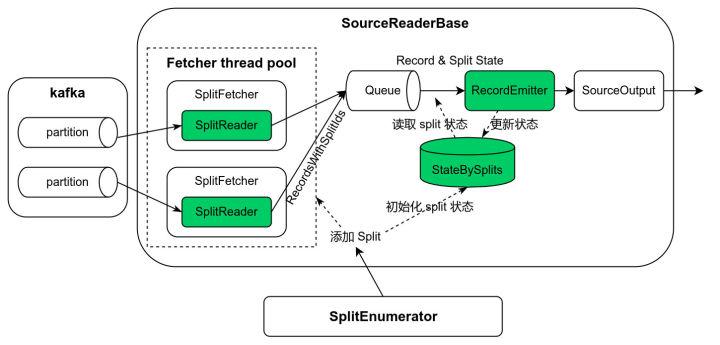
基于 FLIP-27 的 Source 新架构如上图所示,由两个主要部件组成:SplitEnumerator 和 SourceReader。SplitEnumerator 负责数据分片和分配,SourceReader 则负责具体分片数据的读取。当一个新的分片被 SplitEnumerator 添加到 SourceReader,首先初始化分片状态并放入状态哈希表中,然后分片被分配给 SplitReader 读取数据。读取的数据以小批量模式封装于 RecordsWithSplitIds 并放置于中间队列 Queue,这种批量数据模式可以提高性能。SourceReader 从 Queue 中获取一批数据,遍历每一条数据,并查找数据相应的分片状态,数据和分片状态一并传递给 RecordEmitter,RecordEmitter 先把数据传递给 SourceOutput,然后更新分片状态。状态哈希表中的状态在 checkpoint 时持久化到状态存储。
Source 新架构具有以下特点。
数据分片与数据读取分离。例如在 FileSource 中,SplitEnumerator 负责列出所有的文件,并有可能把文件按块或者范围进行切分,SourceReader 则负责具体的文件/块的数据读取。又例如在 KafkaSource 中,SplitEnumerator 负责发现需要读取的 kafka partition,SourceReader 则负责具体 partition 数据的读取。
批流融合。基于新架构开发的 Source 既可以工作于批模式也可以工作于流模式,批仅仅是有界的流。大多数情况下,只有 SplitEnumerator 需要感知数据源是否有界。例如对于 FileSource,批模式下 SplitEnumerator 只需要一次性的列出目录下的所有文件,流模式下则需要周期性的列出所有文件,并为新增的文件生成数据分片。对于 KafkaSource,批模式下 SplitEnumerator 列出处有的 partition,并把每个 partition 的当前最新的数据偏移作为数据分片的结束点,流模式下 SplitEnumerator 则把无穷大作为 partition 数据分片的结束点,即会持续的读取每个 partition 的新增数据,流模式下还可以周期性的监测 partition 的变化并为新增的 partitition 生成数据分片。
双向通信。SplitEnumerator 运行在 JobManager,SourceReader 运行在 TaskManager,SplitEnumerator 和 SourceReader 之间可以双向通信,SourceReader 可以主动向 SplitEnumerator 请求数据分片实现 pull 模式的数据分片分配(例如 FileSource),SplitEnumerator 也可以把数据分片直接分配给 SourceReader 实现 push 模式的分配(例如 KafkaSource)。此外,根据需要还可以定制化一些消息实现 SplitEnumerator 和 SourceReader 之间的交互需求。基于双向通信的能力,比较容易实现事件时间对齐(event-time alignment)的功能,实现数据分片之间事件时间的均衡推进。
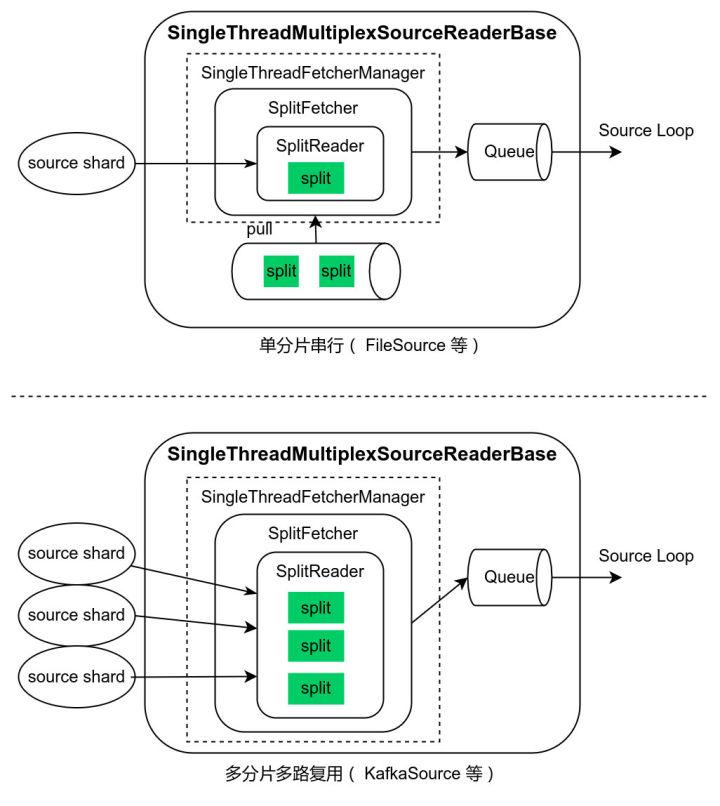
通用线程模型。考虑到外部数据源系统的客户端 API 调用方式的差异(阻塞、非阻塞、异步),SourceReader 在设计上支持单分片串行读取、多分片多路复用、多分片多线程三种模式。Flink 1.13 内核的 SingleThreadMultiplexSourceReaderBase/SingleThreadFetcherManager 抽象出的框架支持前两种线程模型,开发者基于此开发 source connector 变得容易。例如 FileSource 采用了单分片串行读取模式,在一个数据分片读取后,再向 SplitEnumerator 请求新的数据分片。KafkaSource 采用了多分片多路复用模式,SplitEnumerator 把启动时读取的 partition 列表和定期监测时发现的新的 partition 列表批量分配给 SourceReader,SourceReader 使用 KafkaConsumer API 读取所有分配到的 partition 的数据。
容错。SplitEnumerator 和 SourceReader 通过 Flink 的分布式快照机制持久化状态,发生异常时从状态恢复。通常 SplitEnumerator 状态保存了未分配的数据分片,SourceReader 状态保存了分配的数据分片以及分片读取状态(例如 kafka offset,文件 offset)。例如流模式下 FileSource 的 SplitEnumerator 状态保存了未分配的分片以及处理过的文件列表,并定期监测文件列表的变化,为新增文件生成数据分片;SourceReader 状态保存了当前读取的分片信息和文件读取 offset。
FileSource 开发实践
下面我们进入实际操作阶段,基于新架构开一个简单的 FileSource connector,该 connector 工作于流模式,读取指定目录下的文件,并定期监测新增文件。
初始化项目
- 我们使用 IntelliJ IDEA 作为开发工具,并按照 Flink 编码规范配置 IntelliJ IDEA [12],在菜单栏选择 "File -> New -> Project...",填写必要的信息,按照提示操作完成项目创建。
- 在 pom.xml [13] 文件添加必要的 Flink 依赖。
- Flink 基于 Java SPI 机制 l 发现和加载自定义 connector,我们在 resources 目录下创建目录
META-INF/services,并在该目录下创建文件org.apache.flink.table.factories.Factory,文件内容为:
com.tencent.cloud.oceanus.connector.file.table.FileDynamicTableFactory- 创建 Java 类
com.tencent.cloud.oceanus.connector.file.table.FileDynamicTableFactory实现DynamicTableSourceFactory。 - 现在,我们项目初始化已经完成,可以在 IntelliJ IDEA 项目右侧选择 "Maven -> flink-connector-files -> LifeCyle -> package" 构建项目,能够在 target 目录下正确构建出名为 flink-connector-files-1.0.0.jar 的二进制包。
Connector 开发
我们按照 Flink 官方的自定义 connector 开发文档 [14] 来一步步完成 FileSource connector 的开发。
Metadata 层
简单起见,我们的 connector 只支持按行读取指定目录的文件,在 SQL 语句中按如下方式使用 connector。
CREATE TABLE test (
`line` STRING
) WITH (
'connector' = 'file',
'path' = 'file:///path/to/files'
);Planning 层
- 创建类 FileDynamicTableFactory [15],添加自定义 connector 标识
file和参数path。校验参数并创建 FileDynamicSource [16]。 - FileDynamicSource [16] 创建 Runtime 层的 FileSource [17]。
Runtime 层
FileSource [17]
实现 Source [10] 接口,需要三个类型参数:第一类型参数为 Source 输出数据类型,由于我们的 connector 用于 SQL 作业场景,这里设置为 RowData 类型。第二个类型参数为数据分片类型 SourceSplit [18]。第三个类型参数为 SplitEnumerator checkpoint 数据类型。
FileSource 是一个工厂类,用于创建 SplitEnumerator、SourceReader、数据分片序列化器、SplitEnumerator checkpoint 序列化器。
FileSourceSplit [19]
实现 SourceSplit [18]。该类保存了数据分片 id、文件路径、数据分片起始位置的文件偏移(我们这里整个文件作为一个数据分片,不再细分,因此偏移始终为 0)、文件长度、文件读取进度(恢复时从该位置继续数据读取)。
FileSourceSplitSerializer [20]
数据分片序列化器,对 FileSourceSplit [19] 序列化和反序列化。数据分片在从 SplitEnumerator 传输到 SourceReader,以及被 SourceReader checkpoint 持久化时都需要序列化。
PendingSplitsCheckpoint [21]
SplitEnumerator checkpoint 数据,保存了未分配的分片以及处理过的文件列表。
PendingSplitsCheckpointSerializer [22]
SplitEnumerator checkpoint 序列化器,对 PendingSplitsCheckpoint [21] 序列化和反序列化。
FileSourceEnumerator [23]
定期监测目录下的文件,生成数据分片,并分配给 SourceReader。Flink 内核提供了定时回调接口
SplitEnumeratorContext#callAsync [24] 方便我们使用。这里我们采用 pull 模式的数据分片分配策略。
FileSourceReader [25]
继承自 SingleThreadMultiplexSourceReaderBase,在读取完一个数据分片(文件)后再向 FileSourceEnumerator [23] 请求下一个分片。我们需要实现数据分片状态初始化接口 initializedState [26],当新的数据分片加入时会调用该接口。实现接口 toSplitType [27],把可变的数据分片状态 FileSourceSplitState [28] 转换为不可变的数据分片 FileSourceSplit [19],checkpoint 时会调用该接口得到最新状态的 FileSourceSplit 并持久化。 FileSourceRecordEmitter [29] 发送数据到下游,并更新 FileSourceSplitState 的分片读取进度。具体分片数据读取逻辑在 FileSourceSplitReader [30] 实现,这里我们简单的每次读取一行数据。
Connector 测试
基本功能
- 从 Flink 官网下载已经编译好的二进制包 Apache Flink 1.13.3 for Scala 2.11 [31] 并解压,进入解压后的目录。拷贝我们开发的 connector 二进制包 flink-connector-files-1.0.0.jar [32] 到 lib 目录。
tar -zxvf flink-1.13.3-bin-scala_2.11.tgz
cd flink-1.13.3
cp flink-connector-files-1.0.0.jar lib/ -avi- 启动本地集群。可在本地浏览器里打开 http://localhost:8081 进入 Flink UI 验证集群是否启动成功。
./bin/start-cluster.sh- 创建测试数据目录,我们的 connector 从该目录下读取文件。然后进入 sql client 命令行。
mkdir -p /tmp/file-connector
./bin/sql-client.sh- 在 sql client 命令行输入。
create table `source` (
`line` STRING
) with (
'connector' = 'file',
'path' = '/tmp/file-connector'
);
select * from `source`;- 我们往目录
/tmp/file-connector写入几个文件测试一下,可见我们的 connector 能正常的读取文件数据。
cd /tmp/file-connector
echo "Hello World" > 1.txt
echo "tencent" > 2.txt
echo "oceanus" > 3.txt
echo "我爱我的祖国" > 4.txt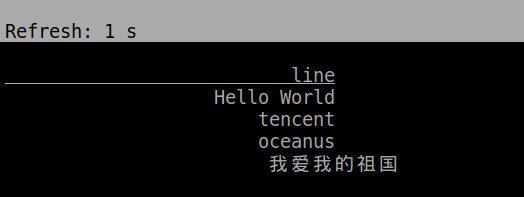
状态和容错
- 在 Flink 配置
conf/flink-conf.yaml添加状态存储配置,设置 checkpoint 和 savepoint 目录,checkpoint 时间间隔,以及 Flink 重启策略。
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints
state.savepoints.dir: file:///tmp/flink-savepoints
execution.checkpointing.interval: 30s
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 30
restart-strategy.fixed-delay.delay: 5s- 重启集群,并重新进入 sql client 命令行。
./bin/stop-cluster.sh
./bin/start-cluster.sh
./bin/sql-client.sh本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java