
Linux I/O 基本原理。
我们先看一张图:
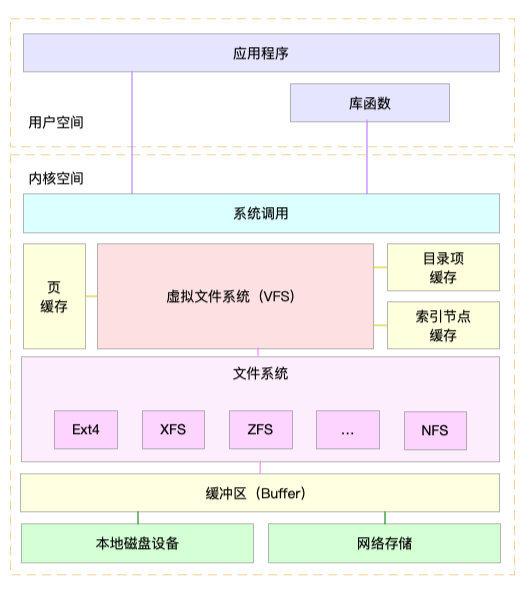
这张图大体上描述了 Linux 系统上,应用程序对磁盘上的文件进行读写时,从上到下经历了哪些事情。
这篇文章就以这张图为基础,介绍 Linux 在 I/O 上做了哪些事情。
文件系统
什么是文件系统
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。比如常见的 Ext4、XFS、ZFS 以及网络文件系统 NFS 等等。
但是不同类型的文件系统标准和接口可能各有差异,我们在做应用开发的时候却很少关心系统调用以下的具体实现,大部分时候都是直接系统调用 open, read, write, close 来实现应用程序的功能,不会再去关注我们具体用了什么文件系统(UFS、XFS、Ext4、ZFS),磁盘是什么接口(IDE、SCSI,SAS,SATA 等),磁盘是什么存储介质(HDD、SSD)
应用开发者之所以这么爽,各种复杂细节都不用管直接调接口,是因为内核为我们做了大量的有技术含量的脏活累活。开始的那张图看到 Linux 在各种不同的文件系统之上,虚拟了一个 VFS,目的就是统一各种不同文件系统的标准和接口,让开发者可以使用相同的系统调用来使用不同的文件系统。
文件系统如何工作(VFS)
Linux 系统下的文件
在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。
用 ls -l 命令看最前面的字符可以看到这个文件是什么类型
brw-r--r-- 1 root root 1, 2 4月 25 11:03 bnod // 块设备文件
crw-r--r-- 1 root root 1, 2 4月 25 11:04 cnod // 符号设备文件
drwxr-xr-x 2 wrn3552 wrn3552 6 4月 25 11:01 dir // 目录
-rw-r--r-- 1 wrn3552 wrn3552 0 4月 25 11:01 file // 普通文件
prw-r--r-- 1 root root 0 4月 25 11:04 pipeline // 有名管道
srwxr-xr-x 1 root root 0 4月 25 11:06 socket.sock // socket文件
lrwxrwxrwx 1 root root 4 4月 25 11:04 softlink -> file // 软连接
-rw-r--r-- 2 wrn3552 wrn3552 0 4月 25 11:07 hardlink // 硬链接(本质也是普通文件)Linux 文件系统设计了两个数据结构来管理这些不同种类的文件:
- inode(index node):索引节点
- dentry(directory entry):目录项
inode 和 dentry
inode
inode 是用来记录文件的 metadata,所谓 metadata 在 Wikipedia 上的描述是 data of data,其实指的就是文件的各种属性,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。
wrn3552@novadev:~/playground$ stat file
文件:file
大小:0 块:0 IO 块:4096 普通空文件
设备:fe21h/65057d Inode:32828 硬链接:2
权限:(0644/-rw-r--r--) Uid:( 3041/ wrn3552) Gid:( 3041/ wrn3552)
最近访问:2021-04-25 11:07:59.603745534 +0800
最近更改:2021-04-25 11:07:59.603745534 +0800
最近改动:2021-04-25 11:08:04.739848692 +0800
创建时间:-inode 和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以,inode 同样占用磁盘空间,只不过相对于文件来说它大小固定且大小不算大。
dentry
dentry 用来记录文件的名字、inode 指针以及与其他 dentry 的关联关系。
wrn3552@novadev:~/playground$ tree
.
├── dir
│ └── file_in_dir
├── file
└── hardlink- 文件的名字:像 dir、file、hardlink、file_in_dir 这些名字是记录在 dentry 里的
- inode 指针:就是指向这个文件的 inode
- 与其他 dentry 的关联关系:其实就是每个文件的层级关系,哪个文件在哪个文件下面,构成了文件系统的目录结构
不同于 inode,dentry 是由内核维护的一个内存数据结构,所以通常也被叫做 dentry cache。
文件是如何存储在磁盘上的

这里有张图解释了文件是如何存储在磁盘上的,首先,磁盘再进行文件系统格式化的时候,会分出来 3 个区:
- Superblock
- inode blocks
- data blocks
(其实还有 boot block,可能会包含一些 bootstrap 代码,在机器启动的时候被读到,这里忽略)其中 inode blocks 放的都是每个文件的 inode,data blocks 里放的是每个文件的内容数据。这里关注一下 superblock,它包含了整个文件系统的 metadata,具体有:
- inode/data block 总量、使用量、剩余量
- 文件系统的格式,属主等等各种属性
superblock 对于文件系统来说非常重要,如果 superblock 损坏了,文件系统就挂载不了了,相应的文件也没办法读写。既然 superblock 这么重要,那肯定不能只有一份,坏了就没了,它在系统中是有很多副本的,在 superblock 损坏的时候,可以使用 fsck(File System Check and repair)来恢复。回到上面的那张图,可以很清晰地看到文件的各种属性和文件的数据是如何存储在磁盘上的:
- dentry 里包含了文件的名字、目录结构、inode 指针
- inode 指针指向文件特定的 inode(存在 inode blocks 里)
- 每个 inode 又指向 data blocks 里具体的 logical block,这里的 logical block 存的就是文件具体的数据
这里解释一下什么是 logical block:
- 对于不同存储介质的磁盘,都有最小的读写单元
/sys/block/sda/queue/physical_block_size
- HDD 叫做 sector(扇区),SSD 叫做 page(页面)
- 对于 hdd 来说,每个 sector 大小 512Bytes
- 对于 SSD 来说每个 page 大小不等(和 cell 类型有关),经典的大小是 4KB
- 但是 Linux 觉得按照存储介质的最小读写单元来进行读写可能会有效率问题,所以支持在文件系统格式化的时候指定 block size 的大小,一般是把几个 physical_block 拼起来就成了一个 logical block
/sys/block/sda/queue/logical_block_size
- 理论上应该是 logical_block_size >= physical_block_size,但是有时候我们会看到 physical_block_size = 4K,logical_block_size = 512B 情况,其实这是因为磁盘上做了一层 512B 的仿真(emulation)(详情可参考 512e 和 4Kn)
ZFS
这里简单介绍一个广泛应用的文件系统 ZFS,一些数据库应用也会用到 ZFS,先看一张 zfs 的层级结构图:

这是一张从底向上的图:
- 将若干物理设备 disk 组成一个虚拟设备 vdev(同时,disk 也是一种 vdev)
- 再将若干个虚拟设备 vdev 加到一个 zpool 里
- 在 zpool 的基础上创建 zfs 并挂载(zvol 可以先不看,我们没有用到)
ZFS 的一些操作
创建 zpool
root@:~ # zpool create tank raidz /dev/ada1 /dev/ada2 /dev/ada3 raidz /dev/ada4 /dev/ada5 /dev/ada6
root@:~ # zpool list tank
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 11G 824K 11.0G - - 0% 0% 1.00x ONLINE -
root@:~ # zpool status tank
pool: tank
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
raidz1-1 ONLINE 0 0 0
ada4 ONLINE 0 0 0
ada5 ONLINE 0 0 0
ada6 ONLINE 0 0 0- 创建了一个名为 tank 的 zpool
- 这里的 raidz 同 RAID5
除了 raidz 还支持其他方案:

| 方案 | 说明 |
|---|
创建 zfs
root@:~ # zfs create -o mountpoint=/mnt/srev tank/srev
root@:~ # df -h tank/srev
Filesystem Size Used Avail Capacity Mounted on
tank/srev 7.1G 117K 7.1G 0% /mnt/srev- 创建了一个 zfs,挂载到了 /mnt/srev
- 这里没有指定 zfs 的 quota,创建的 zfs 大小即 zpool 大小
对 zfs 设置 quota
root@:~ # zfs set quota=1G tank/srev
root@:~ # df -h tank/srev
Filesystem Size Used Avail Capacity Mounted on
tank/srev 1.0G 118K 1.0G 0% /mnt/srevZFS 特性
Pool 存储
上面的层级图和操作步骤可以看到 zfs 是基于 zpool 创建的,zpool 可以动态扩容意味着存储空间也可以动态扩容,而且可以创建多个文件系统,文件系统共享完整的 zpool 空间无需预分配。
事务文件系统
zfs 的写操作是事务的,意味着要么就没写,要么就写成功了,不会像其他文件系统那样,应用打开了文件,写入还没保存的时候断电,导致文件为空。zfs 保证写操作事务采用的是 copy on write 的方式:
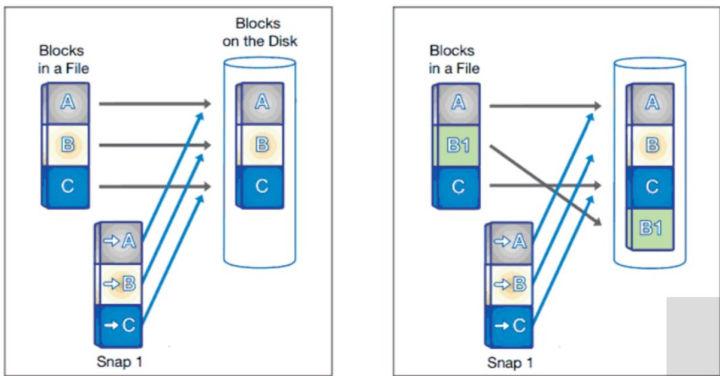
- 当 block B 有修改变成 B1 的时候,普通的文件系统会直接在 block B 原地进行修改变成 B1
- zfs 则会再另一个地方写 B1,然后再在后面安全的时候对原来的 B 进行回收
- 这样结果就不会出现 B 被打开而写失败的情况,大不了就是 B1 没写成功
这个特性让 zfs 在断电后不需要执行 fsck 来检查磁盘中是否存在写操作失败需要恢复的情况,大大提升了应用的可用性。
ARC 缓存
ZFS 中的 ARC(Adjustable Replacement Cache) 读缓存淘汰算法,是基于 IBM 的 ARP(Adaptive Replacement Cache) 演化而来。在一些文件系统中实现的标准 LRU 算法其实是有缺陷的:比如复制大文件之类的线性大量 I/O 操作,导致缓存失效率猛增(大量文件只读一次,放到内存不会被再读,坐等淘汰)。
另外,缓存可以根据时间来进行优化(LRU,最近最多使用),也可以根据频率进行优化(LFU,最近最常使用),这两种方法各有优劣,但是没办法适应所有场景。
ARC 的设计就是尝试在 LRU 和 LFU 之间找到一个平衡,根据当前的 I/O workload 来调整用 LRU 多一点还是 LFU 多一点。
ARC 定义了 4 个链表:
- LRU list:最近最多使用的页面,存具体数据
- LFU list:最近最常使用的页面,存具体数据
- Ghost list for LRU:最近从 LRU 表淘汰下来的页面信息,不存具体数据,只存页面信息
- Ghost list for LFU:最近从 LFU 表淘汰下来的页面信息,不存具体数据,只存页面信息
ARC 工作流程大致如下:
- LRU list 和 LFU list 填充和淘汰过程和标准算法一样
- 当一个页面从 LRU list 淘汰下来时,这个页面的信息会放到 LRU ghost 表中
- 如果这个页面一直没被再次引用到,那么这个页面的信息最终也会在 LRU ghost 表中被淘汰掉
- 如果这个页面在 LRU ghost 表中未被淘汰的时候,被再一次访问了,这时候会引起一次幽灵(phantom)命中
- phantom 命中的时候,事实上还是要把数据从磁盘第一次放缓存
- 但是这时候系统知道刚刚被 LRU 表淘汰的页面又被访问到了,说明 LRU list 太小了,这时它会把 LRU list 长度加一,LFU 长度减一
- 对于 LFU 的过程也与上述过程类似
ZFS 参考资料
关于 ZFS 详细介绍可以参考:
- 这篇文章
磁盘类型
磁盘根据不同的分类方式,有各种不一样的类型。
磁盘的存储介质
根据磁盘的存储介质可以分两类(大家都很熟悉):
- HDD(机械硬盘)
- SSD(固态硬盘)
磁盘的接口
根据磁盘接口分类:
- IDE (Integrated Drive Electronics)
- SCSI (Small Computer System Interface)
- SAS (Serial Attached SCSI)
- SATA (Serial ATA)
- ...
不同的接口,往往分配不同的设备名称。比如, IDE 设备会分配一个 hd 前缀的设备名,SCSI 和 SATA 设备会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,就会按照 a、b、c 等的字母顺序来编号。
Linux 对磁盘的管理
其实在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
g18-"299" on ~# ls -l /dev/sda*
brw-rw---- 1 root disk 8, 0 Apr 25 15:53 /dev/sda
brw-rw---- 1 root disk 8, 1 Apr 25 15:53 /dev/sda1
brw-rw---- 1 root disk 8, 10 Apr 25 15:53 /dev/sda10
brw-rw---- 1 root disk 8, 2 Apr 25 15:53 /dev/sda2
brw-rw---- 1 root disk 8, 5 Apr 25 15:53 /dev/sda5
brw-rw---- 1 root disk 8, 6 Apr 25 15:53 /dev/sda6
brw-rw---- 1 root disk 8, 7 Apr 25 15:53 /dev/sda7
brw-rw---- 1 root disk 8, 8 Apr 25 15:53 /dev/sda8
brw-rw---- 1 root disk 8, 9 Apr 25 15:53 /dev/sda9- 这些 sda 磁盘主设备号都是 8,表示它是一个 sd 类型的块设备
- 次设备号 0-10 表示这些不同 sd 块设备的编号
Generic Block Layer
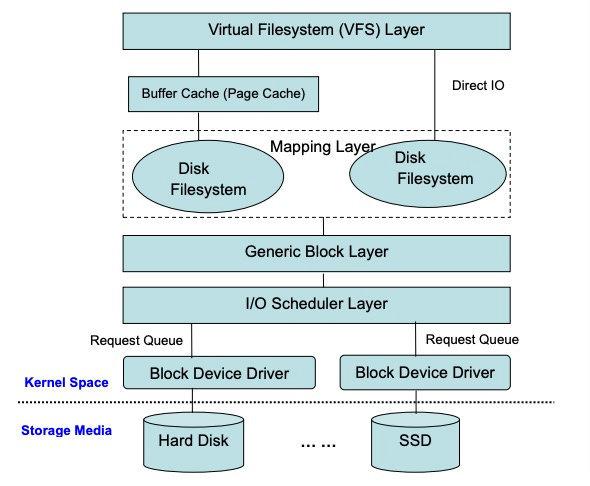
和 VFS 类似,为了对上层屏蔽不同块设备的差异,内核在文件系统和块设备之前抽象了一个 Generic Block Layer(通用块层),有时候一些人也会把下面的 I/O 调度层并到通用块层里表述。
这两层主要做两件事:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java